RabbitMQ 基础
RabbitMQ是一种简单的消息队列,消息队列是什么?
消息队列也就是服务和进程之间相互异步通讯的方式,它的核心模型就是生产者将消息发送到队列,消费者然后从中获取并处理消息。所以关键的组件就在于生产者,消费者,队列,交换机。
异步处理:指的是生产者发送消息后无序等待消费者立即处理完成,继续执行其他任务,它的作用就在于缩短了响应的时间,提高了用户体验。
应用解耦:系统之间通过消息队列之间进行通讯,而不是直接调用API,使得各个服务之间的耦合性大大降低,同时也提高了系统的维护和扩展。
流量削峰:当系统面临高并发的时候,将请求放入消息队列,消费者按照自身的能力从队列中获取消息进行处理,避免了后端系统在瞬间高峰压力在崩溃,平衡系统负载。
Rabbit MQ的核心特点就在于,可靠性,防止信息的丢失和信息的正确处理,以及灵活的路由,通过交换机和绑定,使信息能够正常的进行消费。
RabbitMQ它默认的访问地址:http://localhost:15672
Rabbit MQ核心组件
生产者:消息的发送者。
消费者:接收并处理消息的程序
队列:存储信息的缓冲区。
交换机:接收生产者消息并路由到队列
绑定:交换机与队列之间的关联关系
连接:生产者/消费者与RabbitMQ服务器之间的TCP连接
信道:连接内部创建的虚拟连接,用于消息传递。
各个组件之间的关系:
-
生产者通过信道连接到交换机,发送消息
-
交换机根据路由规则(通过绑定关系)将消息路由到一个或多个队列
-
消费者通过信道连接到队列,接收并处理消息
-
所有通信都在 TCP 连接的基础上进行,一个连接可以包含多个信道
AMQP 三层协议结构
想象一下邮局系统:
-
你想寄信(发消息): 你就是 生产者。
-
邮局(AMQP系统): 这就是负责帮你可靠地传递信件(消息)的基础设施。AMQP 就是规定邮局如何运作的一套标准规则。
-
信箱(队列): 信件不是直接送到收件人手里的,而是先放到邮局的特定信箱里。这个信箱就是 队列。队列是消息暂时存放的地方。
-
收信人(处理消息的程序): 最终会去信箱取信并处理的人(或程序),就是 消费者。
-
邮局工作人员和分拣规则(交换机和绑定): 邮局不是简单地把所有信都塞进一个信箱。它有个“分拣中心”(交换机)。你寄信时要写明地址(路由键)。分拣中心根据一套规则(绑定)决定这封信应该投递到哪个具体的信箱(队列)里。比如,规则可能是“所有寄往北京的信用放到‘北京信箱’里”。
AMQP 的核心就是这套标准化的“邮局工作流程”:
-
标准化: 它规定了一个通用的方式,让不同的程序(可能是用不同语言写的,运行在不同的电脑上)能可靠地收发消息。就像邮局规定了信封怎么写、邮票怎么贴,大家才能互相寄信。
-
可靠性: AMQP 设计时就考虑了消息不能丢。就像邮局会给你挂号信回执,消息发送者能知道消息是否成功被邮局(队列)接收;消费者处理完消息后也会给邮局回执,邮局才把信从信箱里拿走(避免消息没处理完就丢了)。
-
解耦: 发信的人(生产者)只管把信扔给邮局,完全不用关心谁(消费者)会取信、什么时候取信。取信的人(消费者)也只需要去自己的信箱拿信,不用关心是谁寄来的。两边互不干扰,系统更灵活、更好维护。
-
灵活路由: 通过交换机和绑定规则,可以非常灵活地把消息分发到不同的队列。比如:
-
所有消息都复制一份发到每个队列(广播)。
-
根据消息的类型(路由键)发到特定队列(比如“订单消息”发到订单处理队列,“支付消息”发到支付队列)。
-
根据复杂的规则匹配发送。
-
-
AMQP 就是一个通用的、可靠的“消息邮局”工作标准。 它定义了程序之间如何通过“寄信”(发送消息)到“信箱”(队列),再由其他程序“取信”(消费消息)来进行异步通信的一套规则。它的核心目标是让不同的软件组件能可靠地、灵活地互相传递信息,并且彼此之间不需要直接联系(解耦)。
你可以把 RabbitMQ 想象成一个按照 AMQP 这套标准规则建立起来的、功能非常强大的具体邮局。
要想使用AMQP需要先引入关键依赖
<dependencies><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><!--AMQP依赖,包含RabbitMQ--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-amqp</artifactId></dependency><!--单元测试--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId></dependency></dependencies>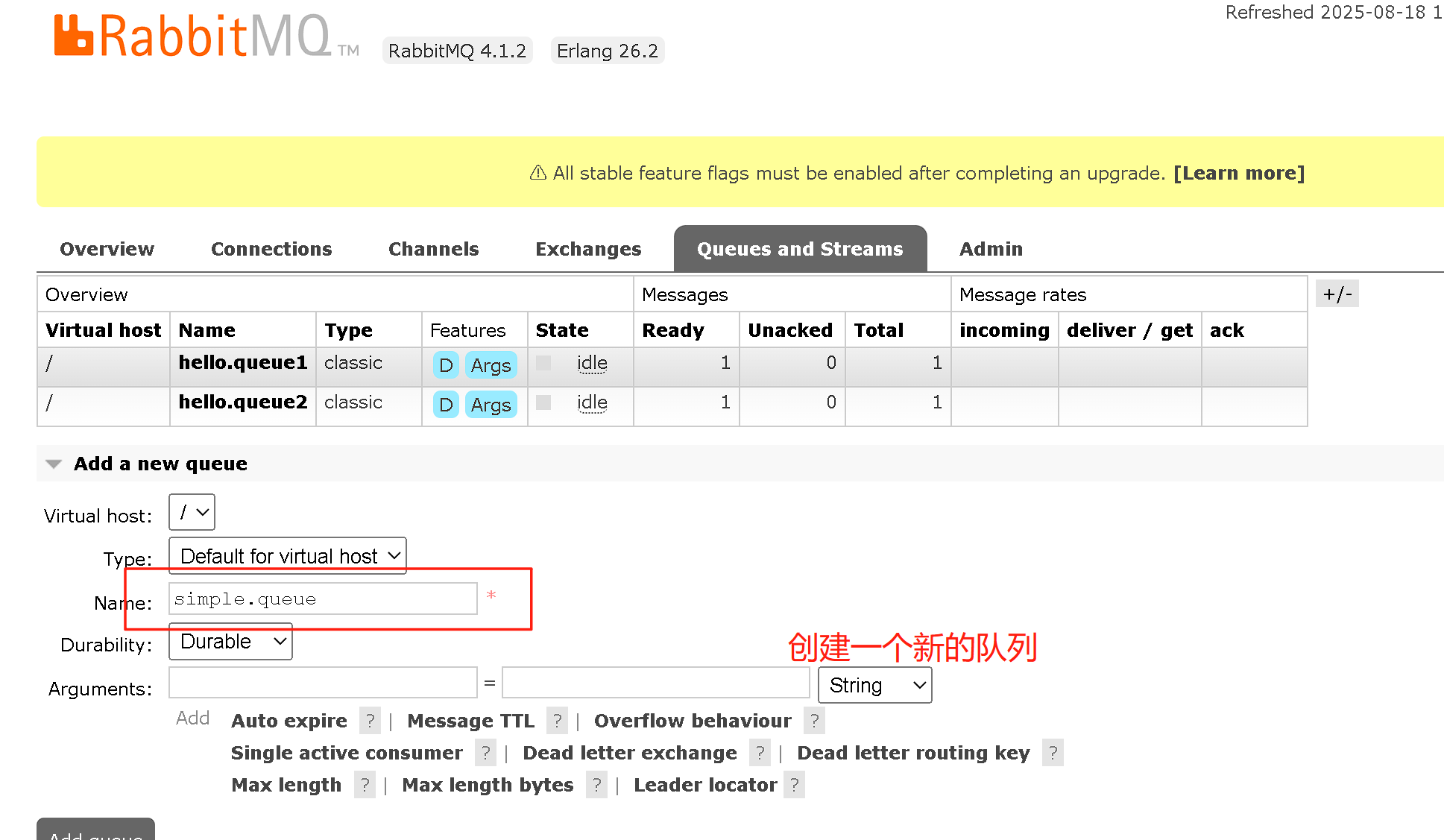
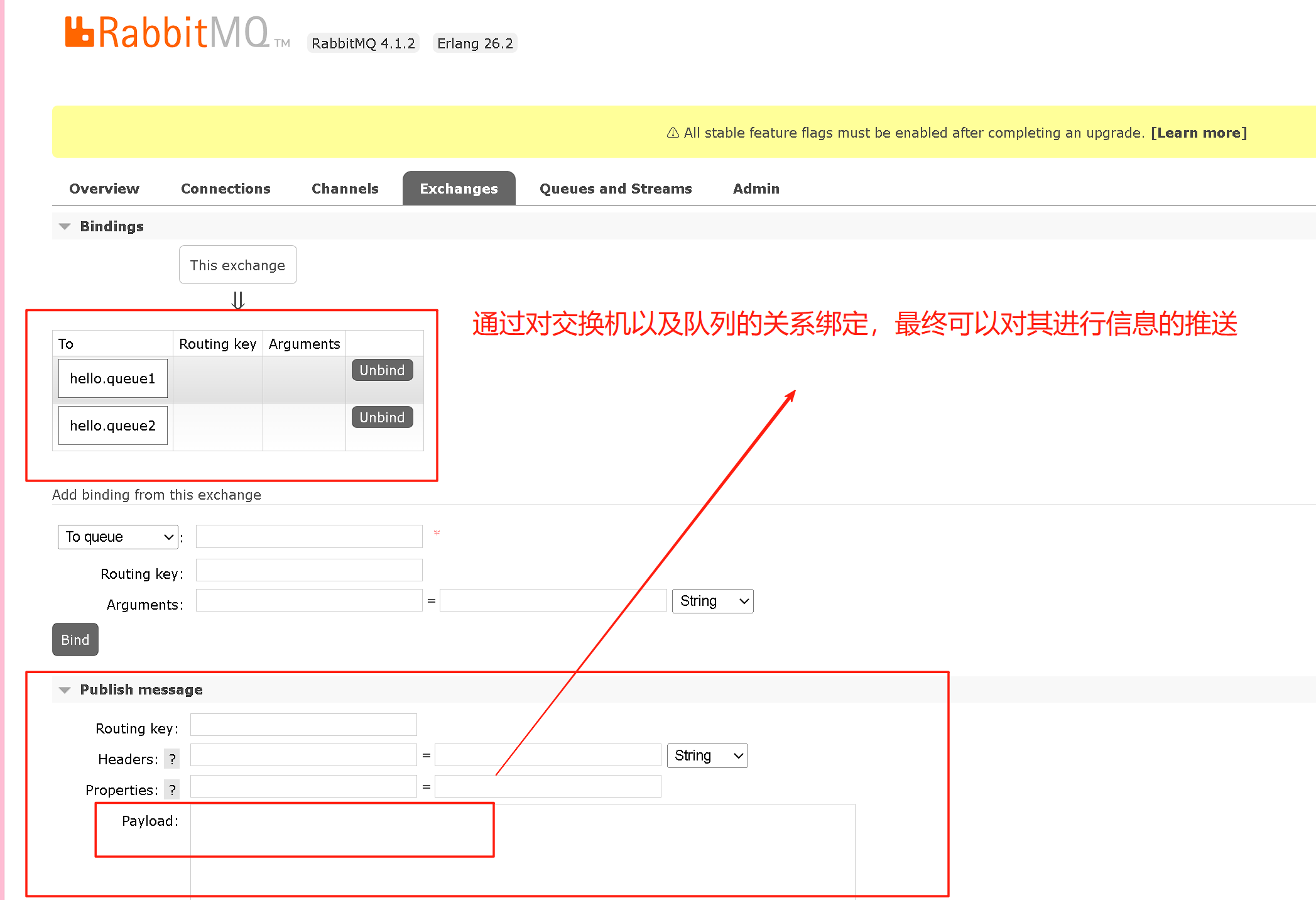
添加新的队列之后就可以进行简单的绑定和发送,在进行绑定之前需要先进行简单的配置:
spring:rabbitmq:host: 127.0.0.1port: 15672username: guestpassword: guest然后就可以进行简单编写测试类:
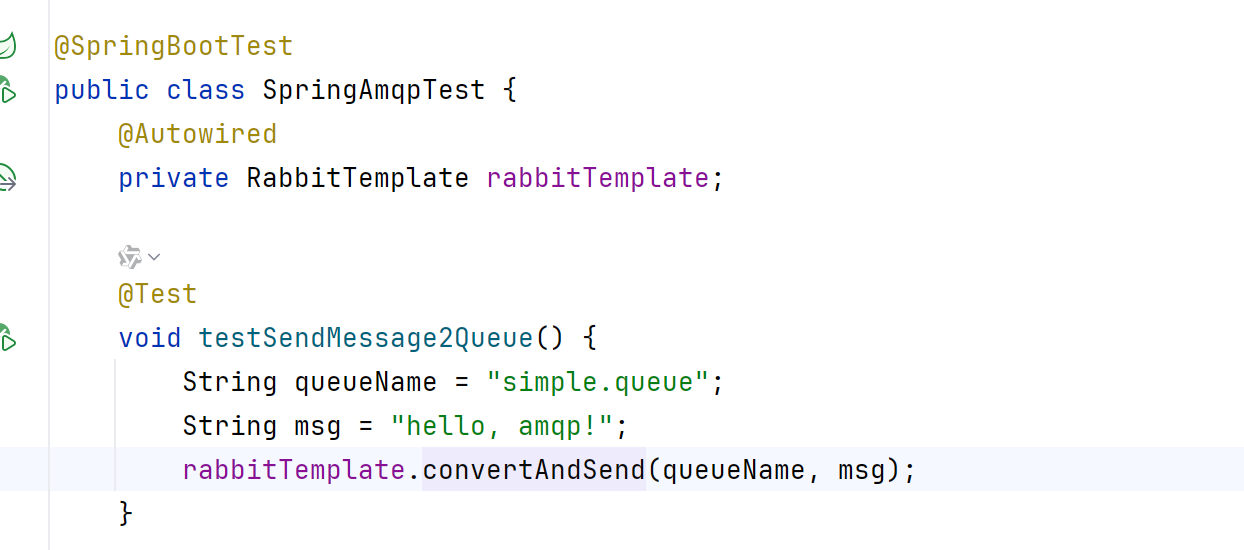
当我们发送之后就可以看到队列处有信息:

这就代表着我们消息发送成功
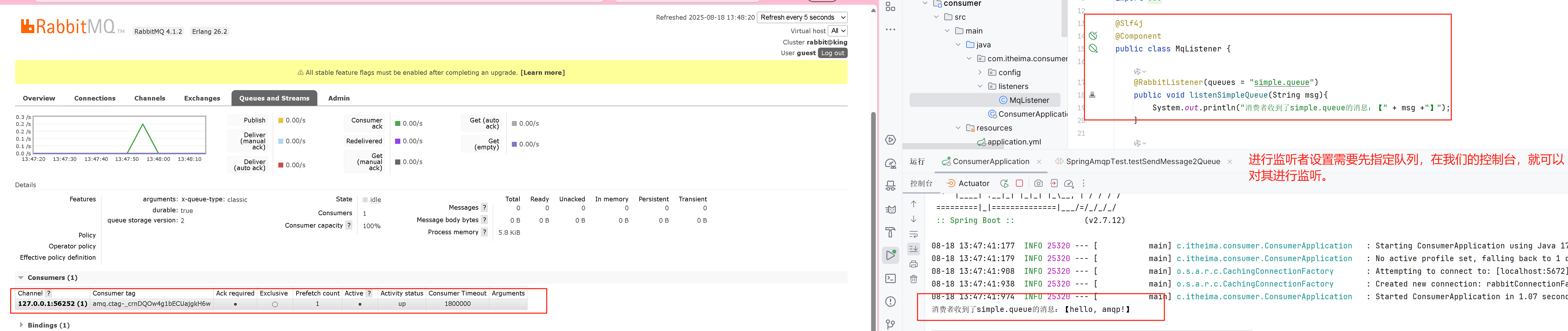
注意,消息的接收方也需要进行Rabbit MQ的简单配置,事实上,要进行消息的发送只需要指定队列,和发送的信息,而接听消息只要指定队列就可以,实现自动的监听,抵达控制台打印。
Work Queues模型
Work queues,任务模型。简单来说就是让多个消费者绑定到一个队列,共同消费队列中的消息。
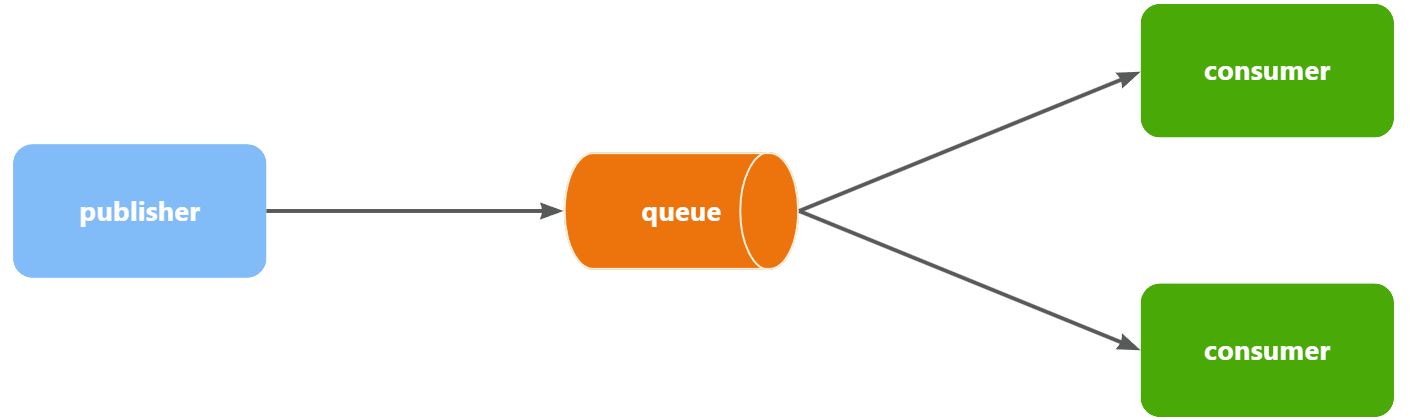
当消息处理比较耗时的时候,可能生产消息的速度会远远大于消息的消费速度。长此以往,消息就会堆积越来越多,无法及时处理。 此时就可以使用work 模型,多个消费者共同处理消息处理,消息处理的速度就能大大提高了。
根据前面简单队列的设置,我们可以模拟一直发送测试方法:
/*** workQueue* 向队列中不停发送消息,模拟消息堆积。*/
@Test
public void testWorkQueue() throws InterruptedException {// 队列名称String queueName = "simple.queue";// 消息String message = "hello, message_";for (int i = 0; i < 50; i++) {// 发送消息,每20毫秒发送一次,相当于每秒发送50条消息rabbitTemplate.convertAndSend(queueName, message + i);Thread.sleep(20);}
}对于消息的接收方,我们可以添加多个监听者实现:
@RabbitListener(queues = "work.queue")
public void listenWorkQueue1(String msg) throws InterruptedException {System.out.println("消费者1接收到消息:【" + msg + "】" + LocalTime.now());Thread.sleep(20);
}
@RabbitListener(queues = "work.queue")
public void listenWorkQueue2(String msg) throws InterruptedException {System.err.println("消费者2........接收到消息:【" + msg + "】" + LocalTime.now());Thread.sleep(200);
}
我们同样启动监听者就可以实现这个消息的发送。
同样这样的方法虽然实现,但是有一个问题,就是当我们的消费者的处理能力良莠不齐的时候,就有可能出现,两个监听者对消息进行的处理相同,但是一个处理的非常快,同等时间下,处理的份额达到了几倍之差,这个时候我们就可以在消费者的配置文件当中,这样配置实现压力的转移。
spring:rabbitmq:listener:simple:prefetch: 1 # 每次只能获取一条消息,处理完成才能获取下一个消息Work模型的使用:
-
多个消费者绑定到一个队列,同一条消息只会被一个消费者处理
-
通过设置prefetch来控制消费者预取的消息数量
交换机类型
在之前的两个测试案例中,都没有交换机,生产者直接发送消息到队列。而一旦引入交换机,消息发送的模式会有很大变化:
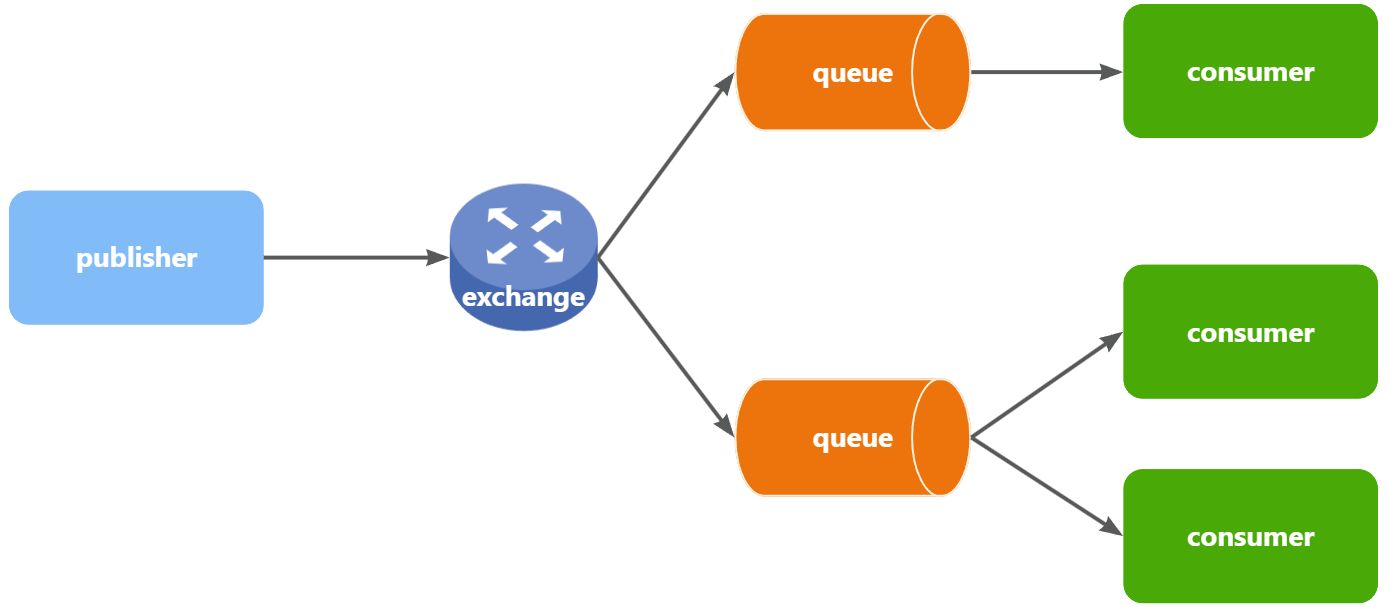
可以看到,在订阅模型中,多了一个exchange角色,而且过程略有变化:
-
Publisher:生产者,不再发送消息到队列中,而是发给交换机
-
Exchange:交换机,一方面,接收生产者发送的消息。另一方面,知道如何处理消息,例如递交给某个特别队列、递交给所有队列、或是将消息丢弃。到底如何操作,取决于Exchange的类型。
-
Queue:消息队列也与以前一样,接收消息、缓存消息。不过队列一定要与交换机绑定。
-
Consumer:消费者,与以前一样,订阅队列,没有变化
Exchange(交换机)只负责转发消息,不具备存储消息的能力,因此如果没有任何队列与Exchange绑定,或者没有符合路由规则的队列,那么消息会丢失!
交换机的类型有四种:
-
Fanout:广播,将消息交给所有绑定到交换机的队列。我们最早在控制台使用的正是Fanout交换机
-
Direct:订阅,基于RoutingKey(路由key)发送给订阅了消息的队列
-
Topic:通配符订阅,与Direct类似,只不过RoutingKey可以使用通配符
-
Headers:头匹配,基于MQ的消息头匹配,用的较少。
Fanout交换机
Fanout交换机也可以说是广播更合适。
在广播模式下,消息发送流程是这样的:
-
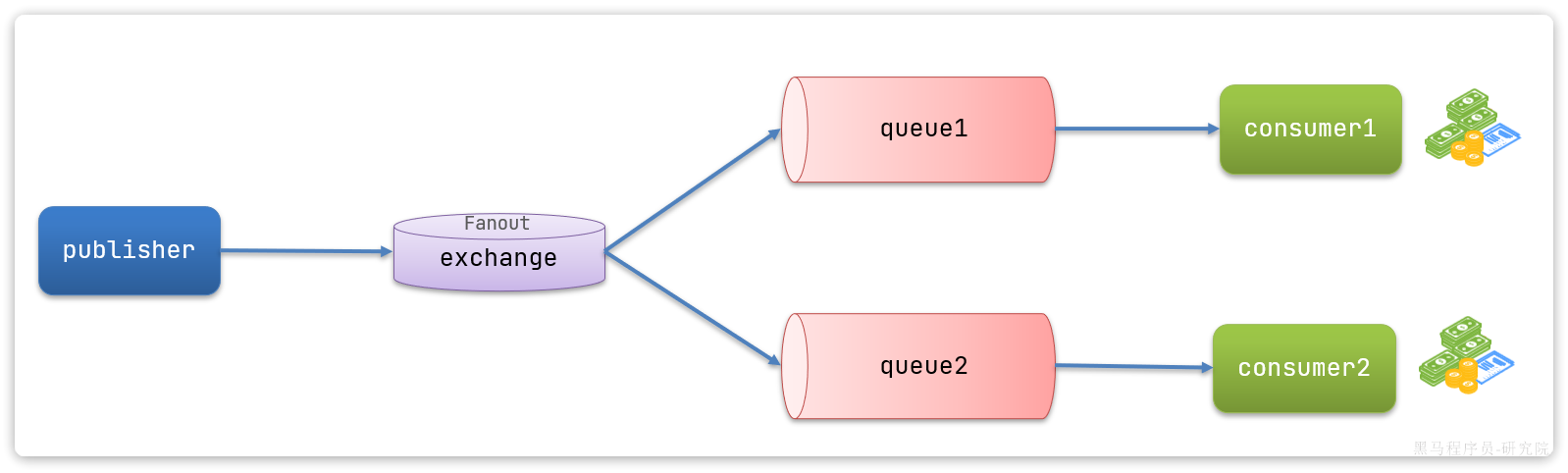
-
1) 可以有多个队列
-
2) 每个队列都要绑定到Exchange(交换机)
-
3) 生产者发送的消息,只能发送到交换机
-
4) 交换机把消息发送给绑定过的所有队列
-
5) 订阅队列的消费者都能拿到消息
这样我们可以先声明队列和交换机
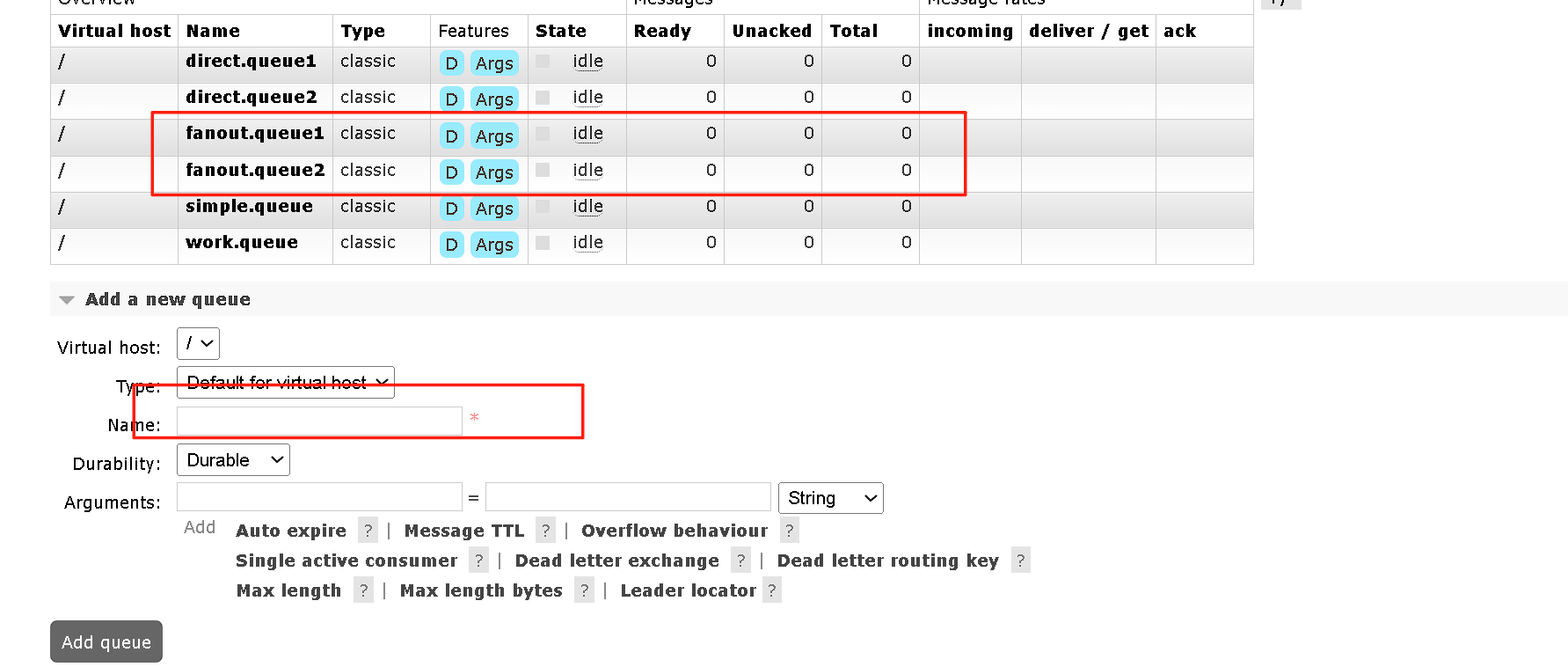
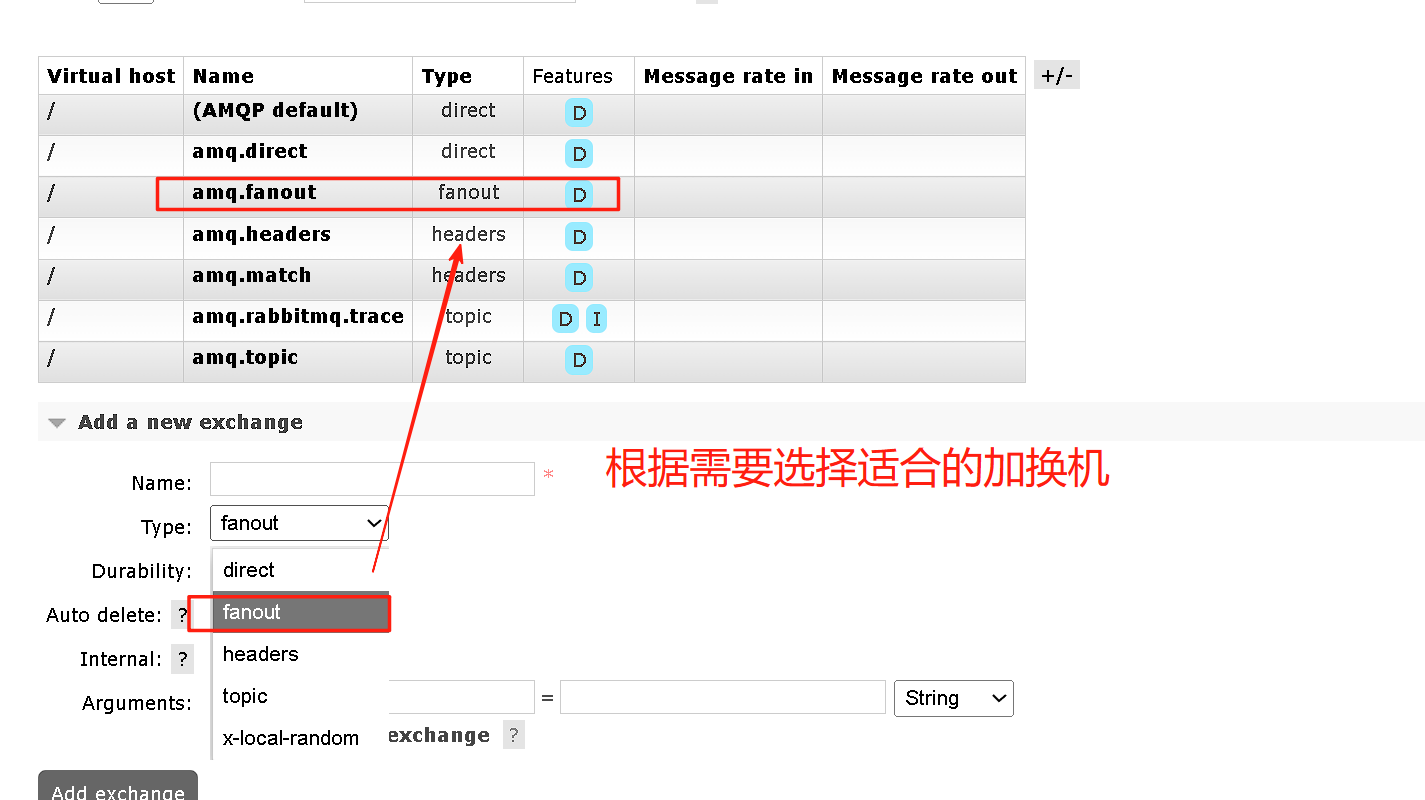
声明完队列和交换机之后就可以选择绑定关系。
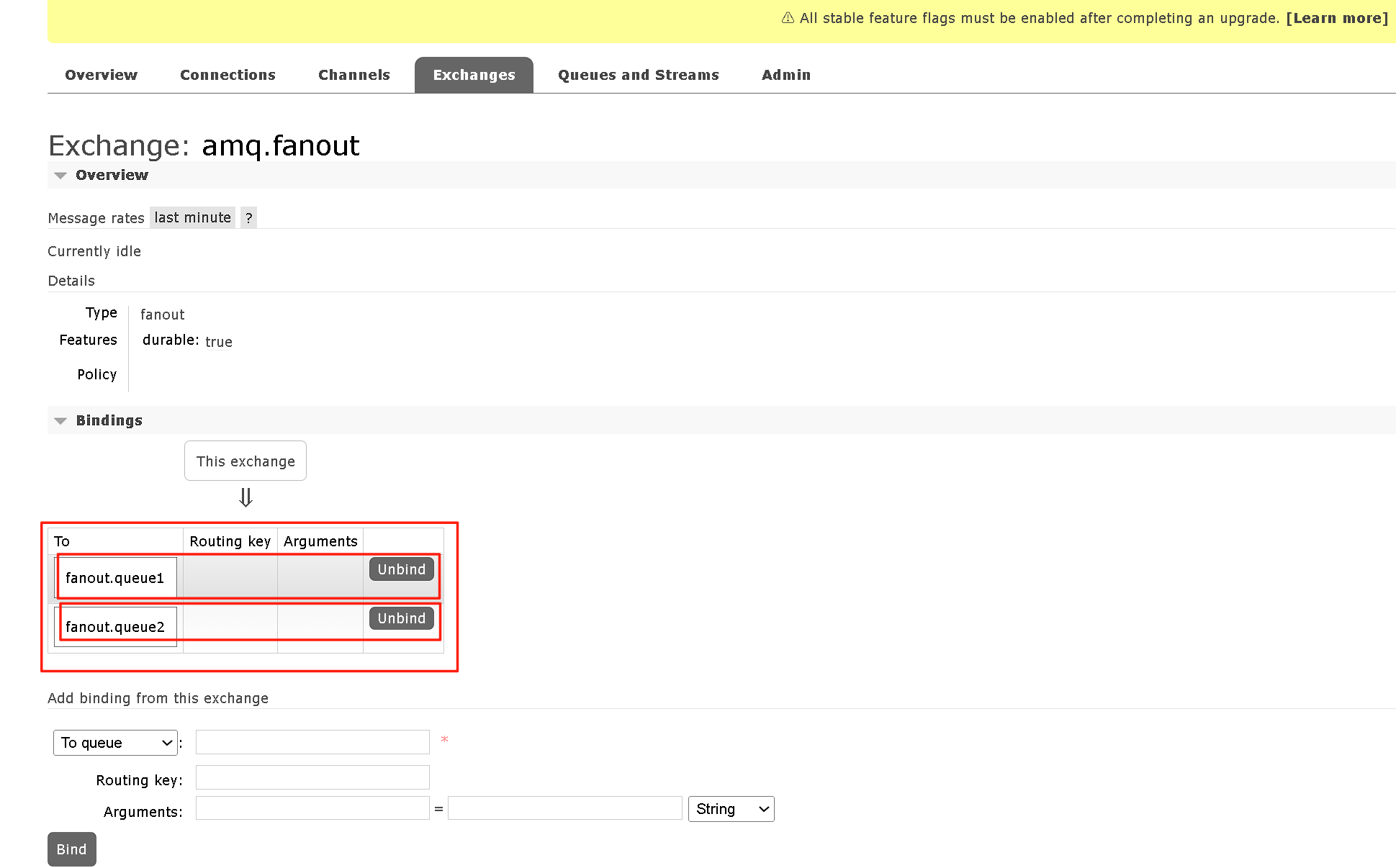
这个时候我们就可以进行消息的发送和接收
@Test
void testSendFanout() {String exchangeName = "amq.fanout";String msg = "hello, everyone!";rabbitTemplate.convertAndSend(exchangeName, null, msg);
}
@RabbitListener(queues = "fanout.queue1")
public void listenFanoutQueue1(String msg) throws InterruptedException {System.out.println("消费者1 收到了 fanout.queue1的消息:【" + msg +"】");
}
@RabbitListener(queues = "fanout.queue2")
public void listenFanoutQueue2(String msg) throws InterruptedException {System.out.println("消费者2 收到了 fanout.queue2的消息:【" + msg +"】");
}交换机的作用是什么?
-
接收publisher发送的消息
-
将消息按照规则路由到与之绑定的队列
-
不能缓存消息,路由失败,消息丢失
-
Fanout Exchange的会将消息路由到每个绑定的队列
Direct交换机
在Fanout模式中,一条消息,会被所有订阅的队列都消费。但是,在某些场景下,我们希望不同的消息被不同的队列消费。这时就要用到Direct类型的Exchange。
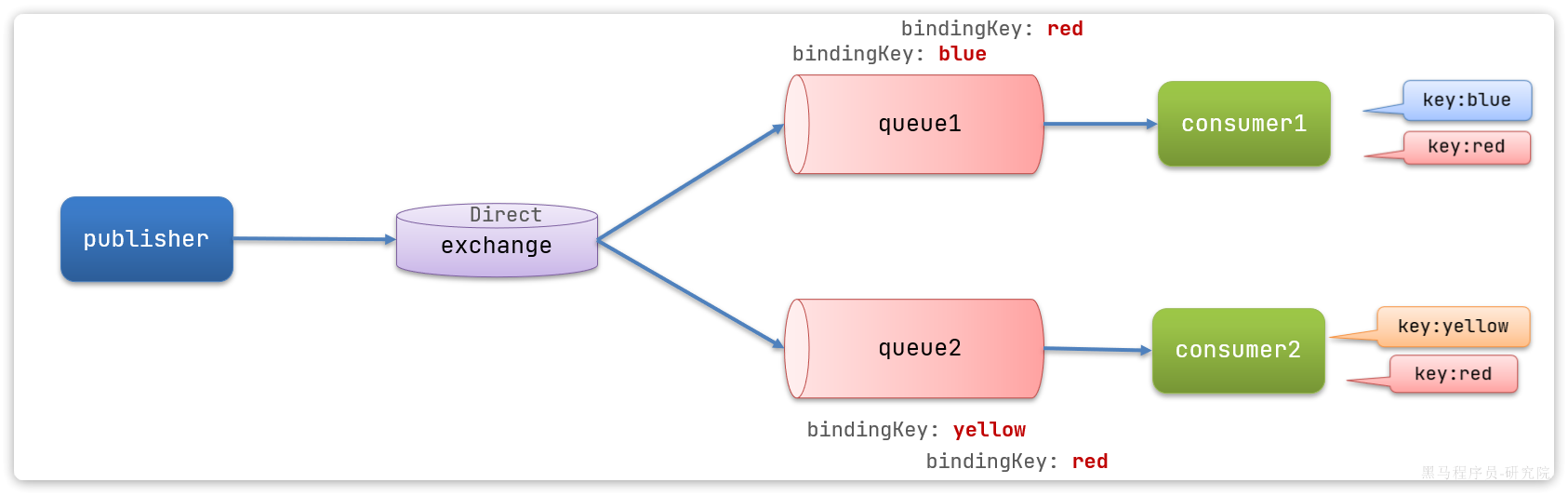
在Direct模型下:
-
队列与交换机的绑定,不能是任意绑定了,而是要指定一个
RoutingKey(路由key) -
消息的发送方在 向 Exchange发送消息时,也必须指定消息的
RoutingKey。 -
Exchange不再把消息交给每一个绑定的队列,而是根据消息的
Routing Key进行判断,只有队列的Routingkey与消息的Routing key完全一致,才会接收到消息
我们要进行演示,还是需要进行声明队列和交换机,我们经过Routingkey的标注来进行交换机和路由器之间的关系
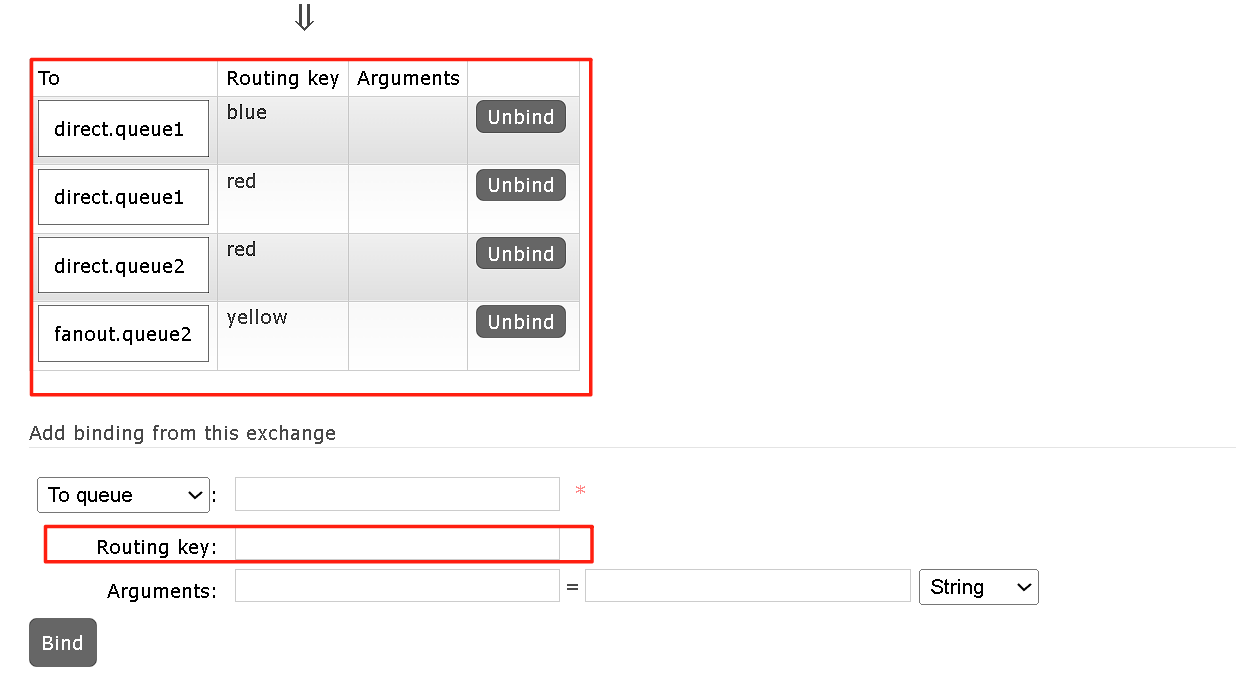
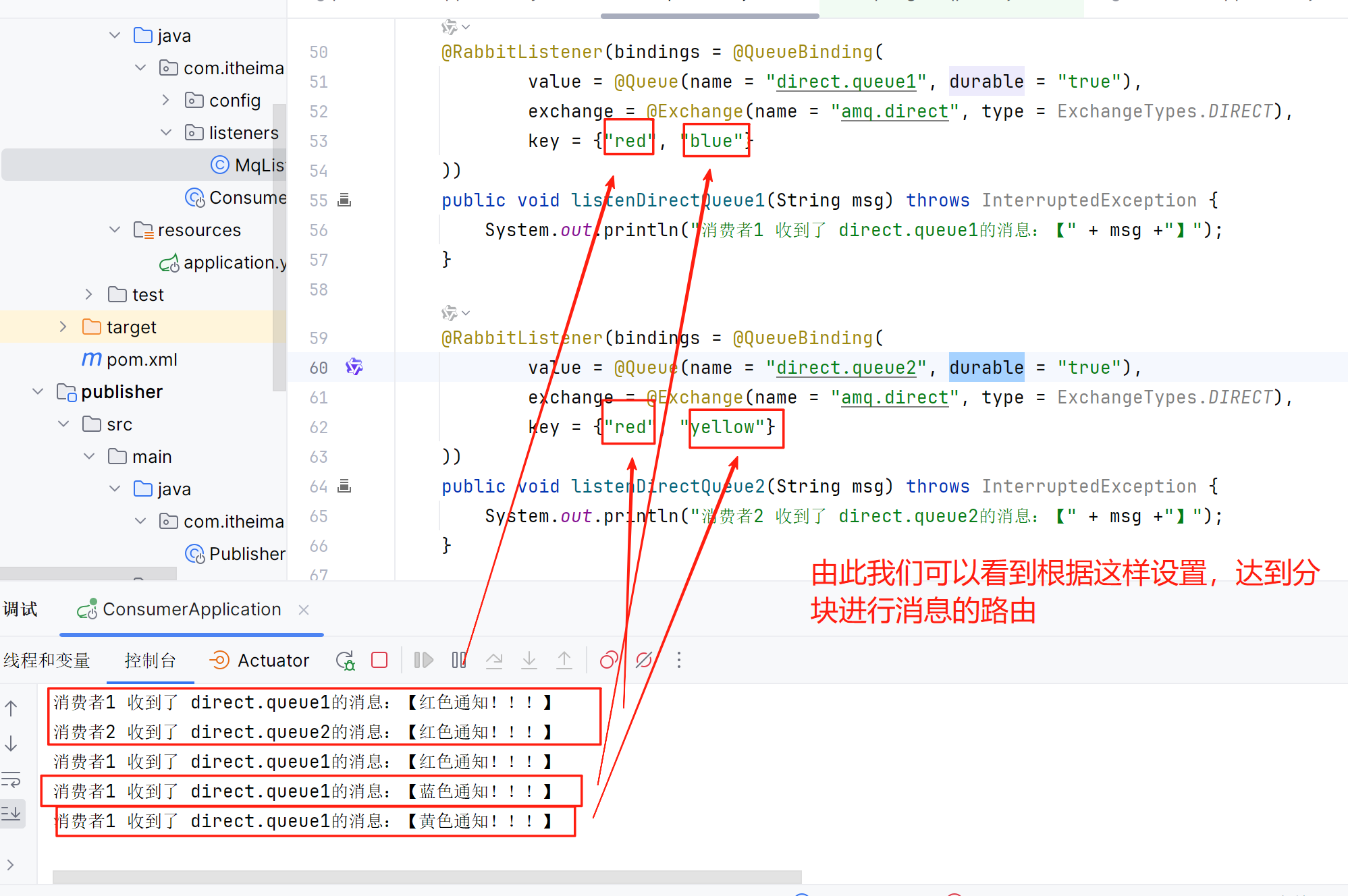
当我们这样简历路由键之后,就可以发现,在不同的路由键情况下,监听到的消息是不一样的。
由于我们监听的窗口增加了不少,所以就需要这样设置
@Testvoid testSendDirect() {String exchangeName = "amq.direct";String msg = "黄色通知!!!";rabbitTemplate.convertAndSend(exchangeName, "blue", msg);}
-----------------------------------------------------------------------
@RabbitListener(bindings = @QueueBinding(value = @Queue(name = "direct.queue1", durable = "true"),exchange = @Exchange(name = "amq.direct", type = ExchangeTypes.DIRECT),key = {"red", "blue"}
))
public void listenDirectQueue1(String msg) throws InterruptedException {System.out.println("消费者1 收到了 direct.queue1的消息:【" + msg +"】");
}
@RabbitListener(bindings = @QueueBinding(value = @Queue(name = "direct.queue2", durable = "true"),exchange = @Exchange(name = "amq.direct", type = ExchangeTypes.DIRECT),key = {"red", "yellow"}
))
public void listenDirectQueue2(String msg) throws InterruptedException {System.out.println("消费者2 收到了 direct.queue2的消息:【" + msg +"】");
}
描述下Direct交换机与Fanout交换机的差异?
-
Fanout交换机将消息路由给每一个与之绑定的队列
-
Direct交换机根据RoutingKey判断路由给哪个队列
-
如果多个队列具有相同的RoutingKey,则与Fanout功能类似
Topic交换机
Topic类型的Exchange与Direct相比,都是可以根据RoutingKey把消息路由到不同的队列。 只不过Topic类型Exchange可以让队列在绑定BindingKey 的时候使用通配符!
BindingKey 一般都是有一个或多个单词组成,多个单词之间以.分割,例如: item.insert
通配符规则:
-
#:匹配一个或多个词 -
*:匹配不多不少恰好1个词
也就是说topic交换机将生产者发送来的信息,根据绑定的Routing key进行模糊的匹配。
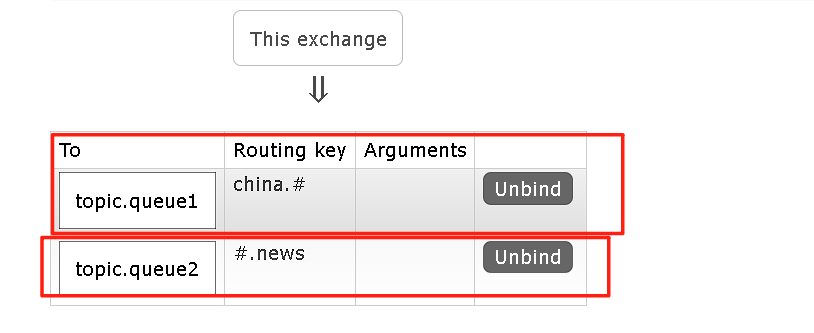
所以当我们发送消息之后就可以得到
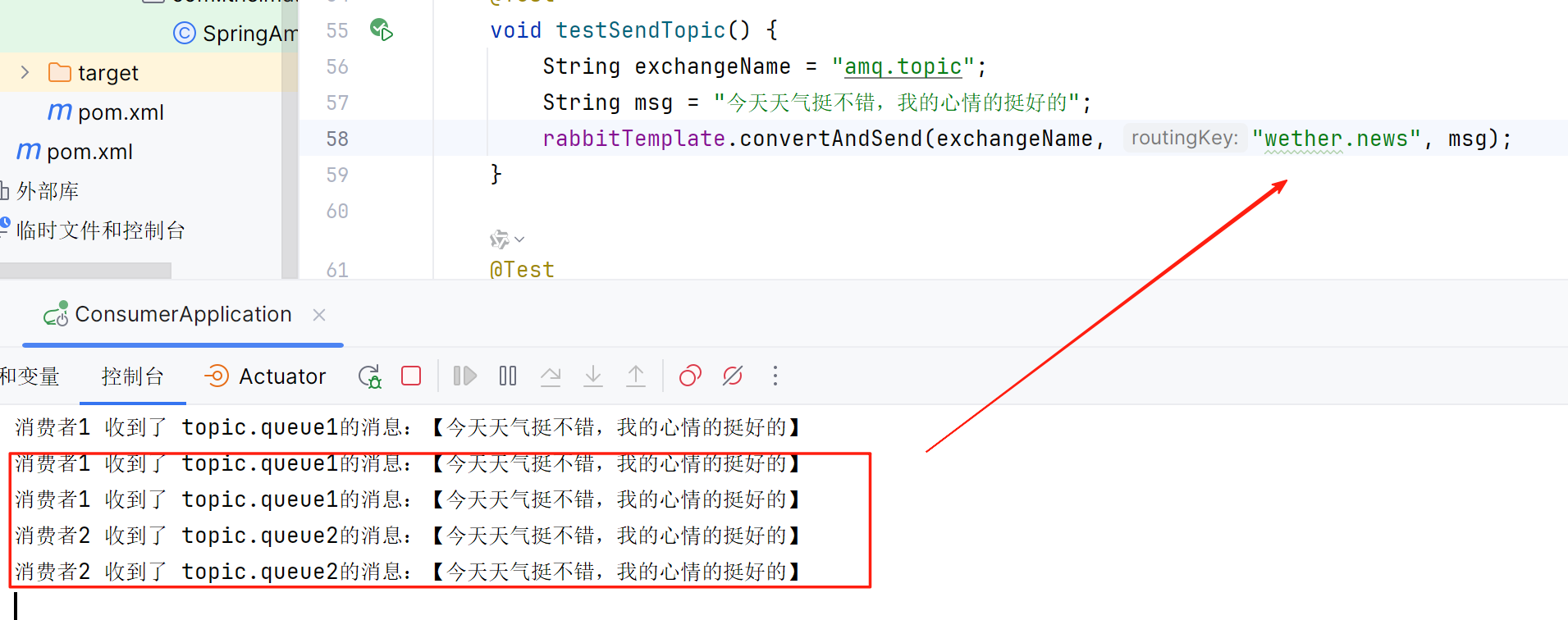
描述下Direct交换机与Topic交换机的差异?
-
Topic交换机接收的消息RoutingKey必须是多个单词,以
**.**分割 -
Topic交换机与队列绑定时的bindingKey可以指定通配符
-
#:代表0个或多个词 -
*:代表1个词
声明交换机和队列
在之前我们都是基于RabbitMQ控制台来创建队列、交换机。但是在实际开发时,队列和交换机是程序员定义的,将来项目上线,又要交给运维去创建。那么程序员就需要把程序中运行的所有队列和交换机都写下来,交给运维。在这个过程中是很容易出现错误的。因此推荐的做法是由程序启动时检查队列和交换机是否存在,如果不存在自动创建。
SpringAMQP提供了一个Queue类,用来创建队列:

SpringAMQP还提供了一个Exchange接口,来表示所有不同类型的交换机:
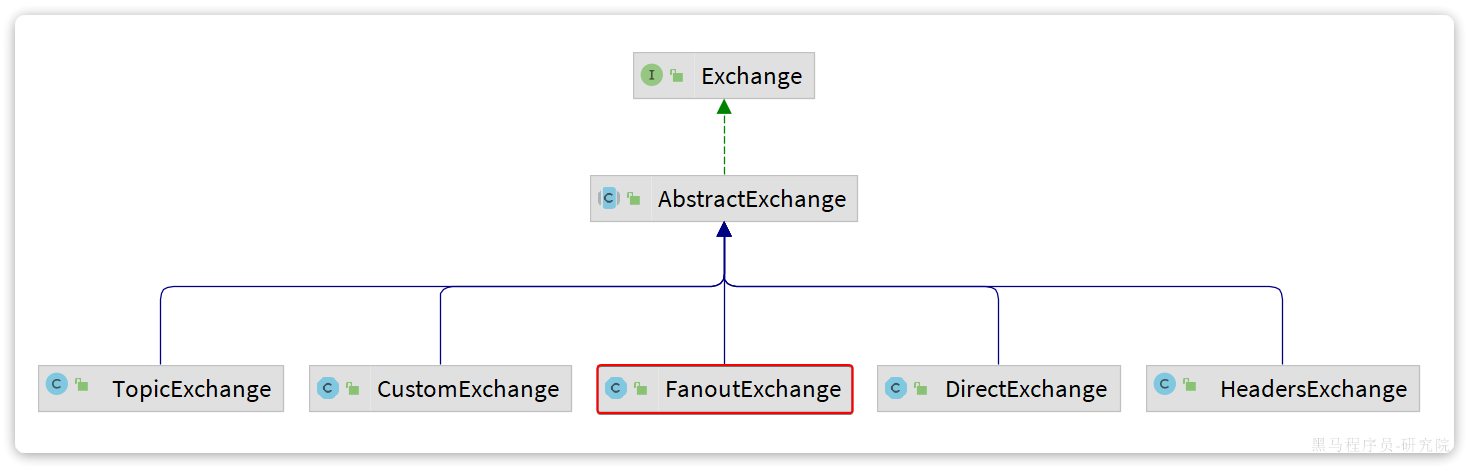
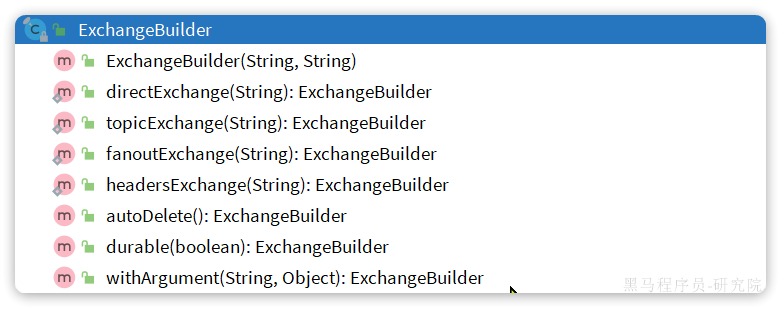
我们可以自己创建队列和交换机,不过SpringAMQP还提供了ExchangeBuilder来简化这个过程:
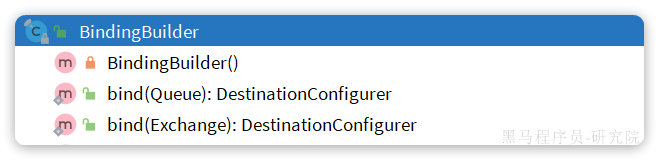
而在绑定队列和交换机时,则需要使用BindingBuilder来创建Binding对象:
我们进行交换机和队列的声明只需要,进行简单的配置,就可以调制出一个fanout交换机。
注意!!!
当我们通过代码实现交换机的时候,Rabbit MQ是绝对禁止使用amq.这样的前缀实现加换机声明的,主要原因是因为以amq.开头的名称仅供内部使用,用户不得创建此类exchange。
@Configuration
public class FanoutConfiguration {
@Beanpublic FanoutExchange fanoutExchange(){return new FanoutExchange("kang.fanout2");}
@Beanpublic Queue fanoutQueue3(){// QueueBuilder.durable("ff").build();return new Queue("fanout.queue3");}
@Beanpublic Binding fanoutBinding3(Queue fanoutQueue3, FanoutExchange fanoutExchange){return BindingBuilder.bind(fanoutQueue3).to(fanoutExchange);}
@Beanpublic Queue fanoutQueue4(){return new Queue("fanout.queue4");}
@Beanpublic Binding fanoutBinding4(){return BindingBuilder.bind(fanoutQueue4()).to(fanoutExchange());}
}direct示例
direct模式由于要绑定多个KEY,会非常麻烦,每一个Key都要编写一个binding:
@Configuration
public class DirectConfiguration {
@Beanpublic DirectExchange directExchange(){return new DirectExchange("KANG.direct");}
@Beanpublic Queue directQueue1(){return new Queue("direct.queue1");}
@Beanpublic Binding directQueue1BindingRed(Queue directQueue1, DirectExchange directExchange){return BindingBuilder.bind(directQueue1).to(directExchange).with("red");}
@Beanpublic Binding directQueue1BindingBlue(Queue directQueue1, DirectExchange directExchange){return BindingBuilder.bind(directQueue1).to(directExchange).with("blue");}
@Beanpublic Queue directQueue2(){return new Queue("direct.queue2");}
@Beanpublic Binding directQueue2BindingRed(Queue directQueue2, DirectExchange directExchange){return BindingBuilder.bind(directQueue2).to(directExchange).with("red");}以上就是基于代码实现,我们也可以基于注解进行实现。
基于@Bean的方式声明队列和交换机比较麻烦,Spring还提供了基于注解方式来声明。
例如,我们同样声明Direct模式的交换机和队列:
@RabbitListener(bindings = @QueueBinding(value = @Queue(name = "direct.queue4", durable = "true"),exchange = @Exchange(name = "amq.direct", type = ExchangeTypes.DIRECT),key = "red"
))
public void listenDirectQueue4(String msg) throws InterruptedException {System.out.println("消费者4 收到了 direct.queue4的消息:【" + msg +"】");
}是不是简单多了。
@RabbitListener(bindings = @QueueBinding(value = @Queue(name = "topic.queue3", durable = "true"),exchange = @Exchange(name = "amq.topic", type = ExchangeTypes.TOPIC),key = "user.#"
))public void listenTopicQueue3(String msg) throws InterruptedException {System.out.println("消费者3 收到了 topic.queue3的消息:【" + msg +"】");
}消息转换器
Spring的消息发送代码接收的消息体是一个Object:
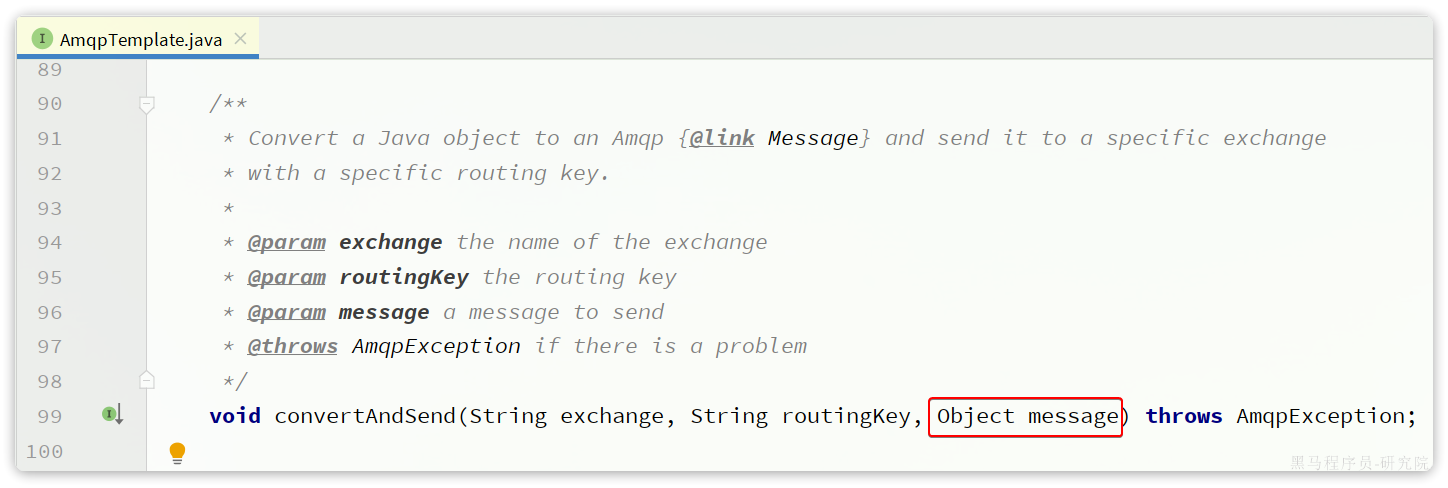
而在数据传输时,它会把你发送的消息序列化为字节发送给MQ,接收消息的时候,还会把字节反序列化为Java对象。 只不过,默认情况下Spring采用的序列化方式是JDK序列化。众所周知,JDK序列化存在下列问题:
-
数据体积过大
-
有安全漏洞
-
可读性差
我们进行测试一下,声明一个测试类。
@Test
void testSendObject() {Map<String, Object> msg = new HashMap<>(2);msg.put("name", "jack");msg.put("age", 21);rabbitTemplate.convertAndSend("object.queue", msg);
}发送到控制台之后可以进行查看。
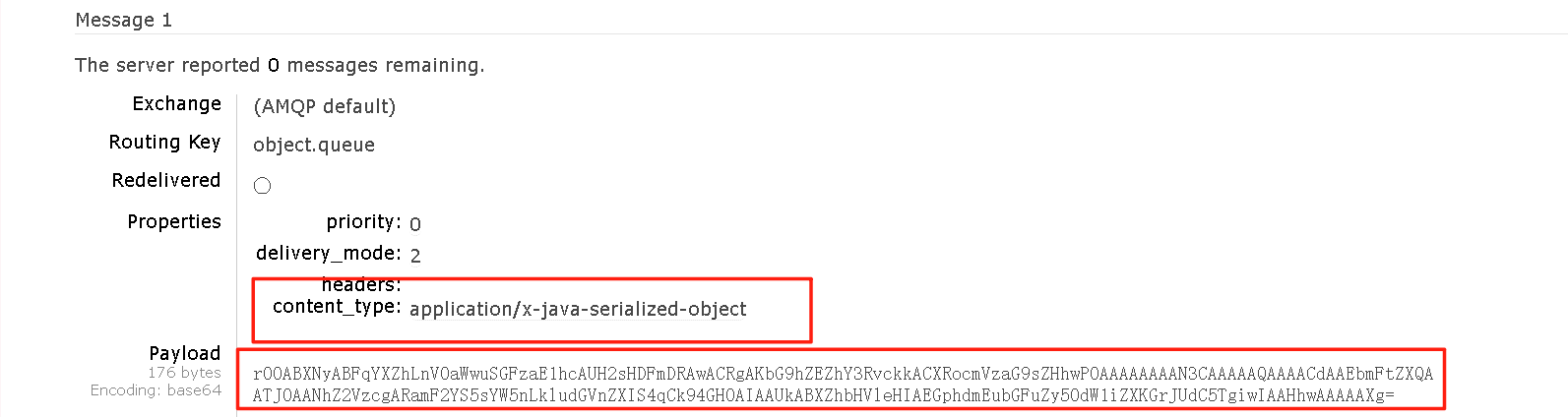
可以看到,JDK序列化方式并不合适,信息的体积过大,而且可读性较差,因此我们可以通过JSON的方式进行序列化和反序列化。
在publisher和consumer两个服务中都引入依赖:
<dependency><groupId>com.fasterxml.jackson.dataformat</groupId><artifactId>jackson-dataformat-xml</artifactId><version>2.9.10</version>
</dependency>注意,如果项目中引入了spring-boot-starter-web依赖,则无需再次引入Jackson依赖。
配置消息转换器,在publisher和consumer两个服务的启动类中添加一个Bean即可:
@Bean
public MessageConverter messageConverter(){// 1.定义消息转换器Jackson2JsonMessageConverter jackson2JsonMessageConverter = new Jackson2JsonMessageConverter();// 2.配置自动创建消息id,用于识别不同消息,也可以在业务中基于ID判断是否是重复消息jackson2JsonMessageConverter.setCreateMessageIds(true);return jackson2JsonMessageConverter;
}消息转换器中添加的messageId可以便于我们将来做幂等性判断。
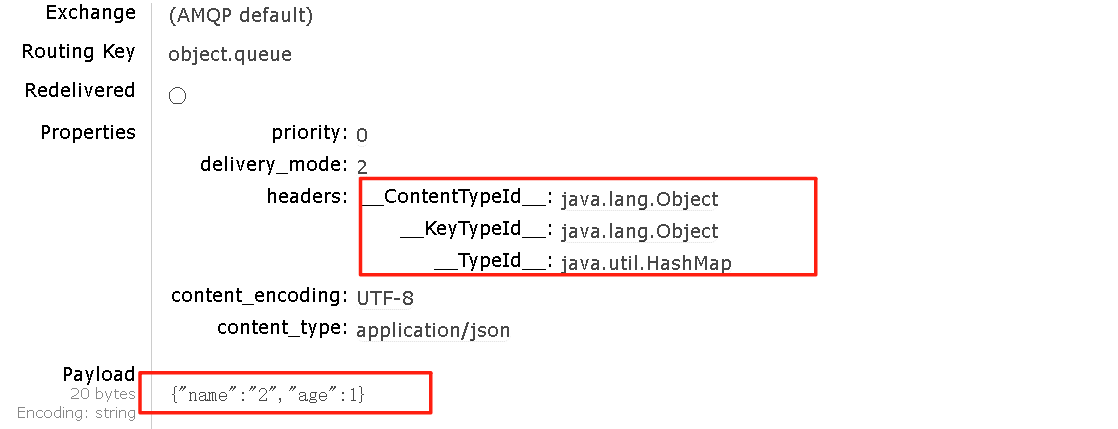
我们在consumer服务中定义一个新的消费者,publisher是用Map发送,那么消费者也一定要用Map接收,格式如下:
@RabbitListener(queues = "object.queue")
public void listenSimpleQueueMessage(Map<String, Object> msg) throws InterruptedException {System.out.println("消费者接收到object.queue消息:【" + msg + "】");
}