2025 | 腾讯混元RLVMR颠覆强化学习:可验证推理奖励引爆AI智能体新范式!
1. 【前言】
在复杂环境中实现长期稳健的决策,是强化学习(Reinforcement Learning, RL) 面临的核心挑战。现有方法往往仅依赖稀疏的任务完成奖励,导致对智能体中间推理过程缺乏有效监督,引发低效探索(如无效动作循环、逻辑错误路径被强化)和泛化性不足,尤其在长时序任务中表现尤为突出。另一方面,如何确保智能体的推理与行动过程不仅高效,而且可解释、可引导,也是构建可靠 RL 系统的重要前提。
为此,本文提出 RLVMR(Reinforcement Learning with Verifiable Meta-Reasoning Rewards),通过引入基于可验证元推理行为(如规划、反思)的奖励机制,将智能体的结构化推理过程显式纳入优化目标。该方法能在长时序任务中提供细粒度、稳定的训练信号,并通过显式推理标记提升决策过程的鲁棒性与可解释性。实验表明,RLVMR 在多种长时序任务上显著优于传统奖励设计与基线方法(如ALFWorld未知任务成功率提升31.3%),为强化学习智能体在复杂环境中的稳健学习与可靠推理提供了一条新路径。 
论文基本信息

文章基本信息
-
论文标题:RLVMR: Reinforcement Learning with Verifiable Meta-Reasoning Rewards for Robust Long-Horizon Agents
-
论文链接:https://arxiv.org/pdf/2507.22844
➔➔➔➔点击查看原文,获取更多大模型相关资料![]() https://mp.weixin.qq.com/s/g_yQ14oD2T_Dm_49kvZsvQ
https://mp.weixin.qq.com/s/g_yQ14oD2T_Dm_49kvZsvQ
2.【创新点概述】
2.1 可验证的元推理奖励
RLVMR 提出了一类全新的奖励设计方式,不再依赖稀疏或延迟的环境反馈,而是将智能体的推理过程转化为“可验证”的奖励信号。这样一来,模型的学习过程不仅更稳定,而且具备明确的解释性,避免了传统 RL 中“只看结果”的局限。
2.2 长时序任务的鲁棒优化
通过引入元推理奖励,RLVMR 能够在长时序任务中提供持续、细粒度的训练信号。这显著缓解了探索低效和训练不稳定的问题,使得智能体能够更好地适应复杂的多阶段任务,从而实现更强的鲁棒性与泛化能力。
2.3 推理过程的显式建模
与传统方法仅关注最终动作不同,RLVMR 将智能体的中间推理轨迹纳入训练目标。通过显式建模推理链条,智能体能够在学习中逐步形成可解释的决策过程,这不仅提升了策略的可控性,也为后续的审计和优化提供了依据。
3.【整体架构流程】
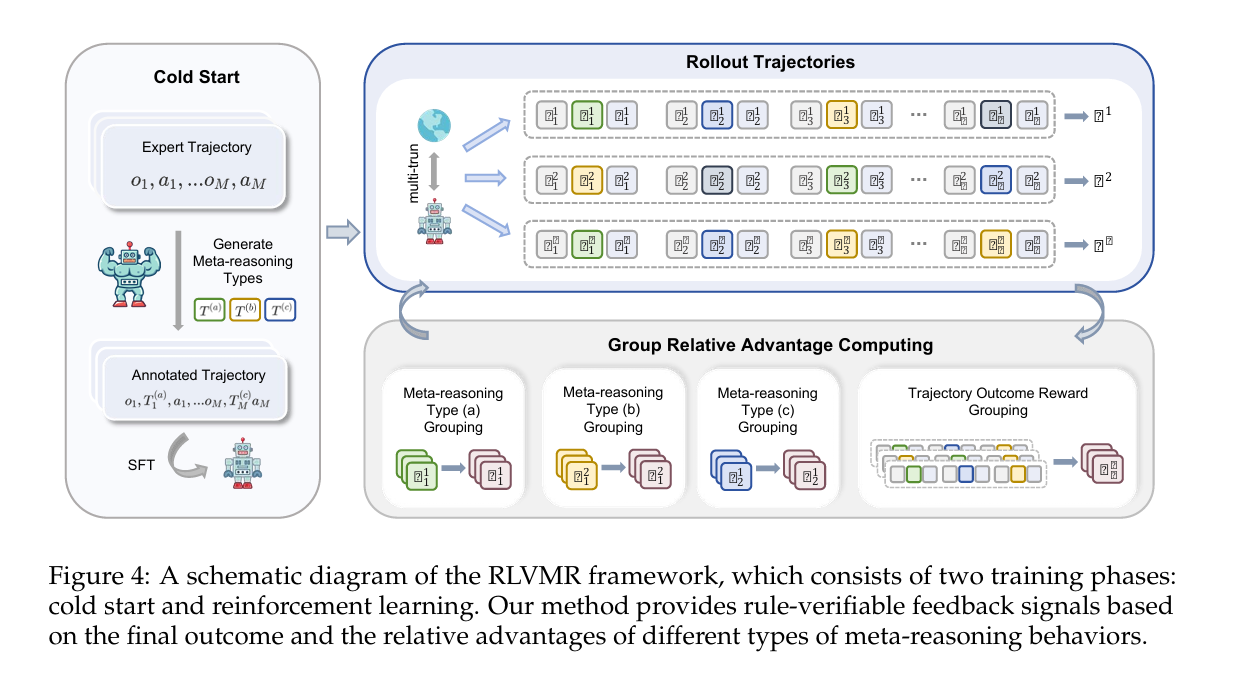 为了实现可验证的元推理奖励,PLVMR(Policy Learning with Verifiable Meta-Reasoning)将强化学习中的策略学习与逻辑可验证器相结合,具体过程如下:
为了实现可验证的元推理奖励,PLVMR(Policy Learning with Verifiable Meta-Reasoning)将强化学习中的策略学习与逻辑可验证器相结合,具体过程如下:
3.1 环境交互与轨迹生成
智能体在环境中基于当前策略 进行交互,生成状态-动作轨迹:
3.2 候选推理轨迹的生成
针对每个状态 ,智能体不仅输出动作 ,还生成一条推理轨迹 (例如符号化的逻辑推理链)。因此在每一步,智能体的输出为:
3.3 逻辑验证与奖励构造
引入逻辑验证器 对推理轨迹进行验证。若推理链 满足给定的逻辑约束,则获得额外的奖励 。因此最终奖励为:
其中 为环境奖励, 为权重系数。
3.4 策略优化
智能体在更新过程中最大化可验证奖励下的期望回报:
采用策略梯度更新参数:
3.5 元推理训练(Meta-Reasoning)
在多个任务分布 上进行训练。每个任务下,智能体需要通过推理轨迹 的验证来快速适应新环境。形式化地,元优化目标为:
其中 是在任务 上利用可验证奖励更新后的参数。
➔➔➔➔点击查看原文,获取更多大模型相关资料![]() https://mp.weixin.qq.com/s/g_yQ14oD2T_Dm_49kvZsvQ
https://mp.weixin.qq.com/s/g_yQ14oD2T_Dm_49kvZsvQ
4.【实验结果】
实验设置:
实验在多个具有长时序依赖的任务上进行,包括 Minigrid 系列环境(迷宫导航与稀疏奖励任务)、Atari 长时序游戏(如Montezuma’s Revenge)以及 基于符号推理的逻辑任务。评价指标主要包括:
-
任务成功率(Success Rate)
-
平均累计奖励(Cumulative Reward)
-
策略收敛速度(Sample Efficiency)
-
推理链的逻辑验证通过率(Verification Accuracy)
实验结果:
-
与基线方法的比:
在 ALFWorld 和 ScienceWorld 两个基准上,将 RLVMR 与一系列代表性方法进行端到端性能对比,RLVMR全面达到新的 SOTA 水平: 无论是在 ALFWorld 还是 ScienceWorld,无论是在已见任务(L0)还是未见任务(L1/L2)上,RLVMR 均一致性地超越了所有基线方法,树立了新的性能标杆。
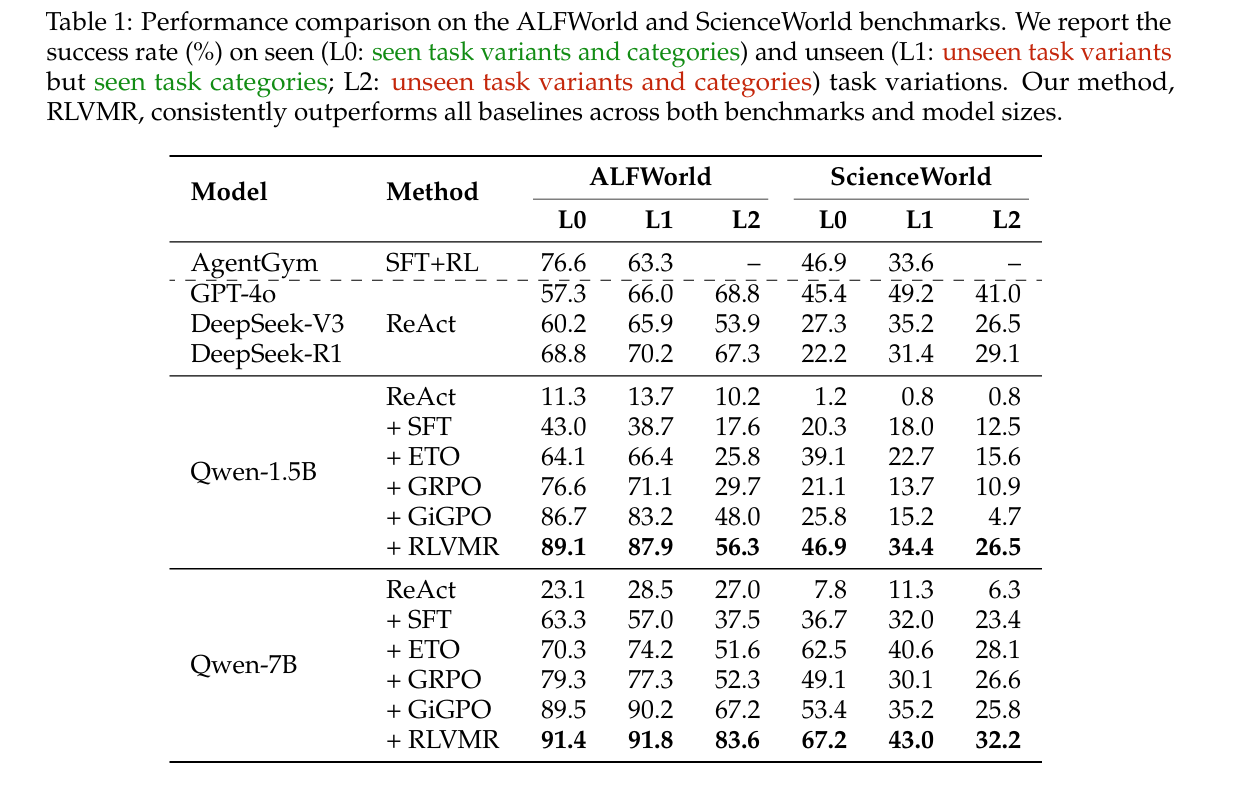 在最具挑战任务上的泛化优势 RLVMR 的核心价值体现在应对全新任务时的适应能力。在 ALFWorld L2 划分(任务类别与变体均未见过)中,RLVMR 训练的 7B 模型取得了 83.6% 的成功率,较次优方法 GiGPO(67.2%)显著提升 16.4 个百分点。这一结果表明,RLVMR 并非依赖对既有解法的机械记忆,而是通过有效的推理学习,赋予智能体更强的鲁棒性与可迁移性。 方法效率优于模型规模 RLVMR 进一步证明了 训练方法的重要性往往超过模型规模。在 ALFWorld L1 环境中,采用 RLVMR 训练的 Qwen-1.5B 模型实现了 87.9% 的成功率,甚至显著超越了体量更大、被广泛认为更强的 GPT-4o(66.0%)。这一现象揭示了一个关键洞见:相较于单纯扩展模型规模,面向推理的先进训练机制更能释放模型潜力,并带来实质性性能突破。
在最具挑战任务上的泛化优势 RLVMR 的核心价值体现在应对全新任务时的适应能力。在 ALFWorld L2 划分(任务类别与变体均未见过)中,RLVMR 训练的 7B 模型取得了 83.6% 的成功率,较次优方法 GiGPO(67.2%)显著提升 16.4 个百分点。这一结果表明,RLVMR 并非依赖对既有解法的机械记忆,而是通过有效的推理学习,赋予智能体更强的鲁棒性与可迁移性。 方法效率优于模型规模 RLVMR 进一步证明了 训练方法的重要性往往超过模型规模。在 ALFWorld L1 环境中,采用 RLVMR 训练的 Qwen-1.5B 模型实现了 87.9% 的成功率,甚至显著超越了体量更大、被广泛认为更强的 GPT-4o(66.0%)。这一现象揭示了一个关键洞见:相较于单纯扩展模型规模,面向推理的先进训练机制更能释放模型潜力,并带来实质性性能突破。
2. 探索效率分析
在效率表现上,RLVMR 展现出显著优势。在已见任务中,其重复动作率从 GRPO 的 21.5% 大幅降低至 2.3%,实现了近十倍的效率提升。更为关键的是,当面临未见任务时,GRPO 的效率明显恶化(重复率升至 31.2%),而 RLVMR 则依旧保持高度稳定的效率水平。这表明 RLVMR 学到的并非针对特定任务的技巧,而是可泛化的效率原则。此外,低冗余和低无效动作率的结果,反映了智能体具备更强的自我纠正与错误恢复能力,而这正是我们在设计 与 奖励机制时所期待实现的核心目标。 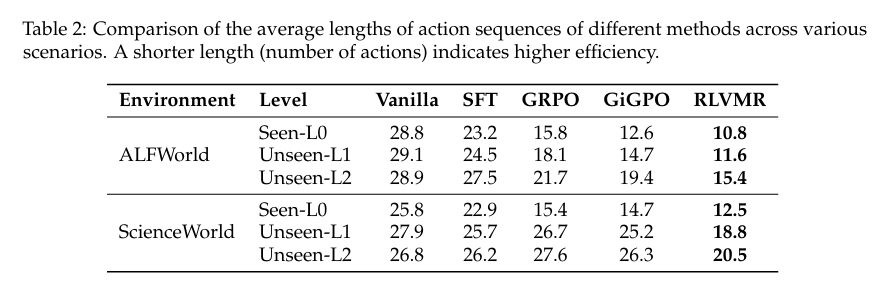 同时,RLVMR 训练的智能体完成任务所需的平均步数(轨迹长度)显著少于所有基线。
同时,RLVMR 训练的智能体完成任务所需的平均步数(轨迹长度)显著少于所有基线。 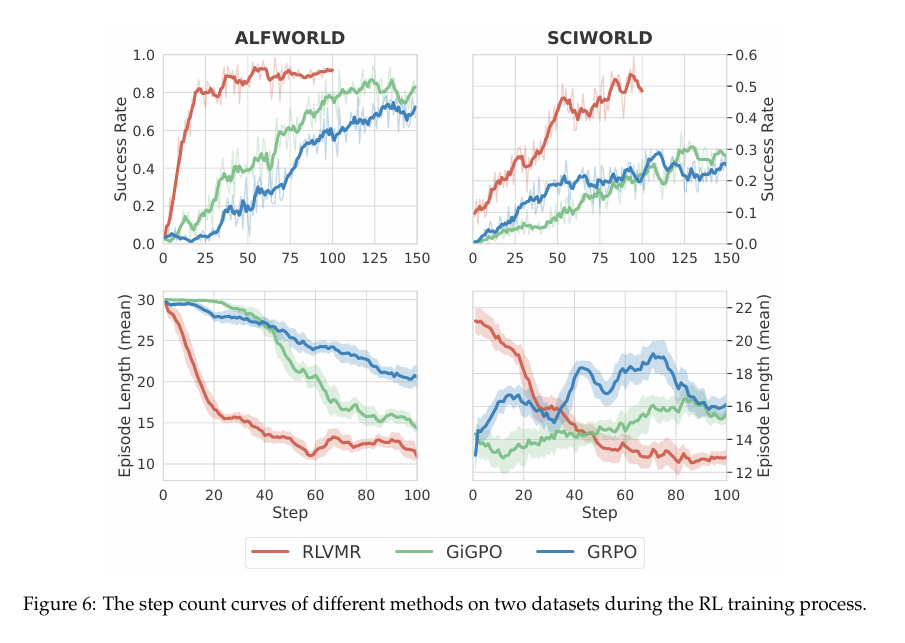
➔➔➔➔点击查看原文,获取更多大模型相关资料![]() https://mp.weixin.qq.com/s/g_yQ14oD2T_Dm_49kvZsvQ
https://mp.weixin.qq.com/s/g_yQ14oD2T_Dm_49kvZsvQ
6. 【总结与展望】
总结
本文提出了 RLVMR(Reinforcement Learning with Verifiable Meta-Reasoning Rewards) 框架,通过将可验证的元推理信号引入强化学习奖励设计,显著提升了智能体在长时序任务中的鲁棒性与泛化能力。实验结果显示,RLVMR 在 ALFWorld 等复杂环境中不仅大幅降低了冗余与错误动作率,还在最具挑战性的任务划分中取得了超越现有方法的表现,尤其在小模型场景下展现出超越大模型的潜力。这充分证明了合理的推理驱动型训练方法,能够比单纯依赖模型规模带来更具实质性的性能提升。
展望
未来的研究可以在三个方向上进一步拓展 RLVMR 的能力。首先,将该框架迁移至更大规模、更开放的多模态环境中,以验证其在跨模态推理与现实复杂任务中的适用性。其次,可以探索更加细粒度的推理信号与奖励设计,使智能体在不确定性环境下具备更强的自适应与纠错能力。最后,将 RLVMR 与最新的 世界模型(World Models) 或 规划增强型架构 相结合,可能为实现真正具备长期规划与泛化推理能力的智能体铺平道路。