一起Oracle 19c bug 导致的业务系统超时问题分析
一、故障概况
1、2025年X月XX日07:36至09:26期间,业务系统无法连接数据库。经查,数据库节点2日志报错“checkpoint not complete”,且数据库出现大量GC等待事件,同时活动连接会话数达到阈值上限。后续通过终止(Kill)会话,业务连接逐步恢复。
2、10:19至11:38期间,该故障再次发生。此阶段部分业务仍可访问。为缓解数据库压力,现场数据库运维人员手动终止(KILL SESSION)了部分空闲(用户连接为空)的会话。同时,与业务方沟通确认当前可用功能是否满足紧急需求。由于数据库状态未能完全恢复,最终决定重启数据库实例2。重启后,数据库资源得以释放,业务恢复正常。
二、处理过程
1、07:45,现场数据库运维人员收到告警:数据库实例1中出现大量“gc buffer busy”等待事件。初步分析,怀疑与业务侧存在大量批量作业或高并发请求有关。
2、08:22 ,现场数据库运维人员收到数据库实例2 DOWN告警短信。
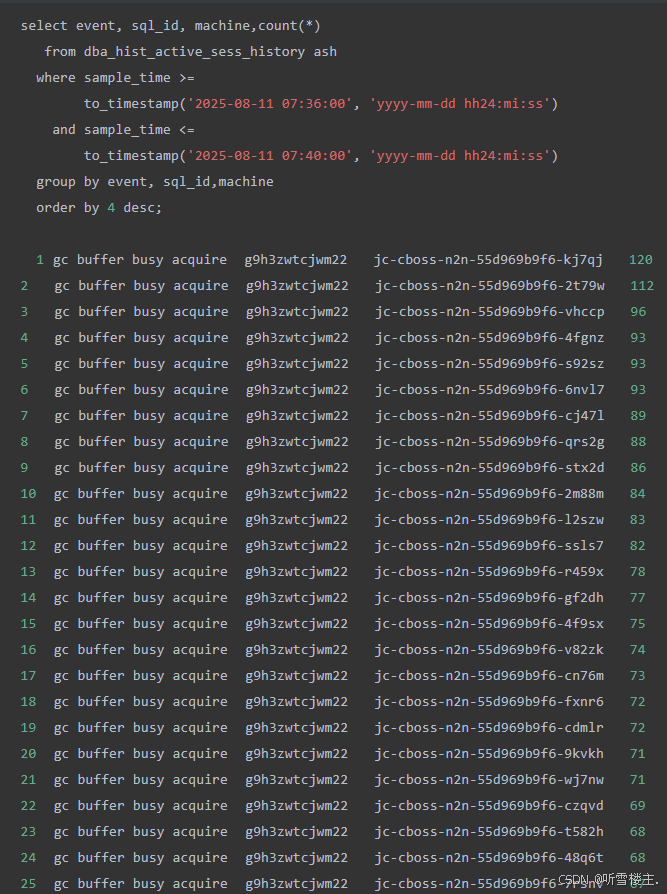
3、08:46,运维人员核查数据库状态,发现其活动会话数(Active Sessions)显著高于历史峰值。同时,数据库内等待事件计数已超过28,000次。上述情况导致数据库响应严重延迟,进而引发应用程序连接数据库失败。
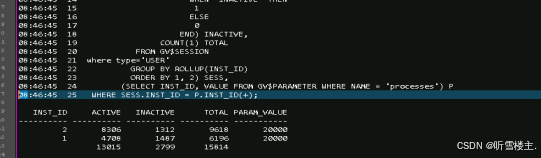
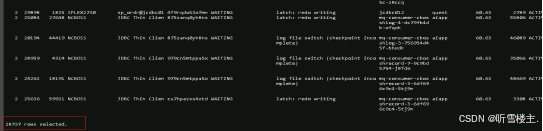
4、同时核查数据库日志报错:ORA-00020: maximum number of processes (20000) exceeded。
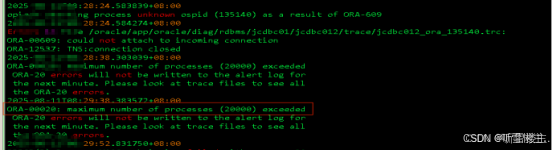
5、08:54,现场数据库运维人员与业务方及负责人达成共识:优先尝试终止(KILL SESSION)数据库会话以降低连接数。 但由于活动会话数量庞大,手动终止效率低下且难以彻底清理,运维人员遂与负责人及业务方再次确认后,决定采取更彻底的方案:停止数据库监听器(Listener),在操作系统层面对残留的数据库进程执行强制终止(kill -9)。此操作旨在彻底中断所有客户端连接并清理残留进程。
6、09:26,会话清理及监听器重启操作完成,业务连接逐步恢复。
7、10:19,该故障现象(业务无法连接数据库)重现。
8、10:25,运维人员核查确认,数据库再次出现活动会话数激增与等待事件堆积情况,导致应用程序无法建立数据库连接。
9、10:30,尝试手动终止(KILL SESSION)会话的操作已无法有效缓解故障状态。
10、10:34,运维人员发现无法通过安全方式(SHUTDOWN IMMEDIATE)停止数据库实例2,实例卡滞在 未完成状态。
11、11:21,对数据库使用abort方式对实例进行重启;
12、11:28 业务数据库实例2节点重启完成,业务陆续恢复正常。

三、问题分析
13:01,现场数据库运维人员组织多位二线专家,从网络、硬件、操作系统、数据库及近期业务量等多个维度协同排查故障根源。
1、14:41,初步排查结果显示:
(1)主机(硬件/OS)层面: 故障时段无异常。
(2)网络层面: 未观测到丢包或重传现象。
(3)操作系统日志(message/oswbb): 无异常记录。
(4)业务量层面: 近期业务量无异常,且较前期有所下降。
2、15:30,运维团队聚焦分析故障时段数据库会话信息,发现存在大量异常等待事件,包括:(gc buffer busy acquire、row cache lock、latch: ges resource hash list、latch: cache buffers chains、enq:SQ contention)追溯相关SQL,发现均为业务INSERT语句。
3、16:41,鉴于上述异常等待事件的关联性及典型性,团队判断MOS(My Oracle Support)可能存在相关案例。随即在MOS平台基于关键等待事件进行检索与分析,比对故障现象一致性。
4、17:15,在MOS上定位到与故障现象高度吻合的技术文档。进一步核查数据库节点2的跟踪日志(jcdbc012_dbw9_170054.trc),发现其内容与该MOS文档描述一致。由此初步判定故障由特定BUG触发:BUG详情: RAC Database Hang - DBWriter Process Hung On Chain 'rdbms ipc message'<='log file switch (checkpoint incomplete)' (Doc ID 3038301.1)该结论需由Oracle原厂工程师进行最终确认。
5、01:20,经原厂确认触发了Oracle bug-36158900(RAC Database Hang - DBWriter Process Hung On Chain 'rdbms ipc message'<='log file switch (checkpoint incomplete)' (Doc ID 3038301.1)),导致Dirty Buffer写出的权限处理机制的问题。
BUG解释:在某些数据库高负载运行的情况下,数据库核心进程DBWR(Database Writer,负责将数据库内存中被修改的数据块批量写入磁盘数据文件)在进行数据写入时,由于内部序列(sequence)错误不能获取相应的权限(write permission),导致内存中的缓存数据(Dirty Buffer)无法及时写入磁盘,进而引发数据库缓冲区(Buffer Cache)中的脏数据(Dirty Data)堆积。当脏数据无法及时写入磁盘时,将造成数据库性能下降,甚至出现僵死现象。在RAC(Real Application Clusters,数据库集群)环境中,该问题还引发了节点间的资源竞争,加剧系统负载,最终导致CBOSS数据库2个实例均无法提供服务。
四、解决方案及建议
1、短期根治方案:应用Oracle官方补丁
故障根因已定位至特定BUG(Doc ID 3038301.1),该BUG导致RAC环境下DBWR进程僵死,触发级联等待事件。从MOS下载并测试补丁 Patch 3038301,在非生产环境验证兼容性与稳定性。再择机在生产环境中进行补丁升级。
2、长期高可用方案:搭建ADG(Active Data Guard)
构建物理备库实现读写分离,将查询业务引流至备库,降低主库并发压力。主库故障时支持分钟级RTO切换,避免单点风险。
建议:优先实施补丁修复确保系统稳定,同步规划ADG建设并纳入容灾体系。