JAVA文件管理系统:如何玩转文件操作
目录
一. 路径与文件元数据:File类的核心用法
二、Java 文件管理核心基础:从 “路径” 到 “流”
三、文件操作高频面试题
1.Java 中File类和流Stream类的区别是什么?
2.Java 中实现文件的复制?如果文件比较大呢?
3.如何遍历指定目录下的所有文件和子目录?
4.Java 中Serializable接口有什么作用,如何实现对象的序列化和反序列化?
在Java编程中,文件管理是一个至关重要的方面,它直接影响着应用程序的可靠性、安全性和性能。文件管理允许应用程序将数据永久保存在磁盘上,而不仅限于内存中的临时存储。确保数据在程序关闭或系统重启后仍然可用。实现配置信息、用户偏好和应用程序状态的长期保存。有效的文件管理可以防止资源泄漏,确保系统资源得到合理分配和释放,避免因文件处理不当导致的系统性能下降。
文件作为不同应用程序间数据交换的通用媒介,支持多种数据格式(文本、二进制、XML、JSON等)的读写操作,便于与其他系统或平台进行数据集成。良好的文件管理实践是编写健壮、可靠Java应用程序的基础,开发者应当重视文件操作的正确性、效率性和安全性。
一. 路径与文件元数据:File类的核心用法
作为一种类,创建的方式依旧是new对象,并在初始化的时候给出文件路径并给出文件名字,这个路径无需给绝对路径,以./开头就可以在该目录下创建文件。File类中提供了一些方法下面介绍一些常用的:
获取文件名用getName,获取文件的路径是getPath,判断是否可读用canRead,判断是否可写用canWrite,判断是否隐藏用isHidden,创建文件用createNewFile,判断文件是否存在用exists,不想要这样文件了删除就用delete。
现在创建一个文本文件,并查看它的属性。示例代码:
public class fileDemo1 {public static void main(String[] args) throws IOException {File file = new File("./demofile1.txt");file.createNewFile();boolean exist=file.exists();System.out.println(exist);String name=file.getName();String path=file.getPath();long length=file.length();System.out.println(name);System.out.println(path);System.out.println(length);boolean read=file.canRead();boolean write=file.canWrite();boolean hide=file.isHidden();System.out.println(read);System.out.println(write);System.out.println(hide);}
}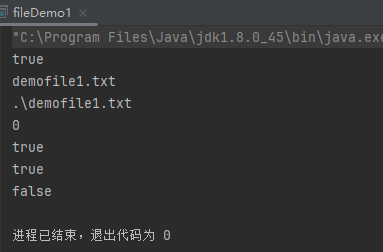
那么就成功在该目录下创建了demofile1这个文本文件,以.txt为后缀时系统会默认他是文本文件
除了文本文件,也可以创建目录,也就是文件夹。
public class MkdirDemo {public static void main(String[] args) {File dir = new File("./a");if(dir.exists()){System.out.println("目录已经存在");}else{dir.mkdirs();System.out.println("创建成功!");}dir.delete();}
}如果想显示目录里面所有的文件名,就可以用文件链表来遍历。每个类型都是File类型的,所以接收的时候也要用个File型的数组来接收。同时也可以将目录下的文件总数打印出来。
public class ListFile {public static void main(String[] args) {File file = new File(".");File[] files=file.listFiles();for(File file1 : files)System.out.println(file1.getName());System.out.println(files.length);}
}
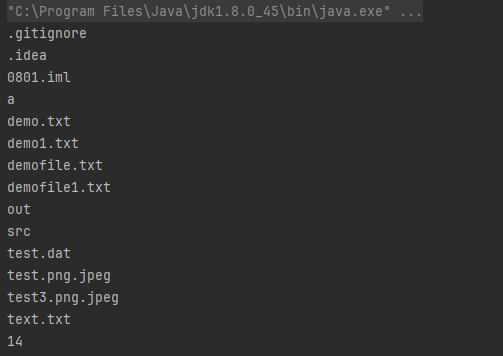
但是如果想在文件里面写内容,File类做不到,只能依靠流。
二、Java 文件管理核心基础:从 “路径” 到 “流”
流(Stream)是Java中处理输入/输出(I/O)操作的核心抽象概念,它代表了一个连续的数据序列,可以从中读取数据或向其中写入数据。流可以被想象为数据的"管道",数据源 → 流 → 程序 (输入流:从数据源读取数据到程序),程序 → 流 → 目的地 (输出流:从程序写入数据到目的地)。
按照功能也可以分为低级流和高级流,低级流也称为节点流,直接连接数据源或目标设备,可以直接操作数据(如文件、内存)。高级流也称处理流或包装流,不直接连接数据源,而是包装在节点流或其他处理流之上,增强功能(如缓冲、转换、序列化等)。常见的处理流有缓冲流(提高读写效率,减少 IO 次数)、转换流(字节流与字符流的转换,可指定编码)、对象流(实现对象的序列化与反序列化)等。
下面向文件写两个数据,并读出它。
public class FOSdemo {public static void main(String[] args) throws IOException {FileOutputStream fops=new FileOutputStream("./test.dat");fops.write(1100);fops.write(-50);fops.close();FileInputStream fips = new FileInputStream("./test.dat");int a=fips.read();int b=fips.read();System.out.println(a);System.out.println(b);fips.close();}
}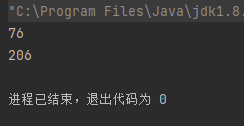
之所以写和读看到的数据完全不同,是因为Java 中byte类型是 8 位有符号整数,取值范围是-128 ~ 127。当使用字节流写入整数时,只会取整数的低 8 位(即一个字节) 进行存储,读取数据时如果读到了-1则说明已经读取到文件末尾。那么1100很明显超过了存储上限,所以我们看到的76也就是1100-1024(1024是2的10次方)。-50的最低八位是11001110,它会被当作无符号字节解读,在它前面默认加24个0,最后也就是206。
不只是数据,甚至连图片和音频也是由诸多二进制组成,不管是常见的 JPEG、PNG、BMP 等格式的图片,在计算机中最终都以二进制形式存储和传输。
图像编辑软件(如 Photoshop)创建或保存图片时,会把视觉信息(像素颜色、位置、透明度等)按照特定格式(如 JPEG 的离散余弦变换、PNG 的 DEFLATE 压缩)编码成二进制。例如,一张 RGB 模式的图片,每个像素的红、绿、蓝颜色分量会被转换成 0~255 的数值(对应 1 个字节,8 位二进制),整幅图的像素数据 + 格式头信息(如文件标识、尺寸、颜色模式等)一起组成二进制文件。当用浏览器或看图软件打开图片时,程序会读取二进制文件,根据文件头识别格式(如 PNG 文件头是 89 50 4E 47 0D 0A 1A 0A 对应的二进制),再按照该格式的解码规则(如解压缩、解析像素数据),把二进制转换回可视化的图像显示出来。
把图片视为一堆二进制数据,来完成一张图片的复制。
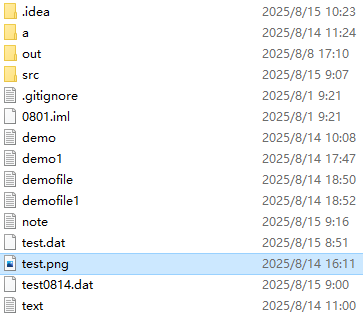

现在本地有一张test.png的图片,想复制到copy.png,因为是从test.png复制过来的,所以应该放到输入流中,输出流就指向复制的路径文件。那么就一个一个读取数据,直到读取到-1就结束。最后不要忘了关闭文件。至于为什么我给文件名的时候.png后面又加上了.jpeg后缀,是因为我开始以为这个图片是.png格式的,但是后面找不到这个文件,然后重新看了下文件属性它其实是.jpeg的图片。所以在在写文件名的时候要先点开它的属性看它到底是什么格式的文件,否则会就找不到。
public class CopyDemo {public static void main(String[] args) throws IOException {FileInputStream f1 = new FileInputStream("./test.png.jpeg");FileOutputStream f2=new FileOutputStream("./copy.png.jpeg");int i;while((i=f1.read())!=-1){f2.write(i);}f1.close();f2.close();}
}
在编译的时候也是等了一段时间,说明它一个字节一个字节的读取还是效率还是太差了,那么我们可以尝试一次性多读一些字节,一次性读10kb,把它放到一个byte型的数组里面再进行读写操作。同时为了更好的比较响应时间,可以分别在读写前后记录时间,然后输出。
public class CopyDemo2 {public static void main(String[] args) throws IOException {FileInputStream fis=new FileInputStream("./test.png.jpeg");FileOutputStream fos=new FileOutputStream("./copy2.png.jpeg");int i;long begin=System.currentTimeMillis();byte[] bytes = new byte[1024*10];while((i= fis.read(bytes))!=-1){fos.write(bytes);}long end=System.currentTimeMillis();System.out.println((double)end-begin);fis.close();fos.close();}
}
像这样一次性读取或写入一组数据(一个"块"),而不是逐字节或逐字符进行操作文件的读写方式是块读写,块读写是Java中一种高效的文件读写方式,它通过减少实际的I/O操作次数来提高性能。这种方式比单字节读写效率高得多,因为它减少了底层I/O操作的次数。
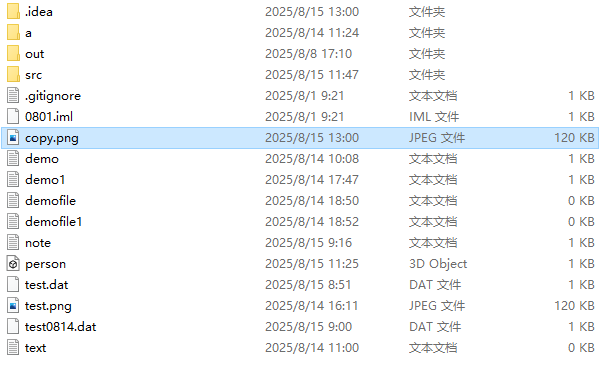
复制完成后,当打开属性面板时,会发现一个细节,原图大小是121870字节,第一次拷贝的图片大小也是121870字节,而第二次拷贝的图片却是122880字节。那为什么只有第二次不一样,而且更大。
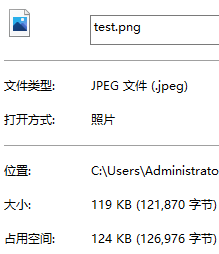
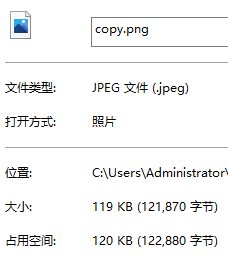
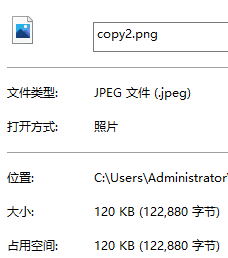
在进行块读写的时候,虽然速度快到起飞,但它永远都是以块为单位在进行读写,哪怕只有一个字节它都会直接读写一整个块。换言之在最后一次读写时,大小不一定刚好等于块的大小,但还是要读写10kb,所以就会有多余部分,多余的数据把他称为脏数据,这也就是为什么copy2要比原图更大的原因了。

为了继续优化,告诉系统在最后一次读写的时候到哪里停止,确保只写入实际读取到的 i 个字节。
public class CopyDemo2 {public static void main(String[] args) throws IOException {FileInputStream fis=new FileInputStream("./test.png.jpeg");FileOutputStream fos=new FileOutputStream("./copy3.png.jpeg");int i;long begin=System.currentTimeMillis();byte[] bytes = new byte[1024*10];while((i= fis.read(bytes))!=-1){fos.write(bytes,0,i);//fos.write(bytes);}long end=System.currentTimeMillis();System.out.println((double)end-(double)begin);fis.close();fos.close();}
}如果想向文件写string字符串,也需要借助流,流只认识二进制,所以在写字符串的时候也需要转为二进制才能写。同时为了能够完成追加写操作,需要在new FileOutputStream的时候给文件名后写上true,表示追加操作为真。
public class WriteString {public static void main(String[] args) throws IOException {FileOutputStream f1=new FileOutputStream("./demo1.txt",true);String s = "一袋米";byte[] b = s.getBytes(StandardCharsets.UTF_8);String line="洗衣机";b=line.getBytes(StandardCharsets.UTF_8);System.out.println(b);f1.write(b);f1.close();}
}如果是自定义类呢?而且自定义类是非常常用的,经常需要把自定义数据保存到硬盘中去,然后又将这个对象传输到另一台计算机上。比如说有个person类里面有名字,年龄,性别还有其他信息。
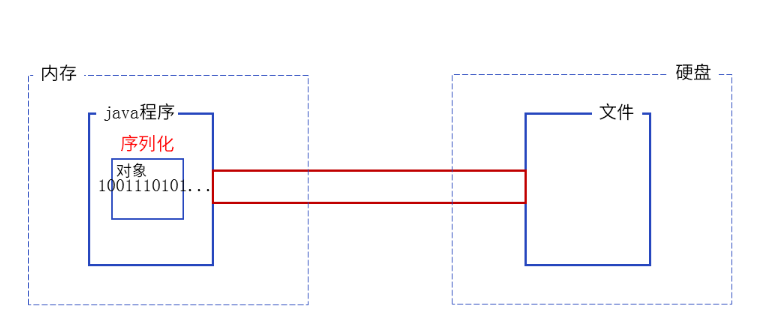
那么自定义类的读写操作就涉及到序列化和反序列化了。将 对象转换成 字节序列 的过程就是序列化,将 字节序列 恢复成 对象的过程就是反序列化,所以将对象写入文件就是要序列化,从文件读取是反序列化。
想要实现序列化和反序列化就需要借助新的流ObjectOutputStream和ObjectInputStream,相当于是对我们的文件输入和输出流进行了一次封装。
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;public class OOSDemo {public static void main(String[] args) throws IOException {String name="小明";int age=22;String gender="男";String[] otherInfo={"music","sleep"};Person person = new Person(name,age,gender,otherInfo);FileOutputStream fos=new FileOutputStream("person.obj");ObjectOutputStream oos=new ObjectOutputStream(fos);oos.writeObject(person);oos.close();}
}import java.io.*;public class OISDemo {public static void main(String[] args) throws IOException, ClassNotFoundException {FileInputStream fis =new FileInputStream("note.txt");ObjectInputStream ois=new ObjectInputStream(fis);Person person = (Person)ois.readObject();System.out.println(person);ois.close();}
}最后关闭高级流就行,无需关闭低级流,这是因为当调用高级流的 close() 时,其默认实现会 递归关闭所有嵌套的底层流。
三、文件操作高频面试题
1.Java 中File类和流Stream类的区别是什么?
File类主要用于操作文件和目录的元数据,如创建、删除、重命名文件或目录,检查文件或目录是否存在,获取文件大小、最后修改时间等,它不涉及文件内容的读写。
Stream类,如InputStream、OutputStream、Reader、Writer及其子类,主要用于文件内容的输入和输出操作。字节流用于处理二进制数据,字符流用于处理文本数据。
2.Java 中实现文件的复制?如果文件比较大呢?
不管是文本、图片还是音频,他们都可以转为二进制然后通过字节流来完成文件的读取和写出。
如果文件比较大,就可以采用块读写的方式,以上已经演示了字符串、数字和图片的复制。
3.如何遍历指定目录下的所有文件和子目录?
可以使用File类结合递归方法来实现。上面已经实现了一个目录下的遍历,也就是不考虑目录里面还有目录的情况,这里还是需要一个File型的数组,不过需要注意,如果是目录,就得进去遍历它。
import java.io.File;public class DirectoryTraversalExample {public static void traverseDirectory(File directory) {if (directory.exists() && directory.isDirectory()) {File[] files = directory.listFiles();if (files != null) {for (File file : files) {if (file.isDirectory()) {traverseDirectory(file);} else {System.out.println("文件路径: " + file.getAbsolutePath());}}}}}public static void main(String[] args) {File directory = new File("指定目录路径");traverseDirectory(directory);}
}4.Java 中Serializable接口有什么作用,如何实现对象的序列化和反序列化?
Serializable接口是一个标记接口,用于表示一个类的对象可以被序列化。序列化是将对象转换为字节流以便存储到文件或在网络上传输,反序列化则是将字节流恢复为对象。序列化和反序列化的例子在上面已经详细说明,因此不再赘述。