CUDA中的基本概念
要学习cuda的同学相信已经对其有一定的了解了,至少直到它是干什么的了。这篇文章主要是对cuda编程中的主要概念进行总结,有了一个大致的轮廓后就好入手了。
异构架构
异构架构即使用CPU和GPU共同进行计算。GPU不能作为一个独立的运行平台(程序无法单独在GPU上运行),它只能作为CPU的一个附属计算加速器。
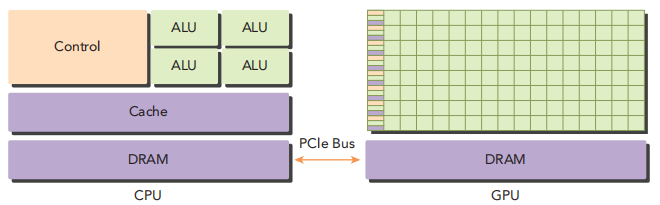
上图展示了异构架构中CPU和GPU的关系。CPU和GPU通过PCIe总线进行数据传输。在碰到计算密集型任务时,CPU将数据传给GPU,GPU计算完成后再传输回CPU。
从上述架构途中也可看出,GPU上有更多的算术逻辑单元,计算能力更强。
主机(host)和设备(device)
由于CPU和GPU的这种从属关系,CPU所在的位置被称为主机端(host),GPU所在位置被称为设备端(device)。在cuda编程中,主机端代码和设备端代码是有严格区分的。核函数的代码只能在GPU上运行。
CUDA中的线程和一般的多线程有什么区别
CPU上的线程是重量级的,上下文切换缓慢且开销较大, 且线程数量往往有限。CPU的线程相对于GPU的线程更适合处理控制密集型任务(多个if-else).
GPU上的线程是轻量级的。现代GPU上可以同时有成千上万个线程并发。GPU的线程更适合控制简单,但是计算密集的任务。
流式多处理器,线程束
GPU架构是围绕流式多处理器(SM)展开的, GPU上有很多个SM,每个SM能够支持数百个线程并发执行,因此在一个GPU上并发执行数千个线程是很容易的。下图所示为一个SM的关键组件(了解即可):
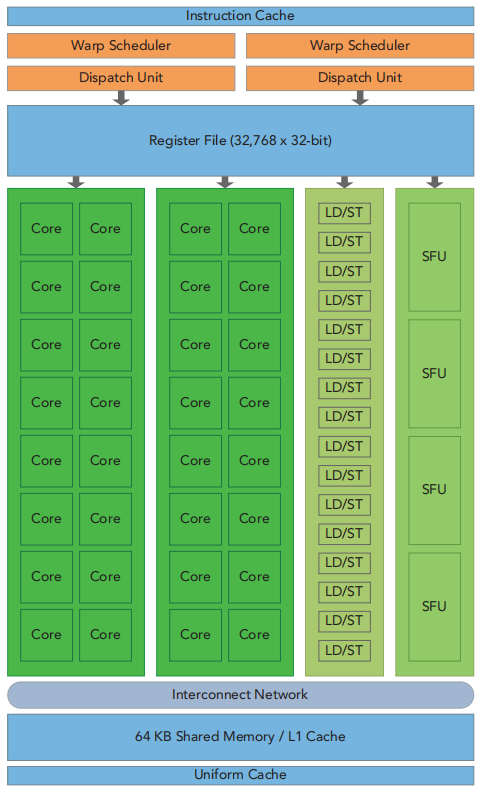
每个SM上有多个线程,每32个线程被组织成一个线程束(thread wrap)。
线程网格,线程块
线程束是物理上线程的划分,但是在cuda编程中,逻辑上更多地是将线程分为不同的线程块(thread block),不同的线程块又分到不同的线程网格(thread grid)中。在编程中,每个在GPU上运行的核函数都要指定线程块和线程网格的维度。线程块和线程网格的维度都可以是一维二维或者三维。
- 区分线程块和线程束
线程束表示的是线程资源。一个线程块可能会占用多个线程束。假设在编程中指定一个线程块中有80个线程,那么这个线程块将占用3个线程束,多出来的线程束将不会活跃,如下图所示:
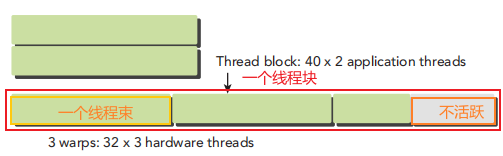
多个线程块在一起将会被组织成网格。
好了,上述就是几个比较重要的概念,后面将直接通过代码来学习cuda。