PaddleOCR从小红书视频中提取字幕并生成思维导图
PaddleOCR从小红书视频中提取字幕并生成思维导图
- 一、项目背景与应用价值
- 技术选型理由
- 二、操作流程
- 1. 创建Docker容器(环境隔离)
- 2. 下载小红书视频
- 3. 字幕提取方案一:OCR图像识别法
- 4. 字幕提取方案二:语音识别法
- 5. 生成思维导图
- 6. 可视化呈现
- 三、技术原理深度解析
- 1、OCR字幕提取核心逻辑
- 2、思维导图生成机制
- 四、常见问题解决方案
- 五、应用场景扩展
本教程展示如何从小红书视频中提取核心内容并生成结构化思维导图
一、项目背景与应用价值
在信息爆炸时代,小红书等平台上的视频内容虽然丰富,但观看完整视频耗时较长。本项目通过技术手段实现:
- 自动提取:直接从视频中提取文字内容
- 智能归纳:将碎片信息整理成结构化知识
- 可视化呈现:生成易于理解的思维导图
- 效率提升:节省90%的信息获取时间
技术选型理由
| 工具 | 作用 | 优势 |
|---|---|---|
| PaddleOCR | 文字识别 | 中文识别准确率高,支持复杂背景 |
| Docker | 环境隔离 | 避免依赖冲突,一键部署 |
| Whisper | 语音转文字 | 支持多语言,识别精度高 |
| DeepSeek | 文本总结 | 语义理解能力强,生成结构化内容 |
二、操作流程
1. 创建Docker容器(环境隔离)
# 拉取预装CUDA的PaddlePaddle镜像
docker pull ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddle:3.1.1-gpu-cuda11.8-cudnn8.9# 启动容器并挂载当前目录
docker run --gpus all --rm -it \-v $PWD:/home ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddle:3.1.1-gpu-cuda11.8-cudnn8.9 /bin/bash# 安装必要工具
apt update
apt install ffmpeg -y
pip install paddleocr
pip install opencv-python-headless
pip install you-get
pip install scikit-image
关键参数解析:
--gpus all:启用GPU加速(OCR处理速度提升5倍)-v $PWD:/home:当前目录映射到容器内/home目录ffmpeg:视频处理的核心工具
2. 下载小红书视频
you-get -O video \"https://www.xiaohongshu.com/explore/689481880000000004005ee6?xsec_token=CBwMuPQcaI0roxLjk35v3RPPE1bqzECrOSgWJZ_iavwAY="
替换URL参数为实际视频地址,小红书视频通常有反爬机制,可能需要添加
xsec_token
3. 字幕提取方案一:OCR图像识别法
cat > video2txt.py <<-'EOF'
import cv2
from paddleocr import PaddleOCR
from PIL import Image
from paddleocr import TextRecognition
import numpy as np
from tqdm import tqdm
from typing import List, Tuple, Optional
from skimage.metrics import structural_similarity as ssimdef vstack_images(images: List[np.ndarray], separator_height: int = 2, separator_color: int = 255) -> np.ndarray:"""垂直堆叠图像,用分隔线隔开参数:images: 需要堆叠的图像列表separator_height: 分隔线高度(像素)separator_color: 分隔线颜色(0-255)返回:堆叠后的图像"""if not images:raise ValueError("输入图像列表不能为空")# 验证所有图像宽度相同widths = {img.shape[1] for img in images}if len(widths) > 1:raise ValueError("所有图像宽度必须相同")width = images[0].shape[1]separator = np.full((separator_height, width, *images[0].shape[2:]), separator_color, dtype=np.uint8)stacked = []for i, img in enumerate(images):stacked.append(img)if i < len(images) - 1:stacked.append(separator)return np.vstack(stacked)def detect_text_region(image: np.ndarray,debug_images: Optional[List[np.ndarray]] = None,min_height: int = 35,max_height: int = 45,text_threshold: int = 210,dilation_kernel1: Tuple[int, int] = (4, 16),dilation_kernel2: Tuple[int, int] = (1, 32)) -> Tuple[int, int, int, int]:"""检测图像中的文本区域参数:image: 输入图像(BGR或灰度)debug_images: 调试图像收集列表(可选)min_height: 文本区域最小高度max_height: 文本区域最大高度text_threshold: 文本二值化阈值dilation_kernel1: 首次膨胀核大小dilation_kernel2: 二次膨胀核大小返回:文本区域坐标(x, y, w, h)"""if image is None or image.size == 0:raise ValueError("输入图像无效")# 转换为灰度图if len(image.shape) == 3:gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)else:gray = image.copy()if debug_images is not None:debug_images.append(gray.copy())# 二值化处理binary = graybinary[binary <text_threshold] = 0if debug_images is not None:debug_images.append(binary.copy())# 形态学操作kernel1 = np.ones(dilation_kernel1, np.uint8)dilated1 = cv2.dilate(binary, kernel1, iterations=1)if debug_images is not None:debug_images.append(dilated1.copy())# 二值化处理dilated1[dilated1!=255] = 0if debug_images is not None:debug_images.append(dilated1.copy())# 二次膨胀处理kernel2 = np.ones(dilation_kernel2, np.uint8)dilated2 = cv2.dilate(dilated1, kernel2, iterations=1)if debug_images is not None:debug_images.append(dilated2.copy())# 连通区域分析num_labels, labels, stats, _ = cv2.connectedComponentsWithStats(dilated2, connectivity=8)center_x = gray.shape[1] // 2candidate_boxes = []# 筛选符合条件的文本区域for i in range(1, num_labels):x = stats[i, cv2.CC_STAT_LEFT]y = stats[i, cv2.CC_STAT_TOP]w = stats[i, cv2.CC_STAT_WIDTH]h = stats[i, cv2.CC_STAT_HEIGHT]if min_height <= h <= max_height:box_center_x = x + w // 2dist_to_center = abs(box_center_x - center_x)candidate_boxes.append((w * h, dist_to_center, (x, y, w, h)))# 选择最佳候选区域if candidate_boxes:# 按面积降序排序candidate_boxes.sort(key=lambda x: x[0], reverse=True)# 取面积最大的前3个区域top_candidates = candidate_boxes[:3]# 按中心距离升序排序top_candidates.sort(key=lambda x: x[1])# 选择最接近中心的区域x, y, w, h = top_candidates[0][2]return (x, y, w, h)# 未找到合适区域return Nonedef compare_images(img1, img2): # 统一调整为相同尺寸(以img1的尺寸为准)img2_resized = cv2.resize(img2, (img1.shape[1], img1.shape[0])) # 计算SSIM(范围[-1, 1],值越大越相似)score, _ = ssim(img1, img2_resized, full=True)return score# 初始化PaddleOCR
ocr = PaddleOCR(use_angle_cls=True, lang='ch') # 使用中文模型# 打开视频文件
video_path = 'video.mp4' # 替换为你的视频路径
cap = cv2.VideoCapture(video_path)# 检查视频是否成功打开
if not cap.isOpened():print("Error: Could not open video file")exit()# 获取视频的宽度和高度
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))# 计算下半部分裁剪区域
start_y = height-120
cropped_height = height - start_y # 裁剪的高度
frame_count=0
save_count=0last_image=None
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
print(total_frames)temp_img_path="tmp.jpg"
progress_bar = tqdm(total=total_frames, desc="处理进度")fo=open("save.txt","w")while True:ret, frame = cap.read()if not ret:breakframe_count+=1progress_bar.update(1)bottom_half = frame[start_y:start_y + cropped_height, 0:width]debug_images=[]box=detect_text_region(bottom_half,debug_images)if box is None:continuex,y,w,h=boximg=cv2.cvtColor(bottom_half[y:y+h, x:x+w],cv2.COLOR_RGB2GRAY)if last_image is not None:score=compare_images(last_image,img)if score>0.10:continuelast_image=img.copy()cv2.imwrite(temp_img_path,img) try:result = ocr.predict(temp_img_path)all_text=""for i in result:all_text+=",".join(i['rec_texts'])if len(all_text)<2:continuefo.write(f"{frame_count:08d}#{all_text}\n")fo.flush()if save_count==10:bottom_half[y:y+h, x:x+w] = 255debug_images.append(cv2.cvtColor(bottom_half, cv2.COLOR_RGB2GRAY))cv2.imwrite("stack.jpg",vstack_images(debug_images))save_count+=1except Exception as e:print(f"帧 {frame_count} 处理出错: {str(e)}")
cap.release()
EOF
python video2txt.py
原理图解:
原始视频帧 → 底部区域裁剪 → 灰度二值化 → 形态学膨胀 → 字幕框定位 → OCR识别 → 文本去重

4. 字幕提取方案二:语音识别法
# 提取视频音频
ffmpeg -i video.mp4 -vn -acodec copy video.aac# 使用Whisper语音识别
pip install openai-whisper
whisper video.aac --language zh --model turbo --output_format txt
方案选择指南:
| 条件 | 推荐方案 | 原因 |
|---|---|---|
| 硬字幕(内嵌在画面中) | OCR方案 | 直接识别图像文字 |
| 软字幕/无字幕 | Whisper方案 | 通过语音内容生成文本 |
| 背景复杂字幕 | OCR+预处理 | 需增强文字区域对比度 |
5. 生成思维导图
cat > llm_ocr_summary.py <<-'EOF'
import openai
import os
import re
import numpy as np
import openai
import os
import re
from typing import Generator
import codecsos.environ["OPENAI_API_KEY"] = "<你自已的>"
os.environ["OPENAI_BASE_URL"] = "https://api.deepseek.com"
model_name="deepseek-chat"from openai import OpenAI
client = OpenAI()class OpenAILLM:"""调用OpenAI API生成象棋走法的LLM接口(支持流式响应)"""def __init__(self, model_name: str = "qwen3:32b"):self.model_name = model_namedef predict(self, msg: str, stream: bool = True) -> Generator[str, None, None]:"""支持流式响应的预测方法"""# 现在直接使用传入的msg作为完整提示prompt = msgtry:# 发起流式请求response_stream = client.chat.completions.create(model=self.model_name,messages=[{"role": "system", "content": "下文是通过OCR从视频中提取的文本,请根据上下文,生成Markdown格式的思维导图"},{"role": "user", "content": prompt}],temperature=0.7,stream=stream # 启用流式响应)# 处理流式响应full_content = ""for chunk in response_stream:if chunk.choices[0].delta.content is not None:content_part = chunk.choices[0].delta.contentfull_content += content_partyield content_part # 实时返回每个数据块except Exception as e:error_msg = f"OpenAI API调用失败:{e}"yield error_msgdef split_into_blocks(content: str) -> list:"""将内容按###分隔符拆分成块,保留分隔符"""# 使用正则表达式拆分,保留分隔符# (?=###) 使用正向先行断言确保###被包含在块中blocks = re.split(r'###', content)# 过滤空块return [block for block in blocks if block.strip()]def llm_request(llm,block,fo):prompt = f"""请分析下面的Patch代码块,用中文归结总结修改点{block}""" # 流式处理响应block_result = ""for partial_result in llm.predict(prompt, stream=True):print(partial_result, end='', flush=True)block_result += partial_resultfo.write(block_result)fo.flush()def process_large_file(file_path: str, llm: OpenAILLM, chunk_size: int = 65536):"""处理大文件,按块分析内容"""# 读取文件内容with codecs.open(file_path, "r", encoding='utf-8') as f:content = f.read()fo=codecs.open("output.md", "w", encoding='utf-8')fo.write("--------------------")fo.flush()print(fo)# 将内容拆分成块blocks = split_into_blocks(content)print(f"文件已拆分为 {len(blocks)} 个块")# 处理每个块request=""for i, block in enumerate(blocks):print(f"\n处理块 {i+1}/{len(blocks)} (大小: {len(block)}字符)...")if len(request)>=chunk_size:llm_request(llm,request,fo)request=""request+=f"{block}"llm_request(llm,request,fo)# 使用示例
if __name__ == "__main__":llm = OpenAILLM(model_name=model_name)process_large_file("out.txt", llm)
EOFcat save.txt | awk -F# '{print $2}' > out.txt
python3 llm_ocr_summary.py
输出
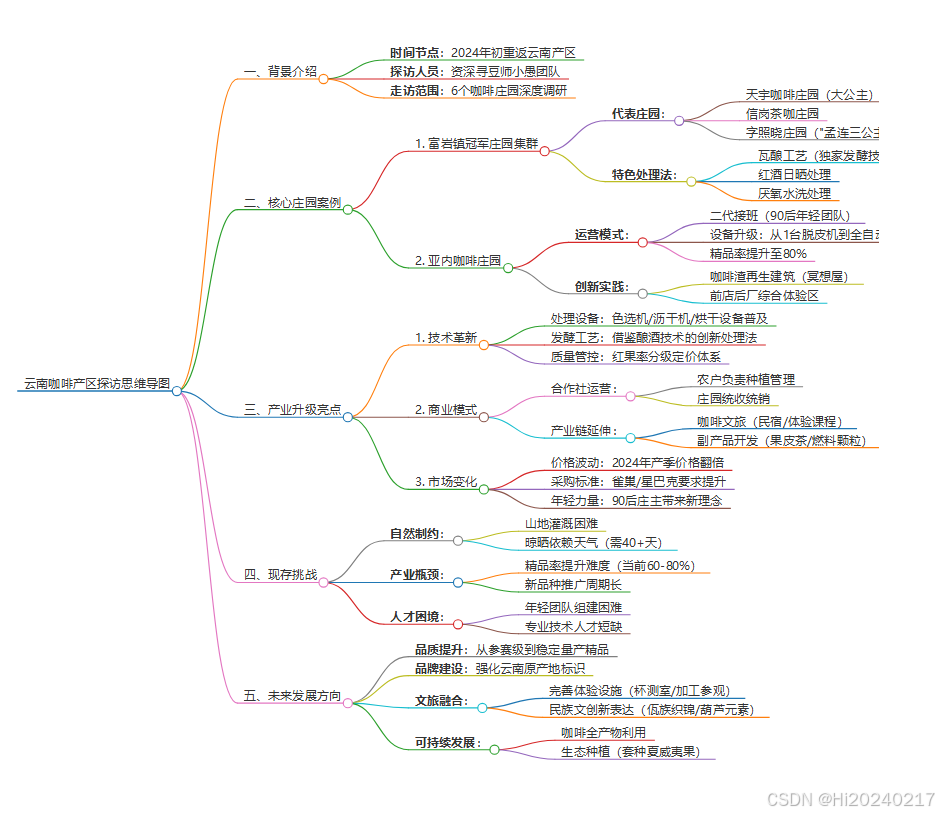
# 云南咖啡产区探访思维导图## 一、背景介绍
- **时间节点**:2024年初重返云南产区
- **探访人员**:资深寻豆师小愚团队
- **走访范围**:6个咖啡庄园深度调研## 二、核心庄园案例
### 1. 富岩镇冠军庄园集群
- **代表庄园**:- 天宇咖啡庄园(大公主)- 信岗茶咖庄园- 字照晓庄园("孟连三公主")
- **特色处理法**:- 瓦酿工艺(独家发酵技术)- 红酒日晒处理- 厌氧水洗处理### 2. 亚内咖啡庄园
- **运营模式**:- 二代接班(90后年轻团队)- 设备升级:从1台脱皮机到全自动化产线- 精品率提升至80%
- **创新实践**:- 咖啡渣再生建筑(冥想屋)- 前店后厂综合体验区## 三、产业升级亮点
### 1. 技术革新
- 处理设备:色选机/沥干机/烘干设备普及
- 发酵工艺:借鉴酿酒技术的创新处理法
- 质量管控:红果率分级定价体系### 2. 商业模式
- 合作社运营:- 农户负责种植管理- 庄园统收统销
- 产业链延伸:- 咖啡文旅(民宿/体验课程)- 副产品开发(果皮茶/燃料颗粒)### 3. 市场变化
- 价格波动:2024年产季价格翻倍
- 采购标准:雀巢/星巴克要求提升
- 年轻力量:90后庄主带来新理念## 四、现存挑战
- **自然制约**:- 山地灌溉困难- 晾晒依赖天气(需40+天)
- **产业瓶颈**:- 精品率提升难度(当前60-80%)- 新品种推广周期长
- **人才困境**:- 年轻团队组建困难- 专业技术人才短缺## 五、未来发展方向
1. **品质提升**:从参赛级到稳定量产精品
2. **品牌建设**:强化云南原产地标识
3. **文旅融合**:- 完善体验设施(杯测室/加工参观)- 民族文创新表达(佤族织锦/葫芦元素)
4. **可持续发展**:- 咖啡全产物利用- 生态种植(套种夏威夷果)> 注:数据统计截至2024年产季,孟连县咖啡种植面积1.16万亩,预计产量1.12万吨
6. 可视化呈现
使用在线工具转换Markdown为思维导图:
- 推荐工具
三、技术原理深度解析
1、OCR字幕提取核心逻辑
- 区域定位:基于字幕通常出现在画面底部的特性
- 图像增强:
- 二值化处理强化文字对比度
- 膨胀操作连接断裂文字笔划
- 去重机制:
- 计算连续帧的结构相似性(SSIM)
- 阈值过滤重复字幕
2、思维导图生成机制
四、常见问题解决方案
-
OCR识别率低
- 调整二值化阈值(
cv2.threshold的第二个参数) - 增加形态学操作强度(扩大kernel尺寸)
- 使用
PaddleOCR的det_db_thresh参数提高检测灵敏度
- 调整二值化阈值(
-
思维导图结构混乱
- 在prompt中添加明确的结构要求
- 示例:“请按’背景-问题-解决方案-效果’四级结构组织”
- 降低temperature参数值(0.2-0.5范围)
五、应用场景扩展
- 教育领域:课程视频→知识图谱
- 商业分析:竞品视频→SWOT分析
- 自媒体运营:热门视频→内容结构拆解
- 个人知识管理:学习视频→复习笔记