4. 图像识别模型与训练策略
这节讲讲非常经典的图像分类任务 和 常用的训练策略。

1. 数据读取与预处理操作
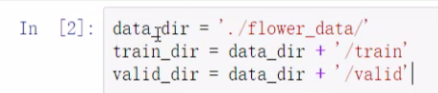
构建数据集的路径
1.1 数据增强
这个项目的数据是有100多个类别,总共6000多张图片,数据量非常小,数据不够怎么办?如何更高效的利用数据?
把图片进行各种变换!
但是这种增强不会保存到本地,这个是图片处理过的中间结果加载到模型中,通常在内存和显存中
1.2 制作好数据源
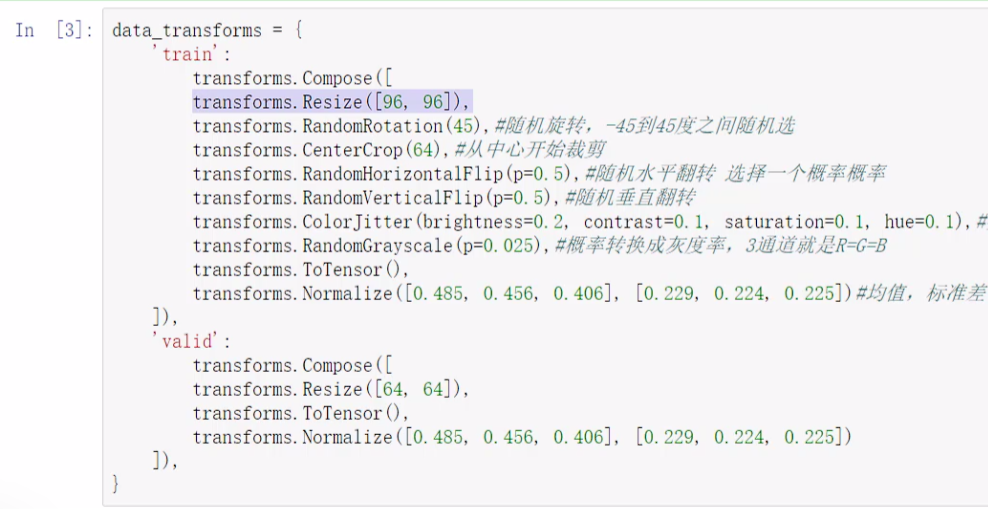
训练集的 compose 中按顺序组合:
- 图片数据的大小(长宽)不一致,虽然 resize 会丢失信息,但是没办法。resize的小一点计算的快一点。
- 如1.1节进行数据增强:随机旋转、随机裁剪、水平垂直翻转(有概率p翻转)、亮度对比度饱和度色相(做的不太多)、彩色转灰度(不常见)
- 转成tensor(必做)
- 标准化(用别人大数据集的均值和标准差,比如 imagenet 的,分别表示RGB)
验证集就不用做数据增强了。训练图片多大,验证集也得多大。验证所用的均值、标准差也得和训练集一样,因为不能预先知道考试的内容。

输入比较小,所以batch_size可以大一点加快速度;如果输入的图片比较大的话,bs就没法加的很大了。
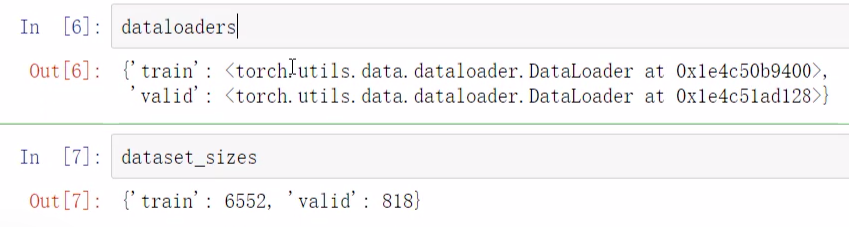
数据集是文件夹形式,所以通过文件夹读取数据 ImageFolder。
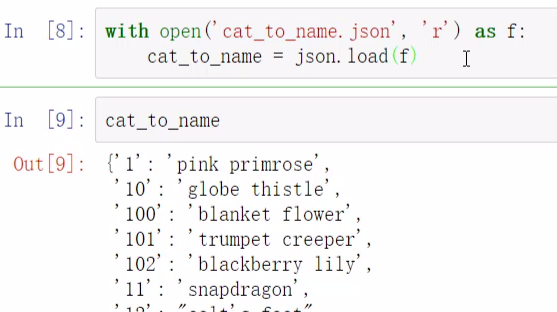
json是一个本地文件,字典结构,几号是什么
2. 加载models中的模型
自己定的模型不太好,不如用人家的经典模型。

一会儿会有一个判断,如果是true的话就把所有参数都冻住。
2.1 迁移学习
从零开始学太难了,迁移学习可以看作站在巨人肩膀上,在别人训练好的基础上进行微调。
今天不仅模型用人家的,权重参数也都用人家的,人家训练好的参数作为我们参数的初始化,就不随机初始化了。
如果没有预训练模型我们自己是很难做出来东西的。
怎么做微调?要调多少东西呢?要调的地方是多一些还是小一些呢?
- 如果我们的数据量很小,都不确定能不能训练出好的模型,这种情况下,我们可以把绝大部分的参数权重都冻住,只更新输出层。本来人着模型挺好的,如果对我们那一点数据不自信的话就可以冻住。
- 数据量中等,冻一部分
- 数据量大,自信,不冻了
输出层肯定不能冻,人家是1000分类的,我们是100分类的,输出层冻了相当于不仅抄人家作业,还把人家名字也抄了。
2.2 模型参数要不要更新
这是 torchvision 中自带的18层的resnet

等等类似的过程...每个小部分都有一个自己的名字。

最后这里是1000分类,我们需要修改一下这个值。
还做了一个全局平均池化,就是把每个特征图中的值都平均成一个值,然后得到的就是特征图个数个(512)特征值,这个就是特征图没法出结果,要经过转化的具体形式。然后1000分类。

这个函数执行的就是冻结所有权重参数,参数不去计算反向传播梯度,就不会更新。
2.3 把模型输出层改成自己的

- 在预训练中选择模型(参数中model_name),使用预训练参数。
- 设置冻结参数
- .fc 通过名字找到 fc 层,然后找到 in_features 参数(512)
- 重写 fc 层,重新赋值 linear 层,102(num_classes)
2.4 设置那些层需要训练
正常情况下是要训练所有层,
model_ft.parameters() 把所有参数都保存下来了,然后遍历所有参数,如果 grad 为true,才放到要更新的参数列表中。

刚才我们把所有的都设置成了false,然后自己新加了一层,默认是要反向传播的,这个新fc层是true,所以现在打印出来的就是fc的权重偏置。
2.5 优化器设置

把要更新的东西、学习率传到优化器中;再指定一个衰减策略,随着迭代,学习率是有一个衰减的过程,这个过程是可以自己定的,每10步(自己定)进行一个衰减;最后就是一个交叉熵损失函数。
3. 训练模块
3.1 准备工作
首先要传model,dataloder,损失函数,优化器,迭代次数,保存文件的路径
记录时间、最好的准确率、保存在验证集上效果最好的那一次,好就做替换,而不是保存最后那一次、计算设备、损失指标、学习率(打印用)、当时最优的模型
3.2 遍历
还是上面的函数

每个epoch都有训练和验证,初始化损失和正确的个数,一会儿会打印
每个epoch中有很多数据,每次遍历取其中一部分,每部分的结果都得算,最后平均
训练和验证阶段都要走下面这个前向传播:
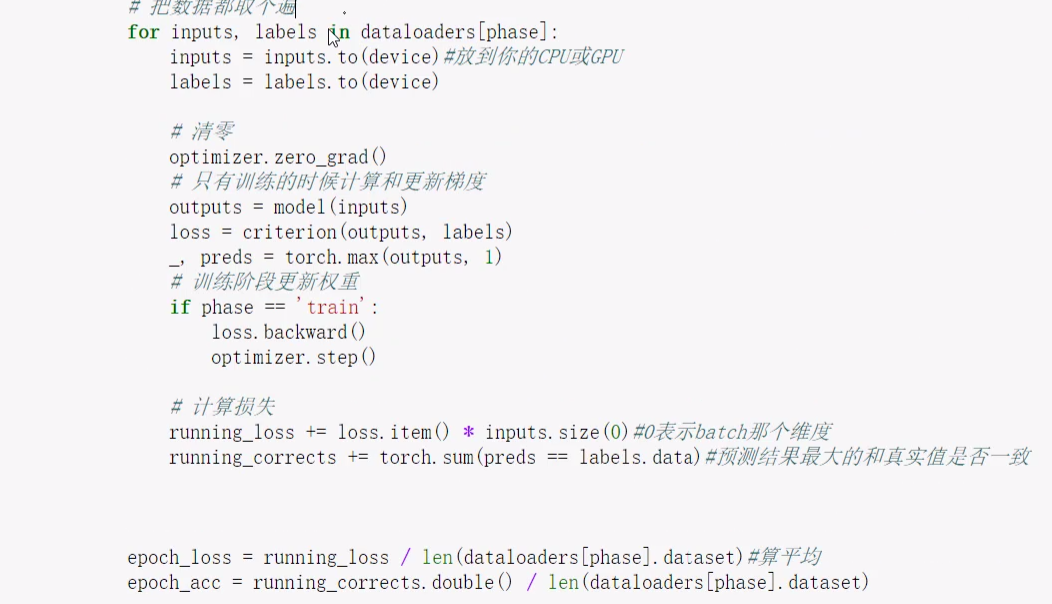
取对应数据放进计算设备,标签也放进去。
- 梯度清零
- model输出结果
- 计算loss
- 得到一堆概率中最大那个,也就是实际预测结果
- 如果是训练阶段就更新权重
- 计算累加损失,+=当前batch的损失,正确个数累加
迭代完一个epoch(跑完整个数据集),按训练和验证分别算平均损失和准确率。
当走完验证集之后,要进行一个判断:

如果验证集上的效果比最好的还要好,那就保存当前次的权重参数等信息。
存训练和验证的结果。

每一个epoch完之后,打印保存学习率,学习率衰减,step是累加的,当step10之后才会衰减。
所有epoch结束后,截至一下时间,打印一些信息,把最好的那次模型当作最终结果。
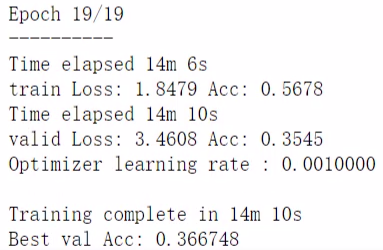
3.3 开始训练
现在是只训练一个输出层,后续会演示训练所有层。
![]()
![]()


...
3.4 训练全部参数
fc 和 所有冻住的层一起训练,grad 全设置为 true。

![]()
![]()
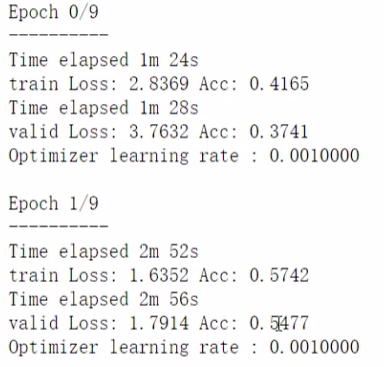
可以看到比之前只训练 fc 层的效果好多了。
4. 加载训练好的模型
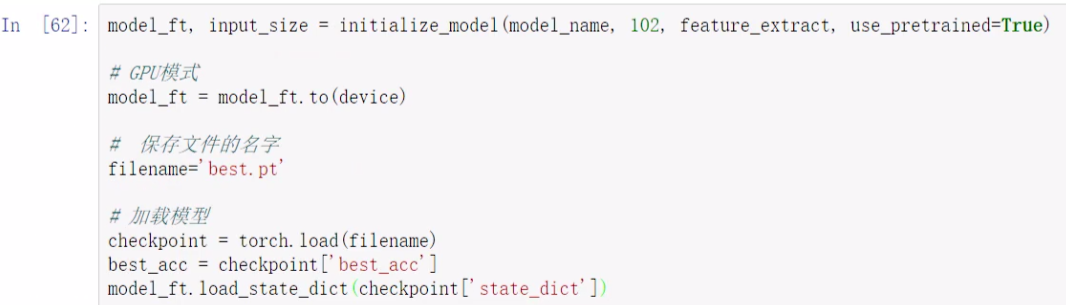
加载模型、替换参数字典
4.1 测试数据预处理

4.2 得到概率最大的那个
4.3 结果展示
transpose 把 0 移到后面了,64*64*3 这是图像格式,channel 在后面。

做了一些子图

