GPT 解码策略全解析:从 Beam Search 到 Top-p 采样
大语言模型(LLM)如 GPT 在推理时,并不是一次性生成整句话,而是一步步预测下一个 token。每一步都会输出一个概率分布,告诉我们在当前上下文下每个词(或子词)出现的可能性。
如何从这个概率分布中选择下一个 token,决定了模型输出的风格和质量。这就是解码策略(Decoding Strategies)的核心。
本文将介绍几种常见的解码方法,并结合公式、例子分析它们的优缺点。
1. Greedy Search(贪心搜索)
原理
每一步都选择概率最高的 token:
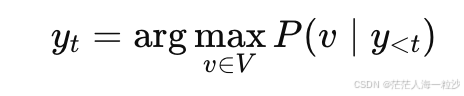
其中 V 是词表。
例子
假设 GPT 在预测下一个词时输出:
apples:0.5bananas:0.3cars:0.2
贪心搜索直接选 apples,然后继续下一个 token 的预测。
优点
快,计算开销最小
结果稳定,可复现
缺点
容易陷入局部最优(早期错误无法修正)
多样性差,常出现重复循环
2. Beam Search(束搜索)
原理
不是每步只保留一个候选,而是保留 k 条概率最高的序列,并在生成过程中并行推进它们。
目标是近似求解:
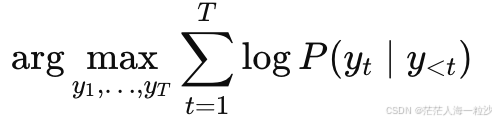
常用长度归一化:
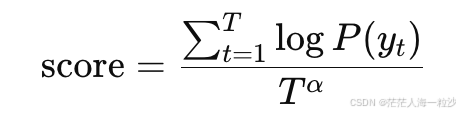
例子:Beam 宽度 k = 2
Step 0
起始输入:["I", "like"]
累计 log 概率 = 0(初始化)
Step 1(预测第一个词)
GPT 输出概率:
"apples":0.5"bananas":0.3"cars":0.2
保留 top-2(k=2):
["I", "like", "apples"],log 概率 = log(0.5)["I", "like", "bananas"],log 概率 = log(0.3)
Step 2(预测第二个词)
对每条 beam 扩展:
从 "apples" 扩展:
"very":0.6"red":0.4
从 "bananas" 扩展:
"are":0.5"yellow":0.5
所有候选(带累计概率):
I like apples very:log(0.5) + log(0.6)I like apples red:log(0.5) + log(0.4)I like bananas are:log(0.3) + log(0.5)I like bananas yellow:log(0.3) + log(0.5)
排序取前 k=2:
I like apples veryI like apples red(假设它比 banana 组合得分高)
Step 3(预测第三个词)
继续扩展 top-2:
从 "I like apples very" 扩展:
"much":0.7"sweet":0.3
从 "I like apples red" 扩展:
"and":0.6"juicy":0.4
最终所有候选(累计概率最高的排前面):
I like apples very muchI like apples red and
优点
比贪心更可能找到全局最优
适合机器翻译、摘要等确定性任务
缺点
计算量大(随 k 增长)
多样性低,生成结果常相似
对开放式生成(聊天、创作)效果一般
3. Top-k Sampling(截断采样)
原理
在每一步的概率分布中,只保留概率最高的 k 个 token,并归一化后按概率随机采样:
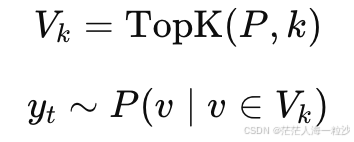
例子(k=3)
如果概率分布是:
apples:0.5bananas:0.3cars:0.2其他:很小概率
只保留 apples、bananas、cars,再随机抽一个。
优点
保证词汇质量(只在高概率集合内选)
增加多样性
缺点
k 选得太小 → 变得接近贪心
k 太大 → 噪音增多
4. Top-p Sampling(核采样,Nucleus Sampling)
原理
动态选择最小的子集 ,使得累计概率 ≥ p:
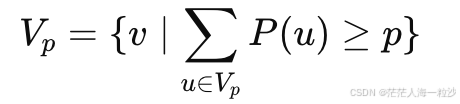
然后在这个子集内按概率采样。
例子(p=0.9)
假设概率排序:
apples:0.5bananas:0.3(累计 0.8)cars:0.1(累计 0.9)
此时只保留 apples、bananas、cars,随机采样一个。
优点
动态调节候选集合大小
在保持流畅性的同时增加创意性
缺点
p 太高会引入低概率词
p 太低会变得保守
5. 温度采样(Temperature)
原理
温度参数 T>0 调整概率分布的平滑度:
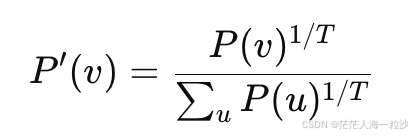
T < 1:放大高概率 token,输出更确定
T > 1:平滑概率,输出更随机
例子
原始分布:apples 0.5, bananas 0.3, cars 0.2
T=0.7:
apples概率会更大T=1.5:三者概率更接近
优缺点
控制随机性
需要与 Top-k / Top-p 搭配使用
6. 对比总结
| 策略 | 多样性 | 确定性 | 计算成本 | 典型场景 |
|---|---|---|---|---|
| Greedy | 低 | 高 | 低 | 快速摘要、确定性任务 |
| Beam | 低 | 高 | 高 | 机器翻译、摘要 |
| Top-k | 中 | 中 | 中 | 创意写作、对话 |
| Top-p | 高 | 中 | 中 | 对话、故事生成 |
| 温度 | 可调 | 可调 | 低 | 调整生成风格 |
7. GPT 的实际选择
在开放式生成任务(聊天、创作)中,GPT 很少用 Beam Search,而是采用 Top-p + 温度,因为这种方式能在保持流畅性的同时,增加多样性与创造性。
机器翻译或摘要类任务,Beam Search 仍有用武之地,但在大多数对话场景中,它会显得“死板”。
结语
解码策略是连接“模型概率”与“实际输出”的桥梁。选对策略,就像给 GPT 配上一双合适的鞋:
想跑得稳?用 Beam Search。
想跑得花?用 Top-p + 温度。