常见的tls检测的绕过方案
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、JA3指纹是什么?
- 二、怎么判断是JA3指纹
- 1.返回结果
- 2.抓包
- 三、怎么处理,绕过方案(常用的)
- 1.curl_cffi
- 2.requests-go
- 四、结合scrapy,高效采集
- 1.创建文件夹
- 2.requests-go异步方案
- 3.curl_cffi(httpx)异步方案
- 4.配置
前言
为了建立安全的通信连接,TLS(Transport Layer Security)协议被广泛应用于Web浏览器、移动应用和其他网络应用程序中。而与此同时,识别和分析这些TLS通信也成为网络安全研究和威胁情报分析的重要任务之一。JA3指纹作为一种独特的指纹识别技术,为我们提供了一种有效的手段来识别和分析TLS通信。
一、JA3指纹是什么?
JA3指纹(JA3 fingerprint)是一种用于网络流量分析的技术,旨在识别和分类不同的TLS(Transport Layer Security)客户端。TLS是一种常用于加密互联网通信的协议,它提供了安全的数据传输和身份验证机制。(更多了解和原理请百度自行查阅)
二、怎么判断是JA3指纹
1.返回结果
<!DOCTYPE html><html lang="en-US"><head><title>Just a moment...</title><meta http-equiv="Content-Type" content="text/html; charset=UTF-8"><meta http-equiv="X-UA-Compatib
请求的结果类似于Just a moment…,那你就开始思考是不是你请求的网站存在tls指纹了
2.抓包
使用fiddler抓包,如图:
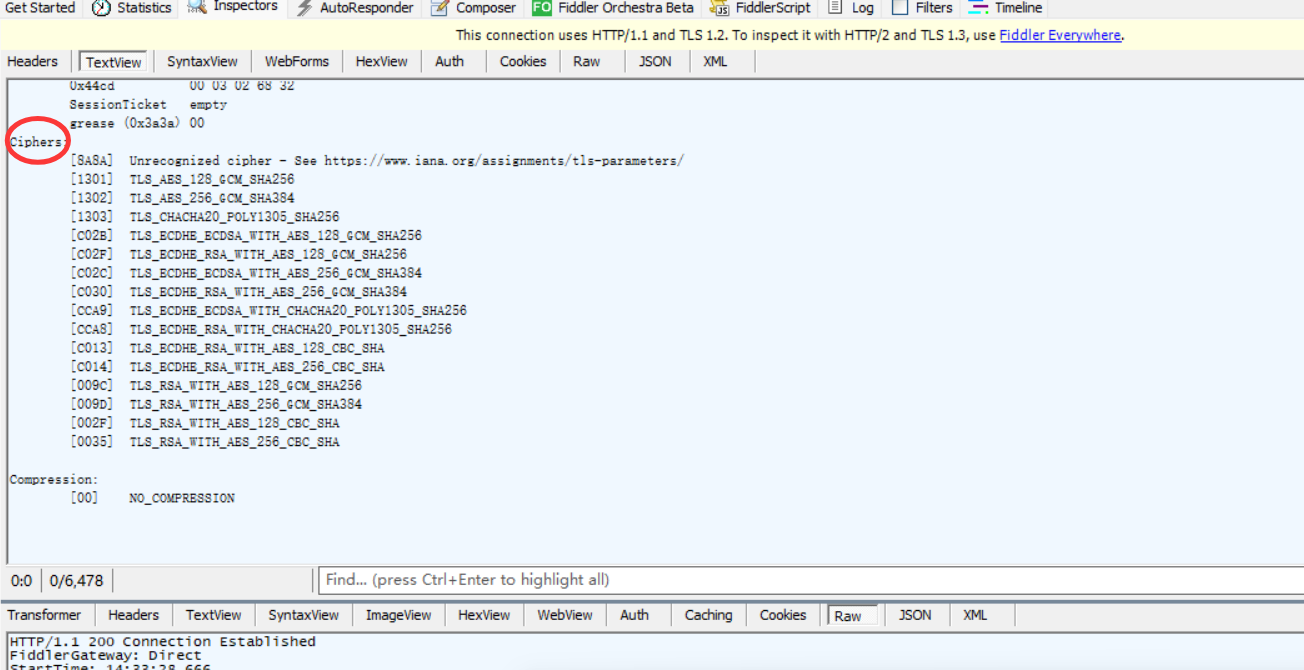
然后我们看到很多的加密算法,还有加密方式
三、怎么处理,绕过方案(常用的)
1.curl_cffi
from curl_cffi import requests
url = ''
response = requests.get(url, impersonate="chrome101").json()
print(response)
优点:使用简单,跟requests一样,所有的方法都能使用
2.requests-go
import requests_go
url = ''data = {'rpc': 100, 'page': 0, 'TaxonomicTags': 'Cytokine Proteins'}
headers = {}
tls = requests_go.tls_config.TLSConfig()
tls.ja3 = "771,4865-4866-4867-49195-49199-49196-49200-52393-52392-49171-49172-156-157-47-53,16-18-5-27-0-13-11-43-45-35-51-23-10-65281-17513-21,29-23-24,0"
tls.pseudo_header_order = [":method",":authority",":scheme",":path",]
tls.tls_extensions.cert_compression_algo = ["brotli"]
tls.tls_extensions.supported_signature_algorithms = ["ecdsa_secp256r1_sha256","rsa_pss_rsae_sha256","rsa_pkcs1_sha256","ecdsa_secp384r1_sha384","rsa_pss_rsae_sha384","rsa_pkcs1_sha384","rsa_pss_rsae_sha512","rsa_pkcs1_sha512"]
tls.tls_extensions.supported_versions = ["GREASE","1.3","1.2"]
tls.tls_extensions.psk_key_exchange_modes = ["PskModeDHE"]
tls.tls_extensions.key_share_curves = ["GREASE","X25519"]
tls.http2_settings.settings = {"HEADER_TABLE_SIZE": 65536,"ENABLE_PUSH": 0,"MAX_CONCURRENT_STREAMS": 1000,"INITIAL_WINDOW_SIZE": 6291456,"MAX_HEADER_LIST_SIZE": 262144}
tls.http2_settings.settings_order = ["HEADER_TABLE_SIZE","ENABLE_PUSH","MAX_CONCURRENT_STREAMS","INITIAL_WINDOW_SIZE","MAX_HEADER_LIST_SIZE"]
tls.http2_settings.connection_flow = 15663105
response = requests_go.post(url=url, data=data, headers=headers, tls_config=tls)
print(response.url)
优点:接口与 requests 一致,支持JA3/JA4,异步支持完善,跨平台兼容性好。
四、结合scrapy,高效采集
1.创建文件夹
在scrapy.cfg同路径创建文件夹scrapy_fingerprint,并创建py文件:fingerprint_download_handler.py
2.requests-go异步方案
写入fingerprint_download_handler.py
import asyncio
import json
from time import timeimport scrapy
from scrapy.http import HtmlResponse
from scrapy.spiders import Spider
from scrapy.http import Responsefrom twisted.internet.defer import Deferredfrom loguru import logger
import requests_godef as_deferred(f):return Deferred.fromFuture(asyncio.ensure_future(f))class FingerprintDownloadHandler:def get_proxies(self):try:return proxiesexcept Exception as e:logger.error(e)return Falseasync def _download_request(self, request):tls = requests_go.tls_config.TLSConfig()tls.ja3 = "771,4865-4866-4867-49195-49199-49196-49200-52393-52392-49171-49172-156-157-47-53,16-18-5-27-0-13-11-43-45-35-51-23-10-65281-17513-21,29-23-24,0"tls.pseudo_header_order = [":method",":authority",":scheme",":path",]tls.tls_extensions.cert_compression_algo = ["brotli"]tls.tls_extensions.supported_signature_algorithms = ["ecdsa_secp256r1_sha256","rsa_pss_rsae_sha256","rsa_pkcs1_sha256","ecdsa_secp384r1_sha384","rsa_pss_rsae_sha384","rsa_pkcs1_sha384","rsa_pss_rsae_sha512","rsa_pkcs1_sha512"]tls.tls_extensions.supported_versions = ["GREASE","1.3","1.2"]tls.tls_extensions.psk_key_exchange_modes = ["PskModeDHE"]tls.tls_extensions.key_share_curves = ["GREASE","X25519"]tls.http2_settings.settings = {"HEADER_TABLE_SIZE": 65536,"ENABLE_PUSH": 0,"MAX_CONCURRENT_STREAMS": 1000,"INITIAL_WINDOW_SIZE": 6291456,"MAX_HEADER_LIST_SIZE": 262144}tls.http2_settings.settings_order = ["HEADER_TABLE_SIZE","ENABLE_PUSH","MAX_CONCURRENT_STREAMS","INITIAL_WINDOW_SIZE","MAX_HEADER_LIST_SIZE"]tls.http2_settings.connection_flow = 15663105timeout = request.meta.get("download_timeout") or 30headers = request.headers.to_unicode_dict()proxies = self.get_proxies()if request.method == "POST":body = json.loads(request.body)response = await requests_go.async_post(url=request.url, json=body, headers=headers, proxies=proxies,tls_config=tls, timeout=timeout)else:response = await requests_go.async_get(url=request.url, headers=headers, proxies=proxies, tls_config=tls,timeout=timeout)response = HtmlResponse(request.url,encoding=response.encoding,status=response.status_code,# headers=response.headers,body=response.content,request=request)return responsedef download_request(self, request: scrapy.Request,spider: Spider) -> Deferred:del spiderstart_time = time()d = as_deferred(self._download_request(request))d.addCallback(self._cb_latency, request, start_time)return d@staticmethoddef _cb_latency(response: Response, request: scrapy.Request,start_time: float) -> Response:request.meta["download_latency"] = time() - start_timereturn response
3.curl_cffi(httpx)异步方案
import asyncio
import json
from time import timeimport scrapy
from oss2.exceptions import status
from scrapy.http import HtmlResponse
from scrapy.spiders import Spider
from scrapy.http import Responsefrom twisted.internet.defer import Deferredfrom loguru import logger
from curl_cffi.requests import AsyncSession
import httpxdef as_deferred(f):return Deferred.fromFuture(asyncio.ensure_future(f))class FingerprintDownloadHandler:def get_proxies(self):try:return proxiesexcept Exception as e:logger.error(e)return Falseasync def _download_request(self, request):headers = request.headers.to_unicode_dict()proxies = self.get_proxies()if request.method == "GET":async with AsyncSession() as s:response = await s.get(url=request.url,headers=headers,proxies=proxies,timeout=20,impersonate="chrome101")if request.method == "POST":async with httpx.AsyncClient() as client:body = json.loads(request.body)response = await client.post(url=request.url,headers=headers,proxies=proxies,json=body,timeout=20)response = HtmlResponse(request.url,encoding=response.encoding,status=response.status_code,# headers=response.headers,body=response.content,request=request)return responsedef download_request(self, request: scrapy.Request,spider: Spider) -> Deferred:del spiderstart_time = time()d = as_deferred(self._download_request(request))d.addCallback(self._cb_latency, request, start_time)return d@staticmethoddef _cb_latency(response: Response, request: scrapy.Request,start_time: float) -> Response:request.meta["download_latency"] = time() - start_timereturn response
4.配置
在setting.py文件加入
DOWNLOAD_HANDLERS = {'http': ('scrapy_fingerprint.fingerprint_download_handler.''FingerprintDownloadHandler'),'https': ('scrapy_fingerprint.fingerprint_download_handler.''FingerprintDownloadHandler'),
}