Coze Studio 概览(十)--文档处理详细分析
文档处理对于知识库建设尤为重要。本文详细分析Coze Studio中对各种文档是如何处理及向量化的。
Coze Studio 文档处理详细分析
Word文档处理机制
1. Word文档解析流程
基于代码分析,Word文档(.docx)的处理采用Python解析器协议:
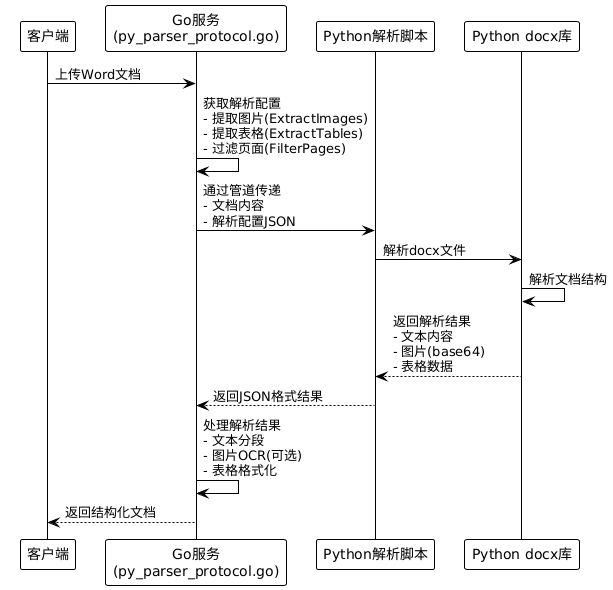
2. Word文档分段策略
核心分段组件:
- 自动分段:基于文档结构(段落、标题)
- 手动分段:自定义分隔符
- 层级分段:按标题层级分段
分段配置参数:
type ChunkingStrategy struct {ChunkType parser.ChunkType // 分段类型ChunkSize int64 // 分段最大长度(字符数)Separator string // 分段标识符Overlap int64 // 分段重叠长度TrimSpace bool // 移除空白字符TrimURLAndEmail bool // 移除URL和邮箱MaxDepth int64 // 层级分段最大深度SaveTitle bool // 保留层级标题
}
Word文档特殊处理:
- 标题识别:根据样式识别H1-H6标题
- 段落分离:保持段落完整性
- 列表处理:保持列表项的层级结构
- 图片提取:转换为base64并可选OCR识别
- 表格提取:转换为HTML表格格式
Excel文档处理机制
1. Excel文档解析流程
Excel文档(.xlsx)使用excelize库进行解析:
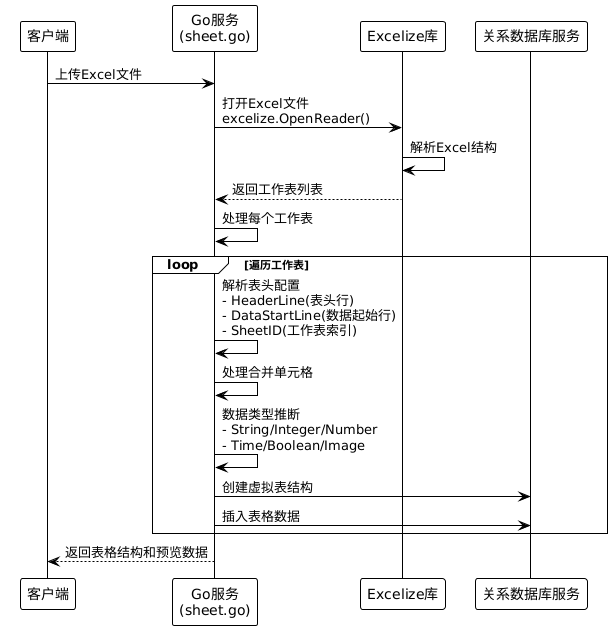
2. Excel合并单元格处理
合并单元格处理策略:
// Excel处理核心逻辑
func (k *knowledgeSVC) LoadSheet(ctx context.Context, b []byte, ps *entity.ParsingStrategy, fileExtension string, sheetName *string, columns []*entity.TableColumn) (*rawSheet, error) {// 1. 使用excelize解析Excel文件pConfig := convert.ToParseConfig(parser.FileExtension(fileExtension), ps, nil, false, columns)p, err := k.parseManager.GetParser(pConfig)// 2. 解析文档获取结构化数据docs, err := p.Parse(ctx, bytes.NewReader(b))// 3. 处理合并单元格:// - 合并单元格的值会填充到第一个单元格// - 其他单元格保持空值// - 在数据类型推断时会忽略空值单元格return &rawSheet{sheet: sheet,cols: cols, // 列定义vals: vals, // 实际数据}, nil
}
合并单元格具体处理逻辑:
- 值分布:合并单元格的值只存储在合并区域的第一个单元格
- 空值处理:其他合并单元格位置保持为空值
- 类型推断:基于非空单元格进行数据类型推断
- 索引策略:合并单元格按第一个单元格位置建立索引
3. Excel数据类型处理
支持的数据类型:
const (TableColumnTypeString = 1 // 文本类型TableColumnTypeInteger = 2 // 整数类型TableColumnTypeTime = 3 // 时间类型TableColumnTypeNumber = 4 // 数字类型TableColumnTypeBoolean = 5 // 布尔类型TableColumnTypeImage = 6 // 图片类型
)
类型转换策略:
func TransformColumnType(src, dst document.TableColumnType) document.TableColumnType {if src == document.TableColumnTypeUnknown {return dst}if dst == document.TableColumnTypeUnknown {return src}if dst == document.TableColumnTypeString {return dst // 字符串类型优先级最高}if src == dst {return dst}if src == document.TableColumnTypeInteger && dst == document.TableColumnTypeNumber {return dst // 整数可以转换为数字}return document.TableColumnTypeString // 默认转换为字符串
}
文本文件处理机制
1. 文本文件分段处理
分段策略类型:
- 自动分段:基于自然语言处理
- 手动分段:用户指定分隔符
- 层级分段:按标题层级
分段实现流程:
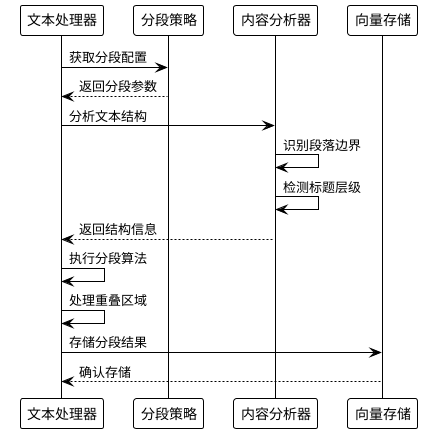
2. 自定义分段配置
前端分段配置界面:
interface CustomSegmentRule {separator: {type: SeperatorType; // 分隔符类型customValue: string; // 自定义分隔符};maxTokens: number; // 最大Token数(100-5000)overlap: number; // 重叠比例(0-90%)preProcessRules: PreProcessRule; // 预处理规则
}// 支持的分隔符类型
enum SeperatorType {PARAGRAPH = 'paragraph', // 段落分隔SENTENCE = 'sentence', // 句子分隔NEWLINE = 'newline', // 换行分隔CUSTOM = 'custom' // 自定义分隔符
}
3. 层级分段处理
层级分段特点:
- 标题识别:自动识别H1-H6标题
- 层级保持:维护文档的层级结构
- 上下文保留:可选择保留上级标题作为上下文
- 深度控制:限制最大分段深度
特殊格式处理
1. PDF文档处理
PDF解析策略:
- 快速解析:提取纯文本内容
- 精确解析:保留格式和结构
- 页面过滤:支持指定页面范围
- 表格提取:识别并提取表格结构
- 图片OCR:可选的图片文字识别
2. Markdown文档处理
Markdown特殊处理:
- 标题层级:保持原有的#标题结构
- 代码块:保持代码块的完整性
- 表格格式:转换为HTML表格
- 链接图片:处理外部链接和图片
3. 图片文档处理
图片处理流程:
- 图片上传:存储到对象存储(TOS/MinIO)
- OCR识别:可选的文字识别
- 描述生成:AI生成图片描述
- 向量化:将描述转换为向量
各类型文档分段策略详析
1. 分段策略类型体系
核心分段策略枚举:
type ChunkType int64
const (ChunkType_DefaultChunk ChunkType = 0 // 自动分段ChunkType_CustomChunk ChunkType = 1 // 自定义分段ChunkType_LevelChunk ChunkType = 2 // 层级分段
)
分段策略配置结构:
type ChunkingStrategy struct {ChunkType ChunkType `json:"chunk_type"`// 自定义分段配置ChunkSize int64 `json:"chunk_size"` // 分段最大长度(字符数)Separator string `json:"separator"` // 分段标识符Overlap int64 `json:"overlap"` // 分段重叠百分比TrimSpace bool `json:"trim_space"` // 移除多余空白TrimURLAndEmail bool `json:"trim_url_and_email"` // 移除URL和邮箱// 层级分段配置MaxDepth int64 `json:"max_depth"` // 层级分段最大深度SaveTitle bool `json:"save_title"` // 保留层级标题
}
2. 文本类文档分段策略
支持的文档类型:
- Markdown文件:保持原有标题结构,支持代码块完整性
- TXT文件:基于自然语言处理的智能分段
- PDF文件:快速解析和精确解析两种模式
分段策略选项:
2.1 自动分段 (DefaultChunk)
- 特点:基于自然语言处理算法自动识别段落边界
- 适用场景:通用文本文档,新闻文章,小说等
- 技术实现:使用Python解析器协议进行语义分析
2.2 自定义分段 (CustomChunk)
- 分隔符类型:
enum SeperatorType {PARAGRAPH = 'paragraph', // 段落分隔(\n\n)SENTENCE = 'sentence', // 句子分隔(.!?)NEWLINE = 'newline', // 换行分隔(\n)CUSTOM = 'custom' // 用户自定义分隔符 } - 配置参数:
- 最大Token数:100-5000
- 重叠比例:0-90%
- 预处理规则:移除URL/邮箱、压缩空白字符
2.3 层级分段 (LevelChunk)
- 标题识别:自动识别H1-H6标题层级
- 层级保持:维护文档的层级结构关系
- 上下文保留:可选择保留上级标题作为上下文
- 深度控制:限制最大分段深度(1-6级)
3. Excel表格文档分段策略
Excel特殊处理机制:
3.1 行级分段策略
- 单行分段:每行作为一个独立的分段
- 多行批量分段:按指定行数批量分段
- 智能分段:基于数据密度自动调整分段大小
3.2 合并单元格处理
// 合并单元格处理逻辑
func processMergedCells(sheet *excelize.File) {// 1. 合并单元格的值只存储在第一个单元格// 2. 其他合并位置保持空值// 3. 类型推断时忽略空值单元格// 4. 按第一个单元格位置建立索引
}
3.3 数据类型推断分段
- 类型优先级:字符串 > 数字 > 整数 > 时间 > 布尔
- 转换策略:智能类型转换,失败时降级为字符串
- 空值处理:合并单元格中的空值不参与类型推断
4. Word文档分段策略
Word文档专项处理:
4.1 结构化分段
- 段落完整性:保持段落的完整性,不在段落中间断开
- 列表处理:维持有序/无序列表的层级结构
- 表格提取:表格转换为HTML格式并独立分段
4.2 样式识别分段
- 标题样式:根据Word样式自动识别标题层级
- 字体格式:保留重要的字体格式信息
- 图片处理:图片转换为base64,可选OCR文字识别
5. 向量化策略详析
5.1 向量化模型支持
Embedding模型接口:
type Embedder interface {embedding.EmbedderEmbedStringsHybrid(ctx context.Context, texts []string, opts ...embedding.Option) ([][]float64, []map[int]float64, error)Dimensions() int64SupportStatus() SupportStatus
}type SupportStatus int
const (SupportDense SupportStatus = 1 // 仅支持稠密向量SupportDenseAndSparse SupportStatus = 3 // 支持稠密+稀疏混合向量
)
5.2 向量化策略类型
5.2.1 稠密向量化 (Dense Embedding)
- 模型支持:Doubao-Embedding、OpenAI系列模型
- 向量维度:通常512-1536维
- 适用场景:语义相似性检索、通用文本匹配
5.2.2 混合向量化 (Hybrid Embedding)
- 稠密向量:捕获语义信息
- 稀疏向量:保留关键词信息
- 融合策略:RRF(Reciprocal Rank Fusion)重排序算法
- 优势:兼顾语义理解和精确匹配
5.3 向量化配置策略
向量化配置参数:
interface VectorStrategy {vectorModel: {name: string; // 向量模型名称dimensions: number; // 向量维度};vectorIndexing: boolean; // 是否开启向量索引hybridSearch: boolean; // 是否启用混合搜索
}
5.4 不同文档类型的向量化策略
5.4.1 文本文档向量化
- 分段后向量化:每个分段生成独立的向量
- 标题增强:层级分段时,标题信息增强分段的向量表示
- 上下文窗口:重叠分段保证上下文连续性
5.4.2 表格文档向量化
- 行级向量化:每行数据作为一个向量单元
- 列组合策略:选择性组合重要列进行向量化
- 元数据增强:表头信息作为向量化的额外上下文
5.4.3 混合文档向量化
- 多模态处理:文本、图片、表格分别向量化
- 权重分配:不同模态按重要性分配权重
- 统一检索:多模态向量在统一空间中检索
6. 向量存储与检索策略
6.1 向量存储后端
- VikingDB:字节跳动自研向量数据库
- Elasticsearch:支持向量检索的ES集群
- Milvus:开源向量数据库
6.2 检索策略优化
- 向量召回:基于余弦相似度的向量检索
- 混合检索:向量检索+BM25关键词检索
- 重排序:使用专门的Rerank模型进行结果重排
核心技术组件总结
后端文档处理组件
- Python解析器协议:处理Word、PDF等复杂格式文档
- Excelize库:专门处理Excel文件的Go库
- Eino文档解析器:统一的文档解析接口
- 分段策略引擎:支持自动、自定义、层级三种分段算法
- 向量化引擎:支持稠密和稀疏混合向量化
- 类型推断系统:智能识别Excel数据类型
- 向量存储层:多后端向量数据库支持
前端文档处理组件
- 文档上传组件:支持多种文件格式拖拽上传
- 分段配置界面:可视化分段参数设置
- 向量模型选择器:动态加载可用的向量模型
- 预览组件:实时预览分段效果
- 编辑器:支持手动调整分段结果
- 进度跟踪:文档处理和向量化进度可视化
关键特性
- 多策略支持:每种文档类型都有针对性的分段策略
- 智能分段:基于文档结构和内容特点自动选择最优策略
- 向量化灵活性:支持多种向量模型和混合向量化
- 类型安全:强类型的数据处理和转换
- 性能优化:流式处理大文件,并行向量化
- 错误恢复:完善的异常处理和重试机制
- 可扩展性:模块化设计支持新的文档类型和分段策略
总结
这套文档处理系统展现了企业级AI应用在文档处理方面的完整解决方案,特别是在处理复杂格式文档和混合向量化方面有着成熟的技术实现。通过多层次的分段策略和向量化策略,能够最大化地保留文档的语义信息和结构信息,为后续的检索和问答提供高质量的数据基础。
本文内容由AI生成,如果错误还请指出。