多轮问答与指代消解
目录
- 引言
- 一、LangChain是怎么实现的多轮问答
- 1、记忆模块(Memory)管理对话历史
- 2、对话链(Conversational Chain)架构
- 3、智能体(Agent)决策机制
- 4、上下文感知的Prompt工程
- 5、RAG(检索增强生成)集成
- 二、多轮问答实现的常规流程
- 三、什么是指代消解
- 四、实战案例
- 1、大模型messages的多轮对话
- 2、RAG下的多轮对话
引言
一个AI智能问答系统一般会被要求有多轮对话的能力,尤其是类似客服系统这种交互性强的应用,如果不支持多轮往往显得很人工智障。而目前我们的大模型是否已经自己具备这种多轮问答的能力呢?如果不具备那又该如何实现呢?
早在之前小马在《如何5分钟快速搭建智能问答系统》中已经介绍过在早期没有大模型LLM的时候就是用的Bert处理的问答对向量库匹配,很显然这套机制基础本身是不具备什么多轮问答能力的。后来chatgpt问世,改用大模型LLM总结输出匹配内容,很显然从整体来讲也只是多了大模型这个环节。我们知道,如果从大模型的原理来说,它本身确实是具备指代消解能力的,但却没有具备记忆能力,因此一般情况下我们需要借助外部机制来完成多轮对话问答的效果。
今天小马就来一起探讨多轮问答具体是如何实现的。

一、LangChain是怎么实现的多轮问答
开始之前,我们不妨先来看下老经典的框架LangChain是怎么实现这块多轮问答功能的。
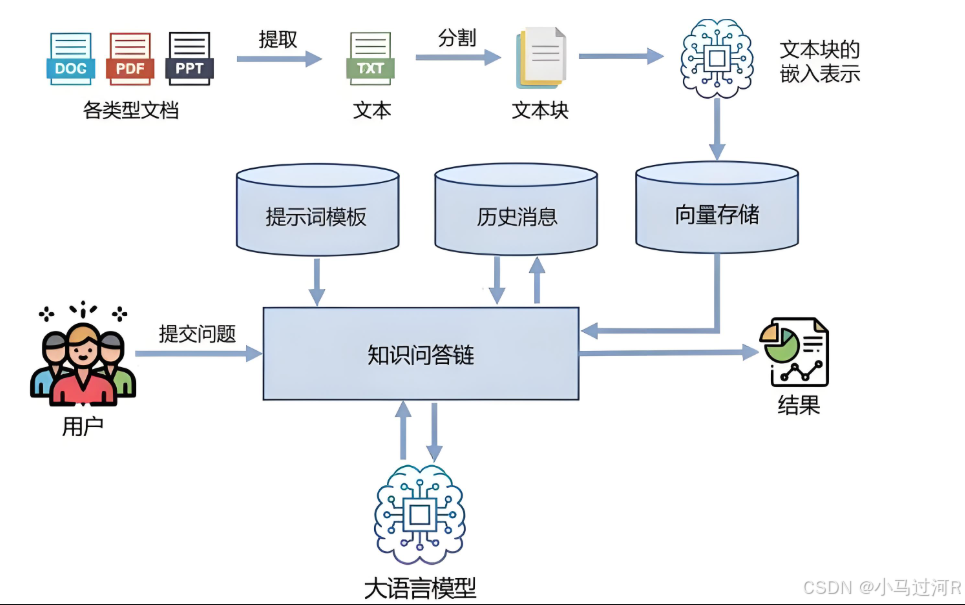
LangChain框架通过以下核心机制实现多轮问答功能:
1、记忆模块(Memory)管理对话历史
采用ConversationBufferMemory或VectorStoreMemory存储对话上下文,前者以字符串形式保存历史记录,后者通过向量化实现高效检索。
记忆模块会自动将历史对话注入到当前Prompt中,确保模型生成响应时考虑上下文连贯性。
(有个关键的点,这里说到最终会将历史对话注入到Prompt中给模型最终生成响应时作参考。曾经有简单调研过这块Memory的底层原理,默认是内存存储,好像记得也是可以自定义指定存储介质的,读者可以自行确认。)
2、对话链(Conversational Chain)架构
使用ConversationalRetrievalChain等专用链类型,组合LLM调用、记忆管理和工具调用流程。
链式结构支持动态插入预处理(如实体提取)和后处理(如敏感词过滤)组件。
3、智能体(Agent)决策机制
选择ConversationalChatAgent等专用Agent类型,支持基于上下文的工具调用决策。
通过initialize_agent整合LLM、工具集和记忆模块,形成闭环对话系统。
4、上下文感知的Prompt工程
采用PromptTemplate动态生成包含历史对话的提示词,例如:
from langchain.prompts import ChatPromptTemplate
template = "Previous chat:{history}\nCurrent question:{question}"
系统会自动将记忆内容填充到{history}占位符。
5、RAG(检索增强生成)集成
结合向量数据库实现知识检索,在对话过程中动态补充外部知识。
典型流程:用户提问→检索相关文档→结合对话历史生成回答。
实现示例代码结构:
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationalRetrievalChainmemory = ConversationBufferMemory()
chain = ConversationalRetrievalChain.from_llm(llm=Qwen_model,retriever=vector_db.as_retriever(),memory=memory
)
这种架构使系统能够:
- 跟踪对话主题演变;
- 处理指代消解(如"它"指代前文提到的实体);
- 支持长达数十轮的复杂对话;
综上,我们体会LangChain的多轮对话核心机制下来,如上1和4这两个点是今天和我们本文相关的重点。
执行流程 = 用户提问→检索相关文档→结合存储的对话历史拼接入Prompt模板→向模型发起请求→处理指代消解→模型生成回答。
二、多轮问答实现的常规流程
综上参考,我们已经基本可以发现实现多轮问答,需要具备的条件。
- 大模型具备指代消解能力;
- 需要外部机制处理历史对话的前置处理和存储;
常规流程 = 用户提问→历史对话存储(这里有可能会也根据实际先对场景对对话数据进行一轮处理,如指代消解、问答简化总结等)→拼接历史对话信息到Prompt模板 →模型进行总结响应输出
因此大模型本身具备基础的多轮问答能力(这里指结合prompt历史数据来综合分析的能力),但实现高质量的长程对话需结合外部机制优化。
大模型原生能力与局限性:
基础支持
大模型可通过会话历史上下文理解当前问题,这是其原生能力。例如将历史对话以 user/assistant 角色拼接输入,模型可基于最新提问生成连贯回复。
性能瓶颈
实验表明,所有主流大模型在多轮对话中的表现均显著低于单轮对话,平均性能下降39%。模型易在早期生成错误结论并难以纠正(称为“对话迷失”现象)。
三、什么是指代消解
上文中我们频繁提到“指代消解”一词,可见它在处理多轮对话中是很重要的一种能力存在。我们认为,模型只有在能够充分理解并处理这些指代消息的情况下,才能更好地保证多轮问答效果。那什么是指代消解呢?
指代消解(Coreference Resolution)是自然语言处理(NLP)中的一项基础任务,旨在识别文本中指向同一实体的不同指代表达式,并将它们关联起来。简单来说,就是确定代词(如“他”、“她”、“它”)或名词短语具体指的是哪个实体。
例子分析:
文本示例
李雷在公园散步。他看到一只流浪猫,这只猫很瘦弱,于是李雷把它带回了家。
指代消解任务目标
找出所有指向同一实体的表达,并建立关联:
李雷 → 他 → 李雷一只流浪猫 → 这只猫 → 它
四、实战案例
纸上得来终觉浅,我们尝试根据一个实际场景来实战说明一下。
1、大模型messages的多轮对话

很多同学说,简单啊,不管三七二十一,我上来就是一把梭,我们按照prompt把每次对话都作存储,然后下一轮来的时候把对话历史传给大模型自己识别指代消解不就全搞定了。你说的对啊!理论上是一点问题都没有的,毕竟模型自己具备了指代消解的理解能力。
#多轮对话组织示例
messages = [{"role":"system","content":"你是一个旅行规划专家,擅长推荐冷门景点"},{"role":"user","content":"我想去巴塞罗那看建筑"}, {"role":"assistant","content":"推荐圣家堂和米拉之家,对高迪作品感兴趣吗?"}, {"role":"user","content":"更喜欢人少的小众景点"} ]
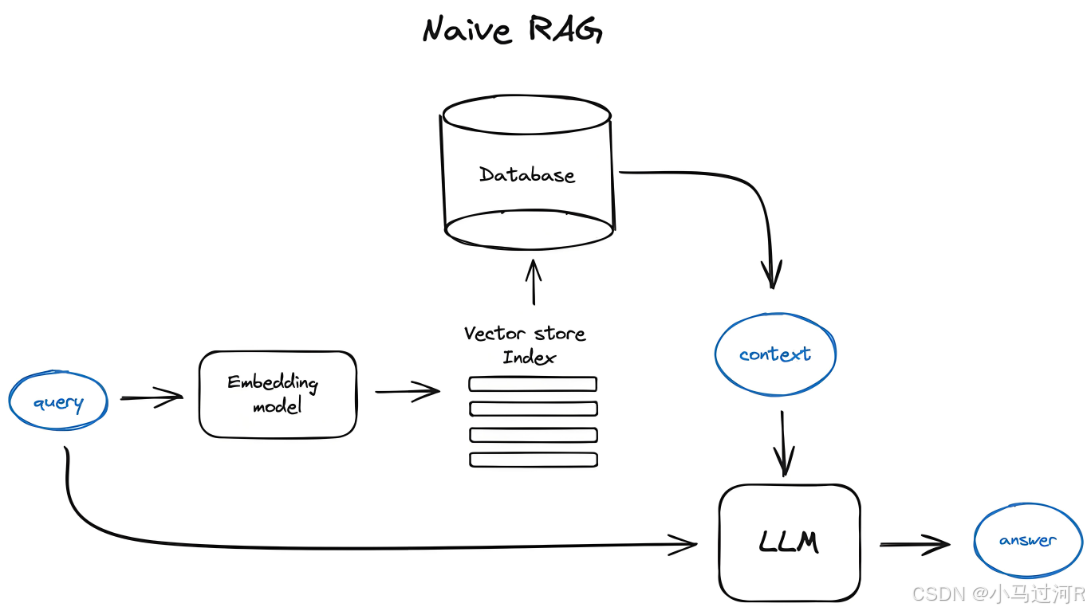
但实际上由于我们的问答系统实现一般是RAG架构(不了解RAG的可以阅读引言提到的这篇文章《如何5分钟快速搭建智能问答系统》,所以我们的真实处理流程是:
用户提问->问题与知识库的相似度匹配->拼接prompt请求大模型->大模型总结输出答案
事情开始变得有趣了。我们之前认为的多轮问答的场景问题居然不是上面那样的,而是现在下面这样的,这两者所面临的问题似乎完全不一样。
2、RAG下的多轮对话
当是多轮的时候,常规情况下我们也是上面这个流程,但是我们会面临着一个多轮问题的匹配召回问题。比如,我们的问题Q1是“南京的特产是什么?”,那么正常一轮是拿Q1去做召回匹配,没问题,召回后模型总结输出,假设模型响应A1是“南京的特产是盐水鸭”。
但是我们要是支持多轮的话,那么用户接下来连着的第二个问题Q2很可能是“它真的很好吃吗?”。那么根据我们的RAG架构流程,自然此时会拿Q2去作匹配召回,结果可想而知,召回的知识库肯定会不符合我们的诉求,因为它的主体没了,知识库资料相似度召回肯定偏得离谱。我们知道,在一个非常依赖RAG外部知识库的垂直业务系统中失去知识库内容的召回这将是致命的。
我们需要如何解决这个问题呢?
事实上,LangChain已经为我们想好了这个问题的解决方案,可以阅读《LangChain与Agent实现》 这篇文章的 “LangChain MultiQueryRetriever通过自动生成多个查询视角来增强检索效果“部分。
在人工智能和自然语言处理领域,高效准确的信息检索一直是一个关键挑战。传统的基于距离的向量数据库检索方法虽然广泛应用,但仍存在一些局限性。一种创新的解决方案:MultiQueryRetriever,它通过自动生成多个查询视角来增强检索效果,提高结果的相关性和多样性。该方案可以解决RAG里前半部分中对问题相识度匹配的局限性,可以更加精准匹配知识库,取出更全面的参考资料给与大模型总结。
MultiQueryRetriever 的核心思想是利用语言模型(LLM)为单个用户查询生成多个不同视角的查询。这种方法有效地自动化了提示工程的过程,克服了传统向量检索中由于查询措辑微小变化或嵌入语义捕获不佳而导致的结果不稳定问题。
所以说现在的小孩是多么得幸福,啥都有了。
啊?!不对,再来。这个貌似是重点解决问题多样性衍生匹配的,不是针对指代消解场景的。搞错了。
算了,那如果我们要是自己来解决RAG多轮问答问题该如何解决呢?
这里的核心问题是,我们最新的问题Q2没办法通过相似度匹配找到我们想要的答案辅助材料。因此,我们要想办法将Q2进行指代消解处理,通过指代消解将它还原出来本来的问题意思,即Q2处理完应该是Q2.1为“盐水鸭真的很好吃吗?”。这种消除了指代的问题描述就能很好支持知识库召回匹配了。
好了,我们的问题已经转变为如何通过Q1、A1、Q2 转化出Q2.1。这就是典型的指代消解问题,我们的大模型不是正好具备这块能力吗,那就安排上。于是我们的prompt案例是这样的。
#prompt请一步步思考:
根据用户的历史问答,判断当前问题是否需要做指代消解或省略补全?
用一个单词回答:[是]或[否]。
如果回答[是],则对当前问题进行指代消解或省略补全,然后输出处理后的问题。
如果回答[否],则输出当前问题的原始内容。
按照json格式输出:{"replace":"[是]或[否]","result":"问题"}
历史问答:{
Q:南京的特产是什么
A:南京的特产是盐水鸭
Q:它真的很好吃吗
A:整体味道还不错,就是有点咸。
Q:有什么食用建议呢?
A:建议配着米饭吃。
}
当前问题:{那米饭需要用五常大米做吗?}
回答是:
这个时候,模型一般会输出:
{"replace": "是", "result": "盐水鸭需要配着用五常大米做的米饭吃吗?"}
至此,我们已经顺利拿到Q2.1,将Q2.1进行RAG的流程就能得到最终答案啦。问题解决啦!
理是这么个理,而事实上,很多模型的指代消解能力并不是我们想的这么理想,特别还是在垂直业务下的话效果再次减弱。于是我们可以对模型这块指代消解能力的特定任务微调。不懂如何微调模型的同学可以参考这里《模型微调(Fine-tuning)实践》。
实际场景中历史数据拼接prompt的时候可能还面临着历史数据对模型上下文窗口长度的挑战,注意把控轮数,做好理论和实际之间的平衡。