TF-IDF——红楼梦案例
目录
用 TF-IDF 挖掘《红楼梦》各回目核心关键词:一个 NLP 实践案例
一、案例背景与目标
二、实现步骤
步骤 1:数据准备与分卷处理
1. 导入模块与创建目录
2. 打开源文件并初始化变量
3. 逐行处理文本内容
4. 写入卷内容并过滤前两行
5. 关闭最后一卷并输出完成信息
步骤2:文本预处理与分词
1. 导入依赖库
2. 读取分卷文本文件
3. 数据存储为 DataFrame
4. 加载自定义词库和停用词表
5. 分词与清洗处理
3.基于 TF-IDF 的《红楼梦》关键词提取
1. 导入依赖库
2. 读取分词后的数据
3. 初始化 TF-IDF 向量器并计算矩阵
4. 获取词汇表并转换为 DataFrame
5. 提取并打印每回目的 Top10 关键词
完整代码及运行结果如下:
用 TF-IDF 挖掘《红楼梦》各回目核心关键词:一个 NLP 实践案例
在自然语言处理中,TF-IDF 是一种经典的文本特征提取方法,尤其适合挖掘文本中的核心关键词。本文以《红楼梦》为例,通过 Python 实现从文本分卷、分词到 TF-IDF 关键词提取的完整流程,带大家直观感受 NLP 技术在古典文学分析中的应用。
一、案例背景与目标
《红楼梦》是中国古典小说的巅峰之作,全书共 120 回,情节复杂,人物众多(仅主要人物就超过 400 个)。各回目围绕不同的核心事件展开(如黛玉进府、元妃省亲、抄检大观园等),蕴含丰富的主题信息。
本案例目标:
- 将《红楼梦》全文按回目拆分,建立分卷文本库;
- 对文本进行分词、去停用词等预处理;
- 利用 TF-IDF 算法提取每回目的 Top10 核心关键词;
- 通过关键词分析各回目的主题侧重,验证 TF-IDF 在古典文学分析中的有效性。
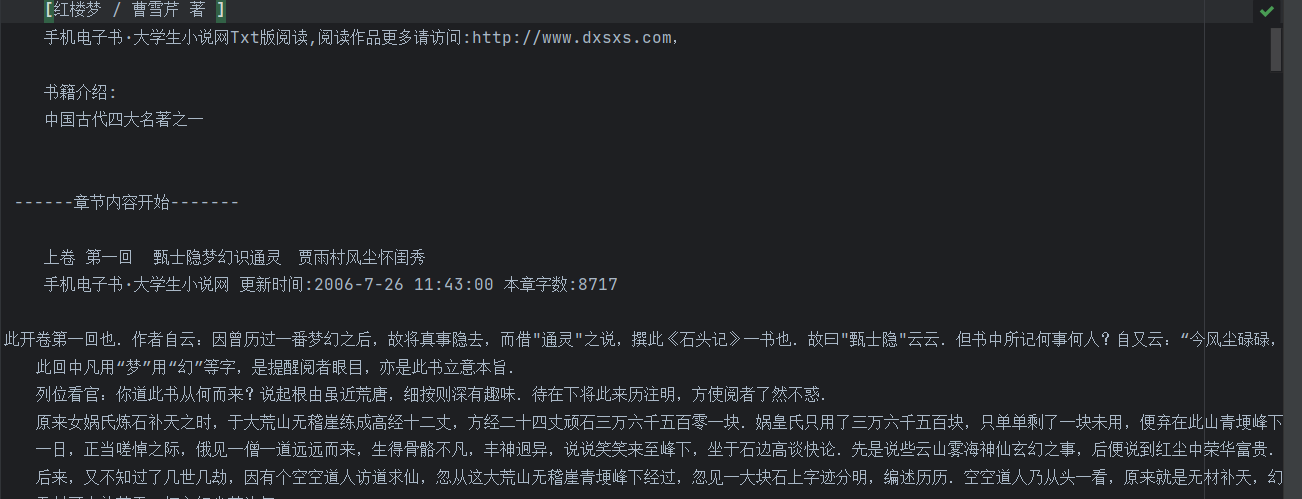
数据集如下:
二、实现步骤
步骤 1:数据准备与分卷处理
整个代码分为三个主要部分:
- 创建存储分卷文件的目录
- 读取全文并按卷拆分
- 关闭文件并输出完成信息
1. 导入模块与创建目录
import os
os.makedirs('.\\红楼梦\\红楼梦分卷', exist_ok=True)import os:导入 Python 的 os 模块,用于处理文件和目录操作os.makedirs(...):创建多级目录- 路径
.\\红楼梦\\红楼梦分卷表示在当前目录下创建 "红楼梦" 文件夹,其内再创建 "红楼梦分卷" 子文件夹 exist_ok=True是一个非常实用的参数:如果目录已存在则不报错,避免程序因目录已存在而终止
2. 打开源文件并初始化变量
- 路径
with open('红楼梦.txt', 'r', encoding='utf-8') as file:current_juan = None # 当前卷的文件对象line_counter = 0 # 计数当前卷的行数(用于跳过前两行)with open(...) as file:使用 with 语句打开源文件,自动管理文件关闭'红楼梦.txt'是源文件路径(假设与脚本在同一目录)'r'表示只读模式encoding='utf-8'指定编码为 utf-8,确保中文正常读取current_juan = None:用于保存当前正在写入的卷文件对象,初始化为 Noneline_counter = 0:计数器,用于记录当前卷已读取的行数,方便后续过滤前两行
3. 逐行处理文本内容
for line in file:# 检测到新卷标题if '卷 第' in line:# 关闭上一卷(如果存在)if current_juan:current_juan.close()# 生成新卷文件名和路径juan_name = line.strip() + '.txt'path = os.path.join('.\\红楼梦\\红楼梦分卷', juan_name)print(f"正在写入:{path}")# 打开新卷文件,重置行数计数器current_juan = open(path, 'w', encoding='utf-8')line_counter = 0 # 新卷从0开始计数continuefor line in file:逐行读取源文件内容if '卷 第' in line:判断当前行是否包含卷标题标记(如 "卷 第一"、"卷 第二十")- 如果是新卷标题,先检查
current_juan是否存在(即是否已有打开的卷文件),如果存在则关闭 juan_name = line.strip() + '.txt':处理卷标题,strip()去除换行符和空格,加上.txt作为文件名os.path.join(...):拼接目录和文件名,生成完整路径print(f"正在写入:{path}"):输出日志,方便跟踪进度current_juan = open(...):以写入模式打开新的卷文件line_counter = 0:重置计数器,新卷从 0 开始计数continue:跳过当前行(不将卷标题写入文件)
4. 写入卷内容并过滤前两行
if current_juan:line_counter += 1if line_counter > 2: # 只写入第3行及以后的内容current_juan.write(line)if current_juan:只有当存在打开的卷文件时才执行(避免处理文件开头到第一卷之前的内容)line_counter += 1:行数计数器加 1if line_counter > 2:判断是否超过前两行,只写入第 3 行及以后的内容(过滤卷标题后的空行或引言)current_juan.write(line):将符合条件的行写入当前卷文件
5. 关闭最后一卷并输出完成信息
# 关闭最后一卷
if current_juan:current_juan.close()
print("分卷完成,已自动删除每卷前两行")- 循环结束后,检查是否还有未关闭的卷文件(最后一卷),如果有则关闭
- 输出完成信息,提示用户分卷操作已完成
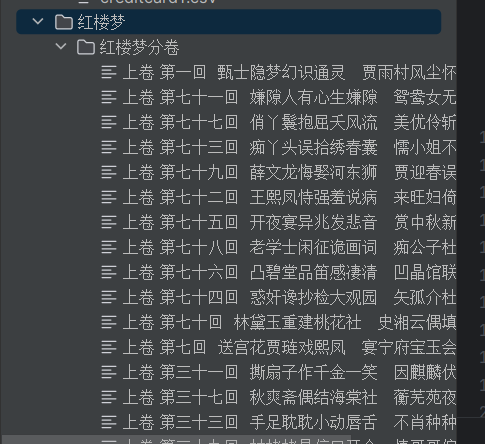
分卷结果如下:
步骤2:文本预处理与分词
代码整体功能:
- 读取之前分卷处理好的《红楼梦》文本文件
- 使用 jieba 进行中文分词
- 过滤停用词(无意义的词汇)
- 将处理后的分词结果保存到文件
1. 导入依赖库
import pandas as pd
import os
import jiebapandas:用于数据处理和存储os:用于文件和目录操作jieba:中文分词库,专门用于将中文文本拆分为词语
2. 读取分卷文本文件
filePaths = []
fileContents = []
for root, dirs, files in os.walk(r"红楼梦"):for name in files:filePath = os.path.join(root, name)filePaths.append(filePath)f = open(filePath, 'r', encoding='utf-8')fileContent = f.read()f.close()fileContents.append(fileContent)filePaths:存储所有分卷文件的路径fileContents:存储所有分卷文件的内容os.walk(r"红楼梦"):遍历 "红楼梦" 目录及其子目录下的所有文件root:当前目录路径dirs:当前目录下的子目录列表files:当前目录下的文件列表- 循环读取每个文件的完整路径和内容,分别存入两个列表
3. 数据存储为 DataFrame
corpos = pd.DataFrame({'filePath': filePaths,'fileContent': fileContents})- 将文件路径和内容组合成一个 DataFrame(表格型数据结构)
- 这样处理便于后续按行遍历和处理每个分卷的内容
corposDataFrame 包含两列:filePath(文件路径)和fileContent(文件内容)
4. 加载自定义词库和停用词表
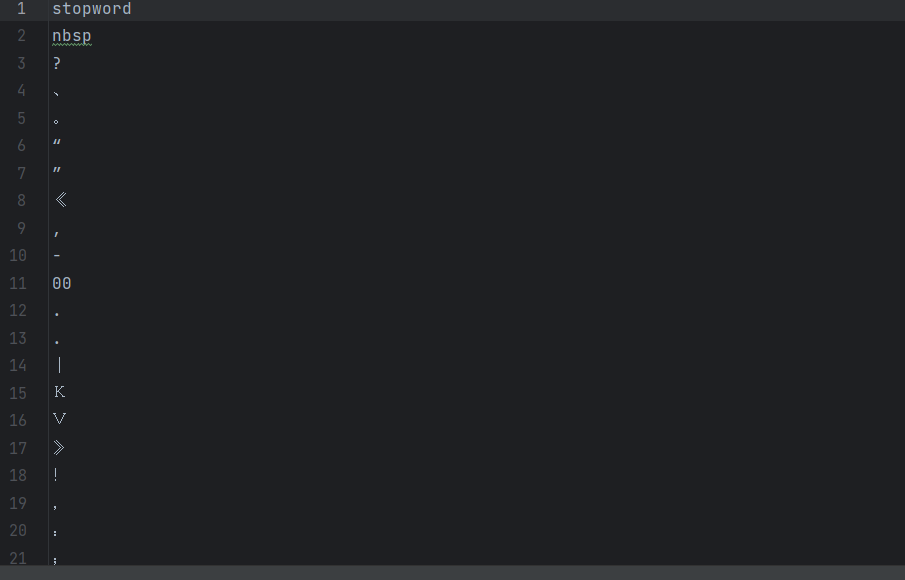
停用词如下:
词库如下:
jieba.load_userdict("红楼梦词库.txt")
stopwords = pd.read_csv("stopwordsCN.txt", encoding='utf8', engine='python', index_col=False)jieba.load_userdict("红楼梦词库.txt"):加载《红楼梦》专用词库- 词库中包含小说中的人名、地名、特定术语等,提高分词准确性
- 例如确保 "贾宝玉" 不被拆分为 "贾"、"宝玉"
pd.read_csv(...):读取中文停用词表- 停用词包括 "的"、"了"、"在" 等无实际意义但出现频率高的词
engine='python':避免中文编码相关的警告index_col=False:不将任何列作为索引
5. 分词与清洗处理
file_to_jieba = open('分词后汇总.txt', 'w', encoding='utf-8')
for index, row in corpos.iterrows():juan_ci = ''fileContent = row['fileContent']segs = jieba.cut(fileContent)for seg in segs:if seg not in stopwords.stopword.values and len(seg.strip()) > 0:juan_ci += seg + ' 'file_to_jieba.write(juan_ci + '\n')
file_to_jieba.close()open('分词后汇总.txt', 'w', encoding='utf-8'):创建文件存储分词结果corpos.iterrows():遍历 DataFrame 中的每一行(即每一卷)jieba.cut(fileContent):对当前卷的文本进行分词- 过滤逻辑:
seg not in stopwords.stopword.values:排除停用词len(seg.strip()) > 0:排除空字符串和纯空格
juan_ci += seg + ' ':将过滤后的词语用空格连接- 每一卷的分词结果写入文件,一行对应一卷
处理之后的数据如下:

3.基于 TF-IDF 的《红楼梦》关键词提取
代码整体功能
- 读取分词后的文本数据
- 计算各回目的 TF-IDF 矩阵
- 提取每回目的 Top10 关键词并打印结果
1. 导入依赖库
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pdTfidfVectorizer:scikit-learn 中用于计算 TF-IDF 值的工具类,能自动完成词频统计、逆文档频率计算和标准化pandas:用于数据处理,将 TF-IDF 矩阵转换为 DataFrame 便于分析
2. 读取分词后的数据
with open('分词后汇总.txt', 'r', encoding='utf-8') as infile:chapters = infile.readlines()with open(...):以只读模式打开之前生成的分词结果文件chapters = infile.readlines():按行读取文件内容,每一行对应《红楼梦》的一个回目(已分词并过滤停用词)- 此时
chapters是一个列表,例如:["宝玉 黛玉 贾母 ...", "凤姐 平儿 大观园 ...", ...]
3. 初始化 TF-IDF 向量器并计算矩阵
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(chapters)TfidfVectorizer():初始化向量器,使用默认参数(后续可根据需求调整,如max_features限制词汇量)fit_transform(chapters):对分词后的文本进行拟合和转换- 拟合(fit):分析文本,构建词汇表并计算每个词的逆文档频率(IDF)
- 转换(transform):计算每个回目中每个词的词频(TF),并结合 IDF 生成 TF-IDF 值
- 输出的
tfidf_matrix是一个稀疏矩阵,形状为(回目数, 词汇数),例如:如果有 120 回目、5000 个独特词汇,矩阵形状为(120, 5000)
4. 获取词汇表并转换为 DataFrame
wordlist = vectorizer.get_feature_names_out()
df = pd.DataFrame(tfidf_matrix.T.todense(), index=wordlist)vectorizer.get_feature_names_out():获取词汇表(所有不重复的词),返回一个数组,例如:["宝玉", "黛玉", "贾母", ...]tfidf_matrix.T:将矩阵转置(行和列互换),形状从(回目数, 词汇数)变为(词汇数, 回目数)todense():将稀疏矩阵转换为稠密矩阵(便于后续处理,小数据量适用)pd.DataFrame(...):创建 DataFrame,行索引为词汇表中的词,列索引为回目索引,值为对应的 TF-IDF 值
5. 提取并打印每回目的 Top10 关键词
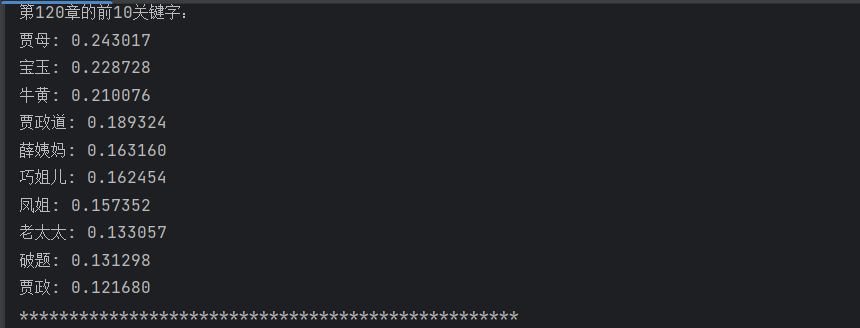
for chapter_idx in range(len(chapters)):# 获取当前回目的TF-IDF值(按词汇排序)chapter_tfidf = df.iloc[:, chapter_idx]# 按TF-IDF值降序排序,取前10个词top_keywords = chapter_tfidf.sort_values(ascending=False).head(10)# 打印结果print(f"第{chapter_idx + 1}章的前10关键字:")for word, score in top_keywords.items():print(f"{word}: {score:.6f}") # 保留6位小数print("*" * 50) # 分隔线,增强可读性for chapter_idx in range(len(chapters)):遍历每个回目df.iloc[:, chapter_idx]:提取当前回目的所有词的 TF-IDF 值(DataFrame 的一列)sort_values(ascending=False).head(10):按 TF-IDF 值从高到低排序,取前 10 个词(核心关键词)- 打印格式说明:
chapter_idx + 1:回目编号(从 1 开始,而非 0)word: score:关键词及其 TF-IDF 值,值越高说明该词对当前回目的代表性越强
运行结果如下:
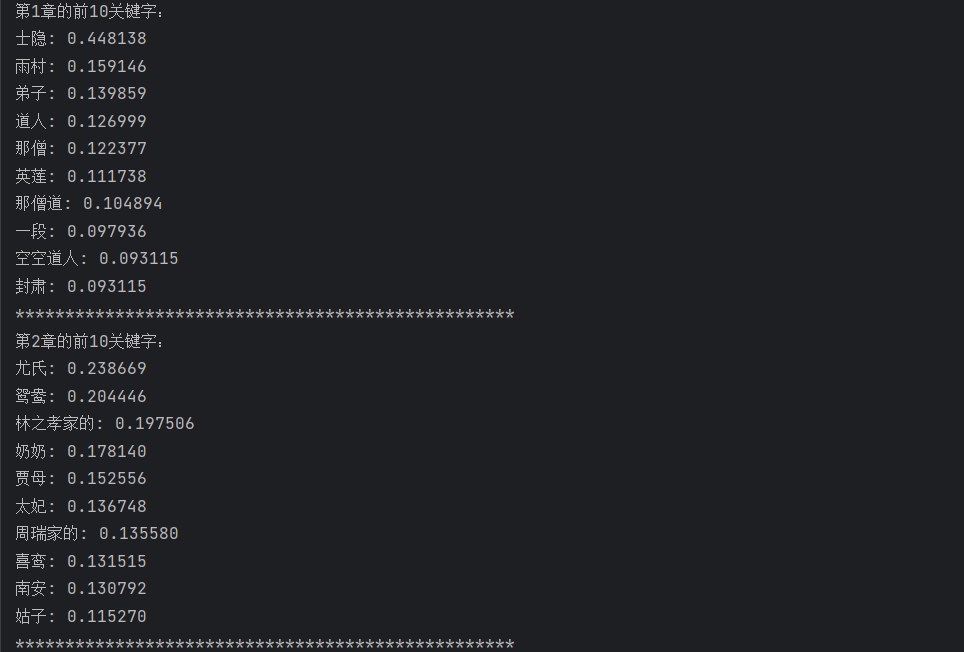
完整代码及运行结果如下:
import os
os.makedirs('.\\红楼梦\\红楼梦分卷', exist_ok=True)# 打开源文件
with open('红楼梦.txt', 'r', encoding='utf-8') as file:current_juan = None # 当前卷的文件对象line_counter = 0 # 计数当前卷的行数(用于跳过前两行)for line in file:# 检测到新卷标题if '卷 第' in line:# 关闭上一卷(如果存在)if current_juan:current_juan.close()# 生成新卷文件名和路径juan_name = line.strip() + '.txt'path = os.path.join('.\\红楼梦\\红楼梦分卷', juan_name)print(f"正在写入:{path}")# 打开新卷文件,重置行数计数器current_juan = open(path, 'w', encoding='utf-8')line_counter = 0 # 新卷从0开始计数continueif current_juan:line_counter += 1if line_counter > 2: # 只写入第3行及以后的内容current_juan.write(line)# 关闭最后一卷if current_juan:current_juan.close()
print("分卷完成,已自动删除每卷前两行")import pandas as pd
import os
import jieba
filePaths = []
fileContents = []
for root, dirs, files in os.walk(r"红楼梦"):for name in files:filePath = os.path.join(root, name)filePaths.append(filePath)f = open(filePath, 'r', encoding='utf-8')fileContent = f.read()f.close()fileContents.append(fileContent)
corpos = pd.DataFrame({'filePath': filePaths,'fileContent': fileContents})
jieba.load_userdict("红楼梦词库.txt")
stopwords = pd.read_csv("stopwordsCN.txt", encoding='utf8', engine='python', index_col=False)
file_to_jieba = open('分词后汇总.txt', 'w', encoding='utf-8')
for index, row in corpos.iterrows():juan_ci = ''fileContent = row['fileContent']segs = jieba.cut(fileContent)for seg in segs:if seg not in stopwords.stopword.values and len(seg.strip()) > 0:juan_ci += seg + ' 'file_to_jieba.write(juan_ci + '\n')
file_to_jieba.close()from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
with open('分词后汇总.txt', 'r', encoding='utf-8') as infile:chapters = infile.readlines()
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(chapters)
wordlist = vectorizer.get_feature_names_out()
df = pd.DataFrame(tfidf_matrix.T.todense(), index=wordlist)
for chapter_idx in range(len(chapters)):chapter_tfidf = df.iloc[:, chapter_idx]top_keywords = chapter_tfidf.sort_values(ascending=False).head(10)print(f"第{chapter_idx + 1}章的前10关键字:")for word, score in top_keywords.items():print(f"{word}: {score:.6f}")print("*" * 50)