Python函数篇:从零到精通
一、函数
1.1 为什么有函数
我们对于一个项目时,会有上千甚至上万条代码,当我们要使用到某个函数时,例如我需要计算一个求和代码,获得求和的值来服务我们的项目,那我们可能会这样
#计算1~100的和
theSun = 0
for i in range(1,101):theSun += i
print(theSun)#计算100~400的和
theSun = 0
for i in range(100,401):theSun += i
print(theSun)#计算1000~2300的和
theSun = 0
for i in range(1000,2301):theSun += i
print(theSun)大家会发现,我们每次需要求出不同值的和,都需要重新手打一次代码,好烦赘,那有没有什么别的方法来方便我们呢?
有的兄弟,有的,像这种方法有很多,今天先讲讲函数
我们先把上面的代码使用函数来优化一下:
#函数定义
def calcSum(beg, end):theSum = 0for i in range(beg, end + 1):theSum += i print(theSum)# 函数调用
calcSum(1, 100)
calcSum(100, 400)
calcSum(1000, 2300)
✅ 优势:
- 代码只写一次,复用多次
- 修改只需改一处
- 逻辑清晰,易于理解
1.1 函数的定义格式
def 函数名(参数):函数体(要执行的代码)return 返回值
def:关键字,表示“我要定义一个函数”函数名:给函数起个名字,要见名知意,比如greet,add_numbers(参数):可选,函数需要的“原材料”return:可选,表示“把结果交出来”
1.1.1 最简单的函数(没有回参)
def say_hello():print("Hello! 欢迎来到Python世界!")# 调用函数
say_hello()🔍 强调:
定义函数 ≠ 执行函数!
必须调用它,才会执行。
1.1.2 带参数的函数
就拿我们刚刚的求和来举例
#函数定义
def calcSum(beg, end):theSum = 0for i in range(beg, end + 1):theSum += i # 修正变量名拼写错误 theSun -> theSumprint(theSum)# 函数调用
calcSum(1, 100) # 输出 5050参数就像“占位符”,调用时传入具体值。
1.1.3 带返回值的函数
def add(a, b):result = a + breturn result # 把结果“交出来”# 调用并接收结果
total = add(3, 5)
print(f"Sum = {total}")🔍 强调:
return不是打印!它是“把结果传递出去”,可以赋值给变量、参与计算等。
二、函数的定义与调用
定义:可以看作是布置任务
调用:可以看作是开始完成任务
2.1 定义语法
def 函数名(参数列表):函数体return 返回值2.2 调用语法
函数名(实际参数)
def greet():print("Hello! 欢迎你!")greet() # 调用函数
greet() # 可以调用多次两者少任何一个都不行,两者往往相伴相随
2.3 函数定义和调用的顺序规则
遵循规则:
定义在前,调用在后
#eroor
r = add(3,5)
print(r)def add(x,y):return x+y
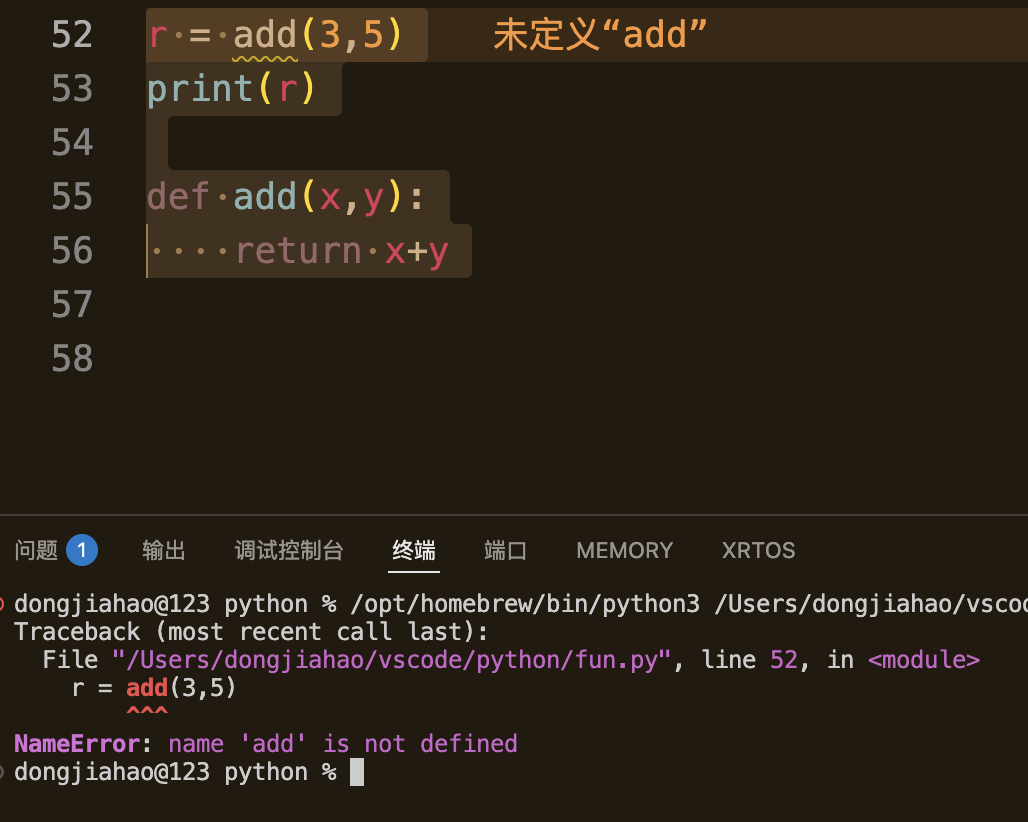
大家可以看到如果将位置颠倒一下会出现错误,这是因为Python执行代码是从上到下的,如果位置调换了那么我们定义的函数Python是并没有接受到的,就像这张图片显示的 未定义"add"
三、函数的参数
3.1 核心思想:函数参数是什么?为什么重要?
本质: 函数参数是函数与外界沟通的桥梁。它们是函数定义时预留的“占位符”,允许你在调用函数时传入具体的数据(值或引用)。
参数是函数的“原材料”。
3.2 形参 vs 实参
- 形参(形式参数):定义时的变量名,如
def add(a, b) - 实参(实际参数):调用时传入的具体值,如
add(3, 5)
def add(a,b):return a+b #形参r = add(3,5) #实参
print(r)3.2.1 位置形参
定义: 最常见的形参。它们按照在函数定义中出现的顺序接收传递进来的实参。
语法: 直接写形参名,例如
def greet(name, greeting):特点:
调用函数时,传递的实参数量必须与位置形参的数量严格匹配(除非有默认值或可变参数)。
实参的顺序决定了它们赋值给哪个形参。
def calculate_area(length, width): # length 和 width 是位置形参area = length * widthreturn area# 调用: 实参 5 按顺序赋值给 length, 3 赋值给 width
result = calculate_area(5, 3) # result = 15
# 错误调用: calculate_area(3) # 缺少一个参数
# 错误调用: calculate_area(5, 3, 2) # 多了一个参数 (除非有可变参数)2.参数传递的过程
def introduce(name, age):print(f"我叫{name},今年{age}岁")introduce("小明", 18) # name="小明", age=18四、函数的返回值
函数的参数可以视为是函数的 "输入", 则函数的返回值, 就可以视为是函数的 "输出"
return是函数的“产出物”。
4.1 有返回值
def add(a, b):return a + bresult = add(3, 5) # result = 84.2 无返回值
def say_hello():print("Hello")x = say_hello() # x = None4.3
def calcSum(beg, end):theSum = 0for i in range(beg, end + 1):theSum += i print(theSum)calcSum(1,12)大家看这个代码并没有什么不对,但是我们程序员写代码时,比较喜欢一个函数干一件事这一原则,使用我们可以把这个代码修改一下
def calcSum(beg, end):theSum = 0for i in range(beg, end + 1):theSum += i return theSumr = calcSum(1,12)
print(f'theSum = {r}')这样我们的calcSum函数就只有一个求和这一职能,可以大大提高我们对代码的阅读性和可维护性
4.4 一个函数多个return
一个函数中可以有多个return语句
#判断是否为偶数
def isOdd(num):if num % 2 == 0:return Trueelse:return Falser = isOdd(4)
print(r)
执行到 return 语句, 函数就会立即执行结束, 回到调用位置.
那么我们根据这一特性,我们可以将这个代码修改一下,使我们的代码更加易读
#判断是否为偶数
def isOdd(num):if num % 2 == 0:return Truereturn Falser = isOdd(4)
print(r)
当我们把4传到num时,函数来判断4是否为偶数
- 这时候,如果num(值为4) % 2 没有余数,则进入"return True",跳出函数
- 如果num(值为4) % 2 有余数,函数到"return True"发现并不符合,则再进入"return False",跳出函数
所以我们发现,这两个代码虽然复杂度不同,但是效果是等价的
4.4 使用逗号来分割多个return
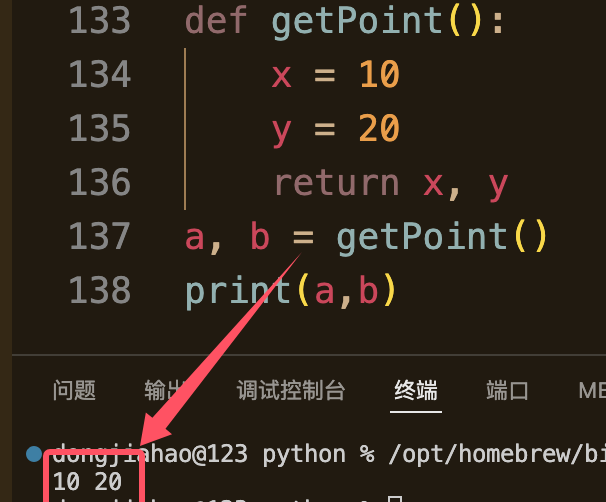
def getPoint():x = 10y = 20return x, y
a, b = getPoint()
print(a,b)我们可以看到这个代码,返回了两个值,中间是用逗号来分割,调试后确实获得了10和20
4.5 使用"_"来忽略部分return
def getPoint():x = 10y = 20return x,y_,b = getattr()五、变量作用域
变量作用域。这决定了变量在哪里“活”着,在哪里能被“看见”和修改。
想象一下,在一个大公司里:
- 部门内部(如财务部)有自己的专用术语和文件(
部门变量),只有本部门的人能直接看到和使用。- 公司层面有全公司通用的规则和资源(
公司变量),所有部门都能访问。- 不同部门可能碰巧用了同一个名字指代不同东西(比如“预算”),但在各自部门内互不干扰。
Python的作用域规则与此非常相似。它定义了变量名(标识符)在代码的哪些区域是有效的、可被访问的。主要的作用域层级称为 LEGB 规则。
5.1 LEGB 规则:查找名字的四层“洋葱”
5.1.1 L: Local (局部作用域)
- 定义: 当前正在执行的函数或方法内部定义的变量。
- 生命周期: 从变量在函数内部被赋值的那一刻开始,到函数执行结束时销毁。
- 访问: 仅限在该函数内部访问。外部代码无法直接看到或修改它。
def calculate_sum(a, b): # a, b 也是此函数的局部变量!result = a + b # result 是局部变量print(result) # 在函数内部可以访问 resultreturn resulttotal = calculate_sum(5, 3) # 调用函数
# print(result) # 错误!result 是 calculate_sum 的局部变量,在此处不存在
print(total) # 正确,total 是全局变量 (下面会讲)5.1.2 Enclosing (闭包作用域 / 非局部作用域)
它揭示了 Python 中一个非常重要的概念:函数可以“记住”它被创建时的环境。
- 定义: 在嵌套函数结构中,外层函数(非全局)的作用域。这是LEGB中比较特殊的一层。
- 生命周期: 与外层函数的执行周期相关。即使内层函数被返回并在其他地方调用,只要内层函数还持有对外层变量的引用,外层函数的这个作用域就不会完全销毁(这就是闭包的核心)。
- 访问: 内层函数可以读取外层函数作用域中的变量。但要修改它,在Python 3中需要使用
nonlocal关键字(稍后详解)
def outer_function(message): # outer_function 的作用域# message 是 outer_function 的局部变量# 但对 inner_function 是 Enclosing 作用域def inner_function(): # inner_function 的作用域 (Local)# 内层函数可以访问外层函数的变量 message (读取)print("Message from outer:", message)return inner_function # 返回内层函数本身,而不是调用它my_closure = outer_function("Hello, Scope!") # 调用 outer_function# 返回 inner_function
my_closure() # 调用 inner_function, 输出: Message from outer: Hello, Scope!
# 注意:此时 outer_function 已经执行完毕
#但它的局部变量 message 仍然能被 my_closure (即 inner_function) 访问到!代码逐行解析
第1行:
def outer_function(message):
- 定义一个外层函数
outer_function- 它有一个参数
message,这个message是它的局部变量就像你进了一个房间(函数),带了一个行李箱(
message)
第3行:
def inner_function():
- 在
outer_function内部,又定义了一个函数inner_function- 这叫嵌套函数(Nested Function)
inner_function可以访问外层函数的变量message🔍 这是关键!内层函数能看到外层的“行李箱”
第5行:
return inner_function
- 注意!是
inner_function,不是inner_function()- 意思是:返回这个函数本身,而不是调用它
- 就像把“打开行李箱的钥匙”交了出去
第8行:
my_closure = outer_function("Hello, Scope!")
- 调用
outer_function,传入"Hello, Scope!"- 此时:
message = "Hello, Scope!"inner_function被定义outer_function返回inner_function这个函数对象- 重点:
outer_function的执行已经结束了!❓ 问题来了:
message是outer_function的局部变量,函数都结束了,message不应该被销毁吗?
第9行:
my_closure()
- 调用我们之前保存的
inner_function- 它仍然能访问到
message,并正确打印!✅ 输出:
Message from outer: Hello, Scope!
5.1.2.1 核心概念:什么是闭包(Closure)?
💬 闭包 = 函数 + 它的“环境”
专业定义:
当一个内层函数引用了外层函数的变量,并且这个内层函数被返回或传递到外部时,就形成了一个闭包。
在这个例子中:
inner_function是内层函数- 它引用了外层的
message- 它被返回给了外部
- → 所以
my_closure是一个闭包
5.1.3 Global (全局作用域)
定义: 在任何函数或类之外,在模块(
.py文件)顶层定义的变量。生命周期: 从模块被导入或执行时创建,到程序结束或模块被卸载时销毁。
访问: 模块内的任何函数通常都可以读取全局变量。但是,要修改全局变量,必须在函数内部使用
global关键字显式声明(否则Python会认为你在创建一个新的同名局部变量)。
# 定义一个全局变量
game_score = 0
player_name = "小明"print(f"游戏开始!玩家:{player_name},当前得分:{game_score}")def increase_score(points):# 想要修改全局变量,必须用 global 声明global game_scoregame_score = game_score + pointsprint(f" 获得 {points} 分!当前得分:{game_score}")def show_status():# 只读取全局变量,不需要 globalprint(f" 状态:玩家 {player_name},得分 {game_score}")def reset_game():# 修改多个全局变量global game_score, player_namegame_score = 0player_name = "无名氏"print(" 游戏已重置!")# ===== 游戏过程模拟 =====
show_status() # 状态:玩家 小明,得分 0increase_score(10) # 获得 10 分!当前得分:10
increase_score(5) # 获得 5 分!当前得分:15show_status() # 状态:玩家 小明,得分 15reset_game() # 游戏已重置!show_status() # 状态:玩家 无名氏,得分 05.1.4 Built-in (内建作用域)
- 定义: Python预先定义好的名字,比如
print(),len(),int(),str(),list(),True,False,None等。它们在任何地方都可用。- 生命周期: Python解释器启动时创建,解释器退出时销毁。
- 访问: 在代码的任何位置都可以直接使用。除非你在更内层的作用域(Local, Enclosing, Global)中定义了同名的变量覆盖了它们! (一般不建议这样做,会让人困惑)。
# 在任何地方都可以使用内建函数和常量
print(len([1, 2, 3])) # 输出: 3
value = int("42")
flag = True# 危险:覆盖内建函数 (不推荐!)
def dangerous_function():# 在这个函数内,str 不再是内建函数,而是一个局部变量str = "I shadowed the built-in str!" # 覆盖 (shadow) 了内建 strprint(str) # 输出: I shadowed the built-in str!# print(str(100)) # 错误!此时str是字符串,不是函数了dangerous_function()
# 在函数外部,str 还是内建函数
print(str(100)) # 输出: '100'代码讲解:
第一部分:正常使用内置函数
print(len([1, 2, 3])) # 输出: 3 value = int("42") flag = True✅ 这就像你正常使用手机上的“电话”、“短信”、“相机”这些系统自带功能。
len():求长度,像“尺子”int():转整数,像“翻译官”str():转字符串,像“打印机”这些都是Python准备好的“工具箱”,我们可以随时使用它们
第二部分:危险操作——“冒名顶替”
def dangerous_function():str = "I shadowed the built-in str!" # 覆盖了内置的 strprint(str) # 输出: I shadowed the built-in str!# print(str(100)) # ❌ 这行被注释了,但一旦打开就出错!这就像你在手机里新建了一个联系人,名字也叫“电话”!
结果:当你想打电话时,手机不知道你是想用“打电话功能”,还是想给“名叫‘电话’的人”发消息。详细解释:
原本
str是 Python 的内置函数,比如str(100)能把数字 100 变成字符串"100"。但现在你在函数里写:
str = "...",这就相当于说:“从现在起,
str不再是‘转换成字符串’的功能了,它只是一个普通的字符串变量!”所以:
print(str)→ 输出那个字符串,没问题。print(str(100))→ 想把 100 转成字符串?不行! 因为str现在是字符串,不是函数,字符串不能被“调用”(就像你不能“打电话”给一个文字)。第三部分:函数外面还是安全的
dangerous_function() # 调用上面那个“危险函数”print(str(100)) # 输出: '100'✅ 这就像:
你只在“某个房间”(函数)里把“电话”这个名字占用了,但出了这个房间,手机功能还是正常的!
str = "..."这个“冒名顶替”只在dangerous_function这个函数内部有效。- 一旦函数执行完,这个“局部变量”就消失了。
- 所以在函数外面,
str依然是那个强大的“字符串转换工具”。
六、函数执行过程
6.1执行过程演示
#函数执行过程
def test():print("执行函数内部代码")print("执行函数内部代码")print("执行函数内部代码")print("1111")
test()
print("2222")
test()
print("3333")这里我们用一个图来解释上面这个代码的执行过程
程序开始↓
定义 test() 函数(不执行)↓
print("1111") → 输出:1111↓
test() → 跳进函数↓(进入函数)print(...) → 输出:执行函数内部代码 ×3↓(函数结束)← 跳回原位置↓
print("2222") → 输出:2222↓
test() → 再次跳进函数↓(进入函数)print(...) → 输出:执行函数内部代码 ×3↓(函数结束)← 跳回原位置↓
print("3333") → 输出:3333↓
程序结束
6.2 核心知识点总结
| 概念 | 说明 |
|---|---|
| 函数定义 | def 只是“写菜谱”,不会执行 |
| 函数调用 | test() 是“按菜谱做饭”,才会执行里面的代码 |
| 执行顺序 | 从上往下,遇到函数调用就“跳进去”,执行完再“跳回来” |
| 可重复使用 | 同一个函数可以被多次调用,代码只写一次 |
七、链式调用和嵌套调用
7.1 嵌套调用
# 简单的嵌套调用
result = abs(round(3.14159, 2)) # 先四舍五入到2位小数,再取绝对值
print(result) # 输出: 3.14
# 多层嵌套示例
def add(a, b):return a + bdef square(x):return x * xdef format_result(value):return f"结果: {value}"# 三层嵌套
output = format_result(square(add(3, 4)))
print(output) # 输出: "结果: 49"主要看 output = format_result(square(add(3, 4)))
- 这句代码先调用format_result()
- 再找到里面的square()
- 接着找到里面的add()
- 先计算add的值,计算后把值传到square函数,最后传到format_result()
7.2 嵌套调用的优缺点对比表
| 类别 | 优点 | 缺点 |
|---|---|---|
| 代码结构 | ✅ 代码紧凑,减少冗余<br>✅ 减少中间变量的使用 | 容易形成“括号地狱”层级过深时结构混乱 |
| 表达能力 | ✅ 能直接表达操作的先后顺序和逻辑关系<br>✅ 适合数学公式或函数式编程风格 | ❌ 多层嵌套时逻辑不直观,难以快速理解执行流程 |
| 可读性 | ✅ 表达简洁,一气呵成 | ❌ 可读性随嵌套深度增加而显著降低 初学者难以理解 |
| 调试与维护 | —— | ❌ 调试困难:无法在中间步骤轻松插入 print或断点 错误定位复杂:报错信息可能只指向最外层调用,难以确定具体出错层级 |
| 命名与作用域 | ✅ 减少临时变量命名需求,降低命名冲突风险 | ❌ 无法复用中间结果,不利于重复使用 |
7.3 链式调用
概念:链式调用是指连续调用同一对象的方法,每个方法返回对象自身(或新对象),从而可以继续调用其他方法。
链式调用的实现原理:
链式调用的关键是每个方法都返回对象本身(
return self)或返回一个新对象。
#判断是否为偶数
def isOdd(num):if num % 2 == 0:return Truereturn Falser = isOdd(4)
print(r)
将这个代码改成链式:
#链式
#判断是否为偶数
def isOdd(num):if num % 2 == 0:return Truereturn Falseprint(isOdd(10))链式调用(Chained Call)的优缺点
| 类别 | 优点 | 缺点 |
|---|---|---|
| 代码风格 | ✅ 代码流畅,像自然语言一样“一气呵成”<br>✅ 操作序列清晰可见,逻辑连贯 | —— |
| 可读性 | ✅ 可读性高(当链较短时)<br>✅ 支持方法调用的自然顺序,符合思维流程 | ❌ 链过长时可读性下降,变成“方法瀑布” |
| 变量管理 | ✅ 减少中间临时变量的使用<br>✅ 避免命名污染和命名冲突 | —— |
| 设计要求 | —— | ❌ 需要精心设计类结构<br>❌ 每个方法必须返回 self(或新对象),否则无法链式 |
| 调试与维护 | —— | ❌ 调试困难:无法在链的中间插入 print 或断点查看状态<br>❌ 错误处理复杂:一旦出错,难以定位是哪一步失败 |
| 容错性 | —— | ❌ 链中任意一步出错,整个调用失败<br>❌ 不便于对中间结果进行验证或日志记录 |
八、函数递归
递归的核心
- “大事化小”:把大问题变成小问题。
- “找到终点”:必须有一个最简单的情况直接解决。
- “自己调用自己”:小问题的解法和大问题一样。
递归的两个关键要素:
基线条件:问题的最简单情况,可以直接得到答案
递归条件:将问题分解为更小的同类子问题
递归的黄金法则:每个递归调用都必须向基线条件靠近
8.1 经典递归案例
1. 阶乘函数:n!
def factorial(n):# 1. 递归出口(最简单的情况)if n == 1:return 1# 2. 递归关系(自己调用自己)return n * factorial(n - 1)print(factorial(5)) # 输出:120调用栈分析(n = 5)
factorial(5)
├── 5 * factorial(4)├── 4 * factorial(3)├── 3 * factorial(2)├── 2 * factorial(1)│ └── return 1 ← 出口!└── return 2*1 = 2└── return 3*2 = 6└── return 4*6 = 24
└── return 5*24 = 120从这个调用栈可以看出,factorial自己调用了三次
8.2 递归三要素!!!
| 要素 | 说明 | 错了会怎样? |
|---|---|---|
| 1. 递归关系 | 问题如何分解?f(n) = ... f(n-1) ... | 逻辑错误,算不出正确结果 |
| 2. 递归出口 | 最简单的情况是什么?if n == 1: return 1 | 无限递归 → 栈溢出! |
| 3. 逐步逼近出口 | 每次调用,问题规模是否变小?factorial(n-1) | 死循环,程序崩溃 |
🚨 特别强调:
没有出口的递归,就像没有终点的楼梯,会把计算机“累死”!(内存是有极限的,如果没有出口会造成溢出)