从 GPT-2 到 gpt-oss:架构进步分析
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

OpenAI 本周刚刚发布了新的开源权重 LLM 模型:gpt-oss-120b 和 gpt-oss-20b,这是自 2019 年 GPT-2 以来首次推出的开源权重模型。是的,由于一些巧妙的优化,这些模型可以在本地运行(稍后会详细介绍)。
这是自 GPT-2 以来,OpenAI 第一次公开一个大型、完全开源权重的模型。早期的 GPT 模型展示了 Transformer 架构的可扩展性。2022 年 ChatGPT 的发布则让这些模型走向主流,展示了它们在写作、知识(后来包括编程)任务中的具体实用性。现在,他们终于分享了期待已久的权重模型,其架构中有一些颇有意思的细节。
作者在过去几天里阅读了代码和技术报告,整理出最有趣的细节。(就在几天后,OpenAI 还宣布了 GPT-5,本文最后会结合 gpt-oss 模型简单讨论一下它。)
以下是本文的主要内容预览。为了更方便阅读,建议在文章页面左侧使用目录导航。
- 与 GPT-2 的模型架构对比
- 将 gpt-oss 模型适配到单 GPU 的 MXFP4 优化
- 宽度与深度的取舍(gpt-oss 对比 Qwen3)
- Attention 偏置与“Sink”
- 基准测试及与 GPT-5 的对比
希望这些内容对读者有所帮助!
1. 模型架构概览
在深入探讨架构之前,先来看看 gpt-oss-20b 和 gpt-oss-120b 这两款模型的整体情况,如下图 1 所示。
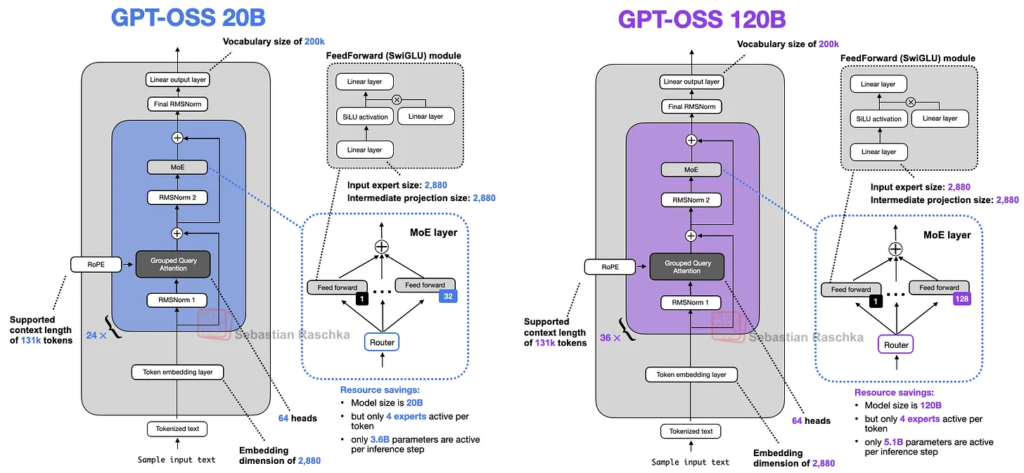
如果之前看过近期 LLM 的架构图,或者读过作者之前的《大型架构对比》文章,可能会注意到,乍一看这两款模型并没有特别新颖或反常的地方。
这并不令人意外,因为领先的 LLM 开发者往往使用相同的基础架构,然后再进行一些小调整。作者的个人猜测是:
- 这些实验室之间的员工流动性很高;
- 目前还没有找到比 Transformer 架构更好的东西。尽管存在状态空间模型(state space models)和文本扩散模型(text diffusion models),但据作者所知,还没有人证明它们在这种规模上能与 Transformer 的表现相媲美。(作者发现的大多数对比研究都集中在基准测试性能上,还不清楚这些模型在真实的、多轮写作和编程任务中表现如何。截至撰文时,LM Arena 排名最高的非纯 Transformer 模型是 Jamba,它是 Transformer–状态空间模型的混合体,排名第 96。补充说明:有人指出还有一个排名更高的混合模型——Hunyuan-TurboS,排在第 22。)
- 大多数性能提升可能来自数据和算法上的调整,而不是架构上的重大变革。
尽管如此,他们在设计上的一些选择仍然很有意思,有些已经在上图中展示(还有一些没展示,稍后会讨论)。本文余下部分会逐一介绍这些特性,并与其他架构进行比较。
需要说明的是,作者与 OpenAI 没有任何关系。本文的信息来自对已发布的模型代码的审查以及技术报告的阅读。如果想了解如何在本地使用这些模型,建议访问 OpenAI 官方模型主页:
https://huggingface.co/openai/gpt-oss-20b
https://huggingface.co/openai/gpt-oss-120b
20B 模型可在配备 16 GB 显存的消费级 GPU 上运行。120B 模型可在单张 80 GB 显存的 H100 或更新硬件上运行。稍后会讨论其中的重要注意事项。
2. 从 GPT-2 说起
在比较 gpt-oss 与更新架构之前,先“坐上时光机”,将 GPT-2 与它放在一起对比(见图 2),看看这些年到底有哪些变化。
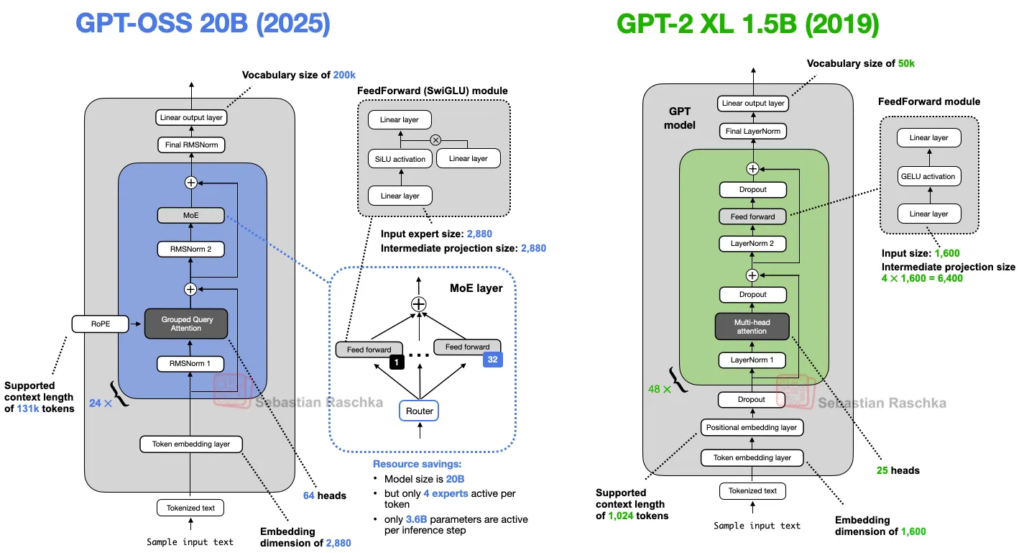
gpt-oss 和 GPT-2 都是基于 Transformer 架构的仅解码(decoder-only)LLM,这种架构最早在 2017 年的《Attention Is All You Need》论文中提出。多年来,很多细节发生了演变。
不过,这些变化并不是 gpt-oss 独有的,很多其他 LLM 中也能看到。作者在之前的《大型架构对比》中已经讨论过许多方面,这里会尽量简短而集中地介绍。
2.1 移除 Dropout
Dropout(2012)是一种防止过拟合的传统技术,通过在训练过程中随机“丢弃”(即设为零)部分层激活值或注意力分数(见图 3)来实现。然而,在现代 LLM 中很少使用 Dropout,大多数 GPT-2 之后的模型都去掉了它(双关非故意)。
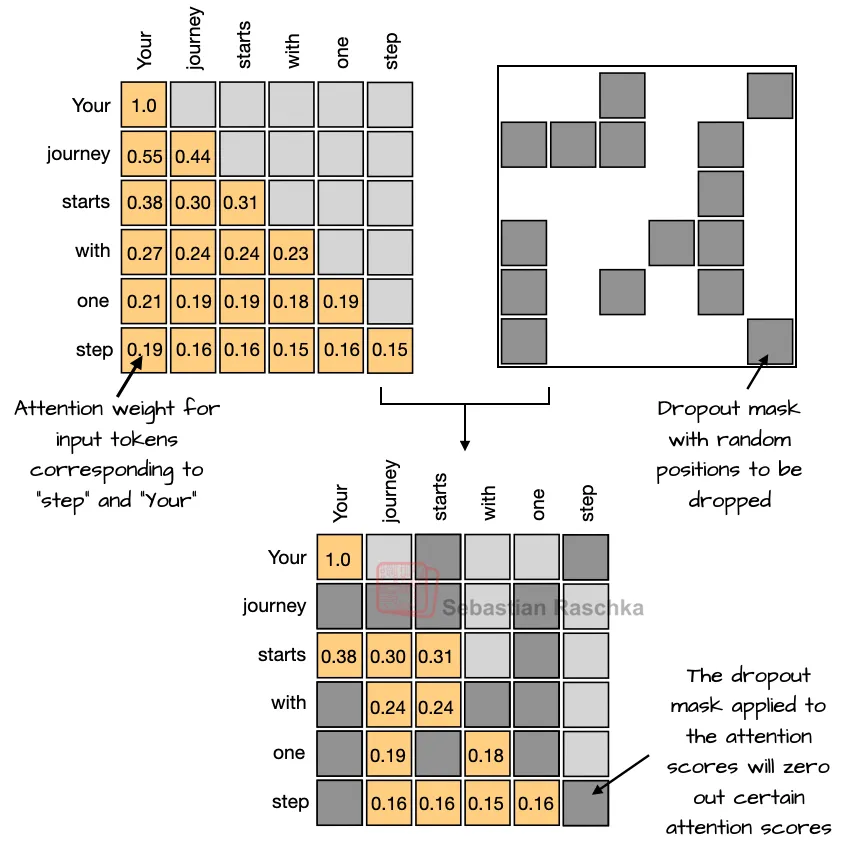
作者推测,GPT-2 使用 Dropout 可能是沿用了原始 Transformer 架构的设计。但研究人员后来发现,它并没有真正提高 LLM 性能(作者在自己小规模的 GPT-2 复现实验中也观察到同样结果)。这可能是因为 LLM 通常只在庞大的数据集上训练一个 epoch,而 Dropout 最初是为训练数百个 epoch 的任务设计的。在 LLM 中,由于训练过程中每个 token 只出现一次,过拟合风险很低。
有趣的是,虽然 Dropout 在 LLM 架构设计中多年被忽略,但作者在 2025 年看到一篇针对小规模 LLM(Pythia 1.4B)的研究,证实在单 epoch 训练环境中,Dropout 会导致下游性能变差。
2.2 RoPE 取代绝对位置编码
在基于 Transformer 的 LLM 中,位置编码是必要的,因为注意力机制默认认为输入 token 是无序的。原始 GPT 架构通过绝对位置嵌入(absolute positional embeddings)来解决这个问题,即为序列中每个位置添加一个可学习的嵌入向量(见图 4),再与 token 嵌入相加。
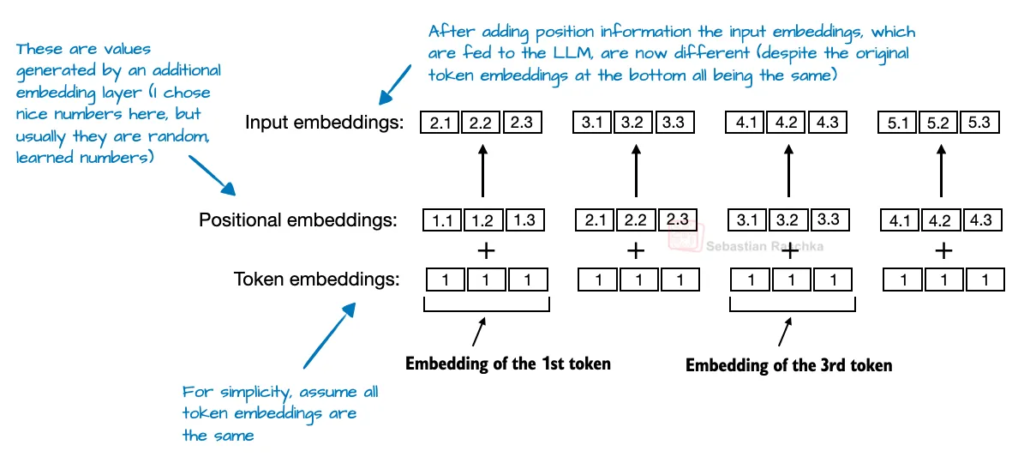
RoPE(旋转位置编码,Rotary Position Embedding)引入了另一种方法:它不是将位置信息作为独立嵌入相加,而是通过依赖于 token 位置的方式旋转查询向量和键向量来编码位置信息。
RoPE 首次提出于 2021 年,并在 2023 年 Llama 模型发布后被广泛采用,成为现代 LLM 的标配。
2.3 Swish/SwiGLU 取代 GELU
早期 GPT 架构使用 GELU 激活函数。Swish 相比 GELU 计算成本略低,这可能是它取代 GELU 的主要原因。不同论文对二者性能孰优的结论不同,这些差异可能在标准误差范围内,而且结果高度依赖超参数选择。
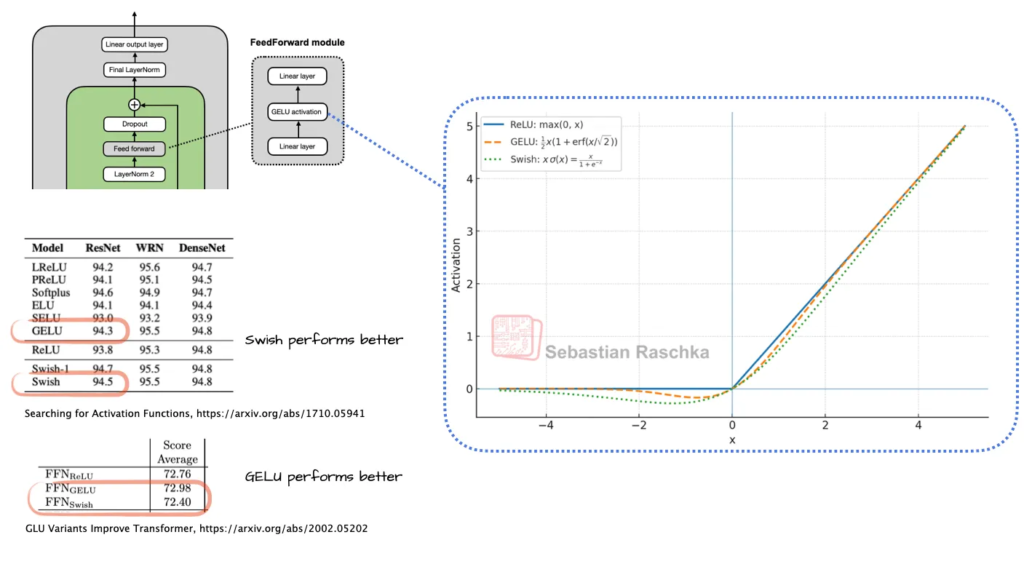
此外,传统的前馈模块(Feed Forward Module)也被门控线性单元(GLU)变体替代,如 SwiGLU。这种结构通过引入额外的乘性交互提升了表达能力,同时参数量还更少。
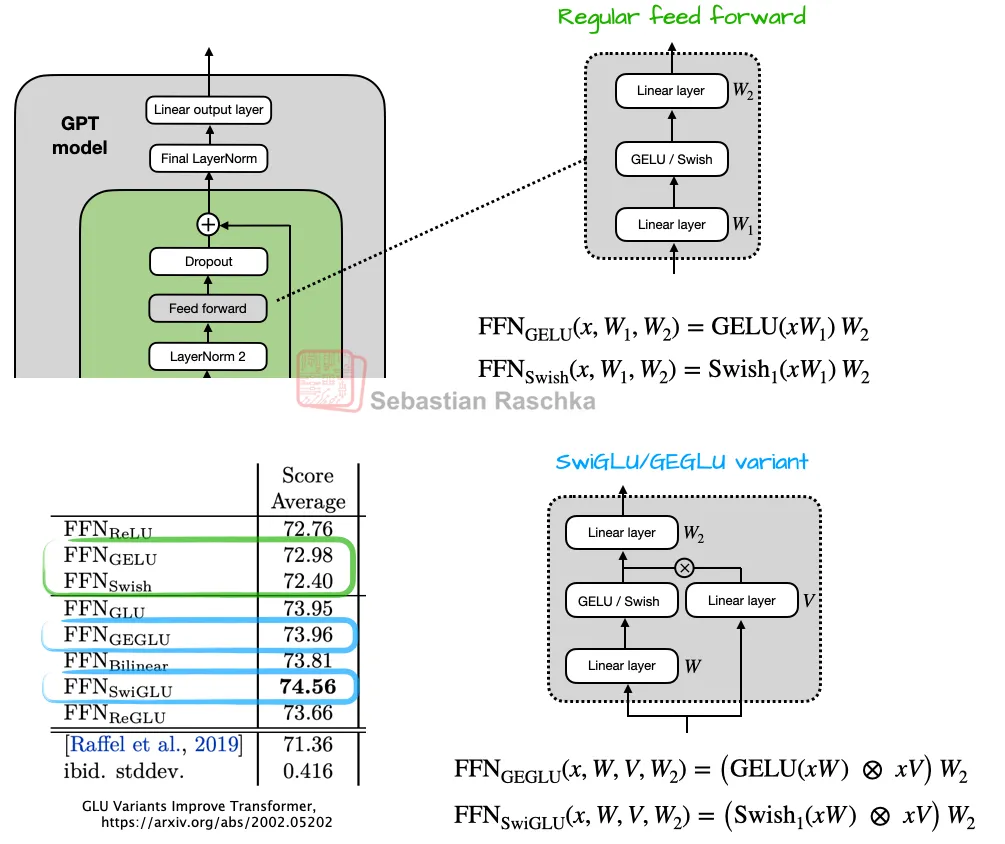
2.4 专家混合(MoE)取代单一前馈模块
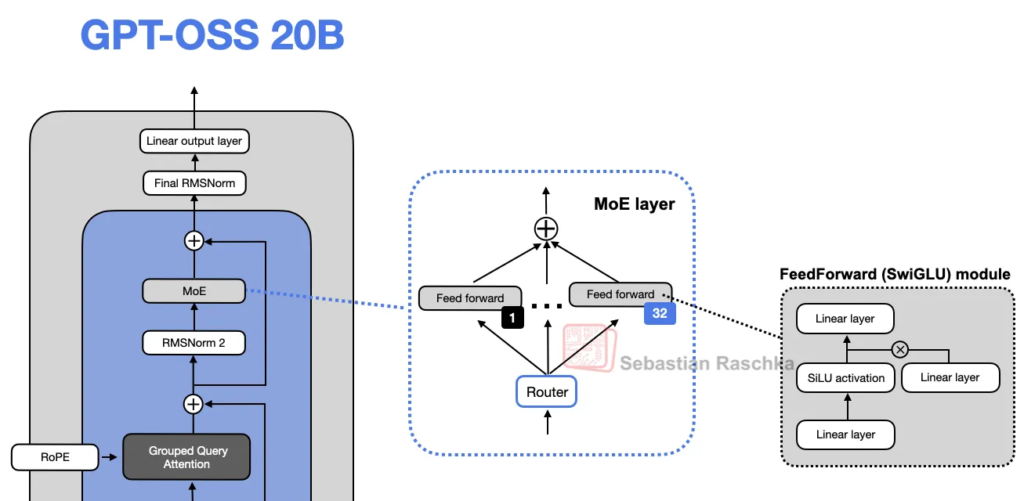
gpt-oss 还用专家混合模块(Mixture-of-Experts, MoE)替代了单一的前馈模块。在 MoE 中,有多个前馈模块,但每次生成 token 时只激活一小部分专家,从而在增加模型容量的同时保持推理效率。
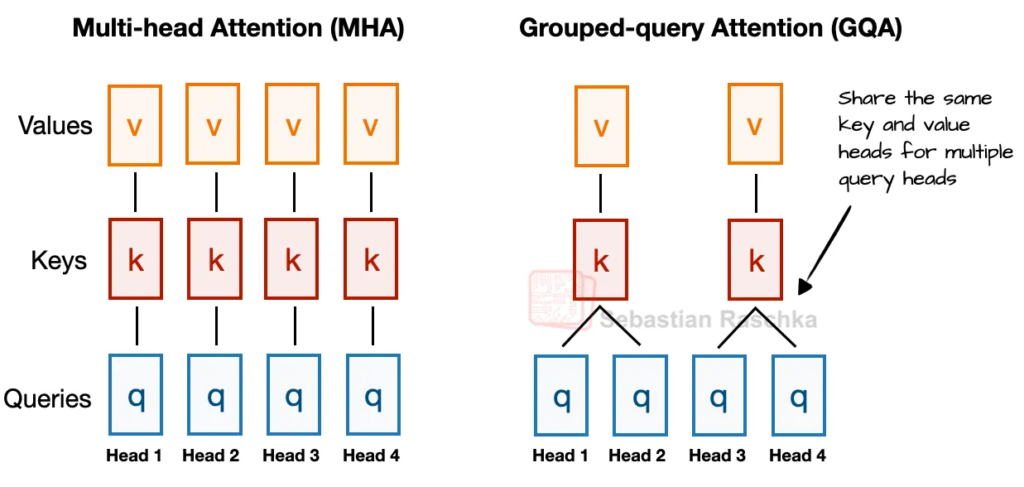
2.5 分组查询注意力(GQA)取代多头注意力(MHA)
GQA 通过让多个注意力头共享同一组键和值,减少了内存使用和计算量,同时保持了接近 MHA 的建模性能。
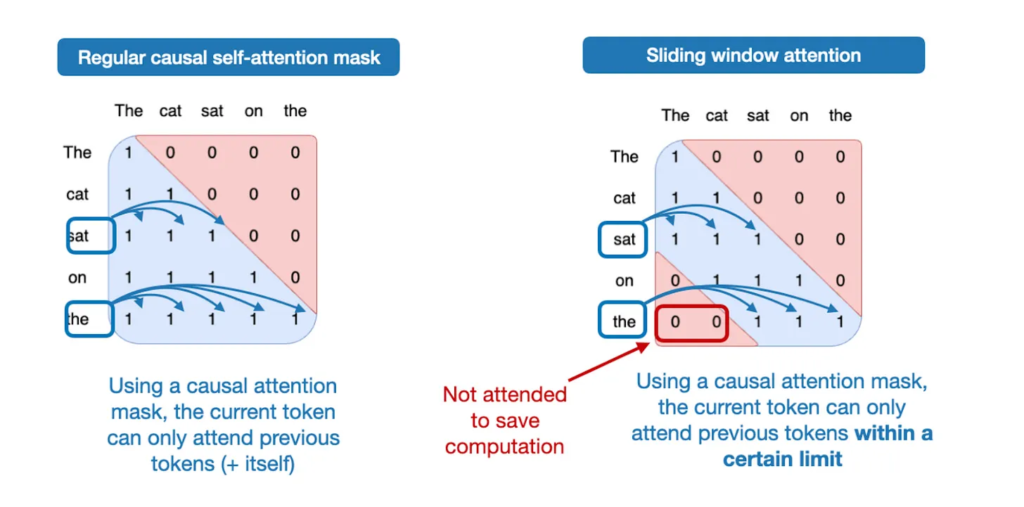
2.6 滑动窗口注意力
gpt-oss 在每隔一层中使用滑动窗口注意力,将注意力范围限制在 128 个 token 内,以降低计算和显存消耗。这种技术最早在 LongFormer(2020)中提出,后被 Mistral 推广。
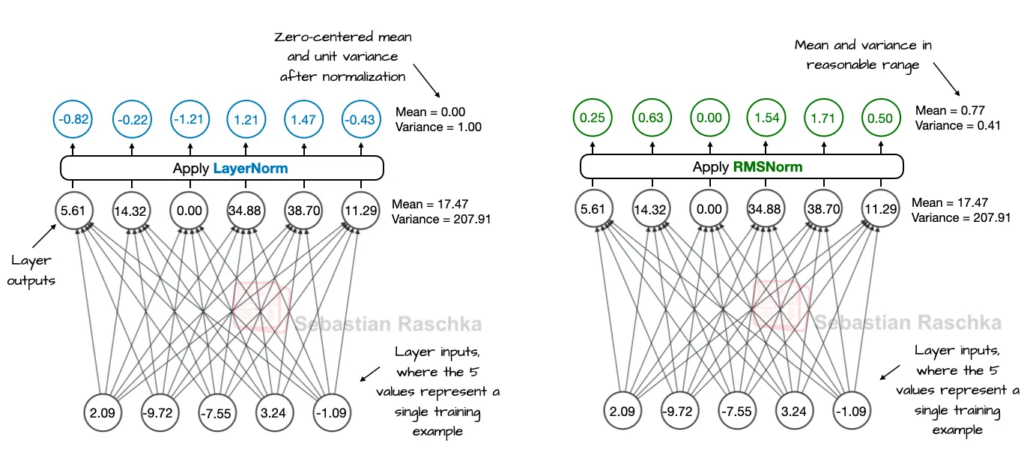
2.7 RMSNorm 取代 LayerNorm
RMSNorm 是近年来流行的替代 LayerNorm 的方法,它计算成本更低,因为只需要一次均方根归一化,而不需要计算均值和方差。
2.8 GPT-2 的遗产
GPT-2 依然是学习 LLM 架构的优秀入门模型,足够简单,便于理解核心原理,同时又包含 Transformer 模型的关键组成部分。先掌握 GPT-2,有助于更好地理解后续架构改进的意义和作用。
作者甚至建议在实现更复杂模型前,先手写一遍 GPT-2,比如他最近就在 GPT-2 代码的基础上从零实现了 Qwen3 架构,而 Qwen3 与 gpt-oss 非常相似,这也引出了下一个主题:将 gpt-oss 与更新架构对比。