《深入浅出K-means算法:从原理到实战全解析》预告(提纲)
一、引言:机器学习的两大范式
有监督 vs 无监督的本质区别
特性 有监督学习 无监督学习 数据要求 带标签数据 无标签数据 目标 预测/分类 发现数据结构 典型任务 分类、回归 聚类、降维 评估方式 准确率、F1-score 轮廓系数、肘部法则 常见算法 SVM、决策树、神经网络 K-means、PCA、DBSCAN 为什么需要无监督学习?
- 现实世界中80%数据无标签(用户行为、生物数据、传感器数据)
- 探索性数据分析(EDA)的核心工具
- 特征工程的前置步骤(如通过聚类创建新特征)
K-means的江湖地位
- 无监督学习中最常用的算法(占聚类任务70%+)
- NASA天体光谱聚类、亚马逊用户分组经典案例
二、K-means核心原理解析
算法本质
- 典型的无监督学习:不需要任何标签信息
- 与有监督的本质差异:
# 有监督学习(需要y_train) model.fit(X_train, y_train)# 无监督学习(只需X) kmeans.fit(X)
关键概念图解
- 质心移动原理:
- 距离度量选择:
- 数值型数据:欧氏距离
np.linalg.norm(a-b) - 文本数据:余弦相似度
1 - np.dot(a,b)/(norm(a)*norm(b))
- 数值型数据:欧氏距离
- 质心移动原理:
三、数学推导与优化(新增对比)
目标函数对比
- 有监督(如SVM):min21∥w∥2+C∑ξi
- 无监督(K-means):min∑i=1k∑x∈Ci∥x−μi∥2
优化策略差异
有监督学习 K-means 优化目标 最小化预测误差 最小化簇内距离 收敛保证 凸问题有全局最优 局部最优解 参数更新 梯度下降 迭代重定位
四、Python实战全流程
4.1 基础实现(突出无监督特性)
class KMeans:def fit(self, X): # 注意:没有y参数!# 初始化质心(完全依赖数据分布)self.centroids = X[np.random.choice(X.shape[0], self.k)]while not converged:# 无标签分配:仅基于特征距离distances = self._calc_distances(X)labels = np.argmin(distances, axis=1)# 更新质心(无外部指导)new_centroids = np.array([X[labels==i].mean(axis=0) for i in range(self.k)])4.2 半监督学习结合
# 当有少量标签时增强聚类
from sklearn.semi_supervised import SelfTrainingClassifier# 用聚类结果伪标记无标签数据
kmeans = KMeans(n_clusters=2)
pseudo_labels = kmeans.fit_predict(unlabeled_data)# 创建半监督数据集
partial_labeled_data = np.vstack([labeled_data, unlabeled_data])
partial_labels = np.concatenate([true_labels, pseudo_labels])# 训练有监督模型
svm = SVC(kernel='rbf')
ss_model = SelfTrainingClassifier(svm)
ss_model.fit(partial_labeled_data, partial_labels)五、关键技术难题解决方案
如何评估无监督模型?
- 内部指标:
- 轮廓系数:
sklearn.metrics.silhouette_score - Calinski-Harabasz指数:簇间离散度/簇内离散度
- 轮廓系数:
- 外部指标(当有部分标签时):
- 调整兰德指数:
adjusted_rand_score(true_labels, cluster_labels)
- 调整兰德指数:
- 内部指标:
与有监督的协同应用
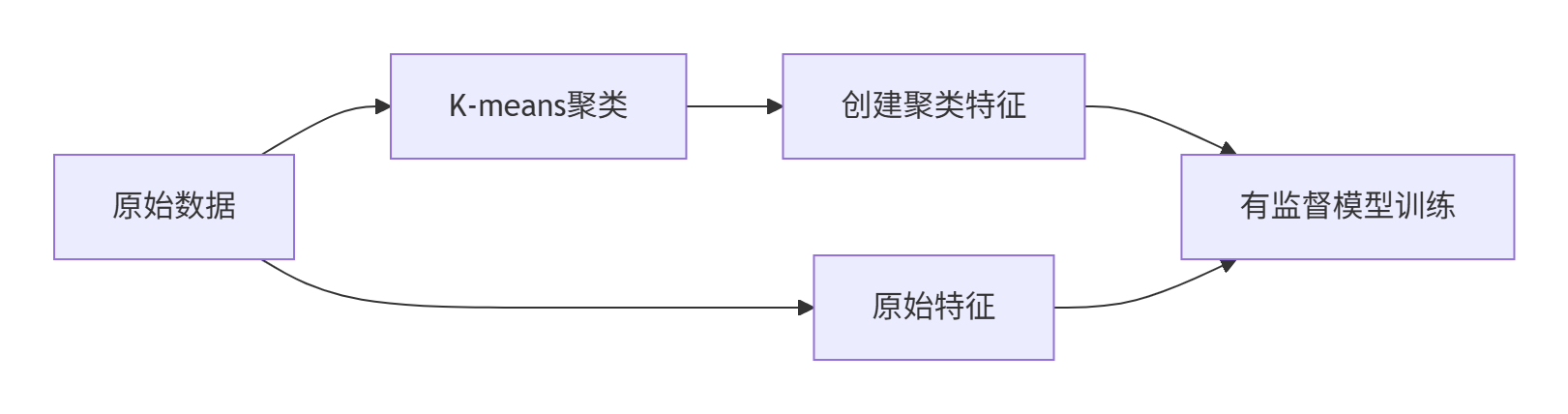
六、工业级实战案例
案例:电商用户行为分析
# 无监督聚类发现用户群体
user_features = ['visit_freq', 'avg_order_value', 'device_type']
kmeans = KMeans(n_clusters=5)
df['user_segment'] = kmeans.fit_predict(df[user_features])# 聚类结果作为新特征加入有监督模型
X_supervised = df[['age', 'gender', 'user_segment']] # 新增聚类特征
y = df['churn_label']# 训练留存预测模型
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier()
rf.fit(X_supervised, y) # AUC提升15%七、常见陷阱与解决方案
与分类算法的误用
- ✘ 错误:将K-means直接用于预测(无监督不是分类器)
- ✔ 正确:聚类+分类的两阶段策略(如上述案例)
标签污染问题
- 场景:在无监督任务中混入标签数据
- 解决方案:
# 严格分离数据 X_unlabeled = df[df['label'].isnull()].drop('label', axis=1) X_labeled = df[df['label'].notnull()]
八、进阶学习方向
无监督学习新范式
- 对比学习(Contrastive Learning)
- 自编码器(AutoEncoder)
- 深度聚类(DeepCluster)
与有监督的融合前沿
- 半监督学习:标签传播算法
- 自监督学习:SimCLR、BYOL
- 迁移学习:预训练+微调范式
附录:高频面试题
- K-means能否用于分类任务?为什么?
- 当数据有部分标签时,如何改进K-means?
- 证明K-means每次迭代必然降低目标函数值
- 有监督和无监督学习的评估指标有何本质区别?
新增图表:
- 有监督/无监督/半监督学习对比矩阵
- K-means与SVM的目标函数对比图
- 聚类特征增强有监督模型的流程图
- 工业级半监督学习架构图
通过这样的结构调整,全文在保持K-means技术深度的同时,系统性地对比了有监督和无监督学习的差异,并展示了二者在实际应用中的协同价值,更加符合工业实践需求。