ICCV-2025 | 同济上海AILab跨越虚拟与现实的具身导航!VLN-PE:重审视觉语言导航中的具身差距

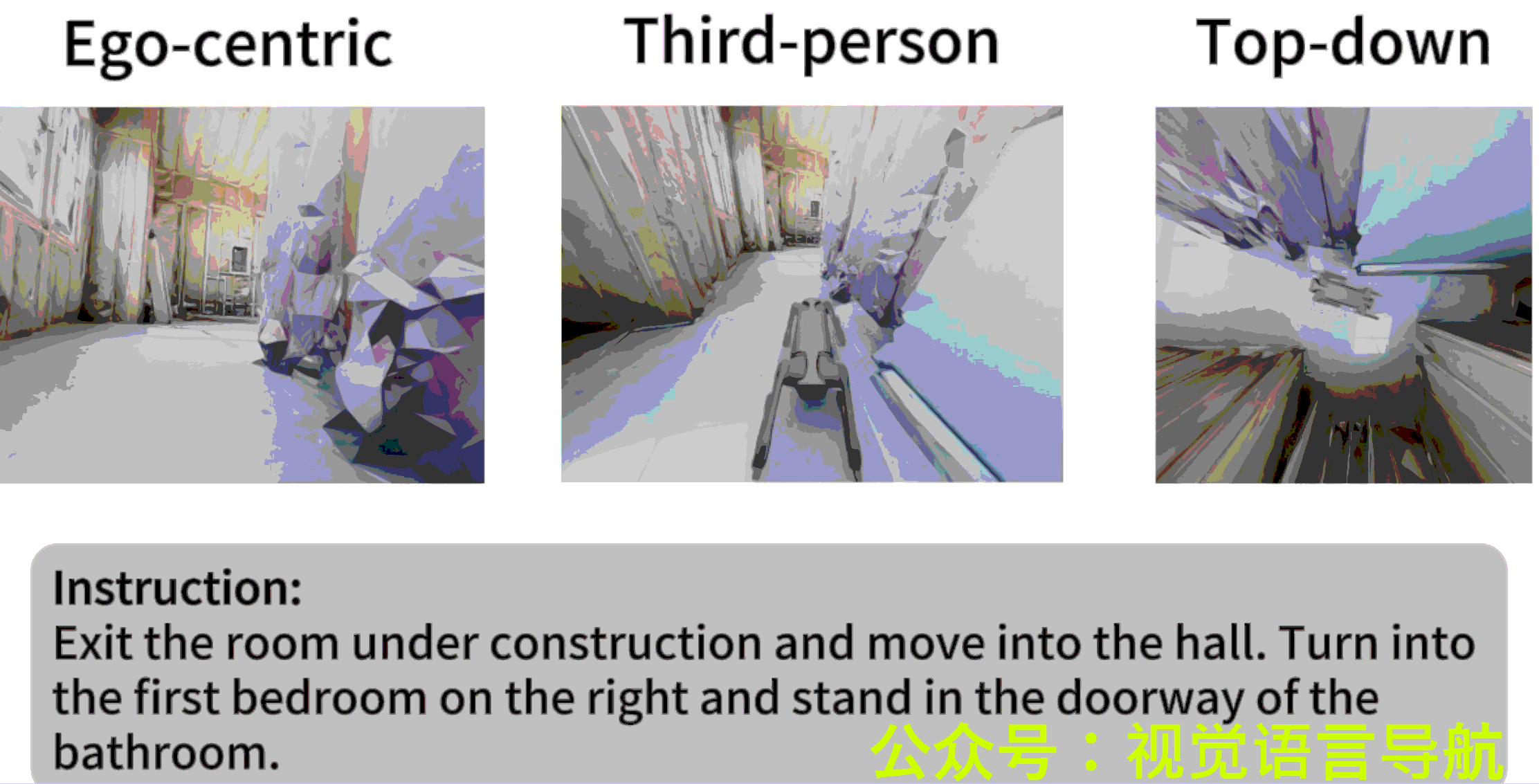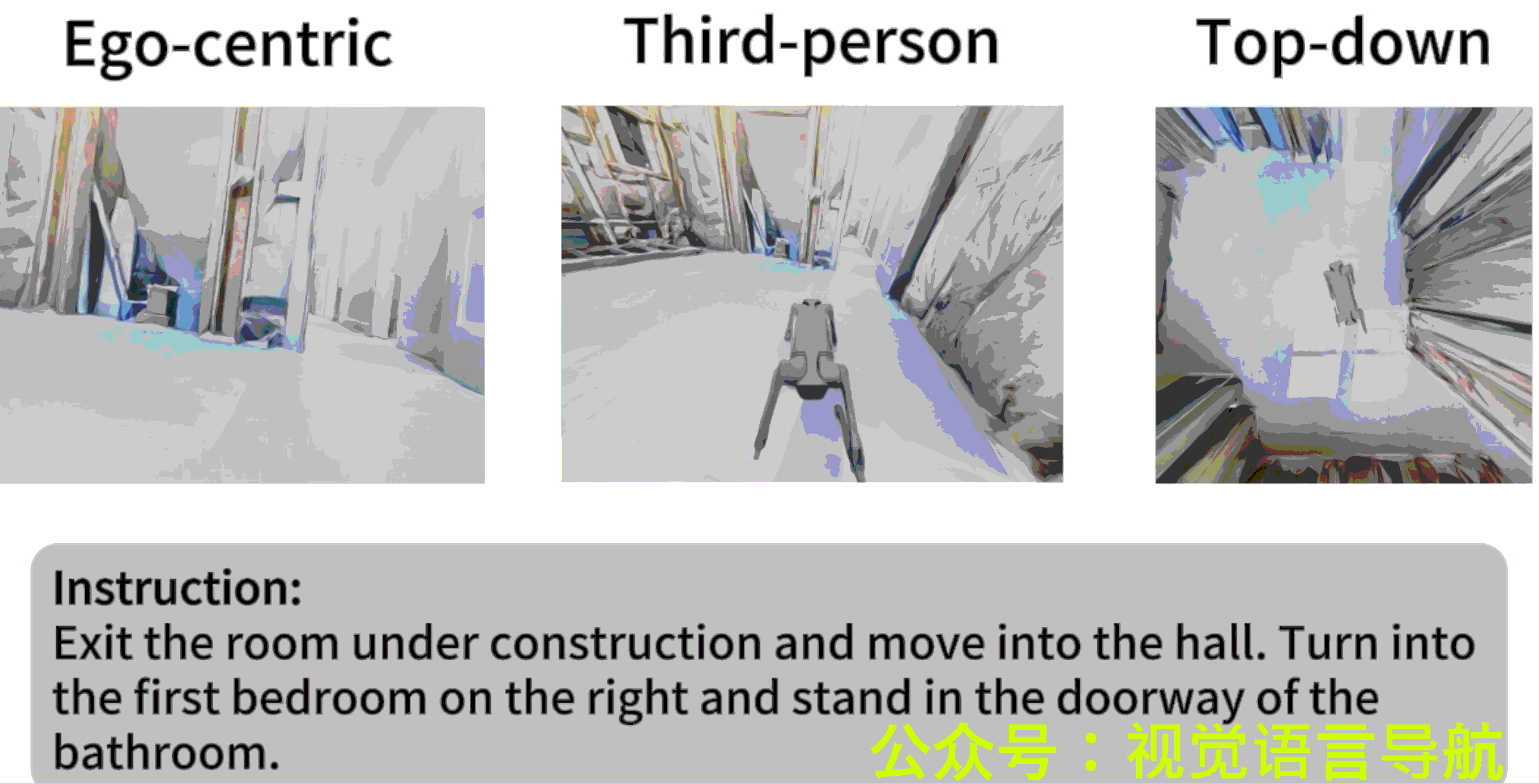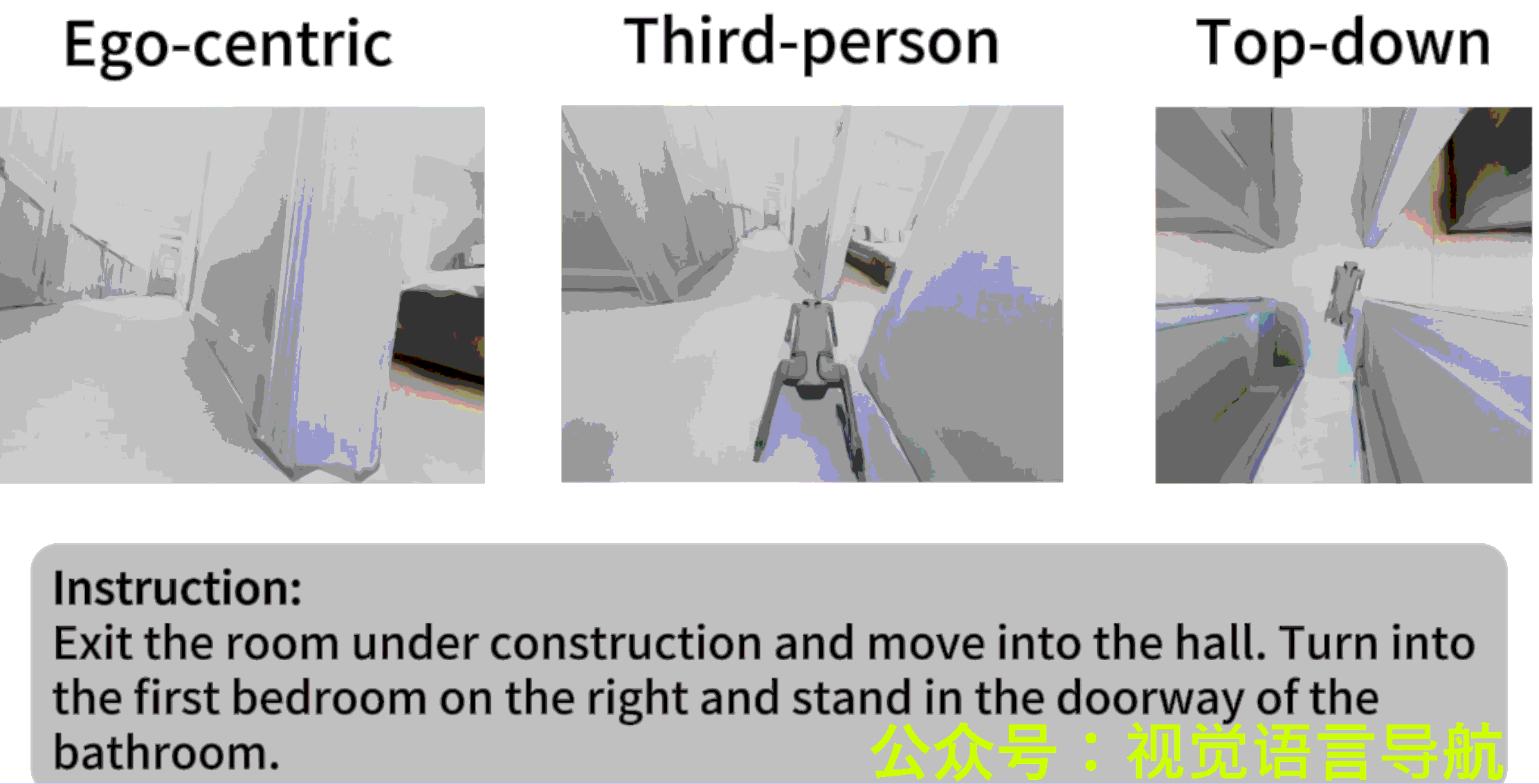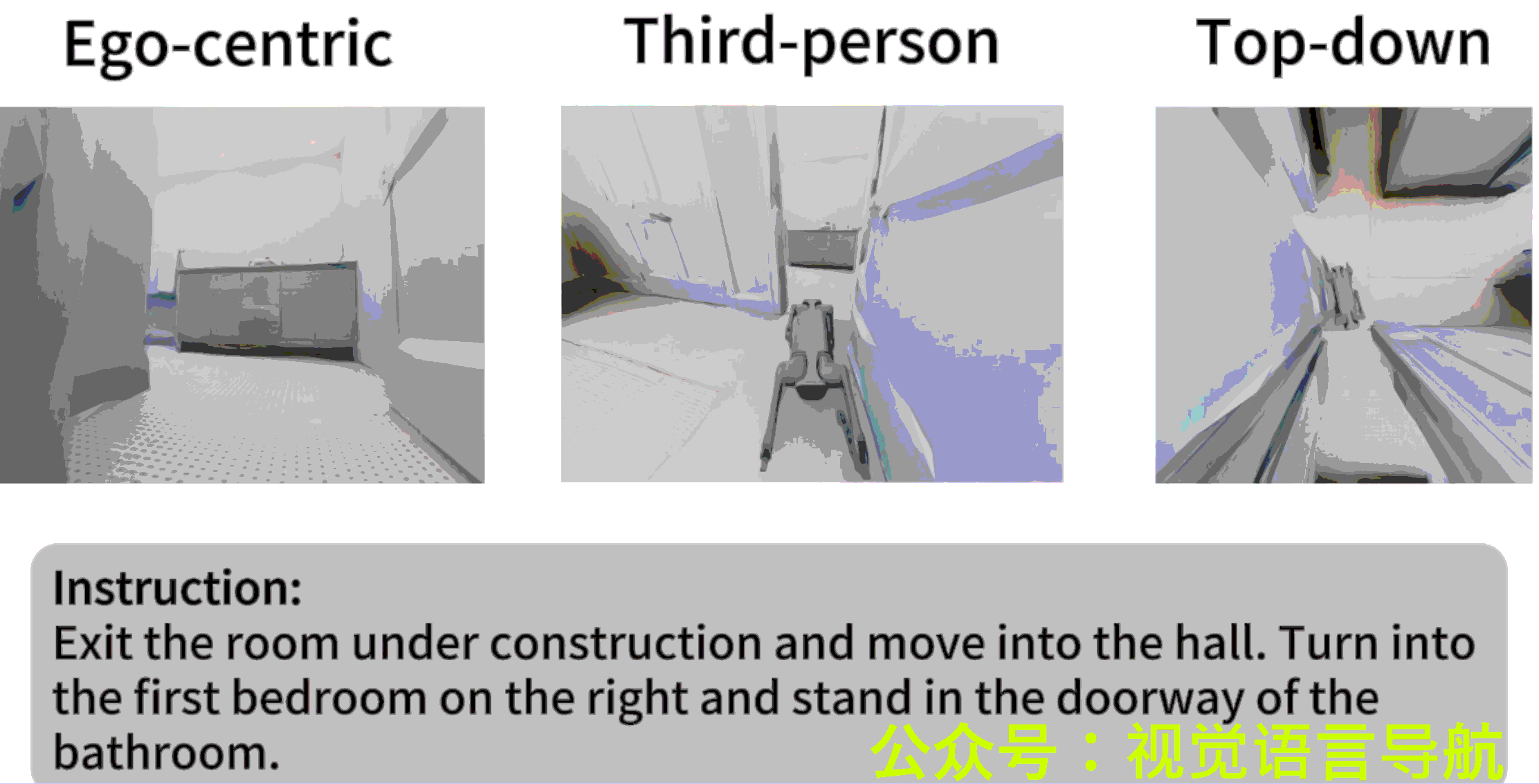
- 作者: Liuyi Wang1,2^{1,2}1,2, Xinyuan Xia2,3^{2,3}2,3, Hui Zhao2^{2}2, Hanqing Wang2^{2}2, Tai Wang2^{2}2, Yilun Chen2^{2}2, Chengju Liu1,4^{1,4}1,4, Qijun Chen1,4^{1,4}1,4, Jiangmiao Pang2^{2}2,
- 单位:1^{1}1同济大学,2^{2}2上海人工智能实验室,3^{3}3上海交通大学,4^{4}4自主智能无人系统国家重点实验室
- 论文标题:Rethinking the Embodied Gap in Vision-and-Language Navigation: A Holistic Study of Physical and Visual Disparities
- 论文链接:https://arxiv.org/pdf/2507.13019
- 项目主页:https://crystalsixone.github.io/vln_pe.github.io/
- 代码链接:https://github.com/InternRobotics/InternNav
主要贡献
- 提出了VLN-PE,这是一个支持人形、四足和轮式机器人的物理级VLN(视觉语言导航)平台,填补了现有研究中从仿真到物理部署的空白。
- 系统性地评估了几种第一视角的VLN方法在物理机器人环境中的表现,包括单步离散动作预测的分类模型、密集轨迹点预测的扩散模型以及基于地图的无需训练的大语言模型(LLM)与路径规划的结合。
- 揭示了由于机器人观测空间有限、环境光照变化以及碰撞和跌倒等物理挑战导致的性能显著下降问题,同时也暴露了在复杂环境中腿部机器人运动的限制。
- VLN-PE具有高度可扩展性,能够无缝集成新的场景,扩展了VLN研究和评估的范围,为提高跨实体的适应性提供了新途径。
研究背景
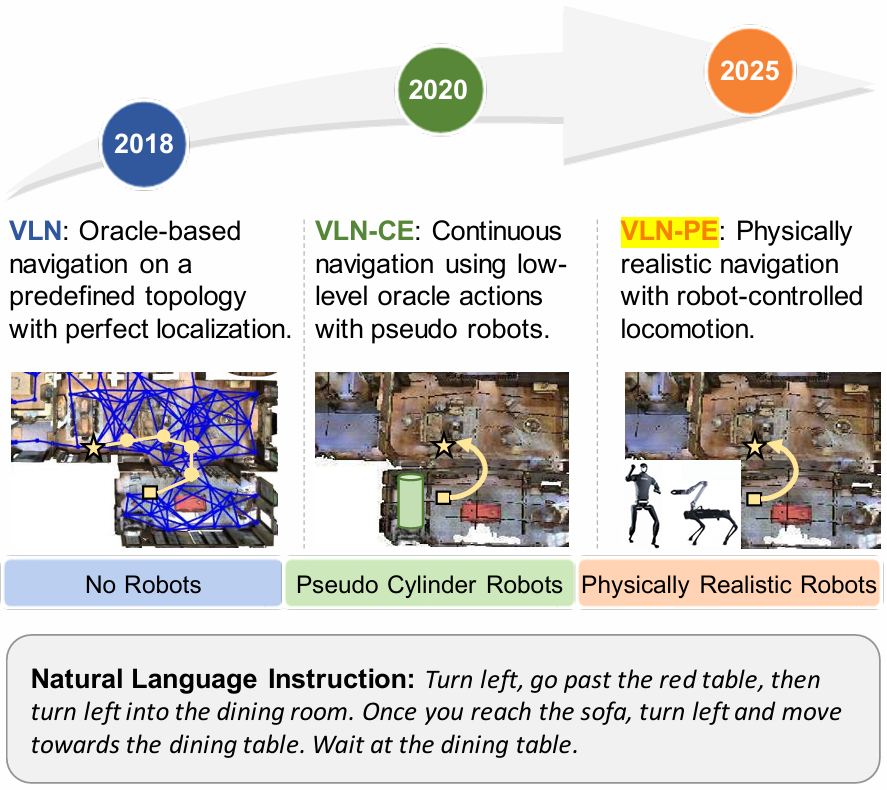
- VLN是具身人工智能中的一个重要任务,要求智能体根据自然语言指令在复杂环境中导航。最初依赖于MP3D模拟器,仅支持基于预定义图节点的导航。
- 后来VLN-CE引入了连续导航,但现有的VLN基准测试大多针对理想的轮式或点基智能体设计,忽略了机器人自身的物理具身性,且测试条件过于理想化,常常忽视了视角变化、跌倒、死锁和运动误差等关键物理问题。
- 随着机器人运动算法的快速发展,尤其是人形和四足机器人的强化学习方法,迫切需要一个集成VLN基准测试平台,支持跨实体数据收集、训练和评估,但现有研究缺乏将真实机器人动力学、精确运动控制和可扩展训练集成在一起的全栈平台。
VLN-PE平台与基准
平台架构
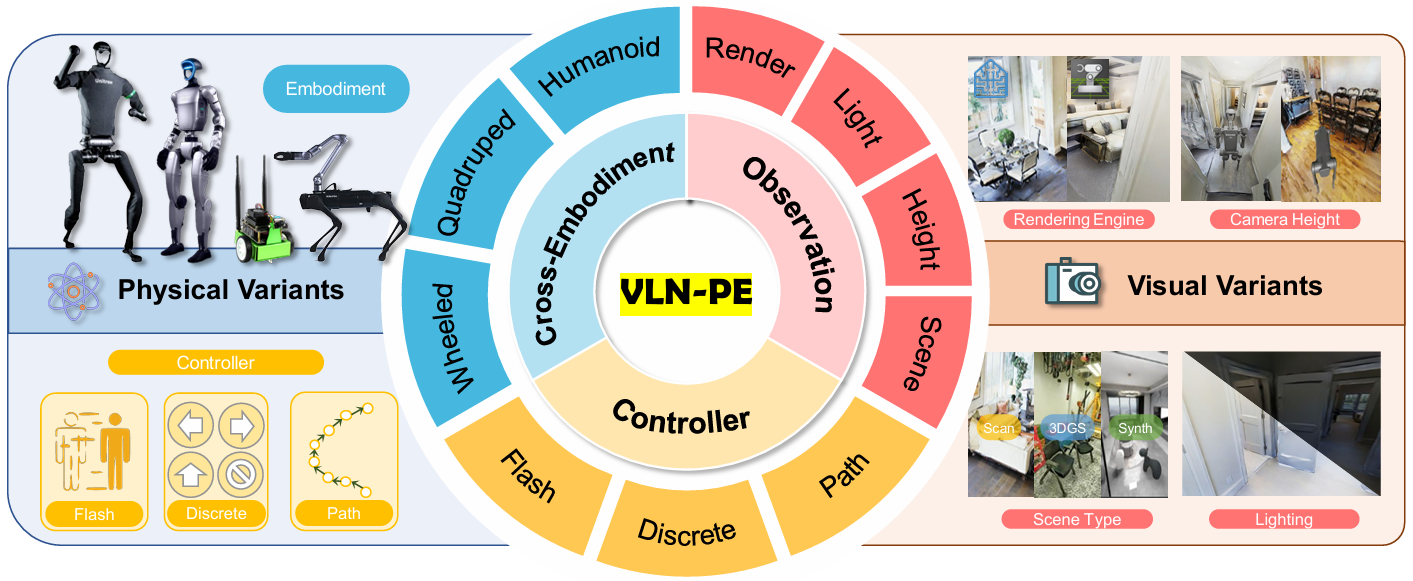
VLN-PE(Vision-and-Language Navigation - Physical Embodiment)是一个物理级的VLN平台,基于GRUTopia构建,支持多种机器人类型(人形、四足和轮式机器人)。该平台的核心特点包括:
- 物理仿真:采用NVIDIA Isaac Sim的强大物理仿真能力,支持多种机器人模型,能够模拟真实的运动和交互。
- 环境扩展性:支持无缝集成多种环境,包括高质量的合成场景和3D高斯绘制(3DGS)场景,扩展了VLN研究的范围。
- 多模态感知:支持RGB和深度传感器,符合真实机器人配置。
场景构建
- MP3D场景:将90个Matterport3D场景转换为USD格式,并修复了由于重建错误导致的地面缺口,以适应腿部机器人的运动。
- 合成场景:引入了10个高质量的合成家庭场景(GRScenes),提供更高的视觉保真度和物理真实性。
- 3DGS场景:使用3D高斯绘制技术重建的实验室环境,提供高度逼真的感知体验。

数据集构建
- R2R数据集:使用R2R数据集进行实验,过滤掉包含楼梯的episode,以适应当前的机器人运动控制器。
- 新数据集:为新引入的场景采样轨迹并生成VLN风格的指令,创建了GRU-VLN10和3DGS-Lab-VLN两个评估数据集。
评估指标
- 标准指标:包括轨迹长度(TL)、导航误差(NE)、成功率(SR)、Oracle成功率(OS)和路径效率加权成功率(SPL)。
- 新增指标:引入摔倒率(FR)和卡住率(StR),以反映物理环境下的性能。
运动控制器
- RL控制器:基于强化学习的运动控制器,支持人形机器人、四足机器人和轮式机器人。这些控制器可以直接应用于真实机器人实验,确保虚拟和物理部署之间的一致性。
基线模型
单步离散动作分类方法
- Seq2Seq:由指令编码器、观察编码器和GRU单元组成,预测下一步动作。
- 指令编码器:使用LSTM对GloVe嵌入的指令进行编码。
- 观察编码器:使用ResNet50对RGB和深度图像进行编码。
- 动作预测:通过GRU单元融合视觉和语言特征,预测下一步动作。
- CMA:在Seq2Seq基础上引入交叉模态注意力机制,通过两个GRU单元分别处理视觉和语言特征,增强模型对指令的理解。
- NaVid:基于视频的多模态大语言模型(MLLM),使用LLaMa-VID架构,能够处理连续的RGB输入并输出导航动作。
多步连续预测方法
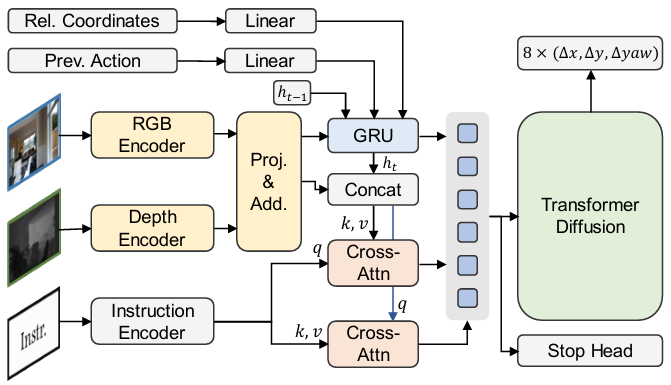
- RDP(Recurrent Diffusion Policy):首次将扩散模型应用于VLN任务,能够生成密集的轨迹点。
- 输入处理:使用LongCLIP对RGB和指令进行编码,使用ResNet50对深度图像进行编码。
- 交叉模态注意力:通过多头注意力机制对视觉和语言特征进行对齐。
- 扩散解码器:基于Transformer结构,预测未来多步的相对位移和偏航角。
- 停止预测:引入额外的MLP预测头,用于预测停止进度,辅助模型做出更精确的停止决策。
基于地图的非训练方法
- VLMaps:利用大语言模型(LLM)解析自然语言指令为子目标,并在语义地图上进行定位和导航。
- 语义地图构建:使用LSeg将3D点云映射到语义嵌入空间。
- 指令解析:LLM将指令解析为可执行的Python代码,定义导航逻辑。
- 探索策略:引入VLFM(Vision-Language Frontier Maps)进行探索,当目标不可见时,机器人会移动到边界并评估下一个地标。
实验
实验设置
- 实验目标:验证现有VLN方法在物理环境中的表现,分析物理控制器对性能的影响,探索跨实体数据对模型适应性的作用,以及研究不同光照条件对模型准确性的影响。
- 实验平台:基于VLN-PE平台,使用人形机器人(Unitree H1)、四足机器人(Unitree Aliengo)和轮式机器人(Jetbot)进行实验。
- 实验数据集:主要使用R2R数据集,并引入了GRU-VLN10和3DGS-Lab-VLN两个新数据集,以评估模型在非MP3D风格环境中的泛化能力。
- 评估指标:采用标准的VLN评估指标(如成功率SR、路径效率SPL等),并新增了摔倒率FR和卡住率StR两个指标,以反映物理环境下的性能。
实验结果与分析
VLN-CE模型在VLN-PE中的表现
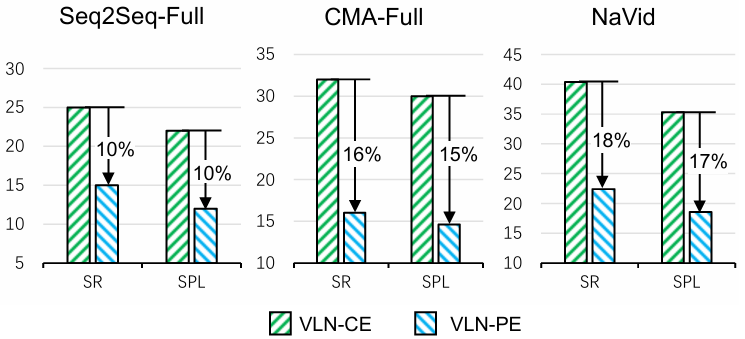
- 零样本迁移性能:直接从VLN-CE迁移到VLN-PE的模型性能显著下降。例如,Seq2Seq-Full、CMA-Full和NaVid的成功率分别下降了10%、16%和18%。这表明现有模型在物理环境中的适应性较差。
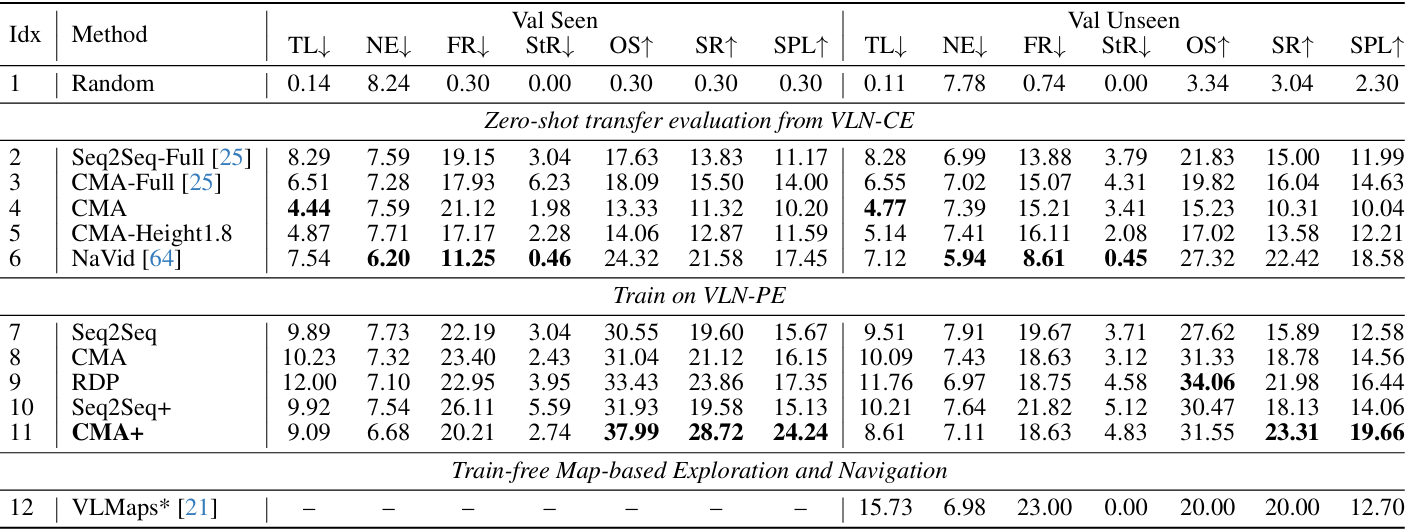
- 领域内训练与微调:使用VLN-PE中的数据进行训练或微调可以显著提升性能。例如,CMA+(微调后的CMA)在验证集上的成功率SR达到了28.72%,超过了NaVid的零样本性能(21.58%)。这表明现有VLN模型倾向于过拟合到特定的仿真平台,而在新环境中需要多样化的数据来提升泛化能力。
物理控制器的影响
- 控制器一致性:当训练和评估时使用的物理控制器保持一致时,模型性能最高。例如,在人形机器人上,使用相同的控制器进行数据收集和评估时,CMA的成功率SR为21.12%,而控制器不一致时,成功率下降到18.54%。
- 控制器数据的重要性:使用带有控制器的数据进行训练可以减少机器人摔倒和卡住的情况,提升整体稳定性。这表明对于腿部机器人,基于控制器的数据收集流程是实现可靠导航的关键。
跨实体数据的影响
- 模型对运动动态和视角高度的敏感性:不同机器人类型的运动动态和视角高度对模型性能有显著影响。例如,人形机器人的“flash”设置(平滑运动)在VLN-PE上表现最好,而四足机器人由于视角高度较低,导致模型几乎失败。
- 跨实体训练的优势:使用多种机器人类型的数据进行训练可以显著提升模型的整体性能,并实现跨实体的泛化。例如,使用人形、四足和轮式机器人数据共同训练的模型在验证集上的成功率SR和路径效率SPL均优于单一机器人类型训练的模型。
光照条件的影响

- 光照变化对模型性能的影响:光照条件的变化对仅依赖RGB输入的模型(如NaVid)影响较大,其成功率在低光照条件下下降了12.47%。而同时使用RGB和深度信息的模型(如CMA和RDP)则表现出更好的稳定性。这表明多模态信息的融合对于提升模型在不同光照条件下的鲁棒性至关重要。
结论与未来工作
- VLN-PE为研究者提供了一个更接近真实世界的VLN研究平台,能够更好地评估和改进现有的VLN方法,推动具身人工智能的发展。
- 未来工作可以包括将VLN-PE扩展到支持全景VLN方法的评估,进一步探索真实世界中的VLN应用,以及研究图像扰动对VLN模型的影响和相关安全问题。
