diffusion原理和代码延伸笔记1——扩散桥,GOUB,UniDB
diffusion原理和代码延伸笔记1——扩散桥,GOUB,UniDB
- 引言
- 扩散桥
- Doob's h-transform
- GOUB
- 前向和反向过程
- 损失函数
- Mean-ODE
- UniDB
- 参考文献
引言
扩散模型包含前向过程和反向过程,前向过程把数据分布映射成高斯分布,反向过程想复原之,不过这种映射是一整个分布和一整个分布之间的,学习的是如何从噪声中创造出新的数据。要是图像修复,去雨,超分,分子设计等需要点对点的任务,不怎么需要“创造”能力的任务,比如在药物设计中,我们可能需要生成一个起始构象和目标构象是固定的分子,在图像修复,去雨等问题上,可以理解为一对一的点任务。这一篇笔记介绍GOUB和更为广泛且纳入GOUB,VE,VP等为特殊情况的UniDB。
扩散桥
扩散桥,Diffusion Bridge,基于SDE,它要连接两个已知的端点,作为一个约束的限制。
与DDPM等基于马尔科夫链(离散化SDE)不同,扩散桥不再是关心p(x0)p(\mathbf{x}_0)p(x0),而是关心在已知 Xs=xs\mathbf{X}_s = \mathbf{x}_sXs=xs 和 XT=xT\mathbf{X}_T = \mathbf{x}_TXT=xT 的情况下,中间状态 Xt,s<t<T\mathbf{X}_t, s<t<TXt,s<t<T 的条件概率分布p(xt∣xs,xT)p(\mathbf{x}_t | \mathbf{x}_s, \mathbf{x}_T)p(xt∣xs,xT)。
从动态视角看,p(xt∣x0,xT)p(\mathbf{x}_t | \mathbf{x}_0, \mathbf{x}_T)p(xt∣x0,xT)其实是一个随机过程,形象点说,描述了一个粒子从t=0t=0t=0的状态开始随机游走,最终被拉到xT\mathbf{x_T}xT这个终点。每一次实验下,路径都是随机的,这个粒子的位置也是不确定的。如果剖析一个时间点的话,就可以发现对于一个固定的xt\mathbf{x_t}xt,其概率分布是完全确定的,后文可以发现确定的是p(xt∣x0,xT)∼N(mean,variance)p(\mathbf{x}_t | \mathbf{x}_0, \mathbf{x}_T) \sim \mathcal{N} (mean, variance)p(xt∣x0,xT)∼N(mean,variance),这里先不给出平均值和方差的具体形式。
好,为了满足这个双端点约束,SDE方程需要做一些修改。
一个标准的SDE如下:
dXt=f(Xt,t)dt+gtdWt,x0∼p(x0)d\mathbf{X}_t = \mathbf{f}(\mathbf{X}_t, t) dt + g_t d\mathbf{W}_t, \quad \mathbf{x_0} \sim p(\mathbf{x_0}) dXt=f(Xt,t)dt+gtdWt,x0∼p(x0)
其中 f(Xt,t)\mathbf{f}(\mathbf{X}_t, t)f(Xt,t) 是漂移项, g(t)dWtg(t) d\mathbf{W}_tg(t)dWt 是扩散项。
接下来记录一种扩散桥的实现方式。
Doob’s h-transform
接下来是Generalized Ornstein-Uhlenbeck,一个基于OU方程扩展的sde,这是一个ttt趋于无穷会保持结果平稳的高斯-马尔可夫过程(线性上有wiener过程,线性组合是高斯分布,马尔可夫性质),任意时刻ttt的边际概率分布随时间ttt的增加会逐渐趋近于一个稳定的均值和方差:
dXt=θt(μ−Xt)dt+gtdWt\begin{equation} d\mathbf{X}_t = \theta_t(\boldsymbol{\mu} - \mathbf{X}_t) dt + g_t d\mathbf{W}_t \end{equation} dXt=θt(μ−Xt)dt+gtdWt
其中μ\boldsymbol{\mu}μ是给定的状态向量,θt\theta_tθt表示标量漂移系数,gtg_tgt表示扩散系数。假定θt\theta_tθt、gtg_tgt满足指定关系 2λ2=gt2/θt2\lambda^2 = g_t^2 / \theta_t2λ2=gt2/θt,其中 λ2\lambda^2λ2是给定的常量标量。因此,其转移概率具有一个封闭形式的解析解:
p(xt∣xs)=N(mˉs:t,σˉs:t2I)=N(μ+(xs−μ)e−θˉs:t,gt22θt(1−e−2θˉs:t)I),θˉs:t=∫stθzdz\begin{align} p (x_t | x_s) &= \mathcal{N}(\bar{m}_{s:t}, \bar{\sigma}^2_{s:t}I) \\ &= \mathcal{N}\left(\mu+ (x_s -\mu) e^{-\bar{\theta}_{s:t}} , \frac{g_t^2}{2\theta_t} \left(1 - e^{-2\bar{\theta}_{s:t}}\right) I \right), \quad \\ \bar{\theta}_{s:t} &= \int_s^t \theta_zdz \end{align} p(xt∣xs)θˉs:t=N(mˉs:t,σˉs:t2I)=N(μ+(xs−μ)e−θˉs:t,2θtgt2(1−e−2θˉs:t)I),=∫stθzdz
随着时间ttt的推移,整个Xt\mathbf{X_t}Xt会收敛于N(μ,λ2)\mathcal{N} (\boldsymbol{\mu}, \lambda^2)N(μ,λ2).
这个是怎么推导的?Yue等人在Appendix C给出了推导,但没有对寻找的辅助函数进行说明。这里给一个证明。
一般地对于随机过程若有:
dXt=(AtXt+Bt)dt+(CtXt+Dt)dWtdX_t = (A_t X_t + B_t)dt + (C_t X_t + D_t) dW_t dXt=(AtXt+Bt)dt+(CtXt+Dt)dWt
有一个本身符合Ito过程的It=μI(t)dt+σI(t)dWtI_t = \mu_I(t) dt + \sigma_I(t) dW_tIt=μI(t)dt+σI(t)dWt,对于dYt=dXtIt=ItdWt+WtdIt+d<I,X>tdY_t = dX_tI_t = I_t dW_t + W_t dI_t + d<I,X>_tdYt=dXtIt=ItdWt+WtdIt+d<I,X>t,d<I,X>td<I,X>_td<I,X>t为一个二次协变差,其为(σI(t)dWt)(CtXtdWt)=σI(t)CtXtdt(\sigma_I(t) dW_t )(C_t X_t dW_t) = \sigma_I(t) C_t X_t dt(σI(t)dWt)(CtXtdWt)=σI(t)CtXtdt,代入到dXtItdX_tI_tdXtIt之中,消除让积分变得困难的随机过程XtX_tXt,则可以获得对应的ItI_tIt。
将我们找到的I(t)I(t)I(t)代回到dYtdY_tdYt的表达式中。这里你甚至可以不用直接赵I(t)I(t)I(t),而是找到一个表达式:(I′(t)−I(t)θt)xt=0(I'(t) - I(t)\theta_t)x_t = 0(I′(t)−I(t)θt)xt=0,可以看到方程大大简化了:
dYt=(I(t)θtμ)dt+I(t)gtdwtdY_t = (I(t)\theta_t\mu) dt + I(t)g_t dw_t dYt=(I(t)θtμ)dt+I(t)gtdwt
现在dYtdY_tdYt的漂移项和扩散项都只依赖于时间ttt,不依赖于随机过程本身。我们可以直接对两边从sss到ttt进行积分:
∫stdYz=∫stI(z)θzμdz+∫stI(z)gzdwz\int_s^t dY_z = \int_s^t I(z)\theta_z\mu dz + \int_s^t I(z)g_z dw_z ∫stdYz=∫stI(z)θzμdz+∫stI(z)gzdwz
左边等于Yt−YsY_t - Y_sYt−Ys。根据YtY_tYt的定义:
Yt=I(t)xt=eθˉtxtY_t = I(t)\mathbf{x}_t = e^{\bar{\theta}_{t}}\mathbf{x}_tYt=I(t)xt=eθˉtxt
Ys=I(s)xs=eθˉsxs=xsY_s = I(s)\mathbf{x}_s = e^{\bar{\theta}_{s}}\mathbf{x}_s = \mathbf{x}_sYs=I(s)xs=eθˉsxs=xs
所以,积分后的方程为:
eθˉtxt−eθˉsxs=μ∫steθˉzθzdz+∫steθˉzgzdwze^{\bar{\theta}_{t}}\mathbf{x}_t - e^{\bar{\theta}_{s}} \mathbf{x}_s = \boldsymbol{\mu} \int_s^t e^{\bar{\theta}_{z}}\theta_z dz + \int_s^t e^{\bar{\theta}_{z}}g_z d\mathbf{w}_zeθˉtxt−eθˉsxs=μ∫steθˉzθzdz+∫steθˉzgzdwz
这两个积分里,前者可以直接积分,后者需要使用Ito Isometry,简单来说就是其方差可以直接放在积分里面,推导需要条件期望公式和全方差公式。别忘记dwzd\mathbf{w}_zdwz本身是一个标准高斯分布,于是:
∫steθˉzgzdwz=N(0,∫ste2θˉzgz2dzI)=N(0,λ2∫ste2θˉz2θzdzI)=N(0,λ2(e2θˉt−e2θˉs)I)\begin{align} \int_s^t e^{\bar{\theta}_{z}}g_z d\mathbf{w}_z &= \mathcal{N}(0, \int_s^t e^{2\bar{\theta}_{z}} g_z^2 dz I) \\ &= \mathcal{N}(0, \lambda^2 \int_s^t e^{2\bar{\theta}_{z}} 2 \theta_z dz I) \\ &= \mathcal{N}(0, \lambda^2 (e^{2\bar{\theta}_{t}} - e^{2\bar{\theta}_{s}})I) \end{align} ∫steθˉzgzdwz=N(0,∫ste2θˉzgz2dzI)=N(0,λ2∫ste2θˉz2θzdzI)=N(0,λ2(e2θˉt−e2θˉs)I)
(5)到(6)是因为用了2λ2=gt2/θt2\lambda^2 = g_t^2 / \theta_t2λ2=gt2/θt,最后放在一起就可以推出(2)-(4)了。
Doob’s h-transform标准形式如下:
dXt=(f(Xt,t)+gt2h(Xt,t,XT,T)dt+gtdWt,x0∼p(x0∣xT)d\mathbf{X}_t = (\mathbf{f}(\mathbf{X}_t, t) + g_t^2 \mathbf{h}(\mathbf{X}_t, t, \mathbf{X}_T, T) dt + g_t d\mathbf{W}_t, \quad \mathbf{x_0} \sim p(\mathbf{x_0}|\mathbf{x_T}) dXt=(f(Xt,t)+gt2h(Xt,t,XT,T)dt+gtdWt,x0∼p(x0∣xT)
Doob变换是一种随机过程里的数学技术。它通过将特定的 h函数纳入随机微分方程(SDE)的漂移项来变换原始过程,使该过程能够通过预定的终点。在漂移项额外加入h(Xt,t,XT,T)=∇xTlogp(xT∣xt)\mathbf{h}(\mathbf{X}_t, t, \mathbf{X}_T, T) = \nabla_{\mathbf{x_T}} \log p(\mathbf{x_T}|\mathbf{x_t})h(Xt,t,XT,T)=∇xTlogp(xT∣xt),当t=Tt=Tt=T时,p(xt∣x0,xT)=1p(\mathbf{x}_t | \mathbf{x}_0, \mathbf{x}_T) = 1p(xt∣x0,xT)=1
GOUB
Yue等人发现,GOU过程(1)具有均值回归特性,即如果我们将初始状态 x0x_0x0视为高质量图像,将对应的低质量图像xT=μx_T = \muxT=μ作为最终条件,那么高质量图像将逐渐收敛于一个以低质量图像为均值、方差稳定为λ2\lambda^2λ2的高斯分布。然而,逆向过程的初始状态需要人为地向低质量图像中添加噪声,这会导致一定的信息损失,从而影响性能。巧合的是,Doob’s h-transform可以修改随机微分方程,使其在终端时间 T时通过指定的 xTx_TxT。因此,需要着重指出的是,将 h -变换应用于GOU过程能有效消除终端噪声的影响,直接在高质量图像和低质量图像之间建立点对点的关系。
前向和反向过程
利用Doob’s h-transform和(2)-(4),基于GOU这个方程,得到前向过程。
前向过程如下:
dxt=(θt+gt2e−2θˉt:Tσˉt:T2)(xT−xt)dt+gtdwt.\begin{equation} d\mathbf{x_t} = \left(\theta_t + g_t^2 \frac{e^{-2\bar{\theta}_{t:T}}}{\bar{\sigma}_{t:T}^2}\right) (\mathbf{x}_T - \mathbf{x}_t)dt + g_td\mathbf{w_t}. \end{equation} dxt=(θt+gt2σˉt:T2e−2θˉt:T)(xT−xt)dt+gtdwt.
其中σˉt:T2=λ2(1−e−2θˉt:T)\bar{\sigma}_{t:T}^2 = \lambda^2 (1 - e^{-2\bar{\theta}_{t:T}})σˉt:T2=λ2(1−e−2θˉt:T)。具体推导比较长,在Yue等人的Appendix A.1里,大概过程是从(2)-(4)写出p(xt∣xs)p(\mathbf{x}_t|\mathbf{x}_s)p(xt∣xs)的具体分布,依据∇xTlogp(xT∣xt)\nabla_{\mathbf{x_T}} \log p(\mathbf{x_T}|\mathbf{x_t})∇xTlogp(xT∣xt)推导hhh,即可推导(8),h(Xt,t,XT,T)=gt2e−2θˉt:Tσˉt:T2(xT−xt)\mathbf{h}(\mathbf{X}_t, t, \mathbf{X}_T, T) = g_t^2 \frac{e^{-2\bar{\theta}_{t:T}}}{\bar{\sigma}_{t:T}^2} (\mathbf{x}_T - \mathbf{x}_t)h(Xt,t,XT,T)=gt2σˉt:T2e−2θˉt:T(xT−xt)
p(xt∣x0,xT)p(\mathbf{x}_t|\mathbf{x}_0, \mathbf{x}_T)p(xt∣x0,xT)的推导可以从贝叶斯公式推导。
p(xt∣x0,xT)=N(mˉt′,σˉt′2I)mˉt′=e−θˉtσˉt:T2σˉT2x0+(1−e−θˉtσˉt:T2σˉT2+e−2θˉt:Tσˉt2σˉT2)xTσˉt′2=σˉt2σˉt:T2σˉ2\begin{align} p(\mathbf{x}_t | \mathbf{x}_0, \mathbf{x}_T) &= \mathcal{N}(\mathbf{\bar{m}}'_t, \bar{\sigma}'^2_t \mathbf{I}) \\ \mathbf{\bar{m}}'_t = e^{-\bar{\theta}_t} \frac{\bar{\sigma}^2_{t:T}}{\bar{\sigma}^2_{T}} \mathbf{x}_0 &+ \left(1 - e^{-\bar{\theta}_t} \frac{\bar{\sigma}^2_{t:T}}{\bar{\sigma}^2_{T}} + e^{-2\bar{\theta}_{t:T}} \frac{\bar{\sigma}^2_{t}}{\bar{\sigma}^2_{T}}\right) \mathbf{x}_T \\ \bar{\sigma}'^2_t &= \frac{\bar{\sigma}^2_{t} \bar{\sigma}^2_{t:T}}{\bar{\sigma}^2} \end{align} p(xt∣x0,xT)mˉt′=e−θˉtσˉT2σˉt:T2x0σˉt′2=N(mˉt′,σˉt′2I)+(1−e−θˉtσˉT2σˉt:T2+e−2θˉt:TσˉT2σˉt2)xT=σˉ2σˉt2σˉt:T2
有了SDE,我们就不用一步一步推导,而是直接一步到位,从x0,xT\mathbf{x}_0, \mathbf{x}_Tx0,xT直接到xt\mathbf{x}_txt,这是训练的第一步。训练的第二步是让模型学习到从xt\mathbf{x}_txt到xt−1\mathbf{x}_{t-1}xt−1的演化。
反向SDE如下,有着p(xt∣xT)p(\mathbf{x_t}|\mathbf{x_T})p(xt∣xT)的边际分布:
dxt=[(θt+gt2e−2θˉt:Tσˉt:T2)(xT−xt)−gt2∇xtlogp(xt∣xT)]dt+gtdwtd\mathbf{x}_t = \left[(\theta_t + g_t^2 \frac{e^{-2\bar{\theta}_{t:T}}}{\bar{\sigma}_{t:T}^2}) (\mathbf{x}_T - \mathbf{x}_t) - g_t^2 \nabla_{\mathbf{x}_t} \log p(\mathbf{x}_t | \mathbf{x}_T) \right] dt + g_t d\mathbf{w}_t dxt=[(θt+gt2σˉt:T2e−2θˉt:T)(xT−xt)−gt2∇xtlogp(xt∣xT)]dt+gtdwt
并且存在一个概率流常微分方程:
dxt=[(θt+gt2e−2θˉt:Tσˉt:T2)(xT−xt)−12gt2∇xtlogp(xt∣xT)]dtd\mathbf{x}_t = \left[(\theta_t + g_t^2 \frac{e^{-2\bar{\theta}_{t:T}}}{\bar{\sigma}_{t:T}^2}) (\mathbf{x}_T - \mathbf{x}_t) - \frac{1}{2} g_t^2 \nabla_{\mathbf{x}_t} \log p(\mathbf{x}_t | \mathbf{x}_T) \right] dt dxt=[(θt+gt2σˉt:T2e−2θˉt:T)(xT−xt)−21gt2∇xtlogp(xt∣xT)]dt
至于为什么这里ODE变成了12\frac 1 221,有一个性质,为保持边际概率密度不变,这一项就得恰好减半。
损失函数
先回顾一下,依照Score based diffusion model,利用conditional score matching,损失函数如下:
L=12∫0TExt[λ(t)∥∇xtlogp(xt)−sθ(xt,t)∥2]dt∝12∫0TEx0,xt[λ(t)∥∇xtlogp(xt∣x0)−sθ(xt,t)∥2]dtL = \frac{1}{2} \int_{0}^{T} \mathbb{E}_{x_t} \left[ \lambda (t) \left\lVert \nabla_{x_t} \log p (x_t) - s_{\theta} (x_t, t) \right\rVert^2 \right] dt \propto \frac{1}{2} \int_{0}^{T} \mathbb{E}_{x_0,x_t} \left[ \lambda (t) \left\lVert \nabla_{x_t} \log p (x_t | x_0) - s_{\theta} (x_t, t) \right\rVert^2 \right] dt L=21∫0TExt[λ(t)∥∇xtlogp(xt)−sθ(xt,t)∥2]dt∝21∫0TEx0,xt[λ(t)∥∇xtlogp(xt∣x0)−sθ(xt,t)∥2]dt
其中λ(t)\lambda(t)λ(t)作为加权函数,若将其选为g2(t)g^2(t)g2(t),则能在负对数似然上得到更优的上界(Song等,2021a)。而正比一行实际上是最常用的,因为条件概率p(xt∣x0)p(x_t | x_0)p(xt∣x0)通常是可获取的。最终,可以从先验分布 p(xT)≈pprior(x)p(x_T) \approx p_{\text{prior}}(x)p(xT)≈pprior(x)中采样得到 xTx_TxT,并通过迭代步骤对公式 (2)进行数值求解来得到 x0x_0x0,从而完成生成过程。
相应地,在GOUB里,得分项∇xtlogp(xt∣xT)\nabla_{x_t} \log p(\mathbf{x}_t | \mathbf{x}_T)∇xtlogp(xt∣xT)可以由神经网络 sθ(xt,xT,t)s_{\theta}(\mathbf{x}_t, \mathbf{x}_T, t)sθ(xt,xT,t)进行参数化,并且可以使用上述score matching的损失函数进行估计。不幸的是,对随机微分方程的得分函数进行训练通常是一项重大挑战。作者没有明说,但我想有一个原因很重要,SDE是连续的,训练神经网络是离散的,为此,Yue等人是通过用反向SDE再用Euler Sampling得到的反向离散化的方程。而先前因为GOUB的解析解是知道的,作者于是推出了一个更为稳定的,使用ELBO的损失函数并推导证明之。
假设xTx_TxT是满足GOU方程的一个有限随机变量,对于固定的 x_T,对数似然函数Ep(x0)[logpθ(x0∣xT)]E_{p(x_0)}[\log p_{\theta}(x_0 | x_T)]Ep(x0)[logpθ(x0∣xT)]具有一个ELBO:
ELBO=Ep(x0){Ep(x1∣x0)[logpθ(x0∣x1,xT)]−∑t=2TEp(xt∣x0)[KL(p(xt−1∣x0,xt,xT)∣∣pθ(xt−1∣xt,xT))]}\text{ELBO} = \mathbb{E}_{p(\mathbf{x}_0)} \left\{ \mathbb{E}_{p(\mathbf{x}_1|\mathbf{x}_0)} [\log p_{\boldsymbol{\theta}} (\mathbf{x}_0 | \mathbf{x}_1, \mathbf{x}_T)] - \sum_{t=2}^{T} \mathbb{E}_{p(\mathbf{x}_t|\mathbf{x}_0)}[\text{KL} (p (\mathbf{x}_{t -1} | \mathbf{x}_0, \mathbf{x}_t, \mathbf{x}_T) || p_{\boldsymbol{\theta}} (\mathbf{x}_{t -1} | \mathbf{x}_t, \mathbf{x}_T))] \right\} ELBO=Ep(x0){Ep(x1∣x0)[logpθ(x0∣x1,xT)]−t=2∑TEp(xt∣x0)[KL(p(xt−1∣x0,xt,xT)∣∣pθ(xt−1∣xt,xT))]}
假设 pθ(xt−1∣xt,xT)p_{\boldsymbol{\theta}}(\mathbf{x}_{t -1} | \mathbf{x}_t, \mathbf{x}_T)pθ(xt−1∣xt,xT) 是一个具有恒定方差的高斯分布 N(μθ,t−1,σθ,t−12I)\mathcal{N}(\boldsymbol{\mu}_{\boldsymbol{\theta},t -1}, \sigma^2_{\boldsymbol{\theta},t -1}\mathbf{I})N(μθ,t−1,σθ,t−12I),最大化ELBO等价于最小化:
L=Et,x0,xt,xT[12σθ,t−12∥μt−1−μθ,t−1∥2]L = \mathbb{E}_{t,\mathbf{x}_0,\mathbf{x}_t,\mathbf{x}_T} \left[ \frac{1}{2\sigma^2_{\boldsymbol{\theta},t -1}} \|\boldsymbol{\mu}_{t -1} - \boldsymbol{\mu}_{\boldsymbol{\theta},t -1}\|^2 \right] L=Et,x0,xt,xT[2σθ,t−121∥μt−1−μθ,t−1∥2]
其中,μt−1\boldsymbol{\mu}_{t -1}μt−1 表示 p(xt−1∣x0,xt,xT)p(\mathbf{x}_{t -1} | \mathbf{x}_0, \mathbf{x}_t, \mathbf{x}_T)p(xt−1∣x0,xt,xT) 的均值:
μt−1=1σˉt′2[σˉt−1′2(xt−bxT)a+(σˉt′2−σˉt−1′2a2)mˉt′]\mu_{t -1} = \frac{1}{\bar{\sigma}'^2_t} \left[ \bar{\sigma}'^2_{t -1}(x_t - bx_T)a + (\bar{\sigma}'^2_t - \bar{\sigma}'^2_{t -1}a^2) \bar{m}'_t \right] μt−1=σˉt′21[σˉt−1′2(xt−bxT)a+(σˉt′2−σˉt−1′2a2)mˉt′]
其中,
a=e−θˉt−1:tσˉt:T2σˉt−1:T2a = e^{-\bar{\theta}_{t -1:t}} \frac{\bar{\sigma}^2_{t:T}}{\bar{\sigma}^2_{t -1:T}}a=e−θˉt−1:tσˉt−1:T2σˉt:T2
b=1σˉT2{(1−e−θˉt)σˉt:T2+e−2θˉt:Tσˉt2−[(1−e−θˉt−1)σˉt−1:T2+e−2θˉt−1:Tσˉt−12]a}b = \frac{1}{\bar{\sigma}^2_T} \left\{ (1 - e^{-\bar{\theta}_t})\bar{\sigma}^2_{t:T} + e^{-2\bar{\theta}_{t:T}} \bar{\sigma}^2_t - \left[ (1 - e^{-\bar{\theta}_{t -1}})\bar{\sigma}^2_{t -1:T} + e^{-2\bar{\theta}_{t -1:T}} \bar{\sigma}^2_{t -1} \right] a \right\}b=σˉT21{(1−e−θˉt)σˉt:T2+e−2θˉt:Tσˉt2−[(1−e−θˉt−1)σˉt−1:T2+e−2θˉt−1:Tσˉt−12]a}
这个证明就比较多,感兴趣的可以参考参考文献第二篇。
根据反向SDE方程,离散化:
xt−1=xt−(θt+gt2e−2θˉt:Tσˉt:T2)(xT−xt)+gt2∇xtlogp(xt∣xT)−gtϵt\mathbf{x}_{t-1} = \mathbf{x}_t - \left( \theta_t + g_t^2 \frac{e^{-2\bar{\theta}_{t:T}}}{\bar{\sigma}_{t:T}^2} \right) (\mathbf{x}_T - \mathbf{x}_t) + g_t^2 \nabla_{\mathbf{x}_t} \log p(\mathbf{x}_t | \mathbf{x}_T) - g_t \boldsymbol{\epsilon}_t xt−1=xt−(θt+gt2σˉt:T2e−2θˉt:T)(xT−xt)+gt2∇xtlogp(xt∣xT)−gtϵt
其中,ϵt∼N(0,dtI)\boldsymbol{\epsilon}_t \sim \mathcal{N}(\mathbf{0}, d_t\mathbf{I})ϵt∼N(0,dtI)。
因此:
μθ,t−1=xt−(θt+gt2e−2θˉt:Tσˉt:T2)(xT−xt)+gt2∇xtlogpθ(xt∣xT)\boldsymbol{\mu}_{\theta,t-1} = \mathbf{x}_t - \left(\theta_t + g_t^2 \frac{e^{-2\bar{\theta}_{t:T}}}{\bar{\sigma}_{t:T}^2}\right) (\mathbf{x}_T - \mathbf{x}_t) + g_t^2 \nabla_{\mathbf{x}_t} \log p_{\theta}(\mathbf{x}_t | \mathbf{x}_T) μθ,t−1=xt−(θt+gt2σˉt:T2e−2θˉt:T)(xT−xt)+gt2∇xtlogpθ(xt∣xT)
标准差就是:σθ,t−1=gt\sigma_{\theta,t-1} = g_tσθ,t−1=gt.
作者发现,L1范数损失在图像重构的结果上效果更好,故而采用L1范数,最后的损失函数结果太长就不写了,代入上面的结果即可。最后,如果我们得到最优的 ϵθ∗(xt,xT,t)\boldsymbol{\epsilon}^*_{\boldsymbol{\theta}}(\mathbf{x}_t, \mathbf{x}_T, t)ϵθ∗(xt,xT,t),就可以计算反向过程的得分 ∇xtlogp(xt∣xT)≈−ϵθ∗(xt,xT,t)σˉt′\nabla_{\mathbf{x}_t} \log p(\mathbf{x}_t | \mathbf{x}_T) \approx \frac {-\boldsymbol{\epsilon}^*_{\boldsymbol{\theta}}(\mathbf{x}_t, \mathbf{x}_T, t)} {\bar{\sigma}'_t}∇xtlogp(xt∣xT)≈σˉt′−ϵθ∗(xt,xT,t),直接代入即可。
Mean-ODE
与普通的扩散模型不同,作者表示,对均值 μθ,t−1\mu_{\theta,t -1}μθ,t−1 的参数化是从随机微分方程的微分推导而来的,这有效地结合了离散扩散模型和基于连续分数的生成模型的特点。在反向过程中,每个采样步骤的值在训练期间会逼近真实均值。因此,作者提出了一个Mean - ODE模型,该模型省略了布朗漂移项,也就是直接在反向SDE上,从经验和实验结果的表现证明上直接删除了dWtd\mathbf{W_t}dWt:
dxt=[θt+gt2e−2θˉt:Tσˉt:T2(xT−xt)−gt2∇xtlogp(xt∣xT)]dt(9)d\mathbf{x}_t = \left[ \theta_t + g_t^2 \frac{e^{-2\bar{\theta}_{t:T}}}{\bar{\sigma}_{t:T}^2} (\mathbf{x}_T - \mathbf{x}_t) - g_t^2 \nabla_{\mathbf{x}_t} \log p(\mathbf{x}_t | \mathbf{x}_T) \,\right] dt \quad (9) dxt=[θt+gt2σˉt:T2e−2θˉt:T(xT−xt)−gt2∇xtlogp(xt∣xT)]dt(9)
作者在实验中也发现,Mean-ODE的表现比Score-ODE好。
UniDB
UniDB仅在GOUB代码的基础上做了极少的修改,而且也利用stochastic optimal control在数学上提供了diffusion bridge via Doob’s h-transform的情况的理解,也证明了这是UniDB的γ→∞\gamma \to \inftyγ→∞的一种特殊情况,在超分辨率(DIV2K)、图像修复(CelebA - HQ)和去雨(Rain100H)上都表现到了SOTA级别。
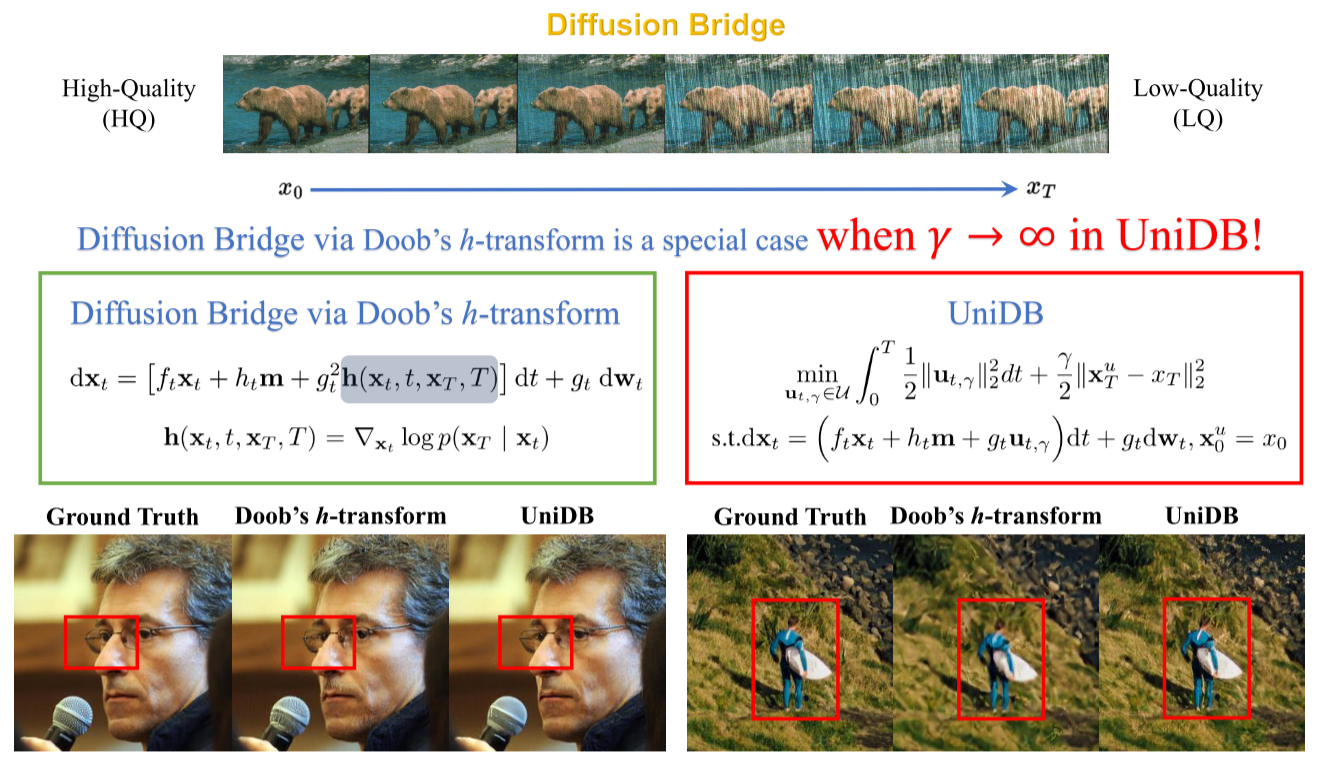
UniDB指出,GOUB其核心技术Doob’s h-transform是一种次优解。而且GOUB虽然性能好,但也有内在的细节模糊或扭曲问题,并通过理论实验帮助阐释了这一点。不过UniDB和GOUB都有着采样慢的通病,但我认为两者的采样速度不会有多少差距,UniDB是可以做到即插即用的,只在GOUB上做了极少量的修改,起到了统一和更深的insight。
注意到图上右边s.t.的部分,ftxtf_t \mathbf{x_t}ftxt是drift项没错,不过多了一个htmh_t \mathbf{m}htm,m\mathbf{m}m是一个given state,一个给定的状态,比如xt−1\mathbf{x_{t-1}}xt−1或者别的。’
把之前GOUB的漂移项展开:
θt(μ−xt)=θtμ−θtxt\theta_t (\boldsymbol{\mu} - x_t) = \theta_t \boldsymbol{\mu} - \theta_t x_t θt(μ−xt)=θtμ−θtxt
然后再看UniDB的通用漂移项:
ftxt+htmf_t x_t + h_t \mathbf{m} ftxt+htm
只要进行如下的参数代换,两者就完全等价了:
- 令 ft=−θtf_t = -\theta_tft=−θt
- 令 ht=θth_t = \theta_tht=θt
- 令 m=μ\mathbf{m} = \boldsymbol{\mu}m=μ
这也是原文中提到的,还有VE,VP等。
UniDB中的一些proposition和GOUB很相似,这里阐述一下不同的部分。
- 依据Theorem 4.1,可以得到一个从x0x_0x0连接到终端xTx_TxT邻域的最优控制正向随机微分方程,这个ut,γ∗\mathbf{u}_{t,\gamma}^*ut,γ∗也是可以计算的,与m,xt,xT\mathbf{m},\mathbf{x_t},\mathbf{x_T}m,xt,xT有关,正向过程中xtx_txt的转移情况也可以推出。
- 对于SOC问题,当γ→∞\gamma \to \inftyγ→∞时,最优控制器变为 ut,∞∗=gt∇xtlogp(xT∣xt)u^*_{t,\infty} = g_t\nabla_{\mathbf{x}_t} \log p(\mathbf{x}_T | \mathbf{x}_t)ut,∞∗=gt∇xtlogp(xT∣xt),并且对应于线性随机微分方程形式的前向和后向随机微分方程与 Doob 的 hhh-变换相同。
- 记J(ut,γ,γ)≜∫0T12∥ut,γ∥22dt+γ2∥xTu−xT∥22\mathcal{J}(\mathbf{u}_{t,\gamma}, \gamma) \triangleq \int_0^T \frac{1}{2} \|\mathbf{u}_{t,\gamma}\|_2^2 \mathrm{d}t + \frac{\gamma}{2} \|\mathbf{x}_T^u - x_T\|_2^2J(ut,γ,γ)≜∫0T21∥ut,γ∥22dt+2γ∥xTu−xT∥22为系统的总成本,ut,γ∗u_{t,\gamma}^*ut,γ∗为最优控制器,则有J(ut,γ∗,γ)≤J(ut,∞∗,∞)\mathcal{J}(\mathbf{u}^*_{t,\gamma}, \gamma) \le \mathcal{J}(\mathbf{u}^*_{t,\infty}, \infty)J(ut,γ∗,γ)≤J(ut,∞∗,∞),这说明γ→∞\gamma \to \inftyγ→∞的情况并非是最优解,后面作者根据实验发现γ\gammaγ的取值是随着不同的具体任务而有变化的。
- 记初始状态分布为 x0x_0x0,由控制器产生的终端分布为 xTu\mathbf{x}_T^uxTu,以及预先定义的终端分布为 xTx_TxT,则
∥xTu−xT∥22=e−2θˉT(1+γλ2(1−e−2θˉT))2∥xT−x0∥22\|\mathbf{x}_T^u - x_T\|_2^2 = \frac{e^{-2\bar{\theta}_T}}{(1 + \gamma\lambda^2(1 - e^{-2\bar{\theta}_T}))^2} \|x_T - x_0\|_2^2 ∥xTu−xT∥22=(1+γλ2(1−e−2θˉT))2e−2θˉT∥xT−x0∥22
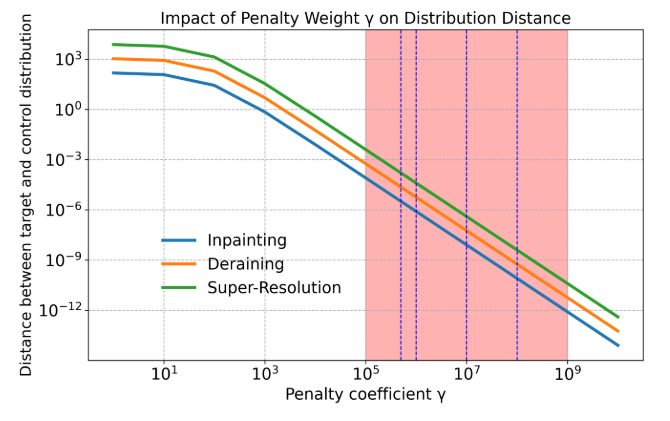
这说明控制的终点和实际的终点是受到γ\gammaγ的调控的,如下图,红色区域是作者推荐的关注区域,蓝色点竖线是作者在后面的消融实验中的选取方式,在四倍超分,图像修复,去雨三个任务上,从PSNR,SSIM,LPIPS,FIDS四个指标看,γ\gammaγ的不同,分数也不同,而且同一个任务里也可能并非一个gamma能得到四个指标都有良好的结果。
与之前GOUB的类似,反向过程SDE和Mean-ODE如下:
dxt=[ftxt+htm+gtut,γ∗−gt2∇xtlogp(xt∣xT)]dt+gtdw~t\mathrm{d}\mathbf{x}_t = [f_t\mathbf{x}_t + h_t\mathbf{m} + g_t\mathbf{u}^*_{t,\gamma} - g_t^2\nabla_{\mathbf{x}_t}\log p(\mathbf{x}_t | x_T)]\mathrm{d}t + g_t\mathrm{d}\tilde{\mathbf{w}}_t dxt=[ftxt+htm+gtut,γ∗−gt2∇xtlogp(xt∣xT)]dt+gtdw~t
dxt=[ftxt+htm+gtut,γ∗−gt2∇xtlogp(xt∣xT)]dt\mathrm{d}\mathbf{x}_t = [f_t\mathbf{x}_t + h_t\mathbf{m} + g_t\mathbf{u}^*_{t,\gamma} - g_t^2\nabla_{\mathbf{x}_t}\log p(\mathbf{x}_t | x_T)]\mathrm{d}t dxt=[ftxt+htm+gtut,γ∗−gt2∇xtlogp(xt∣xT)]dt
整个训练中,以GOU为例子,项的差距与GOUB差距很小,可以看到几乎只是γ−1\gamma^{-1}γ−1的引入:
e−θˉtσˉt:T2σˉT2⇒e−θˉtγ−1+σˉt:T2γ−1+σˉT2e^{-\bar{\theta}_t} \frac{\bar{\sigma}_{t:T}^2}{\bar{\sigma}_T^2} \Rightarrow e^{-\bar{\theta}_t} \frac{\gamma^{-1} + \bar{\sigma}_{t:T}^2}{\gamma^{-1} + \bar{\sigma}_T^2} e−θˉtσˉT2σˉt:T2⇒e−θˉtγ−1+σˉT2γ−1+σˉt:T2
gth=gte−2θˉt:T(xT−xt)σˉt:T2⏟GOUB⇒ut,γ∗=gte−2θˉt:T(xT−xt)γ−1+σˉt:T2⏟UniDB-GOU\underbrace{g_t \mathbf{h} = \frac{g_t e^{-2\bar{\theta}_{t:T}}(x_T - \mathbf{x}_t)}{\bar{\sigma}_{t:T}^2}}_{\text{GOUB}} \Rightarrow \underbrace{\mathbf{u}^*_{t,\gamma} = \frac{g_t e^{-2\bar{\theta}_{t:T}}(x_T - \mathbf{x}_t)}{\gamma^{-1} + \bar{\sigma}_{t:T}^2}}_{\text{UniDB-GOU}} GOUBgth=σˉt:T2gte−2θˉt:T(xT−xt)⇒UniDB-GOUut,γ∗=γ−1+σˉt:T2gte−2θˉt:T(xT−xt)
下面是两个算法。算法一的思路就是,先随机抽取一对图像(x0,xt)(\mathbf{x_0},\mathbf{x_t})(x0,xt),然后在Uniform{1,…,T}Uniform\{1,\dots,T\}Uniform{1,…,T}抽取一个ttt,计算μˉt,γ,γ,σˉt′2\boldsymbol{\bar{\mu}}_{t,\gamma},\gamma,\bar{\sigma}_t'^2μˉt,γ,γ,σˉt′2。为训练稳定,不直接预测分数,而是依据分数匹配理论,分数函数可以被参数化为:
∇xtlogp(xt∣xT)≈−ϵθ(xt,xT,t)σˉt′\nabla_{x_t} \log p(x_t|x_T) \approx -\frac{\epsilon_\theta(x_t, x_T, t)}{\bar{\sigma}'_t} ∇xtlogp(xt∣xT)≈−σˉt′ϵθ(xt,xT,t)
通过计算μˉt−1,θ\boldsymbol{\bar{\mu}}_{t-1,\theta}μˉt−1,θ,再计算μˉt−1,γ\boldsymbol{\bar{\mu}}_{t-1,\gamma}μˉt−1,γ,计算损失函数梯度,让算法收敛。整个算法其实和之前计算GOUB的μθ,t−1\boldsymbol{\mu}_{\theta,t-1}μθ,t−1和μt−1\boldsymbol{\mu}_{t-1}μt−1挺像的。

算法二就是采样啦,解决新问题。

写到这里
参考文献
Zhu K, Pan M, Ma Y, et al. UniDB: A Unified Diffusion Bridge Framework via Stochastic Optimal Control[J]. arXiv preprint arXiv:2502.05749, 2025.
Yue C, Peng Z, Ma J, et al. Image restoration through generalized ornstein-uhlenbeck bridge[J]. arXiv preprint arXiv:2312.10299, 2023.