模拟实现python的sklearn库中的Bunch类以及 load_iris 功能
本文将模拟实现模拟实现python的sklearn库中的Bunch类以及load功能,用来帮助大家更好的学习理解有关于机器学习和sklearn库中函数的使用,对于一些基础不太好的同学建议看一下博主前几期的博客,对照起来更有利于本文的学习。
前置文章链接:python中的容器与自定义容器,python中的容器和对象,python面向对象编程详解,sklearn库中有关于数据集的介绍,这四篇文章中都有涉及博主在学习过程中遇到的一些问题,希望可以帮助到大家。
本文所演示的范例将以鸢尾花数据集的加载作为范例。
一.sklearn库中原始的 load_iris 功能演示
from sklearn.datasets import load_iris
# 加载鸢尾花数据集
iris=load_iris()# 打印数据集对象信息
print(iris)iris = load_iris() 中,load_iris() 是函数调用操作,调用 load_iris 函数并把返回的 Bunch 对象赋值给变量 iris,后文会对此段内容做进一步解释。
运行结果: 中间的大规模数据部分省略
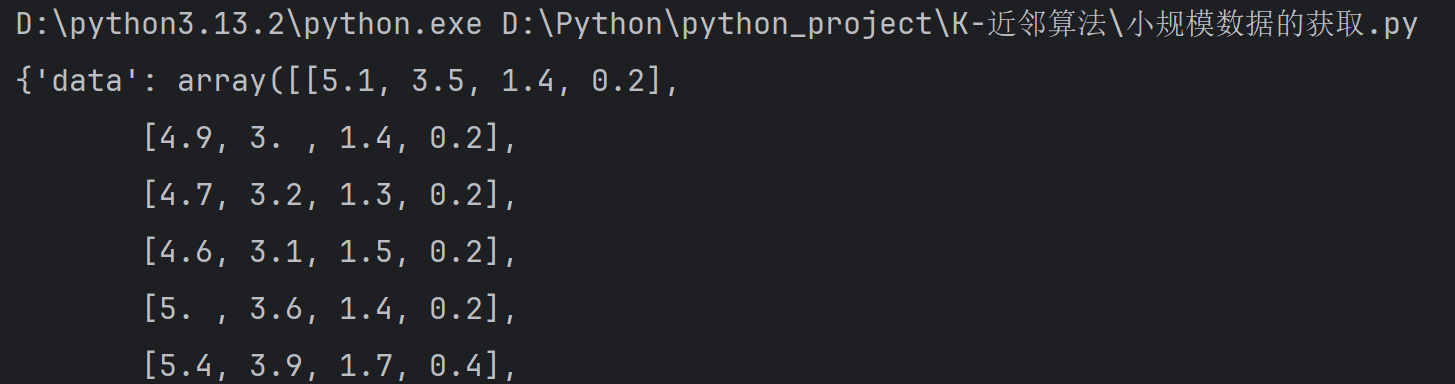
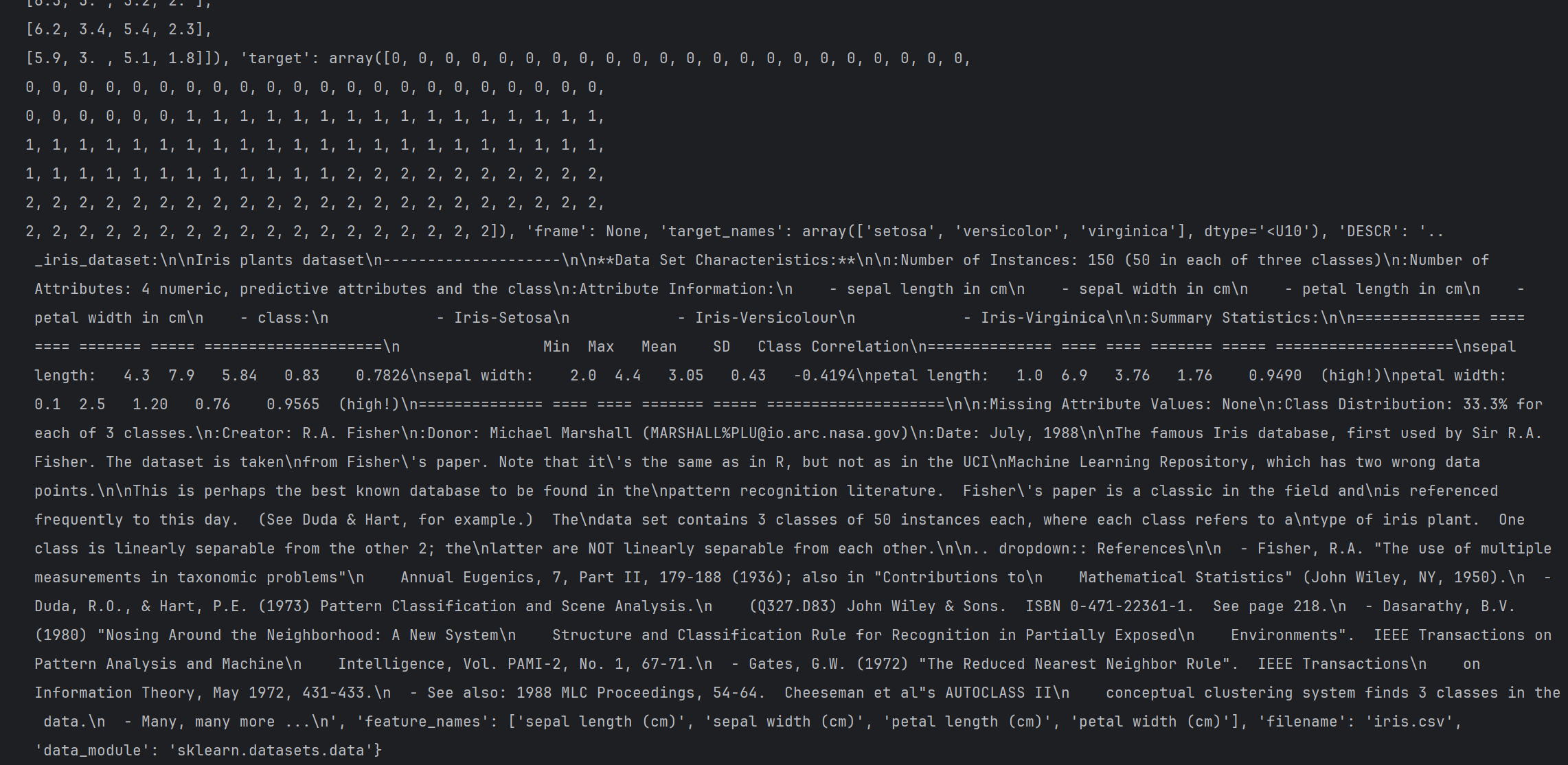
其他代码展示:
# 打印数据集对象的类型
print(type(iris)) # <class 'sklearn.utils._bunch.Bunch'># 打印数据集的特征数据(样本数据)
print(iris.data)# 打印数据集的目标数据(标签数据)
print(iris.target)# 打印数据集的特征名称
print(iris.feature_names)
# ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']二.Bunch 类(数据集容器)
它是 scikit-learn 中用于存储数据集的类似字典的对象,常见于 sklearn.datasets 模块。用于封装数据集,支持通过属性(如.data、.target)访问数据。
示例用法
from sklearn.datasets import load_iris# 加载鸢尾花数据集(返回 Bunch 对象)
iris = load_iris()# 访问数据
print(iris.data.shape) # 特征矩阵 (150, 4)
print(iris.target.shape) # 标签向量 (150,)
print(iris.feature_names) # 特征名称 ['sepal length (cm)', ...]
print(iris.target_names) # 标签名称 ['setosa', 'versicolor', 'virginica']Bunch 的关键属性
data:特征数据数组(numpy.ndarray)
target:标签数组
feature_names:特征名称列表
target_names:标签名称列表 DESCR:数据集的描述文本
三.Bunch 类和 load_iris 的关系
load_iris 是 sklearn.datasets 模块里的一个函数,并非用于创建类。此函数的作用是加载鸢尾花数据集,返回一个 Bunch 类的对象。Bunch 类本质上是字典的子类,能让你通过属性名来访问数据,用起来更便捷。
# 验证load_iris是一个函数
from sklearn.datasets import load_irisprint(callable(load_iris)) # 输出: True四.Bunch 类的模拟实现
Bunch 类的模拟实现代码
class Bunch(dict):"""容器对象,继承自dict,可以像访问字典一样访问数据,也可以通过属性访问"""def __init__(self, **kwargs):super().__init__(kwargs)self.__dict__ = selfdef __repr__(self):keys = list(self.keys())keys.remove('data') if 'data' in keys else Nonekeys.remove('target') if 'target' in keys else Noneinfo = f"数据集对象,包含以下属性: data, target"if keys:info += f", {', '.join(keys)}"return info代码解释
super().__init__(kwargs):调用父类的初始化方法,具体的可以去看python中的容器与自定义容器 中的第三部分。
__dict__解释:在 Python 里,__dict__ 是大部分对象都有的一个特殊属性,它是一个字典,用来存储对象的实例属性。每个键代表属性名,对应的值就是属性的值。
作用1:当你给对象添加实例属性时,这些属性会被存储在对象的 __dict__ 字典里。示例如下:
class ExampleClass:def __init__(self):self.attribute1 = 10self.attribute2 = "hello"obj = ExampleClass()
print(obj.__dict__) # 输出: {'attribute1': 10, 'attribute2': 'hello'}作用2:借助直接操作 __dict__ 字典,你能动态添加或修改对象的属性。示例如下:
class ExampleClass:passobj = ExampleClass()
obj.__dict__['new_attribute'] = 20
print(obj.new_attribute) # 输出: 20理解当前代码: 在你选中的代码 self.__dict__ = self 里,Bunch 类继承自 dict,此代码尝试把 Bunch 对象自身赋值给对象的 __dict__ 属性。这会让对象可以像访问属性一样访问字典里的键值对。示例如下:
import numpy as npclass Bunch(dict):"""容器对象,继承自dict,可以像访问字典一样访问数据,也可以通过属性访问"""def __init__(self, **kwargs):super().__init__(kwargs)self.__dict__ = self # 让对象可以通过属性访问字典键值对# 使用示例
bunch = Bunch(name="example", value=10)
print(bunch['name']) # 像字典一样访问
print(bunch.name) # 像属性一样访问
- 并非所有对象都有
__dict__属性,像一些内置类型(如int、list)和使用__slots__的类就没有。- 直接操作
__dict__可能会破坏类的封装性,所以要谨慎使用。
五. load_iris 函数模拟实现
class DatasetLoader:"""数据集加载器类"""@staticmethoddef load_custom_iris():"""加载自定义鸢尾花数据集"""# 鸢尾花数据集的前几个样本data = np.array([[5.1, 3.5, 1.4, 0.2],[4.9, 3.0, 1.4, 0.2],[4.7, 3.2, 1.3, 0.2],[4.6, 3.1, 1.5, 0.2],[5.0, 3.6, 1.4, 0.2],[7.0, 3.2, 4.7, 1.4],[6.4, 3.2, 4.5, 1.5],[6.9, 3.1, 4.9, 1.5],[5.5, 2.3, 4.0, 1.3],[6.5, 2.8, 4.6, 1.5],[6.3, 3.3, 6.0, 2.5],[5.8, 2.7, 5.1, 1.9],[7.1, 3.0, 5.9, 2.1],[6.3, 2.9, 5.6, 1.8],[6.5, 3.0, 5.8, 2.2]])target = np.array([0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2])feature_names = ['sepal length (cm)', 'sepal width (cm)','petal length (cm)', 'petal width (cm)']target_names = ['setosa', 'versicolor', 'virginica']description = """自定义鸢尾花数据集=================:样本数量: 15 (3个类别,每类5个样本):特征数量: 4:特征信息:- sepal length in cm: 花萼长度- sepal width in cm: 花萼宽度 - petal length in cm: 花瓣长度- petal width in cm: 花瓣宽度:类别:- 0: setosa (山鸢尾)- 1: versicolor (变色鸢尾)- 2: virginica (维吉尼亚鸢尾)"""return Bunch(data=data,target=target,feature_names=feature_names,target_names=target_names,DESCR=description.strip(),filename="custom_iris.csv")# 使用示例
def load_custom_iris():"""全局函数,模仿sklearn的load_iris"""return DatasetLoader.load_custom_iris()# 测试使用
if __name__ == "__main__":# 测试自定义鸢尾花数据集iris_data = load_custom_iris()print("=== 自定义鸢尾花数据集 ===")print(iris_data)# print(f"数据形状: {iris_data.data.shape}")# print(f"标签形状: {iris_data.target.shape}")# print(f"特征名称: {iris_data.feature_names}")# print(f"类别名称: {iris_data.target_names}")# print(f"描述信息:\n{iris_data.DESCR}")## print("\n" + "=" * 50 + "\n")
六.完整代码演示
import numpy as npclass Bunch(dict):"""容器对象,继承自dict,可以像访问字典一样访问数据,也可以通过属性访问"""def __init__(self, **kwargs):super().__init__(kwargs)self.__dict__ = selfprint(self.__dict__)def __repr__(self):keys = list(self.keys())keys.remove('data') if 'data' in keys else Nonekeys.remove('target') if 'target' in keys else Noneinfo = f"数据集对象,包含以下属性: data, target"if keys:info += f", {', '.join(keys)}"return infoclass DatasetLoader:"""数据集加载器类"""@staticmethoddef load_custom_iris():"""加载自定义鸢尾花数据集"""# 鸢尾花数据集的前几个样本data = np.array([[5.1, 3.5, 1.4, 0.2],[4.9, 3.0, 1.4, 0.2],[4.7, 3.2, 1.3, 0.2],[4.6, 3.1, 1.5, 0.2],[5.0, 3.6, 1.4, 0.2],[7.0, 3.2, 4.7, 1.4],[6.4, 3.2, 4.5, 1.5],[6.9, 3.1, 4.9, 1.5],[5.5, 2.3, 4.0, 1.3],[6.5, 2.8, 4.6, 1.5],[6.3, 3.3, 6.0, 2.5],[5.8, 2.7, 5.1, 1.9],[7.1, 3.0, 5.9, 2.1],[6.3, 2.9, 5.6, 1.8],[6.5, 3.0, 5.8, 2.2]])target = np.array([0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2])feature_names = ['sepal length (cm)', 'sepal width (cm)','petal length (cm)', 'petal width (cm)']target_names = ['setosa', 'versicolor', 'virginica']description = """自定义鸢尾花数据集=================:样本数量: 15 (3个类别,每类5个样本):特征数量: 4:特征信息:- sepal length in cm: 花萼长度- sepal width in cm: 花萼宽度 - petal length in cm: 花瓣长度- petal width in cm: 花瓣宽度:类别:- 0: setosa (山鸢尾)- 1: versicolor (变色鸢尾)- 2: virginica (维吉尼亚鸢尾)"""return Bunch(data=data,target=target,feature_names=feature_names,target_names=target_names,DESCR=description.strip(),filename="custom_iris.csv")# 使用示例
def load_custom_iris():"""全局函数,模仿sklearn的load_iris"""return DatasetLoader.load_custom_iris()# 测试使用
if __name__ == "__main__":# 测试自定义鸢尾花数据集iris_data = load_custom_iris()print("=== 自定义鸢尾花数据集 ===")print(iris_data)# print(f"数据形状: {iris_data.data.shape}")# print(f"标签形状: {iris_data.target.shape}")# print(f"特征名称: {iris_data.feature_names}")# print(f"类别名称: {iris_data.target_names}")# print(f"描述信息:\n{iris_data.DESCR}")## print("\n" + "=" * 50 + "\n")