生成式召回-TIGER范式
TIGER(Transformer Index for GEnerative Recommenders)是生成式召回的经典力作,其核心思想就是语义ID+Seq2Seq,这一范式启发了后续大量生成式推荐工作。
📌 背景与痛点
item id是商品在候选库中的独特标识,其具有高度稀疏性,且没有任何物理含义,对于模型训练、新品冷启、可解释性都极不友好。假设一个item的side info足够多,可以完整刻画该item的属性,那么item id完全是可以舍弃的。
TIGER利用多个语义id来表征该item,极大地减少了id embedding词表空间,对工业界生产环境友好;通过模型结构共享相似item的语义信息,提升模型泛化性,利好新品冷启。
✅ TIGER 解决的痛点和优势
| 痛点 | TIGER 的解决方法 | 优势 |
|---|---|---|
| embedding 太大 / 存储高 | Semantic ID token 数量极小,token vocabulary 可控制 | 内存友好、减小表规模 |
| 冷启动 item embedding 缺失 | Semantic ID 来源于 item 内容特征 | 可推广至新 item,无需训练 embedding |
| 类似 item 无共享 | 相似内容生成相近的 Semantic ID | 用户语义共享,加强泛化 |
| 模型检索复杂 | Transformer decoder 直接生成 | 端到端简洁流程 |
🧠 核心创新点
Semantic ID表示
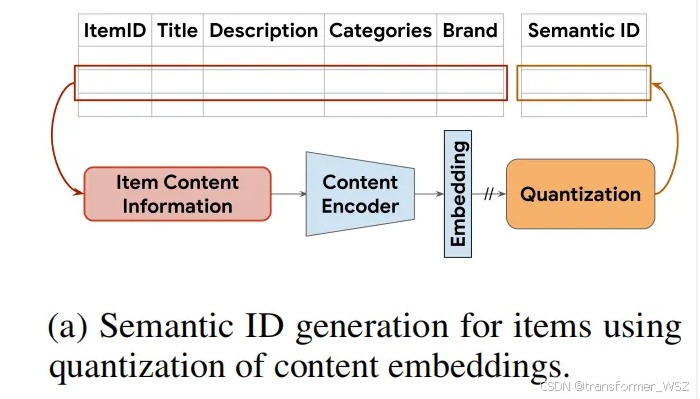
- 使用内容编码(如 SentenceT5)生成 item embedding
- 将embedding经RQ-VAE量化为一系列codeword Tuple,即 Semantic ID
- 各token具有语义信息,编码符号总量远小于item总量
生成式检索(Generative Retrieval)
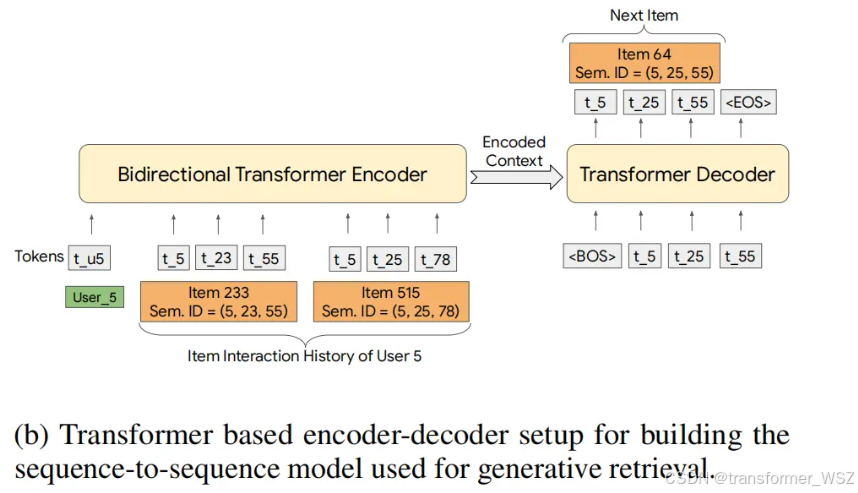
通过自回归解码生成目标item id,而不是传统embedding + ANN。Transformer的decoder直接输出item的Semantic ID作为推荐结果。
实验结果
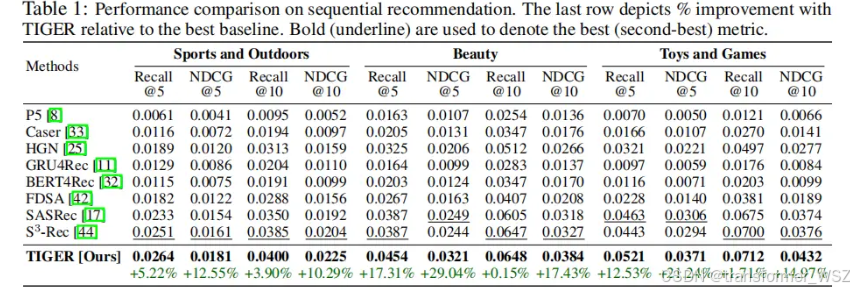
别看实验结果相对值提升很大,很唬人,其实绝对值提升很小。但TIGER范式建模确是一个极大的创新,为生成式推荐打开了思路。
🧾 总结
- TIGER是第一篇将 Generative Retrieval 自回归生成方式 应用于推荐系统的工作;
- 它通过Semantic ID 和 Seq2Seq Transformer,突破embedding + ANN的传统限制;
- 在冷启动、多样性、效率和泛化能力上展现强优势;
- 适用于大规模推荐场景,尤其是content-rich、item海量、频繁上线新品的平台。
参考
- Recommender Systems with Generative Retrieval
- 【谷歌2023】TIGER:基于生成式召回的推荐系统
- NIPS‘23「谷歌」语义ID|TIGER:Recommender Systems with Generative Retrieval