电商项目_核心业务_分布式ID服务
分布式ID有哪些要求
- 全局唯一性:不能出现重复的 ID 号,既然是唯一标识,这是最基本的要求。
- 趋势递增、单调递增:保证下一个 ID 一定大于上一个ID。(索引是基于B+数,非递增的主键在构建索引时容易引起B+数的裂变)
- 信息安全:如果ID的规则非常明显(如果 ID 是连续的),容易被恶意爬取数据。如果是订单号,竞对可以直接知道我们一天的单量。
- 对生成ID的性能要求极高,一个ID 生成系统还需要做到平均延迟和 TP999 延迟都要尽可能低;可用性 5 个9;高 QPS。
分布式ID生成方式
UUID
UUID(Universally Unique Identifier)的标准型式包含 32 个16 进制数字(128位, 16个字节),以连字号分为五段,形式为 8-4-4-4-12 的36 个字符,示例:
550e8400-e29b-41d4-a716-446655440000。
优点:
性能非常高:本地生成,没有网络消耗。
缺点:
- 不易于存储:UUID 太长,16 字节128 位,通常以36 长度的字符串表示,很多场景不适用。
- 信息不安全:基于 MAC 地址生成UUID 的算法可能会造成 MAC 地址泄露,这个漏洞曾被用于寻找梅丽莎病毒的制作者位置。
- 不适合作为DB主键
MySQL 官方有明确的建议主键要尽量越短越好
对MySQL 索引不利:如果作为数据库主键,在 InnoDB 引擎下,UUID 的无序性可能会引起数据位置频繁变动,严重影响性能。
生成UUID方式:
public static void main(String[] args) {String rawUUID = UUID.randomUUID().toString();System.out.println(rawUUID);String uuid = rawUUID.replaceAll("-", "");System.out.println(uuid);}--输出结果
5c15504c-61cd-430d-9308-5838cf8aec98
5c15504c61cd430d93085838cf8aec98雪花算法(Snowflake)
Snowflake 是 Twitter 开源的分布式 ID 生成算法。Snowflake 把64-bit (8个字节)分别划分成多段。
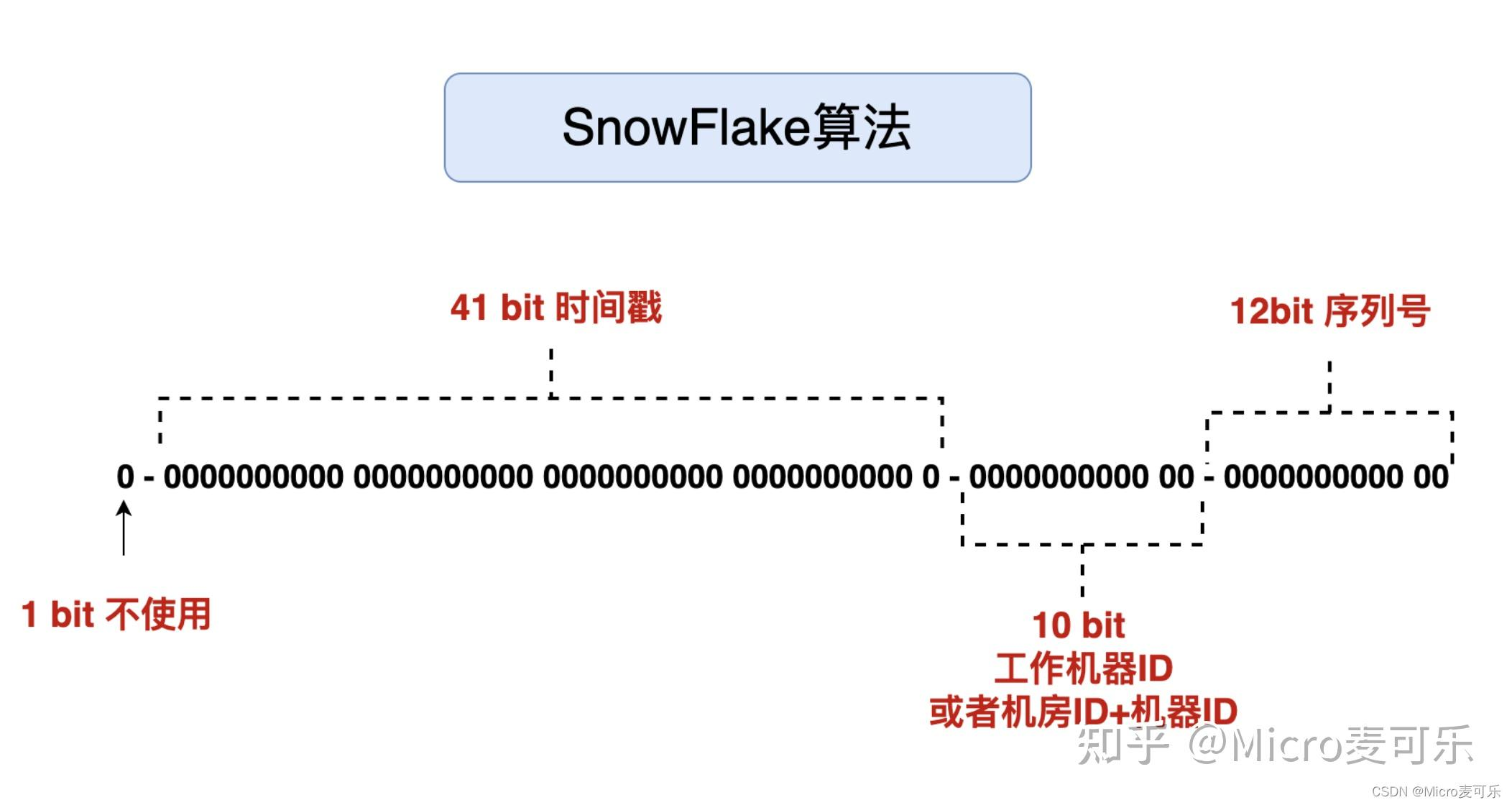
第 0 位: 符号位(标识正负),始终为 0,没有用,不用管。
第 1~41 位 :一共 41 位,用来表示时间戳,单位是毫秒,可以支撑 2 ^41毫秒(约 69 年)
第 42~52 位 :一共 10 位,一般来说,前 5 位表示机房 ID,后 5 位表示机器 ID(实际项目中可以根据实际情况调整),这样就可以区分不同集群/机房的节点,这样就可以表示 32 个 IDC,每个 IDC 下可以有32 台机器。
第 53~64 位 :一共 12 位,用来表示序列号。 序列号为自增值,代表单台机器每毫秒能够产生的最大 ID 数(2^12 = 4096),也就是说单台机器每毫秒最多可以生成 4096 个 唯一 ID。
优点:
- 毫秒数在高位,自增序列在低位,整个 ID 都是趋势递增的。
- 以服务的方式部署(可以不依赖数据库等第三方系统),稳定性更高,生成 ID 的性能也非常高的。
- 可以根据自身业务特性分配 bit 位,非常灵活。
缺点:
- 缺乏协调,还是每个应用自己计算ID。强依赖机器时钟,不同机器间的时钟不一定完全一致;另外,如果机器上时钟回拨(每台机器的时间也不稳定),会导致发号重复 或 服务处于不可用状态。
优化方式:
从一个地方获取id。通过第三方服务生成时间戳。比如Redis incr指令、zookeeper序列化节点, 缺点是获取id的性能开销变大了。
在实际项目中,我们一般也会对 Snowflake 算法进行改造,最常见的就是在算法生成的 ID 中加入业务类型信息。
分布式ID微服务
美团Leaf方案_Leaf-segment

重要字段说明:
- biz_tag 用来区分业务,每个biz-tag 的ID 获取相互隔离
- max_id 表示该biz_tag 目前所被分配的ID 号段的最大值
- step 表示每次分配的号段长度
MySQL 每次获取 ID 是批量获取,每次获取一个 segment(step 决定大小)号段的值。用完之后再去数据库获取新的号段,可以大大的减轻数据库的压力。
优点:
- Leaf 服务可以很方便的线性扩展。
- ID 号码是趋势递增的8byte的64 位数字,满足上述数据库存储的主键要求。
- 容灾性高:Leaf 服务内部有号段缓存,即使 DB 宕机,短时间内 Leaf 仍能正常对外提供服务。
- 可以自定义 max_id 的大小,非常方便业务从原有的 ID 方式上迁移过来。
缺点:
- ID 号码不够随机,能够泄露发号数量的信息,不太安全。 Leaf-segment 方案可以生成趋势递增的 ID,同时ID 号是可计算的。不可用作订单id。
- TP999 数据波动大,当号段使用完之后还是会在获取新号段时在更新数据库的I/O 依然会存在着等待,tg999 数据会出现偶尔的尖刺。
- DB 宕机会造成整个系统不可用。
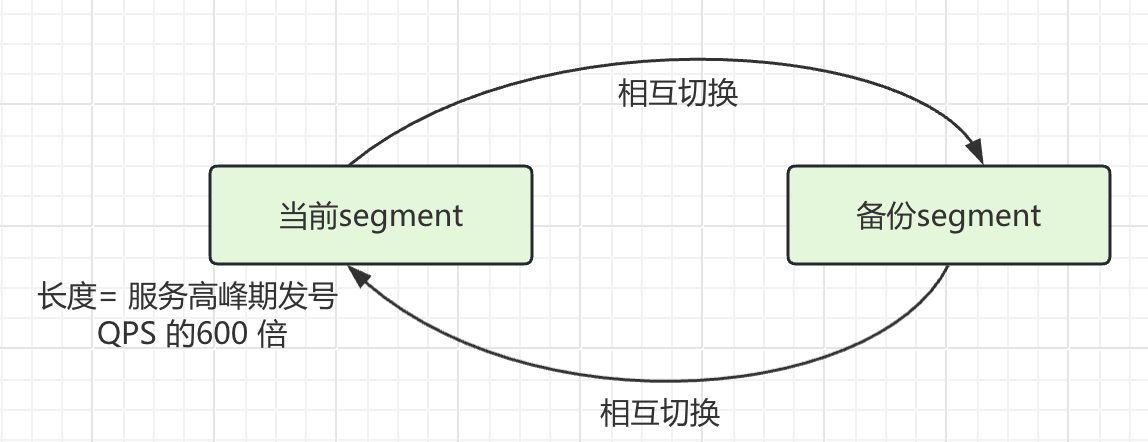
双buffer优化:
针对第二个缺陷,采用双 buffer 的方式,Leaf 服务内部有两个号段缓存区 segment。当前号段已下发10%时,如果下一个号段未更新,则另启一个更新线程去更新下一个号段。
Leaf高可用容灾:
针对第三个缺陷,可以采用一主两从的方式,同时分机房部署,Master 和Slave 之间采用半同步方式同步数据。采用一定的算法保证数据一致性。(奇虎360 的Atlas 数据库中间件、类 Paxos算法)
美团Leaf方案_Leaf-snowflake
针对雪花算法的时间戳字段做优化。Leaf-snowflake 方案完全沿用snowflake 方案的bit 位设计。对于workerId的分配,因为Leaf服务规模较大,所以使用 Zookeeper 持久顺序节点的特性自动对 snowflake 节点配置 wokerID。
弱依赖zookeeper,除了每次会去 ZK 拿数据以外,也会在本机文件系统上缓存一个 workerID 文件。当ZooKeeper 出现问题,恰好机器出现问题需要重启时,能保证服务能够正常启动。