机械学习----knn实战案例----手写数字图像识别
目录
引言
项目介绍
动手思路
一、项目数据
二、关键知识点讲解
三、代码实现
1、加载并预处理训练数据
2、划分训练集和测试集
3、重塑数组形状
4、准备标签
5、使用 sklearn 的 KNN 模型
6、评估模型表现
7、定义单个数字预测函数
8、测试单张图片
引言
经过前两期的学习,相信大家对knn算法已经有了一个较为完整的认知了,本期的博客,我将手把手带大家做一个knn算法的实战案例----手写数字识别
项目介绍
本项目基于 KNN(K 近邻)算法,构建手写数字识别系统。
利用包含 0 - 9 手写数字的训练数据集,通过预处理图像、划分数据集、训练 KNN 模型,实现对手写数字的精准识别,支持批量测试集评估与单张图片预测
动手思路
- 数据加载与预处理:读取训练图像,转为灰度图后按固定规则切割为单个数字图像,将图像数组重塑为二维特征向量(样本数 × 像素特征数),统一数据格式为 float32 以适配模型输入。
- 数据集划分:将预处理后的数字图像按比例划分为训练集和测试集,分别用于模型训练与性能评估。
- 标签制备:针对 0-9 每个数字,生成对应数量的标签,确保训练集和测试集中每个数字的样本与标签一一对应。
- 模型训练:使用 sklearn 库中的 KNN 算法,以 3 个近邻数为参数,基于训练集特征和标签进行模型训练,学习数字特征与类别间的关联。
- 模型评估:用训练好的模型对测试集进行预测,通过准确率指标评估模型在未见过的数据上的识别效果。
- 单图预测功能实现:设计预处理函数,将待预测的单张数字图像转换为与训练数据格式一致的特征向量,调用训练好的模型输出预测结果,并处理可能出现的异常。
一、项目数据
我们使用的是一个包含 5000 个手写数字(0-9) 的图像文件(train_number.png),每种数字500个,总共10类。图像被排布成了一个 50 行 × 100 列 的网格,每个小格是一个 20×20 像素的数字图像。

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
二、关键知识点讲解
首先,我们来了解一下如何读取图片
我们日常保存的图片,本质上既是二进制数据,也可看作矩阵,存储时是二进制数据,程序处理时常用矩阵 / 数组表示,二者协同支撑图片在计算机体系里的存储、处理与展示。
每个像素点的数值含义:
对于彩色图(如 RGB 格式),每个像素由三个数值(R、G、B)组成,分别对应红、绿、蓝三种颜色的亮度,组合后呈现出各种颜色。
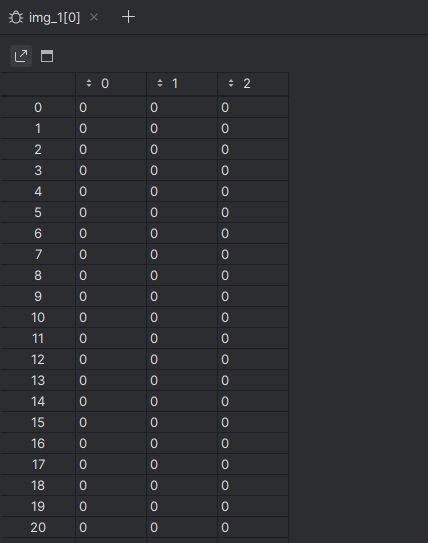
对于灰度图(如代码中的手写数字),每个像素用一个 0-255 的整数表示亮度:0 代表纯黑,255 代表纯白,中间值表示不同深浅的灰色。
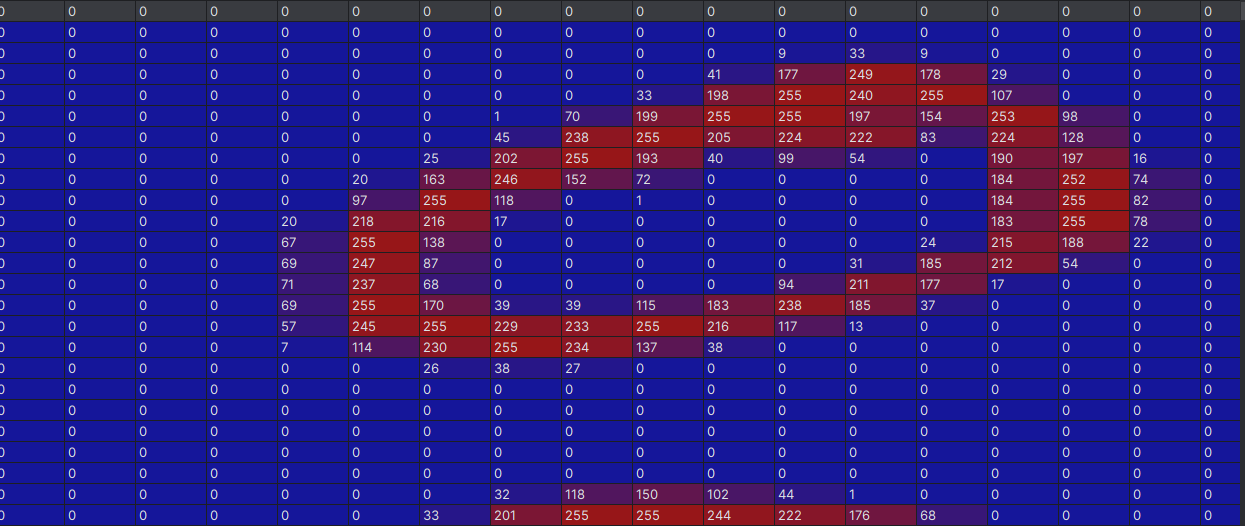
由于rgb图像不方便操作,所以要将图像转化为灰度图像(转化为方便操作的二位数组)
三、代码实现
1、加载并预处理训练数据
img_1 = cv2.imread('train_number.png')
gray = cv2.cvtColor(img_1, cv2.COLOR_BGR2GRAY)
cells = [np.hsplit(row, 100) for row in np.vsplit(gray, 50)]
x = np.array(cells)- 使用 cv2 读取训练图像 "train_number.png"
- 将图像转换为灰度图
- 将灰度图按行分割成 50 份,每份再按列分割成 100 份,得到多个单元格
- 将这些单元格转换为 numpy 数组 x
2、划分训练集和测试集
train = x[:, :50, :, :]
test = x[:, 50:100, :, :]- 从数组 x 中提取前 50 列作为训练集
- 提取后 50 列作为测试集
3、重塑数组形状
train_new = train.reshape(-1, 400).astype(np.float32)
test_new = test.reshape(-1, 400).astype(np.float32)- 将训练集重塑为二维数组(样本数 × 特征数),并转换为 float32 类型
- 对测试集进行同样的处理
4、准备标签
k = np.arange(10)
train_labels = np.repeat(k, 250) # 每个数字有250个训练样本
test_labels = np.repeat(k, 250) # 每个数字有250个测试样本- 创建 0-9 的数字序列
- 为训练集和测试集各生成重复 250 次的标签,每个数字对应 250 个样本
5、使用 sklearn 的 KNN 模型
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(train_new, train_labels)- 初始化近邻数为 3 的 KNN 分类器
- 使用训练集数据和标签训练模型
6、评估模型表现
predictions = knn.predict(test_new)
accuracy = accuracy_score(test_labels, predictions)
print(f"模型准确率: {accuracy * 100:.2f}%")
- 用训练好的模型预测测试集
- 计算并打印模型在测试集上的准确率
7、定义单个数字预测函数
def predict_digit(image_path):# 读取图片并预处理img = cv2.imread(image_path)gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)test_1 = gray_img.reshape(-1,400)prediction = knn.predict(test_1)return prediction- 读取指定路径的图像
- 转换为灰度图并重塑为符合模型输入要求的形状
- 使用训练好的 KNN 模型进行预测并返回结果
8、测试单张图片
result = predict_digit('0.png')
print(f"测试图片'2.png'的预测结果: {int(result)}")
result = predict_digit('1.png')
print(f"测试图片'1.png'的预测结果: {int(result)}")
result = predict_digit('2.png')
print(f"测试图片'2.png'的预测结果: {int(result)}")
result = predict_digit('3.png')
print(f"测试图片'1.png'的预测结果: {int(result)}")
result = predict_digit('4.png')
print(f"测试图片'2.png'的预测结果: {int(result)}")
result = predict_digit('5.png')
print(f"测试图片'1.png'的预测结果: {int(result)}")
result = predict_digit('6.png')
print(f"测试图片'2.png'的预测结果: {int(result)}")
result = predict_digit('7.png')
print(f"测试图片'1.png'的预测结果: {int(result)}")
result = predict_digit('8.png')
print(f"测试图片'2.png'的预测结果: {int(result)}")
result = predict_digit('9.png')
print(f"测试图片'1.png'的预测结果: {int(result)}")
对自己写的数字进行测试,看模型再实际情况下的运行效果
运行结果
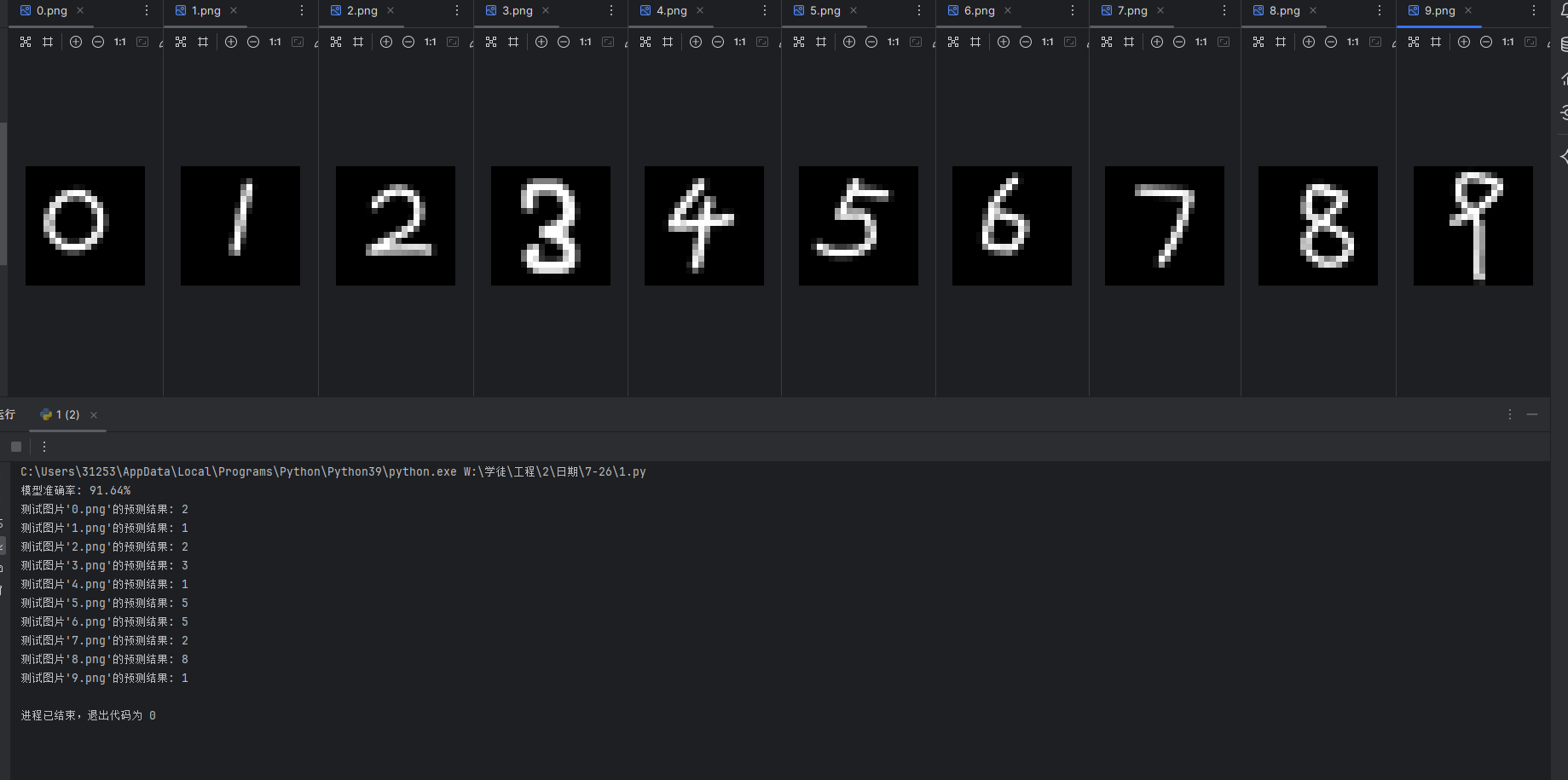
可以看到,虽然模型准确率很高,但实际的运行结果还是不太理想,这是因为每个人对数字的写法不同,笔的粗细,角度,形状甚至是字体格式都不定相同,这些因素我们都没考虑进去。