【算法笔记】树状数组
目录
- 前置知识:lowbit运算
- 模板
- 什么叫二进制的最低一位1?
- 为什么模板这么写
- 树状数组有什么用?
- 为什么要用树状数组
- 模板
- 图示
- 模板解释
- getsum
- update
- 例题1:树状数组求前缀和
- 例题2:树状数组求逆序对
- 例题3:树状数组求逆序对 + 离散化
- 离散化
- 用`unordered_map`
- 用`lower_bound()`
- 例题
- 举一反三1
- 举一反三2
前置知识:lowbit运算
想理解树状数组的原理,首先一定要理解lowbitlowbitlowbit运算。
模板
int lowbit(int x){ // lowbit运算,返回二进制的最低一位1及其后面的0reuturn x & -x;
}
什么叫二进制的最低一位1?
准确的说,lowbitlowbitlowbit返回的其实是一个数的二进制表示的最低一位1,以及它后面所有的0所构成的二进制数。
举一个例子:
比如222222这个数,它的二进制表示是:(10110)2(10110)_2(10110)2,最低一位111也就是从右往左第一位111,所以lowbitlowbitlowbit返回的值是(10)2(10)_2(10)2,转换成十进制也就是222,即lowbit(22)=2lowbit(22) = 2lowbit(22)=2
再比如223222322232这个数,它的二进制表示是(100010111000)2(100010111000)_2(100010111000)2,lowbitlowbitlowbit返回的也就是(1000)2(1000)_2(1000)2,转换成十进制也就是888,即lowbit(2232)=8lowbit(2232) = 8lowbit(2232)=8
为什么模板这么写
首先要知道,计算机存储数据,都是以二进制补码的形式来存的,包含一位符号位和若干数值位,符号位为000表示正数,符号位为111表示负数,对于正数的补码,就是在正数的二进制表示前面加一个000,而对于负数的补码,是将负数的绝对值的二进制表示整体取反再加一后,前面再加一个111
举个例子,x=2232x = 2232x=2232
(x)2=(x)_2 =(x)2= (100010111000)2(100010111000)_2(100010111000)2
(xˉ)2(\bar x)_2(xˉ)2 = (011101000111)2(011101000111)_2(011101000111)2
(xˉ+1)2(\bar x + 1)_2(xˉ+1)2 = (011101001000)2(011101001000)_2(011101001000)2
所以xxx补码等于: 000 100010111000100010111000100010111000
−x-x−x的补码等于: 111 011101001000011101001000011101001000
x&−xx \& -xx&−x,是不是恰好等于100010001000
这也就是lowbitlowbitlowbit的原理。
通过给∣x∣|x|∣x∣的二进制位取反,从而保证最低一位111前面的部分按位与后都为000。
取反后最低一位111的位置变为了000,因为他是最低一位111,他后面几位都是000,取反后都变成111,加一后,恰好把最低一位111变回了111。
xxxxx10000 -取反-> xxxxx01111 -加一-> xxxxx10000 -& xxxxx10000 -> 0000010000 = 10000
树状数组有什么用?
快速(O(logn)O(logn)O(logn))进行单点修改、区间求和的操作。简单来讲,就是快速求前缀和。
为什么要用树状数组
拿一道题举例子:
有n(1≤n≤2×105)n(1 \le n \le 2 \times 10^5)n(1≤n≤2×105)个数,q(1≤q≤2×105)q(1 \le q \le 2 \times 10^5)q(1≤q≤2×105)组查询,每组查询有如下两种:
- 111 xxx yyy : 将数组的第xxx个数的值加上yyy。
- 222 xxx yyy:求数组中第xxx个数到第yyy个数的和。
对于每个操作222,输出一行一个整数。
看到求区间和,第一时间能想到前缀和,但因为有操作1,这题的每个数的值随时都有可能变,也就是每次操作2的时候都要修改一遍前缀和,时间复杂度也就成了O(q×n)O(q \times n)O(q×n),2e52e52e5的数据范围肯定是过不去的。
对这题而言,
如果用普通数组,修改操作是O(1)O(1)O(1)的(a[x] = y),但求和操作是O(n)O(n)O(n)的(for(int i = x; i <= y; i++) sum += a[i])
如果用前缀和数组,求和是O(1)O(1)O(1)的(pre[y] - pre[x - 1]),但修改操作是O(n)O(n)O(n)的(for(int i = x; i <= n; i++) pre[i] += y)
因为一道题分析时间复杂度指的都是最坏情况下的时间复杂度,所以这两种方法的时间复杂度都是O(n)O(n)O(n)
那有没有一种折中的数据结构,能让两种操作的复杂度都不高不低,来提高整体效率呢?
接下来正式来使介绍树状数组:修改和求和复杂度都是O(logn)O(logn)O(logn)的数据结构。
模板
int n;
int tr[N];int lowbit(int x){ // lowbit运算,返回二进制的最低一位1return x & -x;
}void update(int x, int c){ // 相当于a[x] += cfor(int i = x; i <= n; i += lowbit(i)){tr[i] += c;}
}LL getsum(int x){ // 相当于求数组中a[1 ~ x]的前缀和LL res = 0;for(int i = x; i; i -= lowbit(i)){res += tr[i];}return res;
}
图示
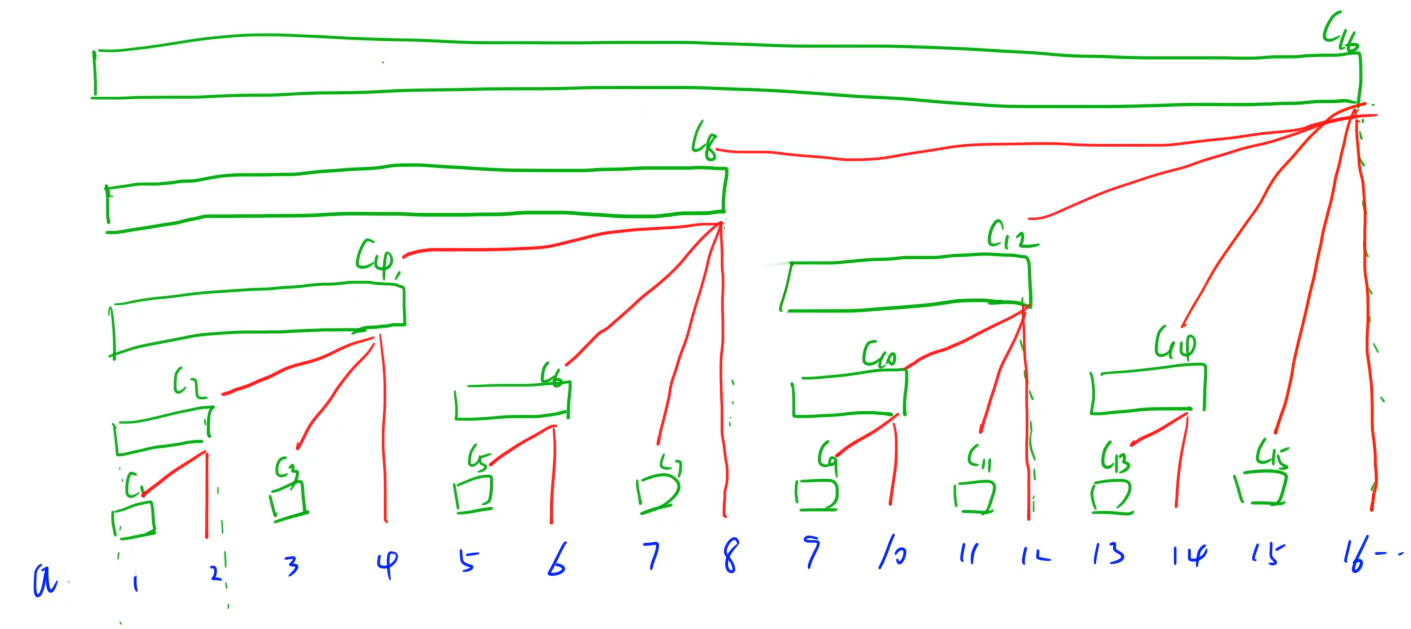
图中:C[i]C[i]C[i]即代码中的tr[i]tr[i]tr[i],表示以iii结尾的lowbit(i)lowbit(i)lowbit(i)个数的和(如图中绿色长条所示)
模板解释
这块看图会好理解一点。
getsum
getsum(x)getsum(x)getsum(x)即求从a[1]a[1]a[1]~a[x]a[x]a[x]的前缀和。
常规的前缀和,是一个数一个数的加,所以效率是O(n)O(n)O(n)的,那能不能将每一个从111~nnn的前缀和,都拆成若干个区间,并且这些区间能不重不漏的以某种特定且唯一的规律表示所有的前缀和呢?
可以基于二进制拆分的思想,每个数的二进制表示都是唯一的,每个数都是由若干222的整数次幂构成的。
比如13=23+22+2013 = 2^3 + 2^2 + 2^013=23+22+20, 23=24+22+21+2023 = 2^4 + 2^2 + 2 ^ 1 + 2 ^ 023=24+22+21+20 ,这些二的次幂,对应着数的二进制表示的每一位111,也就是几个lowbitlowbitlowbit值。
树状数组的getsumgetsumgetsum的过程,便是从xxx开始,每次先查询tr[x]tr[x]tr[x],再查询tr[x−lowbit(x)]tr[x - lowbit(x)]tr[x−lowbit(x)], 再查询…
trtrtr数组便是划分的小区间,每个区间都是tr[x]=sum[x−lowbit(x)+1tr[x] = sum[x - lowbit(x) + 1tr[x]=sum[x−lowbit(x)+1 ~ x]x]x] ,区间长度为lowbit(x)lowbit(x)lowbit(x)。
比如对于getsum(23)getsum(23)getsum(23),
x=23x = 23x=23,lowbit(x)=(1)2=20=1lowbit(x) = (1)_2 = 2^0 = 1lowbit(x)=(1)2=20=1 ,x=x−lowbit(x)=22x = x - lowbit(x) = 22x=x−lowbit(x)=22 ,tr[x]=sum[23,23]tr[x] = sum[23, 23]tr[x]=sum[23,23]
x=22x = 22x=22,lowbit(x)=(10)2=21=2lowbit(x) = (10)_2 = 2^1 = 2lowbit(x)=(10)2=21=2 ,x=x−lowbit(x)=20x = x - lowbit(x) = 20x=x−lowbit(x)=20,tr[x]=sum[21,22]tr[x] = sum[21, 22]tr[x]=sum[21,22]
x=20x = 20x=20,lowbit(x)=(100)2=22=4lowbit(x) = (100)_2 = 2^2 = 4lowbit(x)=(100)2=22=4 ,x=x−lowbit(x)=16x = x - lowbit(x) = 16x=x−lowbit(x)=16,tr[x]=sum[17,20]tr[x] = sum[17, 20]tr[x]=sum[17,20]
x=16x = 16x=16,lowbit(x)=(10000)2=24=16lowbit(x) = (10000)_2 = 2^4 = 16lowbit(x)=(10000)2=24=16 ,x=x−lowbit(x)=0x = x - lowbit(x) = 0x=x−lowbit(x)=0,tr[x]=sum[1,16]tr[x] = sum[1, 16]tr[x]=sum[1,16]
这几个trtrtr加到一起,刚好是sum[1,23]sum[1, 23]sum[1,23]。
因为每个区间长度为lowbit(x)lowbit(x)lowbit(x),这几个lowbitlowbitlowbit加在一起还恰好等于nnn,所以一定刚好不重不漏的包含所有的数的和。
getsum(x)getsum(x)getsum(x)的过程,就是从tr[x]tr[x]tr[x]开始找到所有能拼凑成xxx的前缀和的区间,而每个区间的前一个区间都是tr[x−lowbit(x)]tr[x - lowbit(x)]tr[x−lowbit(x)],所以每次把tr[x]tr[x]tr[x]的值累加到答案,再不断地往下减lowbit(x)lowbit(x)lowbit(x),一直到000,即可。
update
如果要给一个小区间的和加上ccc,对应的包含这个小区间的所有大区间的和,也就是所有它的父节点的和也都要加上ccc。
观察图中的数,
tr[3]tr[3]tr[3]的父节点是tr[4]tr[4]tr[4],4−3=14 - 3 = 14−3=1,lowbit(3)=1lowbit(3) = 1lowbit(3)=1
tr[6]tr[6]tr[6]的父节点是tr[8]tr[8]tr[8],8−6=28 - 6 = 28−6=2,lowbit(6)=2lowbit(6) = 2lowbit(6)=2
tr[12]tr[12]tr[12]的父节点是tr[16]tr[16]tr[16],16−12=416 - 12 = 416−12=4,lowbit(12)=4lowbit(12) = 4lowbit(12)=4
…
update(x)update(x)update(x)的过程,就是从tr[x]tr[x]tr[x]开始不断地向上找父节点,而每个tr[x]tr[x]tr[x]的父节点,都是tr[x+lowbit(x)]tr[x + lowbit(x)]tr[x+lowbit(x)],所以每次给tr[x]+=ctr[x] += ctr[x]+=c,再不断地往上加lowbit(x)lowbit(x)lowbit(x),一直到>n>n>n,即可。
例题1:树状数组求前缀和
P3374 【模板】树状数组 1
const int N = 5e5 + 10;int n, m;
int a[N];
int tr[N];int lowbit(int x){ // lowbit运算,返回二进制的最低一位1return x & -x;
}void update(int x, int c){ // 相当于a[x] += cfor(int i = x; i <= n; i += lowbit(i)){tr[i] += c;}
}LL getsum(int x){ // 相当于求数组中a[1 ~ x]的前缀和LL res = 0;for(int i = x; i; i -= lowbit(i)){res += tr[i];}return res;
}int main(){ios::sync_with_stdio(false); cin.tie(0); cout.tie(0);cin >> n >> m;for(int i = 1; i <= n; i++){cin >> a[i];update(i, a[i]); // 一开始树状数组都为0, 这句话即给i的位置赋值a[i] }while(m--){int op, x, y;cin >> op >> x >> y;if(op == 1){update(x, y);}else cout << getsum(y) - getsum(x - 1) << endl; // 前y个数的和 - 前x-1个数的和 = a[x, y]的和}return 0;
}
例题2:树状数组求逆序对
用树状数组求逆序对是一个非常经典并常用的tricktricktrick,大体原理如下:
- 从a[1]a[1]a[1]到a[n]a[n]a[n]遍历,让a[i]a[i]a[i]作为逆序对中的第二个数
- 对于a[i]a[i]a[i],以a[i]a[i]a[i]作为第二个数的逆序对数即所有满足j<ij < ij<i 且 a[j]>a[i]a[j] > a[i]a[j]>a[i]的a[j]a[j]a[j]的数量
- 简单点说,就是找a[i]a[i]a[i]前面比a[i]a[i]a[i]大的数有几个
- 可以维护一个出现次数的数组(假想是cntcntcnt, cnt[x]cnt[x]cnt[x]就表示数字xxx出现的次数),在遍历的时候,每次给a[i]a[i]a[i]出现次数加一(
cnt[a[i]]++) - 既然是从前往后遍历的,那是不是就能保证遍历到a[i]a[i]a[i]的时候,cnt[x]cnt[x]cnt[x]存的就是在a[i]a[i]a[i]前面xxx出现的次数?
- 这时候算一下cntcntcnt数组的前缀和,pre[a[i]]=cnt[1]+cnt[2]+...+cnt[a[i]]pre[a[i]] = cnt[1] + cnt[2] + ... + cnt[a[i]]pre[a[i]]=cnt[1]+cnt[2]+...+cnt[a[i]],那pre[a[i]]pre[a[i]]pre[a[i]]是不是就是:所有在a[i]a[i]a[i]前面出现的,小于等于a[i]a[i]a[i]的数的个数?pre[N]pre[N]pre[N]是不是就是:所有在a[i]a[i]a[i]前面出现的,小于等于NNN的数的个数?
- 那pre[N]−pre[a[i]]pre[N] - pre[a[i]]pre[N]−pre[a[i]]是不是就是:所有在a[i]a[i]a[i]前面出现的,大于a[i]a[i]a[i]、小于等于NNN的数的个数?如果NNN是题目中的最大值,pre[N]−pre[a[i]]pre[N] - pre[a[i]]pre[N]−pre[a[i]]便是你想要的数,每次累加到答案即可。
- 按上面的思路,把cntcntcnt数组转化成树状数组。
5910. 求逆序对
const int N = 1e5 + 10;int n, m;
int a[N];
int tr[N];int lowbit(int x){ // lowbit运算,返回二进制的最低一位1return x & -x;
}void update(int x, int c){ // 相当于a[x] += c,这里相当于给a[x]出现次数 + cfor(int i = x; i <= 100000; i += lowbit(i)){tr[i] += c;}
}LL getsum(int x){ // 相当于求数组中a[1 ~ x]的前缀和,这里相当于求所有 <= x的数的出现次数LL res = 0;for(int i = x; i; i -= lowbit(i)){res += tr[i];}return res;
}int main(){ios::sync_with_stdio(false); cin.tie(0); cout.tie(0);cin >> n;for(int i = 1; i <= n; i++){cin >> a[i];}LL res = 0;for(int i = 1; i <= n; i++){res += getsum(100000) - getsum(a[i]); // a[i]前面,所有小于等于a[i]的数的出现次数update(a[i], 1); // a[i]又多了一个}cout << res << endl;return 0;
}
例题3:树状数组求逆序对 + 离散化
上面那道题的数据范围比较小,但一般的题都是n≤2×105,a[i]≤109n \le 2 \times 10^5,a[i] \le 10^9n≤2×105,a[i]≤109这样的范围,如果你想像上面那样求逆序对,就要开一个10910^9109的树状数组,肯定是会超内存的,一定要离散化一下,而且不能改变数原本的相对大小(你要求逆序对,你改变他大小了还求什么)
下面讲一下怎么离散化。
离散化
常见的有两种方法,第一步都是先将所有的数都存到一个vectorvectorvector中,然后去重排序。
vector<int> v;
for(int i = 1; i <= n; i++){cin >> a[i];v.push_back(a[i]);
}
sort(v.begin(), v.end());
v.erase(unique(v.begin(), v.end()), v.end());
现在,每个a[i]a[i]a[i]已经从小到大的映射到了v[0]v[0]v[0]~v[v.size()−1]v[v.size() - 1]v[v.size()−1]的位置。
接下来,就是要将v[i]v[i]v[i]映射到i+1i + 1i+1 ,像下面这样:
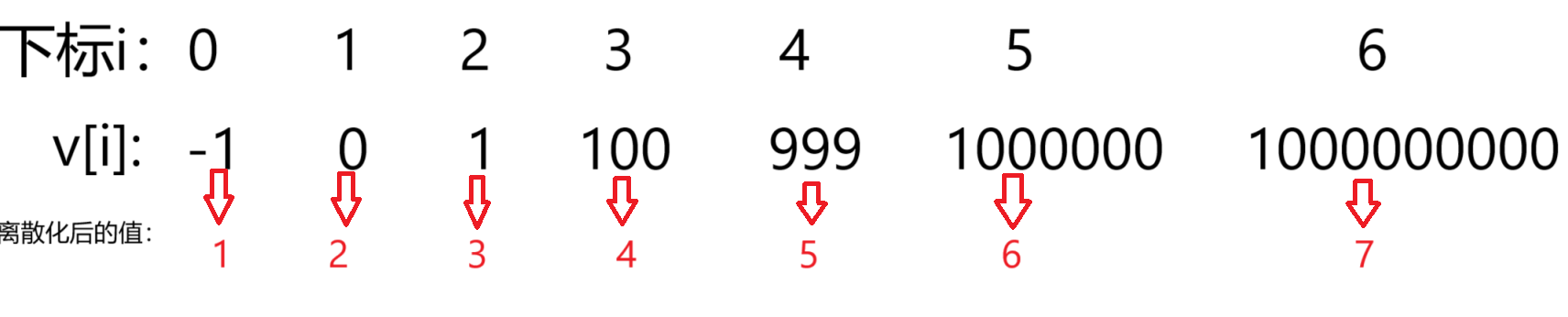
这时候如果原数组是a[]={1000000,1000000000,−1,0,100,1}a[] = \{1000000, 1000000000, -1, 0, 100, 1\}a[]={1000000,1000000000,−1,0,100,1}
离散化后就是:a′[]={5,6,1,2,4,3}a'[] = \{5, 6, 1, 2, 4, 3\}a′[]={5,6,1,2,4,3}
这个时候在新的数组求逆序对,是不是效果是一样的?
离散化下面有两种方法:
用unordered_map
遍历一遍直接将每个数映射到的数存起来,很好理解,直接看代码
unordered_map<int, int> ma;
for(int i = 0; i < v.size(); i++){ma[v[i]] = i + 1;
}
用xxx时,就改成用ma[x]ma[x]ma[x]即可。
-
优点:需要用数xxx时,直接用ma[x]ma[x]ma[x]就行,复杂度为O(1)O(1)O(1)
-
缺点:需要再遍历一遍数组,需要另开一个哈希表。
用lower_bound()
在vvv数组中二分查找xxx的下标,如果下标是pospospos,直接用pos+1pos + 1pos+1即可。
int get_pos(int x){return lower_bound(v.begin(), v.end(), x) - v.begin() + 1;
}
用xxx时,就改成用getpos(x)get_pos(x)getpos(x)即可。
-
优点:不用另开数组和mapmapmap
-
缺点:每次用都要二分一遍,复杂度O(logn)O(logn)O(logn)
例题
P1908 逆序对
const int N = 5e5 + 10;int n, m;
int a[N];
int tr[N];int lowbit(int x){ // lowbit运算,返回二进制的最低一位1return x & -x;
}void update(int x, int c){ // 相当于a[x] += cfor(int i = x; i <= m; i += lowbit(i)){tr[i] += c;}
}LL getsum(int x){ // 相当于求数组中a[1 ~ x]的前缀和LL res = 0;for(int i = x; i; i -= lowbit(i)){res += tr[i];}return res;
}int main(){ios::sync_with_stdio(false); cin.tie(0); cout.tie(0);cin >> n;vector<int> v;for(int i = 1; i <= n; i++){cin >> a[i];v.push_back(a[i]);}unordered_map<int, int> ma;sort(v.begin(), v.end());v.erase(unique(v.begin(), v.end()), v.end());m = v.size();for(int i = 0; i < m; i++){ma[v[i]] = i + 1;}LL res = 0;for(int i = 1; i <= n; i++){res += getsum(m) - getsum(ma[a[i]]);update(ma[a[i]], 1);}cout << res << endl;return 0;
}
const int N = 5e5 + 10;int n, m;
int a[N];
int tr[N];int lowbit(int x){ // lowbit运算,返回二进制的最低一位1return x & -x;
}void update(int x, int c){ // 相当于a[x] += cfor(int i = x; i <= m; i += lowbit(i)){tr[i] += c;}
}LL getsum(int x){ // 相当于求数组中a[1 ~ x]的前缀和LL res = 0;for(int i = x; i; i -= lowbit(i)){res += tr[i];}return res;
}int main(){ios::sync_with_stdio(false); cin.tie(0); cout.tie(0);cin >> n;vector<int> v;for(int i = 1; i <= n; i++){cin >> a[i];v.push_back(a[i]);}unordered_map<int, int> ma;sort(v.begin(), v.end());v.erase(unique(v.begin(), v.end()), v.end());m = v.size();for(int i = 0; i < m; i++){ma[v[i]] = i + 1;}LL res = 0;for(int i = 1; i <= n; i++){res += getsum(m) - getsum(ma[a[i]]);update(ma[a[i]], 1);}cout << res << endl;return 0;
}
举一反三1
Ping pong
const int N = 1e5 + 10;int n, a[N], tr[N];
LL l[N];int lowbit(int x){return x & -x;
}LL getsum(int x){LL res = 0;for (int i = x; i; i -= lowbit(i)) res += tr[i];return res;
}void update(int x, int c){for (int i = x; i < N; i += lowbit(i)) tr[i] += c;
}void solve(){cin >> n;LL res = 0;memset(tr, 0, sizeof tr);for(int i = 1; i <= n; i++){cin >> a[i];update(a[i], 1);l[i] = getsum(a[i] - 1);}memset(tr, 0, sizeof tr);for(int i = n; i >= 1; i--){update(a[i], 1);int y = getsum(a[i] - 1);res += l[i] * (n - i - y) + y * (i - l[i] - 1);}cout << res << endl;
}int main(){ios::sync_with_stdio(false); cin.tie(0); cout.tie(0);int T;cin >> T;while(T--){solve();}return 0;
}
举一反三2
P1637 三元上升子序列
const int N = 3e4 + 10;int n;
int tr1[N], tr2[N];int lowbit(int x){return x & -x;
}void update(int tr[], int x, int d){for(int i = x; i <= n; i += lowbit(i)){tr[i] += d;}
}int getsum(int tr[], int x){int res = 0;for(int i = x; i; i -= lowbit(i)){res += tr[i];}return res;
}int main(){ios::sync_with_stdio(false); cin.tie(0); cout.tie(0);cin >> n;vector<int> a(n + 1);for(int i = 1; i <= n; i++){cin >> a[i];}vector<int> b = a;sort(b.begin(), b.end());b.erase(unique(b.begin(), b.end()), b.end());unordered_map<int, int> ma;int m = b.size() - 1;for(int i = 1; i <= m; i++){ma[b[i]] = i;}vector<int> pre(n + 1, 0), suf(n + 1, 0);for(int i = 1; i <= n; i++){update(tr1, ma[a[i]], 1);pre[i] = getsum(tr1, ma[a[i]] - 1);}for(int i = n; i >= 1; i--){update(tr2, ma[a[i]], 1);suf[i] = getsum(tr2, m) - getsum(tr2, ma[a[i]]);}LL res = 0;for(int i = 2; i < n; i++){res += (LL)pre[i] * suf[i];}cout << res << endl;return 0;
}