用基础模型构建应用(第十章)AI Engineering: Building Applications with Foundation Models学习笔记
想知道如何构建成功的 AI 应用?前文已涵盖多种基础模型适配特定应用的技术,本章(AI Engineering Architecture and User Feedback AI 工程架构与用户反馈)聚焦如何整合这些技术以打造成功产品。从最基础的模型交互架构讲起,一步步通过增强上下文、搭建防护机制、部署模型网关、优化缓存等实用技巧,构建更可靠的 AI 系统。更有用户反馈收集与利用指南,帮助读者破解模型迭代难题,让 AI 产品从搭建到优化都有章可循!
目录
1 AI Engineering Architecture(AI 工程架构)
1.1 Step 1. Enhance Context(第一步:增强上下文)
1.2 Step 2. Put in Guardrails(第二步:设置防护机制)
1.3 Step 3. Add Model Router and Gateway(第三步:添加模型路由器和网关)
1.4 Step 4. Reduce Latency with Caches(第四步:利用缓存降低延迟)
1.5 Step 5. Add Agent Patterns(第五步:添加智能体模式)
1.6 Monitoring and Observability(监控和可观测性)
1.7 AI Pipeline Orchestration(AI 流程编排)
2 User Feedback(用户反馈)
2.1 Extracting Conversational Feedback(提取对话反馈)
2.2 Feedback Design(反馈机制设计)
2.3 Feedback Limitations(反馈的局限性)
1 AI Engineering Architecture(AI 工程架构)
1. 架构起点(最简单的 AI 应用架构):用户查询 → 直接调用模型API → 返回响应(无上下文增强、无防护机制、无优化)。仅包含模型API层(支持第三方API如OpenAI/Google/Anthropic或自托管模型)。
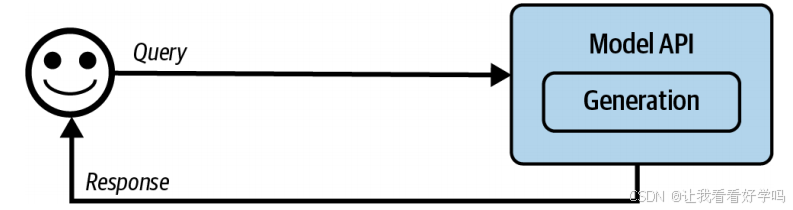
- 成熟的 AI 架构可能很复杂,本节将模拟团队在实际生产中的流程,从最简单架构开始,逐步添加组件进行讲解。尽管 AI 应用多样,但存在诸多通用组件。文中提出的架构已在多家公司验证,适用于广泛场景,不过部分特定应用可能有所偏离。
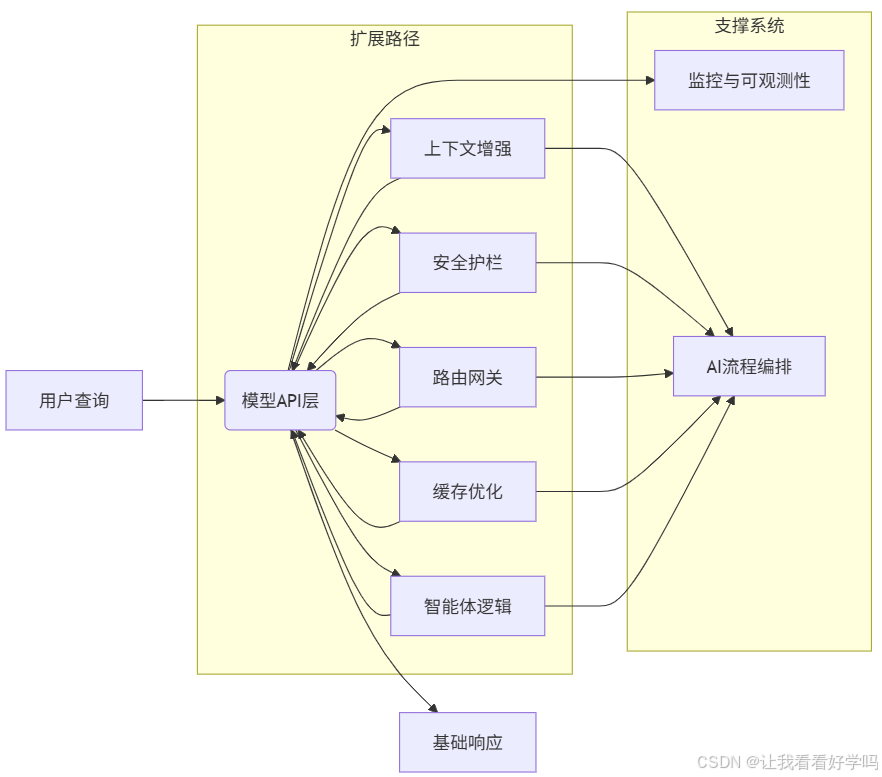
2. 架构组件的渐进式添加流程
按需逐步增加以下组件,顺序可根据应用情况调整:
| 步骤 | 新增组件 | 核心目标 | 实现方式 |
|---|---|---|---|
| 1 | 上下文增强 | 提升模型信息处理能力 | 接入外部数据源与信息采集工具 |
| 2 | 安全防护机制 | 系统与用户保护 | 植入行为约束机制 |
| 3 | 模型路由与网关 | 支持复杂管道 & 增强安全 | 构建请求分发与安全过滤层 |
| 4 | 缓存优化 | 降低延迟 & 控制成本 | 实施缓存策略 |
| 5 | 智能体逻辑 | 最大化系统能力 | 集成复杂决策逻辑与执行动作 |
3. 支撑系统(独立模块):①监控与可观测性(用于质量控制和性能改进,是任何应用的核心部分,架构演进完成后独立部署)。②AI 流程编排(将所有组件链接整合,需在组件完备后实现系统集成)。
1.1 Step 1. Enhance Context(第一步:增强上下文)
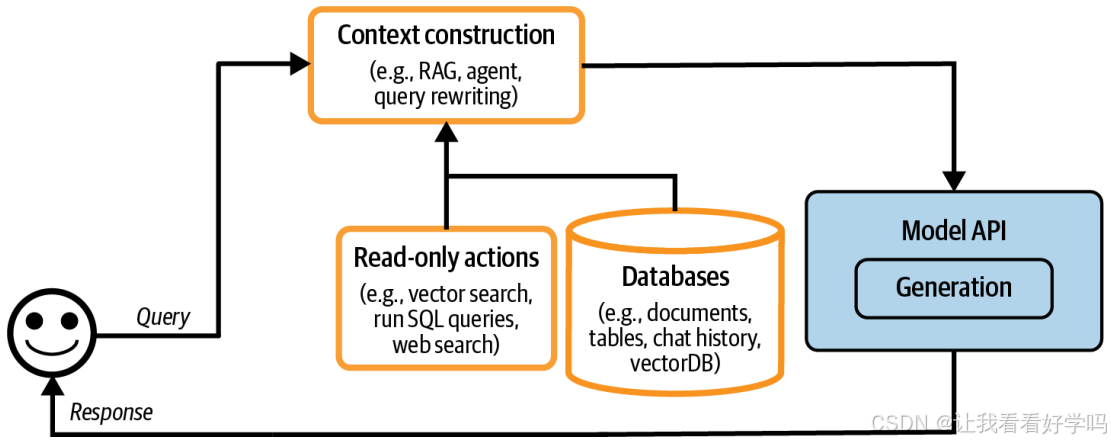
通过各种检索机制和工具构建模型所需的相关上下文,类似基础模型的特征工程,为模型提供生成输出所需的必要信息,直接影响系统输出质量。不同模型 API 提供商和框架在上下文构建支持上存在差异(如文档上传限制、检索算法等)。
1. 增强上下文的核心目的:平台初期扩展的核心任务是添加机制,使系统能构建模型回答每个查询所需的相关上下文。主流模型API提供商普遍支持上下文构建(如 OpenAI、Claude、Gemini 允许用户上传文件和使用工具)。
2. 上下文的构建方式
- 检索机制:通过文本检索、图像检索、表格数据检索等方式构建(第六章已讨论)。
- 工具调用:利用工具(如网页搜索、新闻/天气/事件等 API工具链实时信息采集)让模型自动收集信息,实现上下文增强。
3. 不同方案在上下文构建中的差异
| 对比维度 | 专用RAG解决方案 | 通用模型API(OpenAI/Claude/Gemini等) |
|---|---|---|
| 文档支持 | 无上限(取决于向量数据库容量) | 严格限制上传文档数量/类型 |
| 检索算法 | 可定制(chunk size/相似度计算等) | 固定配置(黑盒优化) |
| 工具扩展 | 支持复杂工作流(并行执行/长时任务) | 基础API调用(有限工具类型) |
-
选型建议:高定制需求 → 采用专用RAG框架(如LlamaIndex, LangChain);快速部署 → 利用模型API原生工具(如OpenAI File Upload)。
- 添加上下文构建后,架构如下图所示(平台架构纳入上下文构建组件)。
1.2 Step 2. Put in Guardrails(第二步:设置防护机制)
用于降低风险,保护系统和用户,分为输入防护和输出防护。
1.2.1 Input guardrails(输入防护)
防范向外部 API 泄露隐私信息和执行恶意提示。可通过工具检测敏感数据,处理方式为拦截查询或移除敏感信息。
1. 输入防护主要应对两类风险(由于模型生成响应的固有特性及不可避免的人为失误,风险无法完全消除,只能缓解)
- ①外部API数据泄露(使用外部模型 API 时,数据需发送至组织外部,可能导致泄露):员工误粘贴机密信息至第三方API、系统提示词包含公司内部策略、工具检索私有数据并添加到上下文。
- ②恶意提示攻击:提示注入、越权指令、模型劫持等(第五章详述)。
2. 隐私信息泄露的缓解措施
- 敏感数据检测工具:利用现有工具自动检测敏感信息(检测范围可自定义),常见敏感数据类别包括个人信息(身份证号、手机号、银行账户等)、与公司知识产权或特权信息相关的特定关键词和短语等。
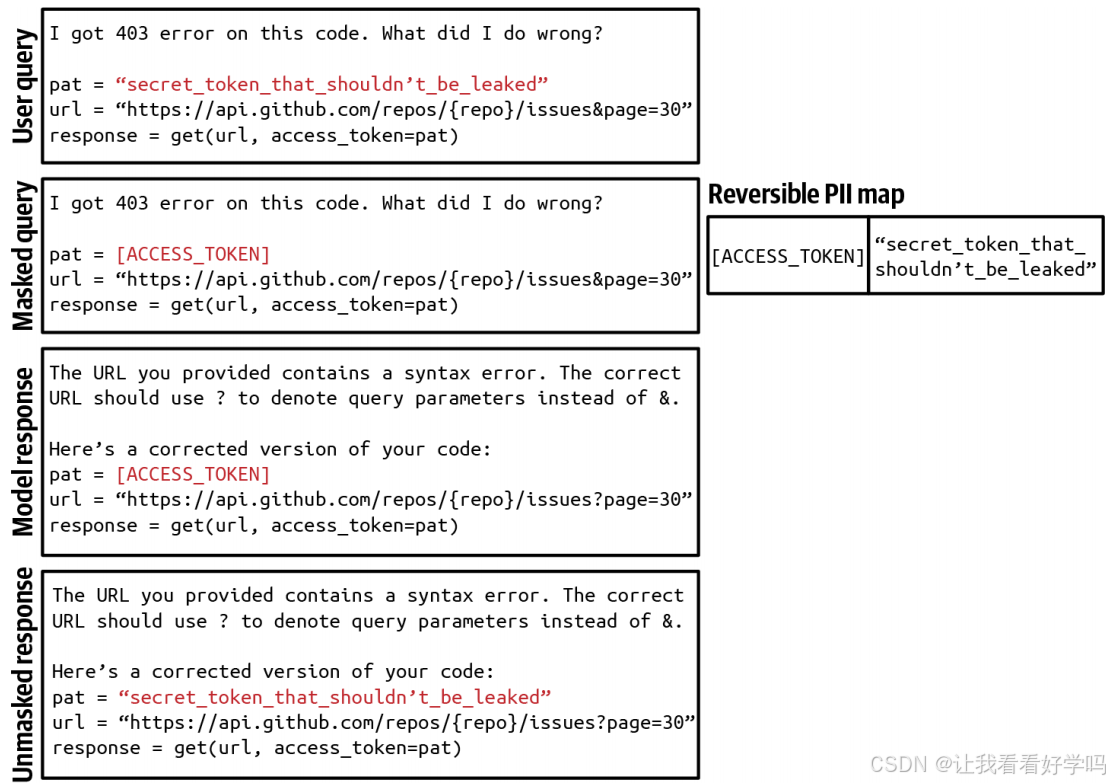
- 处理方式:若查询含敏感信息,可选择拦截整个查询,或移除敏感信息(如用占位符 [PHONE NUMBER] 掩盖手机号)。
- 若生成的响应包含占位符,可通过 PII 反向字典(映射占位符与原始信息)进行还原(如下图),避免敏感信息发送至外部 API。
1.2.2 Output guardrails(输出防护)
捕捉输出失败并指定处理策略。常见失败包括质量问题和安全问题。可通过重试逻辑或移交人工处理。
1. 输出防护的核心功能:①捕获输出故障:识别模型生成结果中不符合标准的问题。②制定故障处理策略:针对不同故障模式明确应对规则。
2. 输出故障的类型与表现:需结合具体应用场景判断,常见故障分为质量和安全两大类。
- 质量故障:①格式错误(如预期返回 JSON 却生成无效格式)。②模型幻觉导致的事实不一致回答。③整体质量差(如生成的文章质量低下)。
- 安全故障:①包含种族歧视、色情、违法内容的有害回答。②泄露隐私和敏感信息的回答。③触发远程工具或代码执行的回答。④损害品牌形象(如错误描述公司或竞争对手)的回答。
- 安全故障的特殊考量:需同时关注安全故障和 “误拒率”(错误拦截合法请求的比例)。过度严格的防护可能导致系统拦截正常请求,影响用户体验并引发不满。
3. 输出故障的处理策略
1)重试机制:基于 AI 模型的概率性特点,重试可能获得不同结果(如为空响应重试 X 次,或直到生成非空结果;格式错误时重试至格式正确)。
- 权衡:重试会增加延迟和成本(每次重试意味着额外 API 调用,失败后重试可能使用户感知延迟翻倍)。
- 优化方案:并行调用(同一查询同时发送多次请求,选择最优结果),以冗余 API 调用换取可控的延迟。
2)人工介入:针对复杂请求,可转交人工处理(如含特定短语的查询)。部分团队通过专用模型决定是否转人工。
| 触发条件 | 实现方案 | 行业案例 |
|---|---|---|
| 特定关键词命中 | 短语规则库匹配 | 金融客服敏感词移交 |
| 用户情绪恶化 | 情绪分析模型阈值触发 | 电商对话愤怒用户转人工 |
| 死循环预防 | 对话轮次计数器 | 技术支持系统3轮移交规则 |
1.2.3 Guardrail implementation(防护机制实现)
存在可靠性与延迟的权衡,在流完成模式下效果可能不佳。实现方式取决于模型部署方式(自托管或第三方 API),可借助现成工具,部分模型网关也提供防护功能。
1. 防护机制的权衡与限制
-
可靠性与延迟的权衡:防护机制虽重要,但会增加应用延迟,部分团队因优先考虑低延迟而选择不实施过多防护。
-
流式输出模式的适配问题:在流式生成模式(新 token 实时推送给用户)中,输出防护难以评估部分响应,可能导致不安全内容在防护机制判定前已被用户看到(默认模式下需生成完整响应后展示,延迟较高但便于防护)。
2. 防护机制的实施差异
-
①第三方 API:提供商通常内置多种防护机制,可减少应用方需自行实现的防护量。
-
②自托管模型:无需向外部发送请求,减少了对输入防护的需求,但需自行构建更多防护组件。
3. 防护机制的实施层级与工具
1)实施主体:
- 模型提供商:为模型内置防护以提升安全性,但需平衡安全性与灵活性(过度限制可能降低模型在特定场景的可用性)。
- 应用开发者:可基于现有技术实现防护(如第五章中对抗提示词攻击的防御手段)。
2)现成防护工具:包括 Meta 的 Purple Llama、NVIDIA 的 NeMo Guardrails、Azure 的 PyRIT 与 AI 内容过滤器、Perspective API、OpenAI 的内容审核 API 等,通常同时支持输入和输出防护(因输入与输出风险存在重叠)。
3)模型网关:部分网关也集成防护功能(下一节将讨论)。
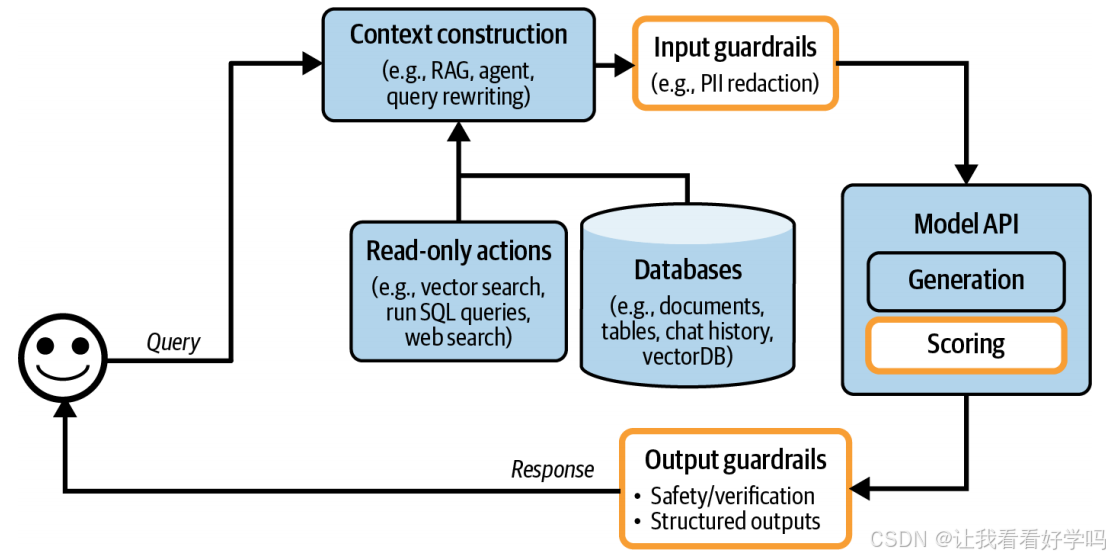
4. 含防护机制的架构变化:添加输入和输出防护后的架构(如下图),其中 “评分器(scorers)” 多为 AI 驱动(通常比生成式模型更小、更快),图中置于模型 API 下方,也可纳入输出防护模块。
1.3 Step 3. Add Model Router and Gateway(第三步:添加模型路由器和网关)
路由器和网关通过智能调度请求与统一管控流量,化解多模型系统的复杂协同难题并实现成本优化。
1.3.1 Router(路由器)
据查询类型路由到不同解决方案,可使用专门模型提升性能、节省成本。由意图分类器预测用户意图,还可辅助模型决策下一步行动。通常基于较小模型实现,需考虑查询上下文与模型上下文限制的匹配。
1. 路由机制的核心思路:不为所有查询使用单一模型,而是针对不同类型查询采用不同解决方案。
- 优势:①性能优化:特定查询路由至专用模型(如:技术故障排查用专门模型,账单问题用另一专门模型)。②成本降低:简单查询路由至廉价模型,避免所有查询都使用昂贵模型。
2. 路由机制的核心组件:意图分类器与扩展功能
-
意图分类器(核心):预测用户意图,据此将查询路由至合适的解决方案。
- 应用示例(以客户支持聊天机器人为例):用户想重置密码→路由至密码恢复 FAQ 页面;用户要求纠正账单错误→路由至人工操作员;用户咨询技术故障→路由至专门的故障排查聊天机器人。
- 附加作用:①阻止系统参与超出范围的对话(如用户询问选举投票倾向时,用预设回复礼貌拒绝,避免无效 API 调用)。②检测模糊查询并请求澄清(如用户输入 “Freezing” 时,询问是 “冻结账户” 还是 “谈论天气”)。
-
下一步动作预测器:辅助模型决定后续操作(如判断接下来应使用代码解释器还是搜索 API,或从记忆层级的哪个部分提取信息)。
3. 路由机制的实现方式:意图分类器和下一步动作预测器可基于基础模型实现,常见方案包括①适配小型语言模型(如 GPT-2、BERT、Llama 7B)。②从零训练更小的分类器。
- 关键要求:路由机制需快速且低成本,以便多次使用时不会显著增加延迟和成本。
4. 路由与上下文限制的适配问题:当查询被路由至不同上下文限制的模型时,可能需要调整查询的上下文。如原计划将 1000 token 的查询路由至 4K 上下文限制的模型,但后续操作(如网页搜索)返回 8000 token 的上下文,此时可选择截断上下文以适配原模型,或路由至更大上下文限制的模型。
5. 含路由机制的架构变化
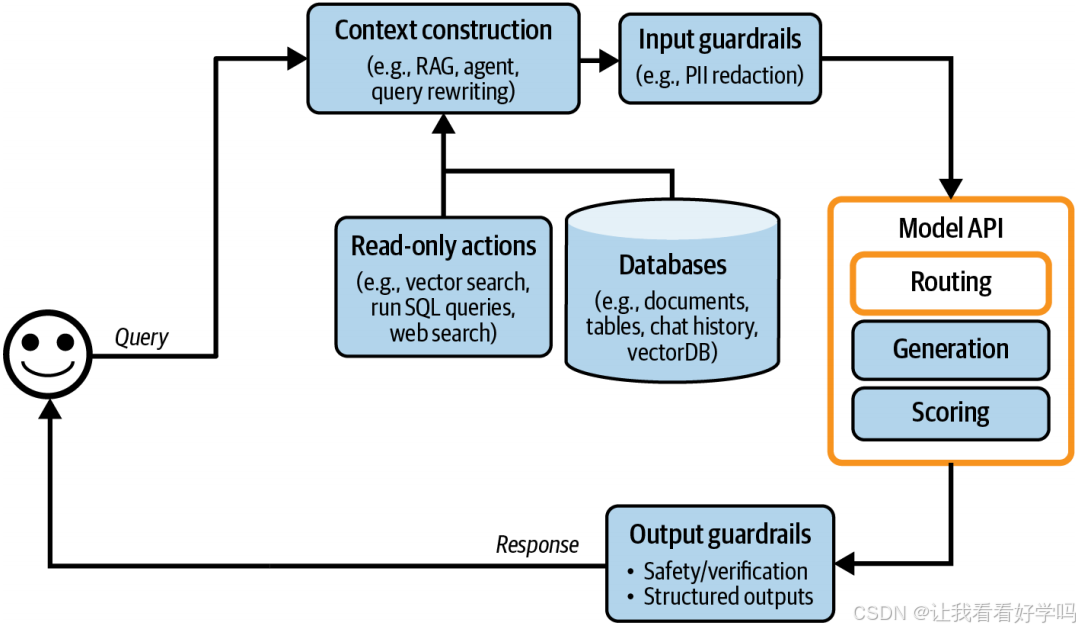
- 架构位置:如上图所示,路由通常被纳入 “模型 API” 模块(因路由多由模型实现),且路由模型通常比生成式模型更小;与其他模型分组管理可提升便利性。
- 常见流程与时机:路由常发生在①检索之前(例如,判断查询是否在范围内、是否需要检索);②检索之后(例如,判断是否需转人工)。
- 最常见模式:路由→检索→生成→评分。
1.3.2 Gateway(网关)
网关作为中间层,提供统一、安全的接口对接不同模型(自托管和商业 API),使组织能以统一、安全的方式与不同模型交互。便于代码维护、访问控制、成本管理、实现 fallback 策略等,还可集成负载均衡、日志、分析等功能,有现成工具(如 Portkey’s AI Gateway、MLflow AI Gateway 等)。
1. 模型网关功能:提供统一接口,兼容自托管模型和商业 API 背后的模型,简化代码维护。
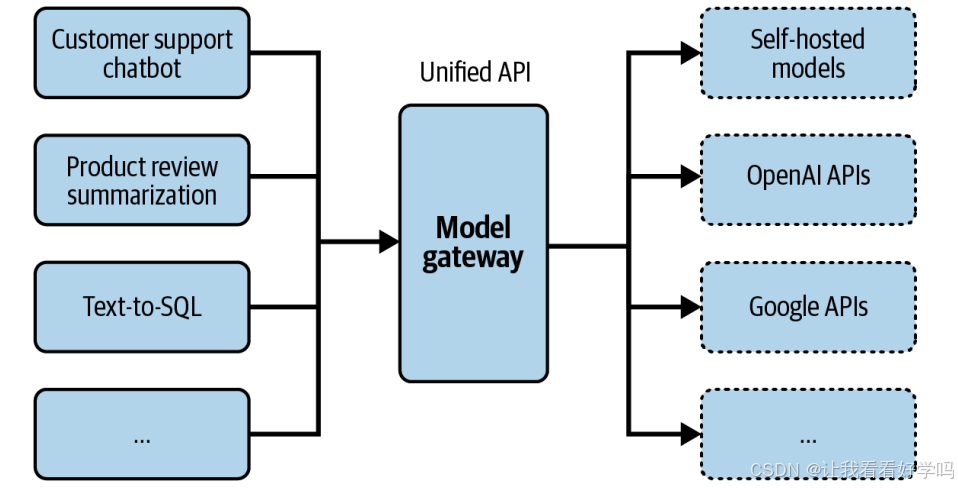
-
维护优势:模型API变更时,只需更新网关,无需修改所有依赖该 API 的应用。
-
技术本质:“统一封装器”,标准化调用协议(屏蔽不同模型API差异),通过代码逻辑对不同模型 API(如 OpenAI、Gemini)进行封装,对外提供统一调用入口(示例代码展示了根据 model_type 路由请求至对应模型的逻辑,不含错误检查和优化)。
import os
from flask import Flask, request, jsonify
import google.generativeai as genai
import openaiapp = Flask(__name__)def openai_model(input_data, model_name, max_tokens):openai.api_key = os.environ["OPENAI_API_KEY"]response = openai.Completion.create(engine=model_name,prompt=input_data,max_tokens=max_tokens)return {"response": response.choices[0].text.strip()}def gemini_model(input_data, model_name, max_tokens):genai.configure(api_key=os.environ["GOOGLE_API_KEY"])model = genai.GenerativeModel(model_name=model_name)response = model.generate_content(input_data)return {"response": response.text}@app.route('/model', methods=['POST'])
def model_gateway():data = request.get_json()required_fields = ["model_type", "model_name", "input_data", "max_tokens"]if not all(field in data for field in required_fields):return jsonify({"error": "Missing required fields"}), 400try:if data["model_type"] == "openai":result = openai_model(data["input_data"], data["model_name"], data["max_tokens"])elif data["model_type"] == "gemini":result = gemini_model(data["input_data"], data["model_name"], data["max_tokens"])else:return jsonify({"error": "Invalid model type"}), 400return jsonify(result)except Exception as e:return jsonify({"error": str(e)}), 500if __name__ == '__main__':app.run()2. 模型网关的扩展功能
1)访问控制与成本管理(集中化权限管理):避免直接将组织 API token 提供给每个想要访问 OpenAI API 的人(易泄露),仅通过网关授予访问权限(只让人们访问模型网关,创建一个集中且可控的访问点),降低泄露风险。
- 网关可以①实施细粒度的访问控制,指定哪些用户或应用程序有权访问哪些模型。②监控和限制API调用的使用情况,有效防止滥用并管理成本。
2)故障应对与稳定性保障(降级与容错机制):当主 API 因速率限制或故障不可用时,网关可自动执行路由请求至替代模型、短时间后重试或其他故障处理方式,确保应用持续运行,避免中断。
3)附加功能(基于流量中枢的扩展能力):因请求和响应均流经网关,可在此实现负载均衡、日志记录、数据分析等功能,部分网关还集成缓存和防护机制。
3. 现成模型网关工具:由于实现相对简单,存在多种现成解决方案,例如 Portkey 的 AI Gateway、MLflow AI Gateway、Wealthsimple 的 LLM Gateway、TrueFoundry、Kong、Cloudflare 等。
4. 含网关的架构变化
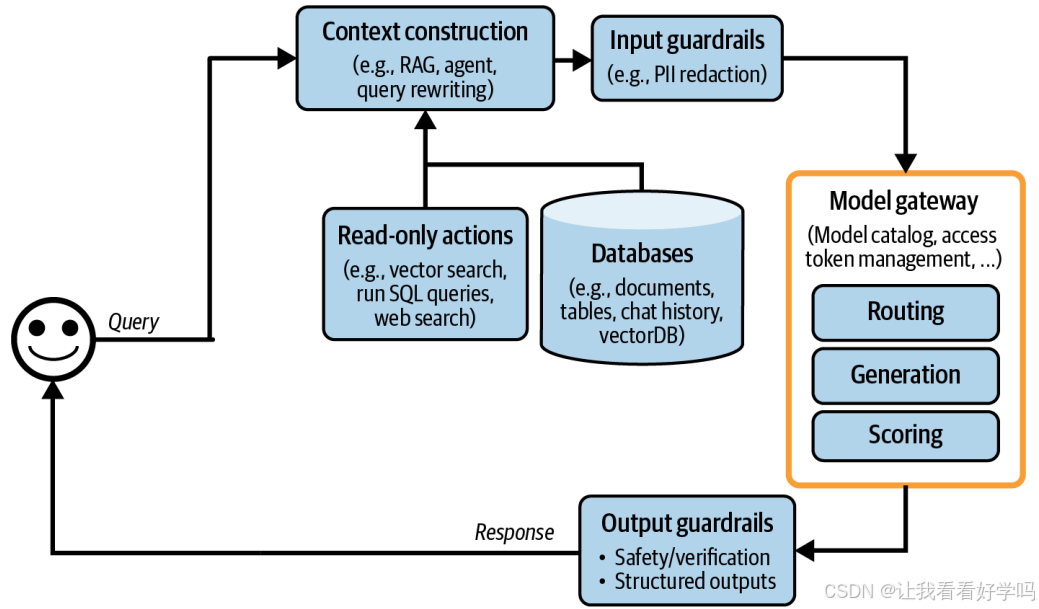
- 在架构中,网关取代了原有的 “模型 API” 模块(如上图),与路由模块共同构成新架构。
1.4 Step 4. Reduce Latency with Caches(第四步:利用缓存降低延迟)
作为软件应用的传统技术,缓存可减少延迟并降低成本,其理念同样适用于 AI 应用(第九章已讨论推理缓存技术,如 KV 缓存、提示词缓存,本节聚焦系统级缓存)。系统缓存主要有两种机制:精确缓存和语义缓存。
1.4.1 Exact caching(精确缓存)
1. 定义:精确缓存是指仅当收到完全相同的请求时,才调用缓存中的内容,即缓存项与请求需完全匹配才能生效。
2. 应用场景:①生成任务:用户请求某产品总结时,系统先检查缓存中是否有该产品的精确总结,有则直接返回,无则生成后缓存。②嵌入检索任务:向量搜索中,若输入查询已在缓存中,直接获取结果;否则执行搜索并缓存。
- 优势场景:适合涉及多步骤(如思维链推理)或耗时操作(如检索、SQL 执行、网页搜索)的查询,可减少重复计算。
3. 存储方式:①可采用内存存储(快速检索)。②可结合 PostgreSQL、Redis、分层存储等,平衡检索速度与存储容量。
4. 缓存管理策略
- 淘汰机制:需设置缓存淘汰策略控制大小,常见策略包括最近最少使用(LRU)、最不常用(LFU)、先进先出(FIFO)。
- 缓存时长判断:取决于查询被重复调用的概率,例如①优化方式:部分团队通过训练分类器预测查询是否适合缓存。②不适合缓存:用户特定查询(如 “我的订单状态”)、时间敏感查询(如 “今天天气如何”)。
5. 精确缓存的风险:数据泄露
- 风险场景:若缓存处理不当,可能泄露隐私信息。例如电商场景中,用户 X 询问 “电子产品退货政策”,系统结合其会员信息生成含个人数据的响应并错误缓存。
- 本质原因:对包含隐性用户特征的 “看似通用” 查询误判,缓存了含个人信息的结果。
1.4.2 Semantic caching(语义缓存)
1. 语义缓存的定义:与精确缓存不同,即使缓存项与输入查询不完全相同但语义相似,也可调用缓存内容。
- 示例:用户 A 询问 “越南的首都是什么?”,模型回答 “河内”;当用户 B 询问 “越南的首都城市是什么?”(语义相同但表述略有差异)时,系统可复用缓存的 “河内” 作为答案。
- 优势:提高缓存命中率,潜在降低成本。
2. 语义缓存的实现原理
依赖语义相似度判断,步骤如下:
- 为每个查询生成嵌入向量(使用嵌入模型)。
- 通过向量搜索,找到与当前查询嵌入向量相似度最高的缓存嵌入向量,得到相似度分数 X。
- 若 X 超过预设阈值,则认为两查询语义相似,返回缓存结果;否则处理当前查询,并将其嵌入向量与结果存入缓存。
- 依赖组件:需向量数据库存储缓存查询的嵌入向量。
3. 语义缓存的局限性与风险
- 性能依赖多环节:成功与否取决于高质量嵌入、有效向量搜索、可靠相似度,任一环节出错都会影响效果。
- 阈值设置难题:相似度阈值需大量试错调整,若设置不当,可能将不相似查询误判为相似,返回错误结果。
- 效率与成本问题:涉及向量搜索,耗时且计算密集,速度和成本取决于缓存嵌入向量的规模。
- 性能风险:可能降低模型输出质量(如返回不匹配的缓存结果)。
4. 语义缓存的适用前提:仅当缓存命中率足够高(大量查询可通过缓存有效回答)时才值得使用,且需先评估其效率、成本及性能风险。
5. 含缓存的架构变化
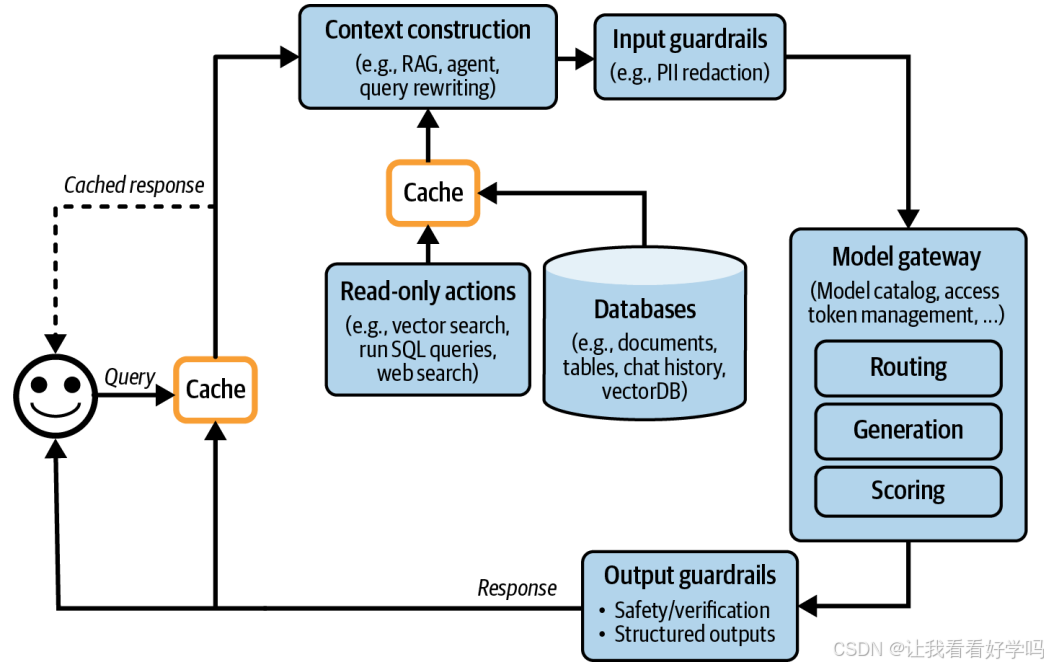
- 添加上下文缓存后,架构如上图所示,新增箭头表示将生成的响应存入缓存的流程。KV 缓存和提示词缓存通常由模型 API 提供商实现,故未在图中显示(逻辑上属于 “模型 API” 模块)。
1.5 Step 5. Add Agent Patterns(第五步:添加智能体模式)
用于构建复杂应用。模型输出可反馈到系统进行进一步处理(如补充检索),还可调用写操作(如发邮件、下单等)。
1. 智能体模式的核心作用:处理复杂流程
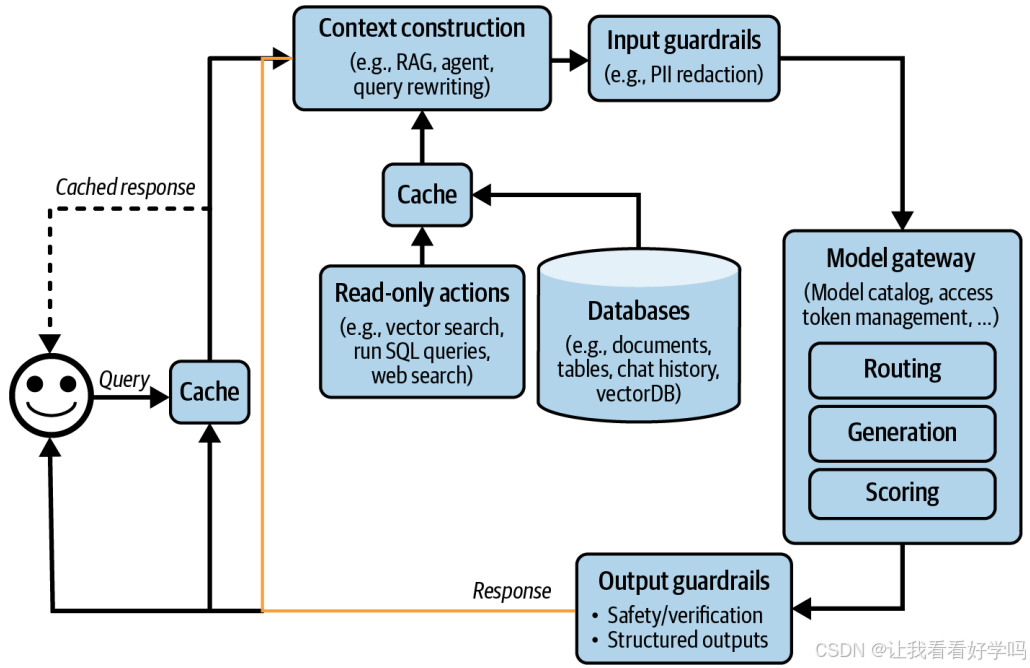
- 前几种的应用流程较简单(多为顺序执行),而智能体模式(第六章已提及)可支持更复杂的应用逻辑,包括循环、并行执行、条件分支等。
- 示例:系统生成输出后,若判断任务未完成,可触发再次检索以收集更多信息,将原始响应与新检索的上下文传入同一模型或不同模型,形成循环流程(如下图所示,黄色箭头表示生成的响应可反馈回系统,支持复杂模式)。
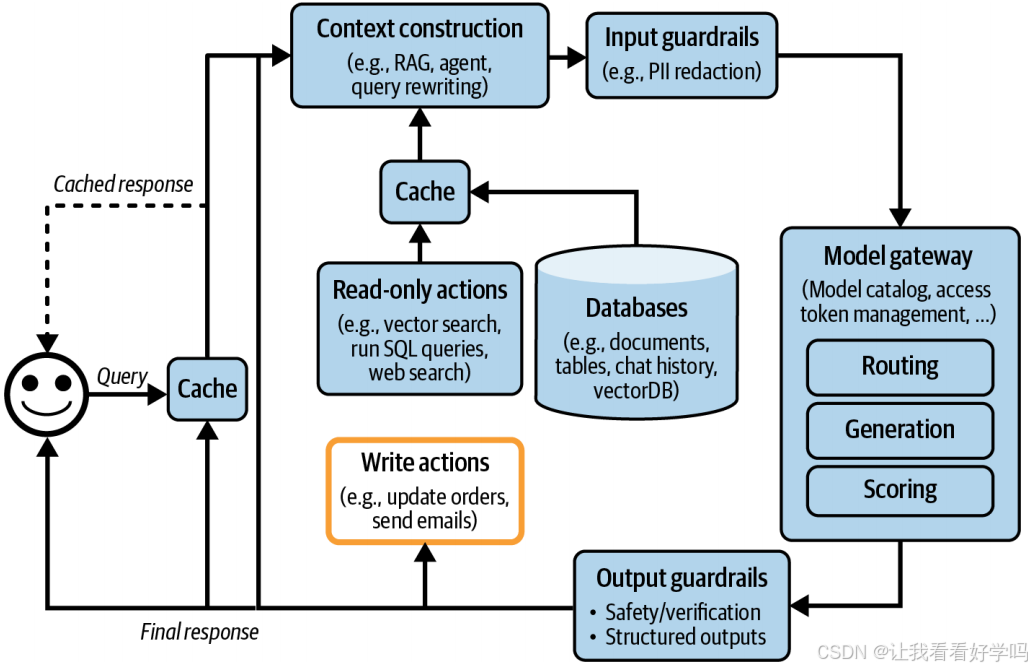
2. 写入操作(Write actions):模型输出可用于触发写入操作,直接改变系统环境,例如撰写邮件、下单、初始化银行转账等。此类操作能极大提升系统能力。但写入操作也会带来风险,需谨慎赋予模型写入权限。下图为添加入写操作后的架构。
3. 复杂架构的挑战:按上述步骤逐步添加组件后,架构会变得复杂,虽能解决更多任务,但也会引入更多故障模式,因潜在故障点增多而更难调试。
1.6 Monitoring and Observability(监控和可观测性)
- 重要性:监控与可观测性是产品设计的核心,而非事后补充,复杂系统尤其关键,目标是降低风险、发现改进机会和成本节约点。
- 关键指标:源自 DevOps 社区的 MTTD(故障发生到被检测出的平均检测时间)、MTTR(故障被检测出来到解决的平均响应时间)、CFR(变更失败率,导致故障且需修复 / 回滚的变更或部署占比。若无法统计 CFR,需重新设计系统以提升可观测性)。
-
评估与监控的协同关系:两者需紧密联动,评估指标应能转化为监控指标(评估中表现好的模型,监控中也应表现好);监控中发现的问题需反馈至评估流程。
-
高 CFR 未必意味着监控系统差,但需优化评估流程,在部署前拦截不良变更。
-
- 监控与可观测性的区别:跟踪系统外部输出以判断内部是否出错,但不保证能通过外部输出定位具体问题;可观测性假设通过外部输出能推断内部状态,需收集和分析足够的运行时信息,确保故障发生时无需新增代码即可定位问题。
1.6.1 Metrics(指标)
1. 指标的目的:指标本身不是目标,而是用于判断系统是否出现问题、识别改进机会的工具(例如,输出相关性分数需服务于实际业务需求才有意义)。
- 设计逻辑:需先明确要捕获的故障模式,再针对性设计指标。例如①若需避免幻觉,可设计 “输出是否能从上下文推断” 的指标。②若需控制 API 成本,可跟踪 “每请求输入 / 输出 token 数”“缓存成本与命中率” 等。
- 特殊性:基础模型输出具有开放性,故障模式多样,指标设计需结合分析思维、统计知识和创造力,且高度依赖具体应用场景。
2. 常见监控指标分类与示例
1)模型质量相关指标
- 格式故障指标:易检测和验证,例如预期 JSON 输出时,跟踪 “无效 JSON 占比” 及 “可修复比例”(如缺失闭合括号易修复,缺失关键键值难修复)。
- 开放式生成质量指标:事实一致性、相关性、简洁性、创造性、积极性等(可通过 AI 评判器计算)。
- 安全性指标:①毒性相关指标、输入 / 输出中的隐私敏感信息检测。②防护机制触发频率、系统拒绝回答的频率。③异常查询检测(可能暴露边缘案例或提示词攻击)。
- 用户反馈与交互信号:①用户中途终止生成的频率。②平均对话轮次、每轮输入 / 输出 token 数(反映任务复杂度或模型 verbose 程度)。③输出 token 分布及变化(反映多样性变化)。
2)组件与系统层面指标
- 特定组件指标:例如 RAG 应用需跟踪检索上下文相关性与精度;向量数据库需跟踪存储需求、查询耗时。
- 业务关联指标:需分析指标与业务北极星指标(如日活 DAU、会话时长、订阅量)的相关性,以明确优化方向(强相关指标可指导北极星指标提升,弱相关指标可排除无效优化点)。
- 延迟指标(参考第九章):首 token 生成时间(TTFT)、每输出 token 耗时(TPOT)、总响应延迟。需按用户维度拆分,评估系统在用户量增长时的表现。
- 成本与资源指标:请求量、输入 / 输出 token 总量、token 每秒(TPS)。若使用有速率限制的 API,需跟踪 “每秒请求数” 以避免超出限制导致服务中断。
3. 指标计算与分析的实用策略
- 数据抽样方式:①抽查(spot checks):抽样数据快速识别问题。②全量检查(exhaustive checks):评估所有请求以全面了解性能。建议结合两者,平衡效率与全面性。
- 粒度要求:指标需可按 “用户、版本、提示词 / 链类型、时间” 等维度拆分,以定位具体问题。
- 指标设计需服务于 “故障检测” 和 “改进机会识别”,需结合应用场景定制,并通过多维度分析与业务目标关联,实现有效监控。
1.6.2 Logs and traces(日志和追踪)
- 日志是事件的追加记录,便于调试;追踪是关联事件形成的完整事务时间线,显示请求执行路径、各步骤耗时和成本等。
1. 日志:是追加式的事件记录(仅可新增,不可修改),与指标(聚合性数值)不同,可记录具体事件细节。
- 核心作用:补充指标的局限性,帮助定位问题根源。例如指标显示 5 分钟前出现异常时,可通过查看同期日志还原事件过程,确认 “是否曾发生过类似问题”。
- 日志记录原则:
- 1)全面性(需记录所有关键信息),包括①配置细节(模型 API 端点、模型名称、采样参数如 temperature/top-p、提示词模板版本等)。②用户查询、发送给模型的最终提示词、输出结果及中间输出。③工具调用行为、组件启动 / 结束 / 崩溃事件等。
- 2)可追溯性:每条日志需添加标签和 ID,明确其在系统中的来源位置。
- 日志管理:日志量会快速增长,可借助 AI 驱动的自动化分析工具检测异常。
- 人工每日检查日志的价值:开发者通过接触更多数据,能更新对 “好坏输出” 的认知,进而优化提示词和评估流程(Shankar et al., 2024)。
2. 追踪:通过关联相关事件,重构完整的事务或流程时间线,记录一个请求在系统各组件中的执行路径细节。
- 核心作用:展示从用户发送查询到返回最终响应的完整过程,包括①系统执行的所有操作(如检索的文档、调用的工具)。②每个步骤的耗时、可量化的成本。逐步骤追踪查询的处理过程,精准定位失败环节(如处理错误、检索上下文无关、模型输出错误等)。
- 示例:LangSmith 可视化的请求追踪(下图),可直观展示一个查询的完整执行链路。
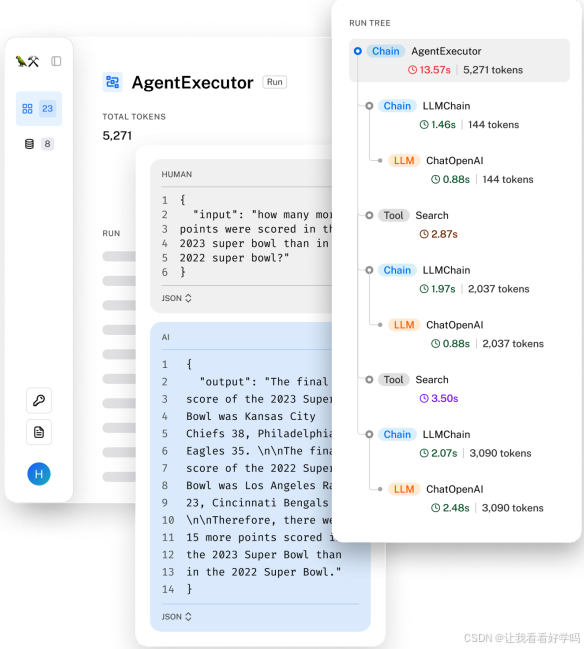
3. 日志与追踪的协同价值:指标提供系统整体状态的 “警报”,日志提供事件细节,追踪则还原完整执行路径,三者结合实现从 “发现异常” 到 “定位根因” 的全流程问题排查。
1.6.3 Drift detection(漂移检测)
漂移的本质是系统组件的变化风险。系统组成部分越多,可能发生变化的环节就越多。在AI应用中,关键变化点包括:系统提示、用户行为、底层模型。
1. 系统提示词变化(System prompt changes)
- 原因:可能因提示词模板更新、同事修正拼写错误等原因发生,且可能未被明确告知。
- 检测方式:通过简单逻辑校验(如哈希值对比)即可捕获提示词的变更。
2. 用户行为变化(User behavior changes)
- 本质:用户会逐渐适应技术并调整行为以获取更好结果(例如:学习优化查询句式(Google搜索技巧)、通过特定行为影响系统决策(“逼迫”自动驾驶汽车让行))。
- 影响:可能引发指标渐变(如用户要求简洁回复 → 响应长度逐渐下降)
-
检测难点:仅看指标无法定位根因(需结合用户行为分析)。
-
解决方案:主动调查(如用户反馈分析、交互日志研究)。
3. 底层模型变化(Underlying model changes)
- 原因:API接口不变,但后端模型升级(供应商可能未主动通知)。
- 影响:不同版本模型性能可能差异显著,例如GPT-4/GPT-3.5不同版本间基准得分差异明显(Chen et al., 2023)。
-
检测方法:需主动监控模型输出(如设置一致性测试或性能基线)。
1.7 AI Pipeline Orchestration(AI 流程编排)
1. AI 流程编排的核心价值
- 问题背景:AI应用复杂度高(多模型、多数据源、多工具) → 需协调组件间协作与数据流
- 解决方案:编排器(Orchestrator) = 定义组件关系 + 控制端到端流程执行
- AI编排器(专为AI流程设计) vs. 通用工作流工具
| 对比维度 | AI专用编排器 | 通用工具(如Airflow) |
|---|---|---|
| 核心目标 | 优化AI组件协作 | 通用任务调度 |
| 典型能力 | Prompt模板处理、模型输出解析 | 定时任务、依赖管理 |
| 代表工具 | LangChain/LlamaIndex/Haystack | Airflow/Metaflow |
2. 编排器的核心操作步骤
1)组件定义(Components Definition):向编排器声明系统使用的所有组件,包含模型(通过Model Gateway快速接入)、外部数据源(检索库/知识库)、工具(功能插件)、评估/监控工具(如有)。
2)链式编排(Chaining):本质是 “函数组合”,定义从接收用户查询到完成任务的完整步骤。

- 核心职责:在组件间传递数据,提供工具确保步骤输出格式符合下一步预期,并在数据流转中断(如组件故障、数据不匹配)时发出通知。
3. 流程设计与工具选择
1)低延迟场景的优化建议:对延迟要求严格的应用,尽量并行处理步骤(例如,路由组件与 PII 移除组件可同时运行)。
2)常见 AI 编排工具:包括 LangChain、LlamaIndex、Flowise、Langflow、Haystack 等,许多 RAG 和智能体框架也具备编排功能(因检索和工具使用是常见模式)。
3)工具选择的考量因素
- 集成性与可扩展性:是否支持现有及未来可能采用的组件;不支持的组件是否易于扩展集成。
- 复杂流水线支持:能否处理多步骤、条件逻辑、分支、并行处理、错误处理等复杂场景。
- 易用性(API 直观性、文档完整性、社区支持(降低学习成本))、性能(避免隐藏 API 调用或引入额外延迟)、可扩展性(能否随应用、开发者数量及流量增长而扩展)。
4. 实践建议:项目初期暂不使用编排工具(外部工具会增加复杂度,增加理解与调试难度),随复杂度上升逐步引入编排器降低维护成本。
2 User Feedback(用户反馈)
用户反馈不仅用于评估应用性能和指导开发,还是改进模型的专有数据,助力数据飞轮,但需秉持用户隐私保护的原则。
2.1 Extracting Conversational Feedback(提取对话反馈)
1. 传统反馈的分类:显性与隐性
-
显性反馈(Explicit feedback):用户响应应用明确请求提供的反馈,如点赞 / 踩、投票、星级评分、“是否解决问题” 的是非回答等。
- 特点:在各类应用中较为标准化(询问用户喜好的方式有限),因此更容易理解和处理。
-
隐性反馈(Implicit feedback):从用户行为中推断出的信息(例如,用户购买推荐产品意味着推荐质量高)。
- 特点:高度依赖应用场景,取决于用户在应用内可执行的操作;基础模型催生了更多新应用场景,也带来了更多隐性反馈类型。
2. 对话式反馈的特殊性与提取价值
- 对话界面的优势:AI 应用的对话式界面让用户更易自然反馈(如日常对话中鼓励良好表现、纠正错误),用户的语言表达可同时传递对应用性能的评价和个人偏好。
- 示例:用户规划澳大利亚旅行时,AI 推荐悉尼酒店后,用户回应 “预订靠近画廊的那家” 体现对艺术相关推荐的偏好;回应 “没有 200 美元以下的吗?” 则反映价格敏感需求,暗示 AI 未精准匹配需求。
- 应用场景:提取的对话反馈可用于①评估:生成监控应用的指标。②开发:训练未来模型或指导模型迭代。③个性化:为每位用户定制应用体验。
- 对话式反馈的提取挑战:隐性对话反馈融入日常对话中,提取难度较大,需结合对对话线索的直觉、严谨的数据分析和用户研究才能有效识别。
2.1.1 Natural language feedback(自然语言反馈)
| 反馈类型 | 具体表现 / 示例 | 解读与潜在含义 |
|---|---|---|
| 提前终止互动(Early termination) | 用户中途停止生成响应、退出应用、让语音助手停止、无回应等。 | 暗示对话未达预期,用户可能对当前交互不满。 |
| 错误纠正(Error correction) | - 直接纠正:以 “No, …”“I meant, …” 开头 - 重新表述:改写请求以纠正误解 - 具体纠错:“Bill 是嫌疑人,不是受害者” - 行动导向纠错:“做 XYZ 公司分析时,还应查其 GitHub 页面” | 表明模型理解存在偏差,需修正输出(如摘要、分析结果)或优化任务执行路径。 |
| 请求确认与验证(Explicit confirmation) | 用户询问 “你确定吗?”“再检查一遍”“展示来源” 等。 | 未必说明答案错误,但可能暗示输出缺乏用户所需细节,或反映用户对模型的普遍不信任。 |
| 直接编辑模型输出(User edits) | 用户修改模型生成内容(如修正代码、调整回复)。 | 强烈信号表明原始输出存在问题,同时构成偏好数据(<查询、胜出响应、失败响应>),可用于模型对齐。 |
| 抱怨(Complaints) | 吐槽输出错误、无关、有毒、冗长、缺乏细节等(如 FITS 数据集聚类的 8 类常见抱怨)。 | 可直接指导优化方向(如用户嫌冗长则调整提示词使其更简洁)。 |
| 情感表达(Sentiment) | 用 “Uggh” 等词汇表达负面情绪,或通话中音量升高;从愤怒到满意的情绪变化。 | 情感变化反映对话效果(如情绪好转可能意味着问题解决)。 |
| 模型拒绝响应(Model refusal rate) | 模型频繁回复 “抱歉,我不知道”“作为语言模型,我无法…” 等。 | 可能导致用户不满,需关注拒绝原因并优化。 |
2.1.2 Other conversational feedback(其他对话反馈)
1. 再生响应(Regeneration):用户通过应用生成新响应(可能使用不同模型)的行为。
- 解读:可能暗示对首次响应不满,但也可能是用户希望对比选项(尤其在创意场景,如生成图片或故事时)。
- 信号强度与计费模式相关:按使用量计费的应用中,用户再生响应的成本更高,因此该行为更可能反映真实不满(而非出于好奇);订阅制应用中信号较弱。
- 特殊场景:用户可能为复杂请求再生响应以验证一致性(若两次响应矛盾,则可信度低)。
- 衍生价值:部分应用在再生后会让用户对比新旧响应(如下图),此类 “优劣判断” 数据可用于偏好微调。

2. 对话组织行为(Conversation organization):①删除对话:强烈暗示对话质量差,除非是用户因隐私原因删除(如尴尬内容)。②重命名对话:可能表明对话有价值,但自动生成的标题不佳。③分享、收藏对话:需结合场景判断(可能是正向推荐,也可能是分享错误案例)。
3. 对话长度(Conversation length)
- 解读依赖应用场景:①正向信号:AI 陪伴类应用中,长对话可能表明用户享受互动。②负向信号: 生产类应用(如客户支持)中,长对话可能暗示机器人效率低,未快速解决问题。
4. 对话多样性(Dialogue diversity):通过不同 token 或主题数量衡量。
- 解读:长对话若伴随低多样性(如机器人重复内容),可能表明用户陷入循环,体验差。
5. 显性反馈 vs 隐性反馈
| 反馈类型 | 特点 | 挑战 |
|---|---|---|
| 显性反馈 | 易解读,但需用户额外付出精力。 | 数据稀疏(小用户群更明显),存在响应偏差(不满用户更可能抱怨,导致反馈偏负面)。 |
| 隐性反馈 | 数据丰富(受想象力限制),源自用户自然行为。 | 噪声大、解读难(如分享对话可能是正向也可能是负向),需深入研究用户行为动机。 |
6. 隐性反馈的优化方向:结合多信号交叉验证(如用户分享对话后重述问题,可能暗示对话未达预期)。
2.2 Feedback Design(反馈机制设计)
2.2.1 When to collect feedback(何时收集反馈)
- 用户旅程全程,如初期(校准应用)、出现问题时(如模型幻觉)、模型低置信度时(如让用户选择偏好响应)。
1. 反馈收集时间的基本原则
- 全程性:应在用户旅程的各个阶段收集反馈,确保用户有机会随时反馈(尤其是报告错误)。
- 非侵入性:反馈收集入口不应干扰用户流程,避免破坏体验。
2. 关键反馈收集场景
1)用户初期使用阶段(In the beginning)
- 作用:帮助应用校准用户需求(类似面部识别 APP 扫描面部、语音助手采集唤醒词声音)。
- 注意事项:必要校准(如核心功能依赖的用户数据)可强制,非必要校准应设为可选(避免增加用户试用门槛)。若用户未提供偏好,可默认中性选项,后续通过行为逐步校准。
2)出现问题时(When something bad happens)
- 触发场景:模型幻觉、误拦截合法请求、生成不当内容(如有害图像)、响应延迟过高等。
- 反馈方式:允许用户通过差评、重新生成响应、切换模型等方式反馈;或通过自然语言表达不满(如 “你错了”“太冗长”)。
- 体验保障:确保用户在问题发生时仍能完成任务,例如允许用户直接编辑错误(如修改产品分类错误);转人工处理(如客服机器人对话超时或用户愤怒时转人工)。
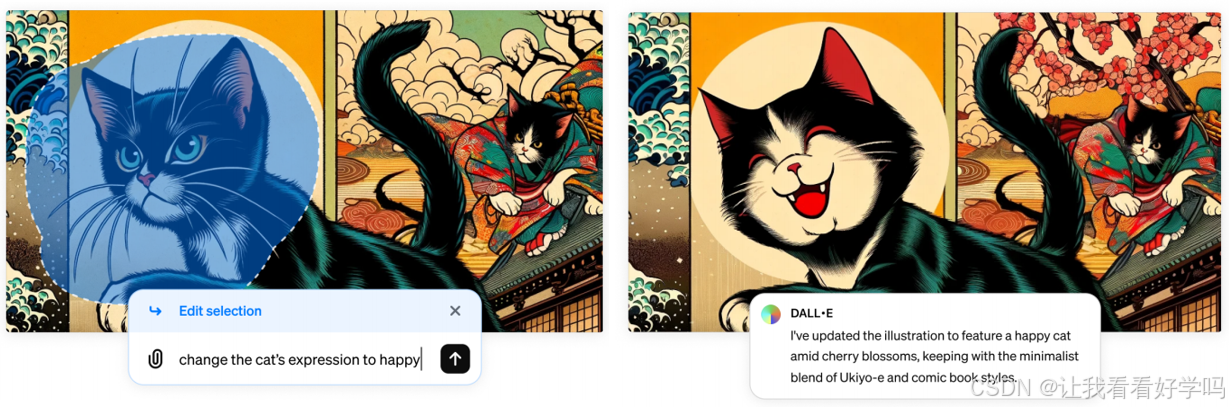
- 示例(下图):DALL-E 的 “inpainting” 功能(用户可选中图像区域并描述修改需求),既提升体验,又为开发者提供高质量反馈。
3)模型低置信度时(When the model has low confidence)
- 作用:通过用户反馈提升模型确定性,例如模型不确定用户偏好 “简短摘要” 还是 “详细摘要” 时,生成两种版本供用户选择,结果可用于偏好微调。
- 展示方式:完整展示(如 ChatGPT 显示两个完整响应让用户对比);部分展示(如 Google Gemini 只显示响应开头,用户点击展开后选择,减少用户阅读负担)。

- 示例:Google Photos 不确定两张照片是否为同一人时,主动询问用户确认。
3. 关于 “正面反馈” 的争议与处理:对正面反馈需权衡 “用户体验” 与 “功能优化需求”,通过非侵入性方式(如控制频率)平衡收集。
- 控制频率:通过限制反馈请求的展示范围(如仅向 1% 用户推送),减少对体验的干扰。
- 注意偏差:小比例用户反馈可能存在偏差,但大用户基数下仍可提供有意义的产品洞察。
2.2.2 How to collect feedback(如何收集反馈)
1. 反馈收集的核心原则
- 无缝融入流程:反馈机制需自然嵌入用户工作流,让用户轻松提供反馈(无需额外负担),且不干扰体验,同时易于忽略。
- 激励性:需设计机制激励用户提供高质量反馈。
2. 有效反馈收集的实例参考
1)隐性反馈的自然收集(通过用户行为)
- Midjourney(下图):生成 4 张图像后,提供 “放大某张”“生成某张的变体”“重新生成” 选项,通过用户选择传递反馈:“放大”= 强正向信号;“生成变体”= 弱正向信号;“重新生成”= 对当前结果不满(但可能仅是想多要选项,尤其创意场景)。

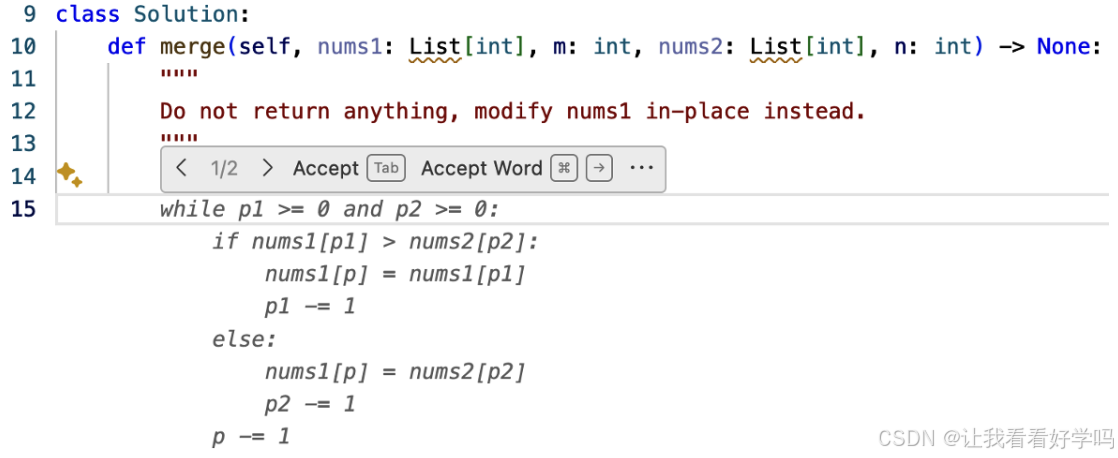
- GitHub Copilot:以浅色显示代码草稿,用户按 Tab 接受或继续输入忽略,通过操作自然传递反馈。
2)集成产品 vs 独立产品的反馈差异
- 集成产品(如 Gmail、GitHub Copilot):更易收集高质量反馈,因可追踪反馈后的用户行为(如 Gmail 可追踪邮件草稿的使用 / 编辑情况)。
- 独立 AI 产品(如 ChatGPT、Claude):难追踪反馈后的实际使用(如 ChatGPT 生成邮件后,无法知道是否被发送),反馈质量受限。
3. 反馈的上下文与隐私处理
- 上下文的重要性:仅靠 “点赞 / 差评” 等反馈对深度分析不足,需结合前 5-10 轮对话等上下文才能定位问题,但上下文可能含个人信息(PII)。
- 获取方式:①服务条款中明确允许使用用户数据用于分析和改进。②数据捐赠流程:用户提交反馈时,询问是否分享近期交互数据作为上下文(如勾选框确认)。
4. 激励用户与确保反馈有效性
- 明确反馈用途:向用户说明反馈的使用场景(如用于个性化体验、统计分析、训练新模型),增强用户配合度;若用户关注隐私,需如实承诺数据用途(如 “不用于模型训练”“数据不离开设备”)。
- 避免不合理要求:不强迫用户做无法完成的选择,例如:对用户不懂的领域(如复杂统计问题),不应让其在两个选项中选 “偏好”,需提供 “我不知道” 等中性选项。
5. 设计细节:避免模糊与错误
- 辅助理解:通过图标、工具提示(tooltips)解释选项含义,减少用户困惑。
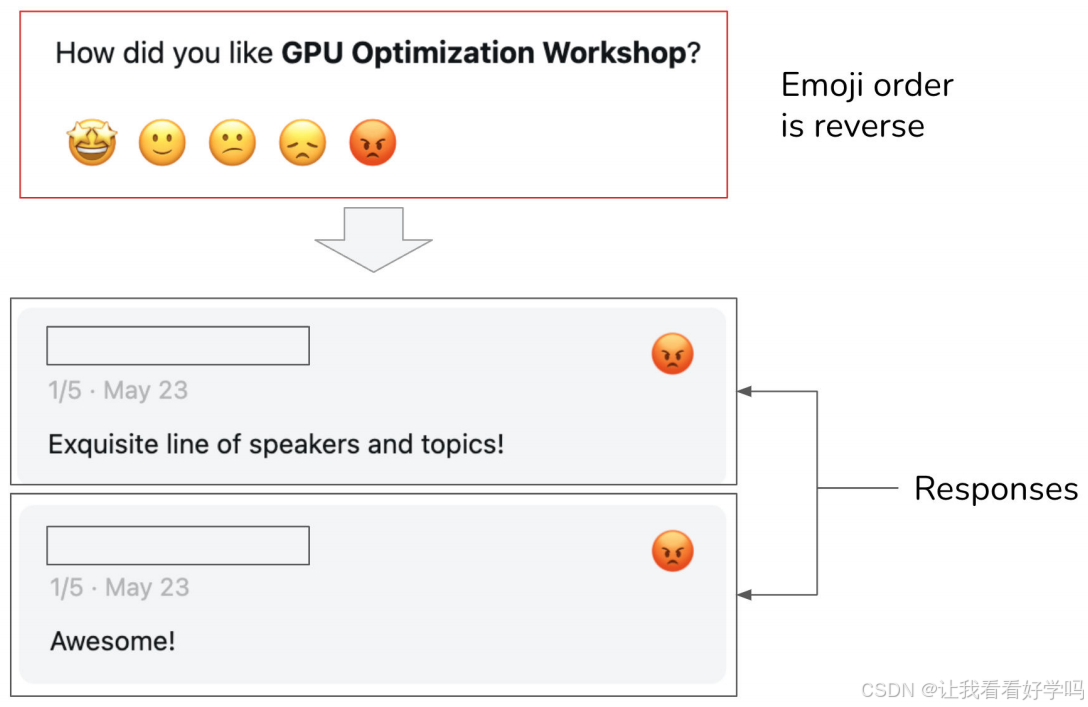
- 防止歧义:模糊的设计会导致反馈噪声,例如:Luma 的反馈表单中,代表 1 星的 “愤怒 emoji” 被误放在 5 星位置,导致用户本想给好评却误选 1 星。
6. 反馈的公私属性权衡
| 反馈属性 | 优势 | 劣势 |
|---|---|---|
| 私人反馈 | 用户更坦诚(例如:将 “点赞” 设为私密后,点赞量显著上升) | 可能降低内容的可发现性(如其他用户看不到热门内容)和可解释性(如推荐逻辑因缺乏公开信号更难理解) |
| 公共反馈 | 可展示给其他用户(如 “热门内容”),增强社区互动 | 用户可能因顾虑评价而隐瞒真实想法,反馈真实性下降 |
2.3 Feedback Limitations(反馈的局限性)
2.3.1 Biases(偏差)
用户反馈和其他数据一样存在偏差,需主动识别并针对性设计反馈系统,避免因误读偏差导致错误的产品决策。
1. 常见反馈偏差及应对
1)宽容偏差(Leniency bias):用户倾向于给出偏高评价(如为避免冲突、减少麻烦,即使不满也给高分)。
- 示例:五星评分中,用户可能因 “打低分需填写理由” 而默认给高分;Uber 司机平均评分达 4.8,低于 4.6 才可能被停用。未必完全失效(如 Uber 仍能通过评分区分司机优劣),但需关注评分分布以识别偏差。
- 应对:减少低评分的负面暗示,用描述性选项替代数字(如 “很棒的行程”“可以更好”“不想再匹配该司机”),鼓励更细致的反馈。
2)随机性偏差(Randomness):用户因缺乏动力提供随意反馈,非恶意但无实际意义。比如对比两个长响应时,用户未通读就随机选择;Midjourney 中随机选择某张图片生成变体。
3)位置偏差(Position bias):选项展示位置影响用户选择,通常更倾向于点击第一个选项(未必因内容优质)。
- 应对:随机调整选项位置,减少固定位置的影响;训练模型根据位置计算选项的真实成功率,修正偏差。
4)偏好偏差(Preference bias):用户因固有偏好产生的偏差,例如:对比时更青睐较长的响应(长度比准确性更易感知);近因偏差(更偏好最后看到的答案)。
2. 应对偏差的核心原则:需主动检查用户反馈,挖掘潜在偏差(如分析评分分布、用户选择模式)。
- 理解偏差本质是正确解读反馈的前提,确保基于反馈的产品决策不被误导。
2.3.2 Degenerate feedback loop(退化反馈循环)
1. 定义:当模型预测结果本身影响用户反馈,而反馈又反过来强化模型的初始偏差,形成不断放大偏差的循环。
- 核心问题:用户反馈仅基于 “展示给他们的内容”,而非全部可能性,导致反馈的片面性被持续放大。
2. 退化反馈循环的典型案例与影响
1)推荐系统中的偏差放大:例如视频推荐中,排名靠前的视频因曝光率高获得更多点击,系统据此进一步提升其排名,即使初始差异很小(如视频 A 略高于 B),最终 A 会远超 B,形成 “热门内容恒热门” 的局面,新内容难以突围。
- 关联概念:这类问题被称为 “曝光偏差(exposure bias)”“流行度偏差(popularity bias)” 或 “过滤气泡(filter bubbles)”,是研究成熟的经典问题。
2)产品定位的偏移:若少数用户反馈喜欢猫咪照片,系统会生成更多猫咪内容,吸引更多猫爱好者,进而催生更多正面反馈,最终导致应用沦为 “猫咪专属平台”。
- 风险延伸:同理,该机制可能放大种族主义、性别歧视、对低俗内容的偏好等有害偏差。
3)模型的 “迎合性” 扭曲:基于用户反馈训练的模型可能为满足用户预期而牺牲准确性,甚至 “说谎”。
3. 应对原则:用户反馈对提升体验至关重要,但要避免不加辨别地使用,需评估反馈可能带来的潜在影响,防止偏差持续累积破坏产品核心价值。