DolphinScheduler 如何高效调度 AnalyticDB on Spark 作业?
DolphinScheduler是一个分布式易扩展的可视化DAG工作流任务调度开源系统,能高效地执行和管理大数据流程。用户可以在DolphinScheduler Web界面轻松创建、编辑和调度云原生数据仓库 AnalyticDB MySQL 版的Spark作业。
前提条件
-
AnalyticDB for MySQL集群的产品系列为企业版、基础版或湖仓版。
-
AnalyticDB for MySQL集群中已创建Job型资源组或Spark引擎的Interactive型资源组。
-
已安装JDK,且JDK的版本为1.8及以上版本。
-
已安装DolphinScheduler。
-
已将运行DolphinScheduler的服务器IP地址添加至AnalyticDB for MySQL集群的白名单中。
调度Spark SQL作业
AnalyticDB for MySQL支持使用批处理和交互式两种方法执行Spark SQL。选择的执行方式不同,调度的操作步骤也有所不同。详细步骤如下:
批处理
- 安装Spark-Submit命令行工具并配置相关参数。
说明:您只需要配置keyId、secretId、regionId、clusterId和rgName这些必填参数。
-
创建项目。
-
访问DolphinScheduler Web界面,在顶部导航栏单击项目管理。
-
单击创建项目。
-
在弹出的创建项目对话框中配置项目名称、所属用户等参数。
-
-
创建工作流。
-
单击已创建的项目名称,进入工作流定义页面。
-
单击创建工作流,进入工作流DAG编辑页面。
-
在页面左侧选择SHELL,并将其拖拽到右侧空白画布中。
-
在弹出的当前节点设置对话框中配置如下参数:

-
单击确认。
-
单击页面右上角保存,在弹出的基本信息对话框中配置工作流名称等参数,单击确定。
-
说明:其他参数说明请参见DolphinScheduler任务参数。
- 运行工作流。
-
单击工作流操作列的
 按钮,上线工作流。
按钮,上线工作流。 -
单击工作流操作列的
 按钮。
按钮。 -
在弹出的启动前请先设置参数对话框中,配置对应参数。
-
单击确定,运行工作流。
- 查看工作流详细信息。
-
在左侧导航栏单击任务实例。
-
在操作列,单击
 按钮,查看工作流执行结果和日志信息。
按钮,查看工作流执行结果和日志信息。
交互式
-
获取Spark Interactive型资源组的连接地址。
-
登录云原生数据仓库AnalyticDB MySQL控制台,在左上角选择集群所在地域。在左侧导航栏,单击集群列表,在企业版、基础版或湖仓版页签下,单击目标集群ID。
-
在左侧导航栏,单击集群管理 > 资源管理,单击资源组管理页签。
-
单击对应资源组操作列的详情,查看内网连接地址和公网连接地址。您可单击端口号括号内的image按钮,复制连接地址。
以下两种情况,您需要单击公网地址后的申请网络,手动申请公网连接地址。
-
提交Spark SQL作业的客户端工具部署在本地。
-
提交Spark SQL作业的客户端工具部署在ECS上,且ECS与AnalyticDB for MySQL不属于同一VPC。
-
-
创建数据源。
-
访问DolphinScheduler Web界面,在顶部导航栏单击数据源中心。
-
单击创建数据源,选择数据源类型为Spark。
-
在弹出的创建数据源对话框中配置如下参数:
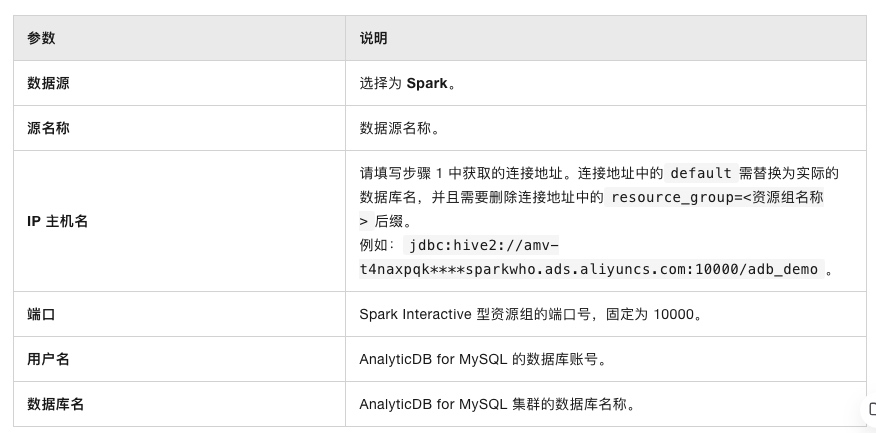
-
单击测试连接,测试成功后,单击确定。
-
说明:其他参数为选填参数,详情请参见MySQL数据源。
-
创建项目。
-
访问DolphinScheduler Web界面,在顶部导航栏单击项目管理。
-
单击创建项目。
-
在弹出的创建项目对话框中配置项目名称、所属用户等参数。
-
-
创建工作流。
-
单击已创建的项目名称,进入工作流定义页面。
-
单击创建工作流,进入工作流DAG编辑页面。
-
在页面左侧选择SQL,并将其拖拽到右侧空白画布中。
-
在弹出的当前节点设置对话框中配置如下参数:
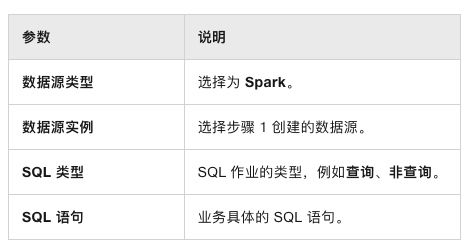
-
单击确认。
-
单击页面右上角保存,在弹出的基本信息对话框中配置工作流名称等参数,单击确定。
-
-
运行工作流。
-
单击工作流操作列的
 按钮,上线工作流。
按钮,上线工作流。 -
单击工作流操作列的
按钮。 -
在弹出的启动前请先设置参数对话框中,配置对应参数。
-
单击确定,运行工作流。
-
-
查看工作流详细信息。
-
在左侧导航栏单击任务实例。
-
在操作列,单击
 按钮,查看工作流执行结果和日志信息。
按钮,查看工作流执行结果和日志信息。
-
调度Spark Jar作业
- 安装Spark-Submit命令行工具并配置相关参数。
说明:您只需要配置keyId、secretId、regionId、clusterId和rgName这些必填参数。如果您的Spark Jar包在本地,还需要配置ossUploadPath等OSS相关参数。
-
创建项目。
-
访问DolphinScheduler Web界面,在顶部导航栏单击项目管理。
-
单击创建项目。
-
在弹出的创建项目对话框中配置项目名称、所属用户等参数。
-
-
创建工作流。
-
单击已创建的项目名称,进入工作流定义页面。
-
单击创建工作流,进入工作流DAG编辑页面。
-
在页面左侧选择SHELL,并将其拖拽到右侧空白画布中。
-
在弹出的当前节点设置对话框中配置如下参数:

-
单击确认。
-
单击页面右上角保存,在弹出的基本信息对话框中配置工作流名称等参数,单击确定。
-
说明:其他参数说明请参见DolphinScheduler任务参数。
-
运行工作流。
-
单击工作流操作列的
按钮,上线工作流。 -
单击工作流操作列的
按钮。 -
在弹出的启动前请先设置参数对话框中,配置对应参数。
-
单击确定,运行工作流。
-
-
查看工作流详细信息。
-
在左侧导航栏单击任务实例。
-
在操作列,单击
按钮,查看工作流执行结果和日志信息。
-