GitHub开源轻量级语音模型 Vui:重塑边缘智能语音交互的未来
前言
今天将深入解析一款颠覆性开源语音模型——Vui(来自 Fluxions-AI 项目)。它正以“轻量化”为矛,刺破传统语音模型高耗能的壁垒,让智能语音无处不在。
- GitHub:https://github.com/fluxions-ai/vui
- huggingface:https://huggingface.co/spaces/fluxions/vui-space
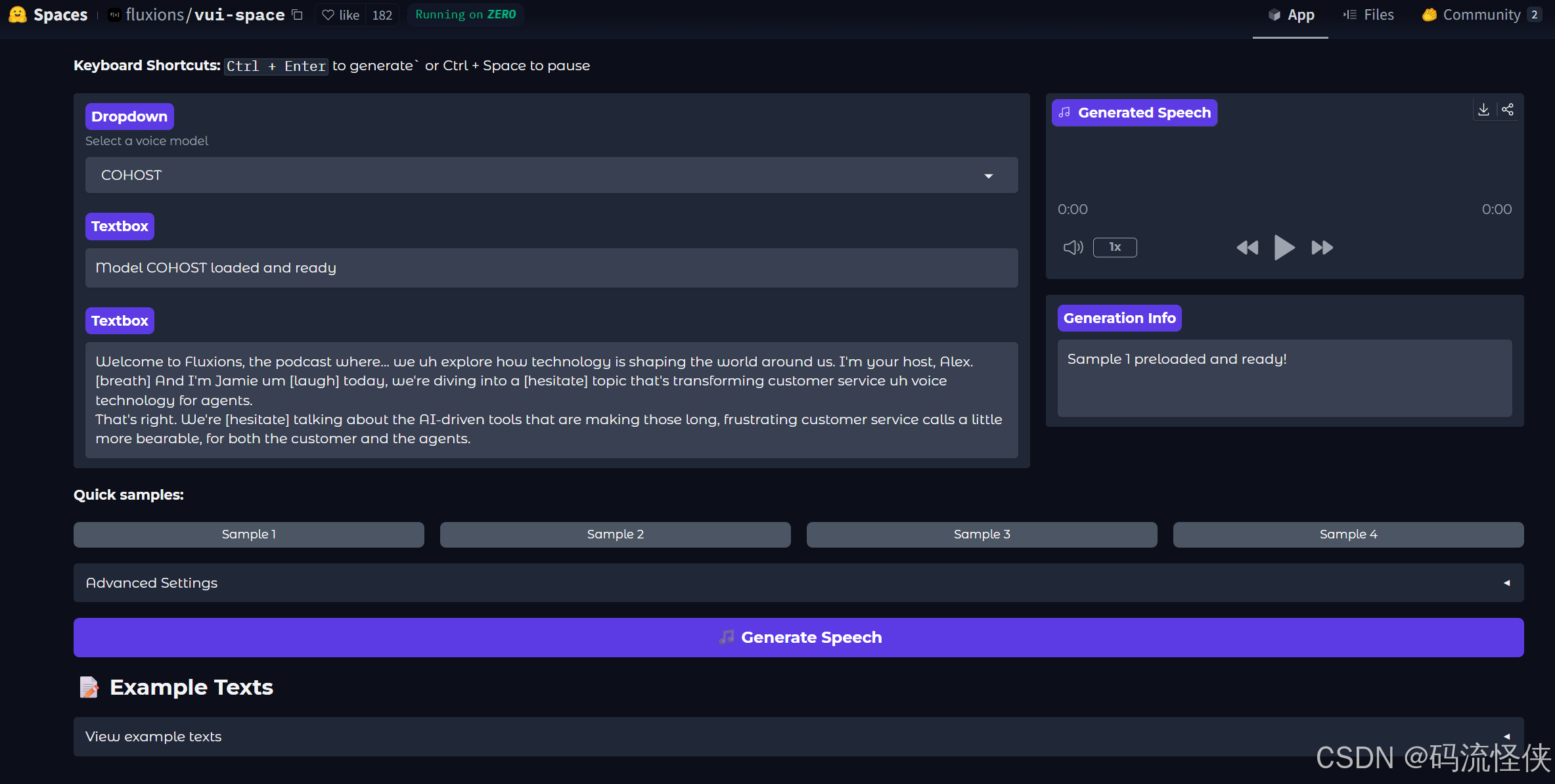
1️⃣、为何需要轻量级语音模型?
随着智能终端(IoT设备、车载系统、穿戴设备)的普及,传统语音模型面临两大瓶颈:
- 计算资源限制:云端推理依赖网络,延迟高且隐私风险大。
- 高能耗与存储压力:如百参数级模型在移动端部署困难。
Vui 应运而生,通过算法优化实现超低参数量(通常<1MB)与毫秒级实时响应,成为边缘语音交互的核心引擎。
2️⃣、Vui 的核心技术架构
-
高效声学建模
- 深度可分离卷积:替代标准卷积,减少90%计算量(参考MobileNet设计)。
- 分组循环网络:如GTCRN采用分组时间卷积,仅需23.7K参数实现语音降噪。
- 频谱压缩技术:对高频信息动态压缩,降低计算复杂度。
-
自适应语音处理
- 多频段联合优化:全频带处理避免传统分频段信息损失。
- 端到端流式处理:支持连续语音输入,RTF(实时因子)低至0.07(中端CPU)。
-
极简部署方案
- 量化与剪枝:8-bit量化使模型体积缩小4倍。
- 无依赖运行时:如TensorVox仅需DLL文件,脱离Python环境运行。
3️⃣、使用教程
-
安装
在运行demo.py之前,您必须在 Hugging Face 上接受语音活动检测和分割的模型条款。 -
Linux 系统
uv pip install -e . -
Windows 系统
创建并激活虚拟环境uv venv .venv\Scripts\activate安装依赖
uv pip install -e . uv pip install triton_windows -
演示
在 Gradio 上尝试python demo.py
4️⃣、Vui 的典型应用场景
| 场景 | 案例 | 技术优势 |
|---|---|---|
| 智能家居 | 语音控制家电(离线指令识别) | 隐私保护,响应延迟<200ms |
| 工业降噪 | GTCRN模型在机械噪声中提取人声,精度提升40% | 23.7K参数,39.6MMACs/秒运算量 |
| 多语言合成 | Kokoro-TTS支持英/德/西语,生成耳语等特殊风格 | 8200万参数,实时生成 |
| 医疗辅助 | 低功耗助听器实时增强语音,功耗降低60% | 全频带处理,0.89M参数 |
5️⃣、关键技术挑战与解决方案
- 精度-效率平衡
- 方案:多头注意力机制替代RNN,捕获长距离依赖(如Vui-Transformer)。
- 多方言适配
- 方案:IPA音素集兼容方言音素,支持自定义训练(如TensorVox)。
- 资源极端受限环境
- 方案:神经架构搜索(NAS)自动生成最优轻量结构。
6️⃣、开源生态与工具链
- 训练框架:MXNet(高效分布式训练)、PyTorch Mobile。
- 部署工具:ONNX Runtime(跨平台推理)、TensorRT加速。
- 知名开源项目:
- Vosk:离线支持16种语言,中文识别准确率>92%。
- GTCRN:开源语音增强模型,提供流式处理Demo。
- TensorVox:桌面级TTS应用,C++/Qt实现。
7️⃣、未来演进方向
- 多模态融合:结合唇动识别提升噪声场景鲁棒性。
- 自监督学习:减少标注数据依赖(如HuBERT轻量化变体)。
- 脑机接口延伸:EEG信号与语音合成联合建模。
结语
Vui 代表的轻量级语音技术正推动AI向“无处不在”迈进。其在隐私保护、实时性、能耗控制上的突破,使其成为端侧智能的核心基础设施。未来,随着神经拟态芯片与算法-硬件协同设计的发展,Vui 类模型将解锁更多颠覆性应用场景。