论文略读:Can LLMs Solve Longer Math Word Problems Better?
ICLR 2025 3556
数学文字题(Math Word Problems, MWPs)在评估大语言模型(LLMs)推理能力中起着关键作用,然而当前研究主要聚焦于背景简洁的题目,而长上下文对数学推理的影响仍缺乏系统探索。
本研究首次提出并系统性研究了上下文长度泛化能力(Context Length Generalizability,CoLeG)——即模型在面对冗长叙述下仍能解决数学问题的能力。
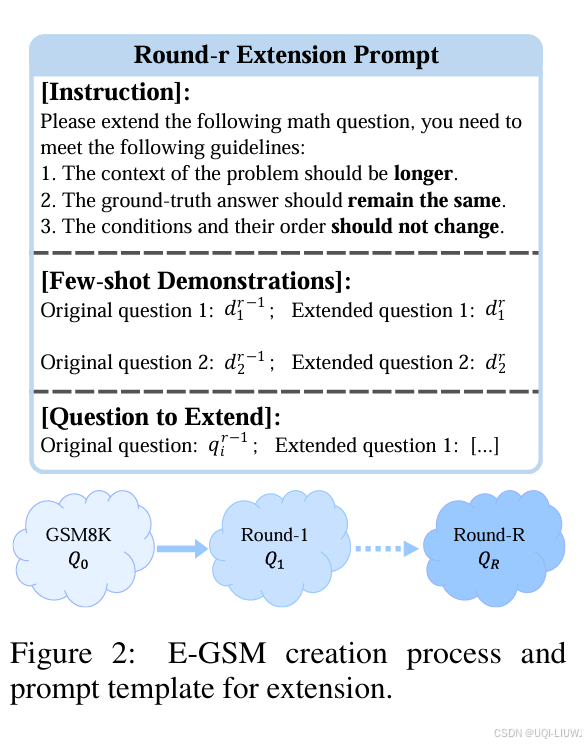
我们构建了一个新的数据集:扩展版小学数学题(Extended Grade-School Math, E-GSM),该数据集包含了带有冗长叙述背景的数学文字题。同时,我们提出了两个新的评估指标,用于衡量LLMs在应对这类问题时的有效性与鲁棒性。
我们使用主流的零样本提示(zero-shot prompting)方法,对比了闭源LLMs与开源LLMs在E-GSM任务上的表现,结果显示它们普遍存在CoLeG 能力不足的问题。
为缓解这一问题,我们针对不同类型的模型提出了相应的策略:
-
对于闭源LLMs,我们设计了一种新的指令提示模板,以减轻长上下文对推理能力的干扰;
-
对于开源LLMs,我们提出了一种用于微调的辅助任务,以增强其CoLeG能力。
我们的大量实验证明,所提出的方法显著提升了模型在E-GSM数据集上的表现。此外,我们还深入分析了改进效果是来自语义理解能力还是推理能力本身,结果显示我们的策略主要提升了推理能力。
我们进一步验证了该方法在多个其他数学文字题基准数据集上的可泛化性,表明其具有广泛实用价值。
综上,本研究揭示了当前LLMs在处理长上下文数学问题方面的局限性,并提出了具有实用性的方法解决方案,为未来在模型泛化能力与训练机制研究方面提供了新方向。