LeetCode第 454 场周赛题解
题目地址
https://leetcode.cn/contest/weekly-contest-454/
锐评
参赛人数不足2k,跟巅峰时期没法比。随着AI加入,感觉会越来越多人弃坑。
题目难度适中。每一题基本上思路还算明显,就是细节上可能有些小坑,看榜上一片WA。可惜了第四题,思路是对的,赛时一直没调出来,错在了两个点,一是树节点深度跟距离用混了,二是倍增时,右侧方向枚举反了。
题解
Q1. 为视频标题生成标签
题意
给你一个字符串 caption,表示一个视频的标题。
需要按照以下步骤 按顺序 生成一个视频的 有效标签 :
-
将 所有单词 组合为单个 驼峰命名字符串 ,并在前面加上 ‘#’。驼峰命名字符串 指的是除第一个单词外,其余单词的首字母大写,且每个单词的首字母之后的字符必须是小写。
-
移除 所有不是英文字母的字符,但 保留 第一个字符 ‘#’。
-
将结果 截断 为最多 100 个字符。
对 caption 执行上述操作后,返回生成的 标签 。
示例
示例1
输入: caption = "Leetcode daily streak achieved"
输出: "#leetcodeDailyStreakAchieved"
说明
除了 “leetcode” 以外的所有单词的首字母需要大写。
示例2
输入: caption = "can I Go There"
输出: "#canIGoThere"
说明
除了 “can” 以外的所有单词的首字母需要大写。
示例3
输入: caption = "hhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhh"
输出: "#hhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhh"
说明
由于第一个单词长度为 101,因此需要从单词末尾截去最后两个字符。
提示
- 1 < = c a p t i o n . l e n g t h < = 150 1 <= caption.length <= 150 1<=caption.length<=150
- caption 仅由英文字母和 ’ ’ 组成。
解题思路:模拟
简单题。按照题意模拟即可,时间复杂度为 O ( n ) O(n) O(n)。
PS:可能会有空字符串,需要注意下。幸好我的解法不需要考虑这种case。赛时差点切Java,好在最后没有,不然可能WA一发。逃)
参考代码(C++)
class Solution {
public:string generateTag(string caption) {string ans;ans.push_back('#');bool f = false;int n = caption.size();for (int i = 0; i < n; ++i)if (isalpha(caption[i])) {if (!f)ans.push_back(tolower(caption[i]));else {if (i - 1 >= 0 && !isalpha(caption[i - 1]))ans.push_back(toupper(caption[i]));elseans.push_back(tolower(caption[i]));}f = true;}return ans.substr(0, min(int(ans.size()), 100));}
};
Q2. 统计特殊三元组
题意
给你一个整数数组 nums。
特殊三元组 定义为满足以下条件的下标三元组 (i, j, k):
- 0 <= i < j < k < n,其中 n = nums.length
- nums[i] == nums[j] * 2
- nums[k] == nums[j] * 2
返回数组中 特殊三元组 的总数。
由于答案可能非常大,请返回结果对 10 9 + 7 10^9 + 7 109+7 取余数后的值。
示例
示例1
输入: nums = [6,3,6]
输出: 1
说明
唯一的特殊三元组是 (i, j, k) = (0, 1, 2),其中:
- nums[0] = 6, nums[1] = 3, nums[2] = 6
- nums[0] = nums[1] * 2 = 3 * 2 = 6
- nums[2] = nums[1] * 2 = 3 * 2 = 6
示例2
输入: nums = [0,1,0,0]
输出: 1
说明
唯一的特殊三元组是 (i, j, k) = (0, 2, 3),其中:
- nums[0] = 0, nums[2] = 0, nums[3] = 0
- nums[0] = nums[2] * 2 = 0 * 2 = 0
- nums[3] = nums[2] * 2 = 0 * 2 = 0
示例3
输入: nums = [8,4,2,8,4]
输出: 2
说明
共有两个特殊三元组:
- (i, j, k) = (0, 1, 3)
- nums[0] = 8, nums[1] = 4, nums[3] = 8
- nums[0] = nums[1] * 2 = 4 * 2 = 8
- nums[3] = nums[1] * 2 = 4 * 2 = 8
- (i, j, k) = (1, 2, 4)
- nums[1] = 4, nums[2] = 2, nums[4] = 4
- nums[1] = nums[2] * 2 = 2 * 2 = 4
- nums[4] = nums[2] * 2 = 2 * 2 = 4
提示
- 3 < = n = = n u m s . l e n g t h < = 10 5 3 <= n == nums.length <= 10^5 3<=n==nums.length<=105
- 0 < = n u m s [ i ] < = 10 5 0 <= nums[i] <= 10^5 0<=nums[i]<=105
解题思路:计数+前后缀分解
中等题。根据题目中的式子,很明显,我们可以枚举中间的位置,然后计算出它前面和后面满足条件的数的个数,根据 乘法原理 将二者乘起来计入答案即可,时间复杂度为 O ( n ) O(n) O(n)。
参考代码(C++)
class Solution {const int mod = 1'000'000'007;
public:int specialTriplets(vector<int>& nums) {unordered_map<int, int> prec, sufc;for (int& x : nums)++sufc[x];int ans = 0;for (int& x : nums) {--sufc[x];int y = x << 1;if (prec.count(y) && sufc.count(y)) {ans += 1LL * prec[y] * sufc[y] % mod;ans %= mod;}++prec[x];}return ans;}
};
Q3. 子序列首尾元素的最大乘积
题意
给你一个整数数组 nums 和一个整数 m。
返回任意大小为 m 的 子序列 中首尾元素乘积的最大值。
子序列 是可以通过删除原数组中的一些元素(或不删除任何元素),且不改变剩余元素顺序而得到的数组。
示例
示例1
输入: nums = [-1,-9,2,3,-2,-3,1], m = 1
输出: 81
说明
子序列 [-9] 的首尾元素乘积最大:-9 * -9 = 81。因此,答案是 81。
示例2
输入: nums = [1,3,-5,5,6,-4], m = 3
输出: 20
说明
子序列 [-5, 6, -4] 的首尾元素乘积最大。
示例3
输入: nums = [2,-1,2,-6,5,2,-5,7], m = 2
输出: 35
说明
子序列 [5, 7] 的首尾元素乘积最大。
提示
- 1 < = n u m s . l e n g t h < = 10 5 1 <= nums.length <= 10^5 1<=nums.length<=105
- − 10 5 < = n u m s [ i ] < = 10 5 -10^5 <= nums[i] <= 10^5 −105<=nums[i]<=105
- 1 < = m < = n u m s . l e n g t h 1 <= m <= nums.length 1<=m<=nums.length
解题思路:线段树/滑动窗口
中等题。根据题意,既然是首尾,那么我们可以枚举首/尾,然后去找尾/首。因为子序列长度要为 m,题目又没要求所有的子序列,因此只要满足条件即可。
显然,第一个满足条件的位置要基于当前位置滑动 m - 1 个位置,这时恰好有 m 个元素。进而基于当前位置滑动 m 个以上位置的地方仍然可作为首/尾,因为此时该区间元素个数已经大于 m 了,固定首尾,中间随便选择 m - 2 个位置即可。
那么答案怎么来呢?题目要求乘积最大,而根据提示数据有正有负,对于我们枚举的这个首/尾,怎么样才可能有最大值呢?显然,要么乘以一个最大值,要么乘以一个最小值。
根据上面的分析,那么问题就转化为:对于每个位置,求符合条件的某个位置区间的最大最小值。这个问题解法有很多,例如 ST表/线段树 等。赛时,为了快速A掉,直接上了线段树,时间复杂度为 O ( n l o g n ) O(nlogn) O(nlogn)。
但其实你会发现这题区间是随着枚举位置的移动只会变大的,每移动一个位置,区间边界扩大一。因此,完全没必要用 线段树 。直接用一个 有序集合 就可以了,不断扩张该集合,每次取一下最大最小值更新答案,时间复杂度为 O ( n l o g n ) O(nlogn) O(nlogn)。
再仔细想一下,你会发现 有序集合 也是多余的,我只需要知道当前满足条件的区间最大最小值是多少即可,因此,每扩展一个区间端点,更新一下当前区间最大最小值,时间复杂度为 O ( n ) O(n) O(n)。
参考代码(C++)
线段树版本
using ll = long long;
const int maxn = 100'005;
const ll inf = 0x3f3f3f3f3f3f3f3fLL;
const ll mod = inf;
const ll maxvi = -inf;
const ll minvi = inf;
const ll setvi = -1;
const ll addvi = 0;
const ll revvi = 0;
struct seg_info {ll sumv, maxv, minv;seg_info() {sumv = 0;maxv = maxvi;minv = minvi;}seg_info(ll sumv, ll maxv, ll minv): sumv(sumv), maxv(maxv), minv(minv) {}seg_info operator + (const seg_info& p) const {seg_info ans;ans.sumv = (sumv + p.sumv) % mod;ans.maxv = max(maxv, p.maxv);ans.minv = min(minv, p.minv);return ans;}seg_info& operator += (const seg_info& p) {sumv = (sumv + p.sumv) % mod;maxv = max(maxv, p.maxv);minv = min(minv, p.minv);return *this;}
};struct seg_node_info {seg_info si;ll setv, addv, revv;seg_node_info() {si = seg_info();}void set(int l, int r, ll val) {setv = val;si.sumv = val % mod * (r - l + 1) % mod;si.maxv = val;si.minv = val;}void add(int l, int r, ll val) {addv = (addv + val % mod) % mod;si.sumv = (si.sumv + val % mod * (r - l + 1) % mod) % mod;si.maxv = (si.maxv == maxvi) ? val : (si.maxv + val);si.minv = (si.minv == minvi) ? val : (si.minv + val);}void rev(int l, int r, ll val) {revv ^= val;si.sumv = (r - l + 1) - si.sumv;si.maxv = (si.maxv == maxvi) ? val : (si.maxv ^ val);si.minv = (si.minv == minvi) ? val : (si.minv ^ val);}
};struct segment_tree {#ifndef SEG_SET#define SEG_SET#endif
// #ifndef SEG_ADD
// #define SEG_ADD
// #endif
// #ifndef SEG_REV
// #define SEG_REV
// #endif#define lrt rt << 1#define rrt rt << 1 | 1#define lson l, mid, lrt#define rson mid + 1, r, rrt#define op_set 0#define op_add 1#define op_rev 2seg_node_info sni[maxn << 2];void push_up(int rt) {sni[rt].si = sni[lrt].si + sni[rrt].si;}void build(int l, int r, int rt) {sni[rt] = seg_node_info();#ifdef SEG_SETsni[rt].setv = setvi;#endif#ifdef SEG_ADDsni[rt].addv = addvi;#endif#ifdef SEG_REVsni[rt].revv = revvi;#endifif (l == r)return;int mid = (l + r) >> 1;build(lson);build(rson);push_up(rt);}void push_down(int l, int r, int rt) {int mid = (l + r) >> 1;#ifdef SEG_SETif (sni[rt].setv != setvi) {sni[lrt].set(l, mid, sni[rt].setv);sni[rrt].set(mid + 1, r, sni[rt].setv);sni[lrt].addv = addvi;sni[rrt].addv = addvi;sni[rt].setv = setvi;}#endif#ifdef SEG_ADDif (sni[rt].addv != addvi) {sni[lrt].add(l, mid, sni[rt].addv);sni[rrt].add(mid + 1, r, sni[rt].addv);sni[rt].addv = addvi;}#endif#ifdef SEG_REVif (sni[rt].revv != revvi) {sni[lrt].rev(l, mid, sni[rt].revv);sni[rrt].rev(mid + 1, r, sni[rt].revv);sni[rt].revv = revvi;}#endif}void update(int op, int cl, int cr, ll val, int l, int r, int rt) {if (cl <= l && r <= cr) {if (op == op_set) {sni[rt].set(l, r, val);sni[rt].addv = addvi;} else if (op == op_add)sni[rt].add(l, r, val);else if (op == op_rev)sni[rt].rev(l, r, val);return;}push_down(l, r, rt);int mid = (l + r) >> 1;if (cl <= mid)update(op, cl, cr, val, lson);if (cr > mid)update(op, cl, cr, val, rson);push_up(rt);}void update_set(int cl, int cr, ll val, int l, int r, int rt) {update(op_set, cl, cr, val, l, r, rt);}void update_add(int cl, int cr, ll val, int l, int r, int rt) {update(op_add, cl, cr, val, l, r, rt);}void update_rev(int cl, int cr, int l, int r, int rt) {update(op_rev, cl, cr, 1, l, r, rt);}seg_info queries(int ql, int qr, int l, int r, int rt) {if (ql <= l && r <= qr)return sni[rt].si;push_down(l, r, rt);int mid = (l + r) >> 1;seg_info ans = seg_info();if (ql <= mid)ans += queries(ql, qr, lson);if (qr > mid)ans += queries(ql, qr, rson);return ans;}
} st;class Solution {
public:long long maximumProduct(vector<int>& nums, int m) {int n = nums.size();st.build(0, n - 1, 1);for (int i = 0; i < n; ++i)st.update_set(i, i, nums[i], 0, n - 1, 1);ll ans = -inf;for (int i = 0; i < n; ++i) {int j = i + m - 1;if (j < n) {auto res = st.queries(j, n - 1, 0, n - 1, 1);ans = max({ans, nums[i] * res.minv, nums[i] * res.maxv});}}return ans;}
};
有序集合版本
class Solution {using ll = long long;
public:long long maximumProduct(vector<int>& nums, int m) {int n = nums.size();multiset<int> mst;ll ans = LLONG_MIN;for (int i = m - 1; i < n; ++i) {int j = i - m + 1;mst.insert(nums[j]);ans = max({ans, 1LL * nums[i] * (*mst.begin()), 1LL * nums[i] * (*mst.rbegin())});}return ans;}
};
滑动窗口版本
class Solution {using ll = long long;
public:long long maximumProduct(vector<int>& nums, int m) {int n = nums.size(), minv = INT_MAX, maxv = INT_MIN;ll ans = LLONG_MIN;for (int i = m - 1; i < n; ++i) {int j = i - m + 1;minv = min(minv, nums[j]);maxv = max(maxv, nums[j]);ans = max({ans, 1LL * nums[i] * minv, 1LL * nums[i] * maxv});}return ans;}
};
Q4. 树中找到带权中位节点
题意
给你一个整数 n,以及一棵 无向带权 树,根节点为节点 0,树中共有 n 个节点,编号从 0 到 n - 1。该树由一个长度为 n - 1 的二维数组 edges 表示,其中 e d g e s [ i ] = [ u i , v i , w i ] edges[i] = [u_i, v_i, w_i] edges[i]=[ui,vi,wi] 表示存在一条从节点 u i u_i ui 到 v i v_i vi 的边,权重为 w i w_i wi。
带权中位节点 定义为从 u i u_i ui 到 v i v_i vi 路径上的 第一个 节点 x,使得从 u i u_i ui 到 x 的边权之和 大于等于 该路径总权值和的一半。
给你一个二维整数数组 queries。对于每个 q u e r i e s [ j ] = [ u j , v j ] queries[j] = [u_j, v_j] queries[j]=[uj,vj],求出从 u j u_j uj 到 v j v_j vj 路径上的带权中位节点。
返回一个数组 ans,其中 ans[j] 表示查询 queries[j] 的带权中位节点编号。
示例
示例1
输入: n = 2, edges = [[0,1,7]], queries = [[1,0],[0,1]]
输出: [0,1]
说明
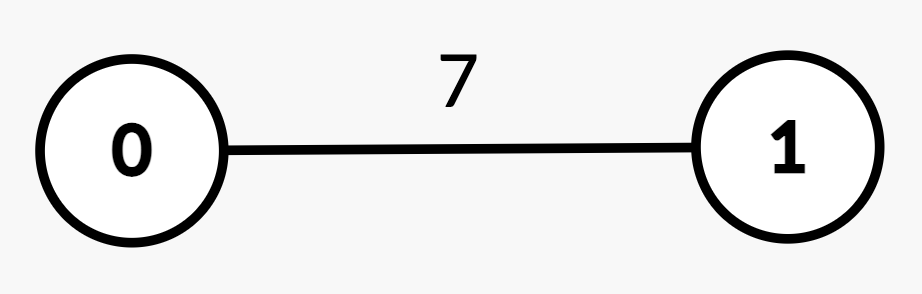
| 查询 | 路径 | 边权 | 总路径权值和 | 一半 | 解释 | 答案 |
|---|---|---|---|---|---|---|
| [1, 0] | 1 → 0 | [7] | 7 | 3.5 | 从 1 → 0 的权重和为 7 >= 3.5,中位节点是 0。 | 0 |
| [0, 1] | 0 → 1 | [7] | 7 | 3.5 | 从 0 → 1 的权重和为 7 >= 3.5,中位节点是 1。 | 1 |
示例2
输入: n = 3, edges = [[0,1,2],[2,0,4]], queries = [[0,1],[2,0],[1,2]]
输出: [1,0,2]
说明
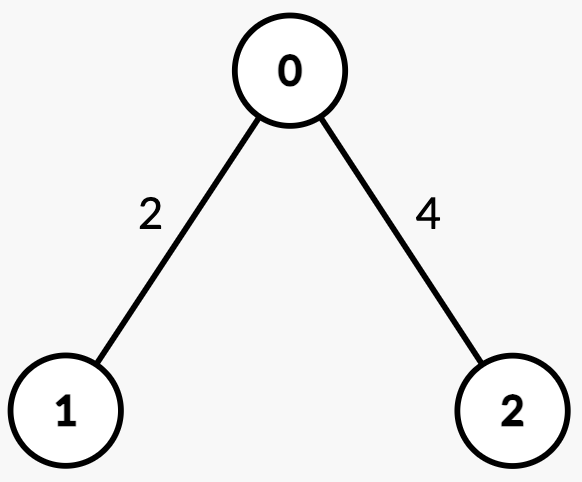
| 查询 | 路径 | 边权 | 总路径权值和 | 一半 | 解释 | 答案 |
|---|---|---|---|---|---|---|
| [0, 1] | 0 → 1 | [2] | 2 | 1 | 从 0 → 1 的权值和为 2 >= 1,中位节点是 1。 | 1 |
| [2, 0] | 2 → 0 | [4] | 4 | 2 | 从 2 → 0 的权值和为 4 >= 2,中位节点是 0。 | 0 |
| [1, 2] | 1 → 0 → 2 | [2, 4] | 6 | 3 | 从 1 → 0 = 2 < 3, 从 1 → 2 = 6 >= 3,中位节点是 2。 | 2 |
示例3
输入: n = 5, edges = [[0,1,2],[0,2,5],[1,3,1],[2,4,3]], queries = [[3,4],[1,2]]
输出: [2,2]
说明
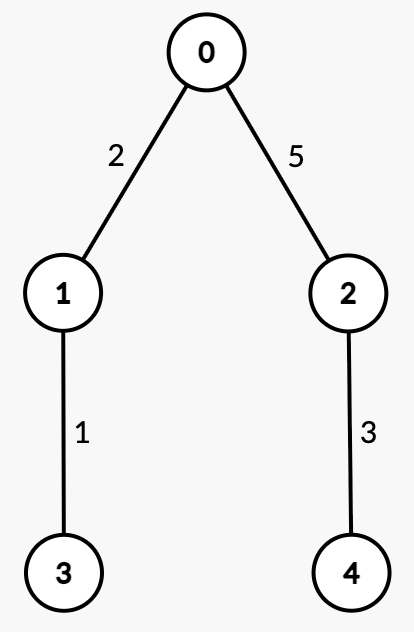
| 查询 | 路径 | 边权 | 总路径权值和 | 一半 | 解释 | 答案 |
|---|---|---|---|---|---|---|
| [3, 4] | 3 → 1 → 0 → 2 → 4 | [1, 2, 5, 3] | 11 | 5.5 | 从 3 → 1 = 1 < 5.5, 从 3 → 0 = 3 < 5.5, 从 3 → 2 = 8 >= 5.5,中位节点是 2。 | 2 |
| [1, 2] | 1 → 0 → 2 | [2, 5] | 7 | 3.5 | 从 1 → 0 = 2 < 3.5, 从 1 → 2 = 7 >= 3.5,中位节点是 2。 | 2 |
提示
- 2 < = n < = 10 5 2 <= n <= 10^5 2<=n<=105
- e d g e s . l e n g t h = = n − 1 edges.length == n - 1 edges.length==n−1
- e d g e s [ i ] = = [ u i , v i , w i ] edges[i] == [u_i, v_i, w_i] edges[i]==[ui,vi,wi]
- 0 < = u i , v i < n 0 <= u_i, v_i < n 0<=ui,vi<n
- 1 < = w i < = 10 9 1 <= w_i <= 10^9 1<=wi<=109
- 1 < = q u e r i e s . l e n g t h < = 10 5 1 <= queries.length <= 10^5 1<=queries.length<=105
- q u e r i e s [ j ] = = [ u j , v j ] queries[j] == [u_j, v_j] queries[j]==[uj,vj]
- 0 < = u j , v j < n 0 <= u_j, v_j < n 0<=uj,vj<n
- 输入保证 edges 表示一棵合法的树。
解题思路:二分/树上倍增+LCA
困难题。首先,树上任意两点之间的路径是唯一的,那么从树上一点到另一点经过的点的权值和是非递减的。又因为询问是 10 5 10^5 105 级别的,我们不能每次都去遍历,这样肯定会 TLE。那么怎么快速计算出两点之间的距离呢?显然我们可以在 LCA 计算过程中计算出基于根节点的每个点 u u u 的深度 d e p u dep_u depu 以及权值和 d i s u dis_u disu,那么对于任意两点 u , v u, v u,v,其路径上的权值和如下。
d i s u v = d i s u + d i s v − 2 ∗ d i s f a ,其中 f a = L C A ( u , v ) dis_{uv} = dis_u + dis_v - 2 * dis_{fa},其中 fa = LCA(u, v) disuv=disu+disv−2∗disfa,其中fa=LCA(u,v)
如上所述,其实路径被分为了两条链, u → f a u \rightarrow fa u→fa 和 f a → v fa \rightarrow v fa→v,那么我们可以分别 二分 两条链中的节点,判断该节点是否满足条件,至于中点怎么确定呢?这个时候就需要用到深度了,取 u u u 和 f a fa fa 的深度差,就可以表示他最多能往上走几步,时间复杂度为 O ( q l o g 2 n ) O(qlog^{2}n) O(qlog2n)(其中二分步长需要 O ( l o g n ) O(logn) O(logn),倍增算出向上走具体步数所对应的节点需要 O ( l o g n ) O(logn) O(logn),总共有 q q q 次询问)。
其实求出 f a fa fa 后就能够确认答案在哪条链上了。假如 d i s u − d i s f a > = ⌈ d i s u v 2 ⌉ dis_u - dis_{fa} >= \lceil{\frac{dis_{uv}}{2}}\rceil disu−disfa>=⌈2disuv⌉ ,答案在第一条链上,否则在第二条链上。加个分类讨论,可以简化代码写法,时间复杂度不变。
再思考一下,既然路径确定,是否可以直接用 倍增 来锁定节点?显然是可以的,跟计算 LCA 是一样的思路,从高位枚举跳跃步数即可,而且可以优化掉二分的时间,时间复杂度为 O ( q l o g n ) O(qlogn) O(qlogn)。
参考代码(C++)
二分+LCA版本
using ll = long long;
using pii = pair<int, int>;
const int maxn = 100'005;
const int maxm = 20;
struct tree_ancestor {int n, m, id;int d[maxn];ll dis[maxn];int p[maxn][maxm];pii pv[maxn];vector<pii> adj[maxn];void init(int n) {this->n = n;id = 0;for (int i = 0; i < n; ++i)adj[i].clear(), d[i] = dis[i] = 0;m = 32 - __builtin_clz(n);for (int i = 0; i < n; ++i)for (int j = 0; j < m; ++j)p[i][j] = -1;}void add_edge(int u, int v, int w) {adj[u].push_back({v, w});adj[v].push_back({u, w});}void dfs(int u, int fu) {p[u][0] = fu;pv[u].first = id++;for (auto& [v, w] : adj[u])if (v != fu) {d[v] = d[u] + 1;dis[v] = dis[u] + w;dfs(v, u);}pv[u].second = id - 1;}void calc(int root) {dfs(root, -1);for (int j = 1; j < m; ++j)for (int i = 0; i < n; ++i)if (int pa = p[i][j - 1]; pa != -1)p[i][j] = p[pa][j - 1];}int get_kth_ancestor(int u, int k) {while (k && u != -1) {u = p[u][__builtin_ctz(k)];k &= k - 1;}return u;}int get_lca(int u, int v) {// 返回 u 和 v 的最近公共祖先(节点编号从 0 开始)if (d[u] > d[v])swap(u, v);// 使 u 和 v 在同一深度v = get_kth_ancestor(v, d[v] - d[u]);if (v == u)return v;for (int j = m - 1; j >= 0; --j) {int pu = p[u][j], pv = p[v][j];if (pu != pv)u = pu, v = pv;}return p[u][0];}bool is_ancestor(int u, int v) {return pv[u].first < pv[v].first && pv[v].first <= pv[u].second;}
} ta;class Solution {
public:vector<int> findMedian(int n, vector<vector<int>>& edges, vector<vector<int>>& queries) {ta.init(n);for (auto& e : edges)ta.add_edge(e[0], e[1], e[2]);ta.calc(0);vector<int> ans;for (auto& q : queries) {int u = q[0], v = q[1];int fa = ta.get_lca(u, v);ll dt = ta.dis[u] + ta.dis[v] - (ta.dis[fa] << 1);int l = 0, r = ta.d[u] - ta.d[fa], res = -1;while (l <= r) {int mid = (l + r) >> 1;int fu = ta.get_kth_ancestor(u, mid);if (((ta.dis[u] - ta.dis[fu]) << 1) >= dt) {res = fu;r = mid - 1;} elsel = mid + 1;}if (res != -1)ans.push_back(res);else {l = 0, r = ta.d[v] - ta.d[fa], res = fa;while (l <= r) {int mid = (l + r) >> 1;int fv = ta.get_kth_ancestor(v, mid);if (((ta.dis[fv] + ta.dis[u] - (ta.dis[fa] << 1)) << 1) >= dt) {res = fv;l = mid + 1;} elser = mid - 1;}ans.push_back(res);}}return ans;}
};
树上倍增(左右尝试)+LCA版本
using ll = long long;
using pii = pair<int, int>;
const int maxn = 100'005;
const int maxm = 20;
struct tree_ancestor {int n, m, id;int d[maxn];ll dis[maxn];int p[maxn][maxm];pii pv[maxn];vector<pii> adj[maxn];void init(int n) {this->n = n;id = 0;for (int i = 0; i < n; ++i)adj[i].clear(), d[i] = dis[i] = 0;m = 32 - __builtin_clz(n);for (int i = 0; i < n; ++i)for (int j = 0; j < m; ++j)p[i][j] = -1;}void add_edge(int u, int v, int w) {adj[u].push_back({v, w});adj[v].push_back({u, w});}void dfs(int u, int fu) {p[u][0] = fu;pv[u].first = id++;for (auto& [v, w] : adj[u])if (v != fu) {d[v] = d[u] + 1;dis[v] = dis[u] + w;dfs(v, u);}pv[u].second = id - 1;}void calc(int root) {dfs(root, -1);for (int j = 1; j < m; ++j)for (int i = 0; i < n; ++i)if (int pa = p[i][j - 1]; pa != -1)p[i][j] = p[pa][j - 1];}int get_kth_ancestor(int u, int k) {while (k && u != -1) {u = p[u][__builtin_ctz(k)];k &= k - 1;}return u;}int get_lca(int u, int v) {// 返回 u 和 v 的最近公共祖先(节点编号从 0 开始)if (d[u] > d[v])swap(u, v);// 使 u 和 v 在同一深度v = get_kth_ancestor(v, d[v] - d[u]);if (v == u)return v;for (int j = m - 1; j >= 0; --j) {int pu = p[u][j], pv = p[v][j];if (pu != pv)u = pu, v = pv;}return p[u][0];}bool is_ancestor(int u, int v) {return pv[u].first < pv[v].first && pv[v].first <= pv[u].second;}
} ta;class Solution {
public:vector<int> findMedian(int n, vector<vector<int>>& edges, vector<vector<int>>& queries) {ta.init(n);for (auto& e : edges)ta.add_edge(e[0], e[1], e[2]);ta.calc(0);vector<int> ans;for (auto& q : queries) {int u = q[0], v = q[1];int fa = ta.get_lca(u, v);ll dt = ta.dis[u] + ta.dis[v] - (ta.dis[fa] << 1);int ut = u;for (int j = ta.m - 1; j >= 0; --j)if (ta.p[ut][j] != -1 && ta.d[ta.p[ut][j]] >= ta.d[fa] && ((ta.dis[u] - ta.dis[ta.p[ut][j]]) << 1) < dt)ut = ta.p[ut][j];// cout << "ut1:" << ut << '\n';if (ut != fa) {ut = ta.p[ut][0];if (ut != -1 && ta.d[ut] >= ta.d[fa]) {ans.push_back(ut);continue;}}ut = v;for (int j = ta.m - 1; j >= 0; --j)if (ta.p[ut][j] != -1 && ta.d[ta.p[ut][j]] >= ta.d[fa] && ((ta.dis[u] + ta.dis[ta.p[ut][j]] - (ta.dis[fa] << 1)) << 1) >= dt)ut = ta.p[ut][j];// cout << "ut2:" << ut << '\n';ans.push_back(ut);}return ans;}
};
树上倍增(判定左右分支)+LCA版本
using ll = long long;
using pii = pair<int, int>;
const int maxn = 100'005;
const int maxm = 20;
struct tree_ancestor {int n, m, id;int d[maxn];ll dis[maxn];int p[maxn][maxm];pii pv[maxn];vector<pii> adj[maxn];void init(int n) {this->n = n;id = 0;for (int i = 0; i < n; ++i)adj[i].clear(), d[i] = dis[i] = 0;m = 32 - __builtin_clz(n);for (int i = 0; i < n; ++i)for (int j = 0; j < m; ++j)p[i][j] = -1;}void add_edge(int u, int v, int w) {adj[u].push_back({v, w});adj[v].push_back({u, w});}void dfs(int u, int fu) {p[u][0] = fu;pv[u].first = id++;for (auto& [v, w] : adj[u])if (v != fu) {d[v] = d[u] + 1;dis[v] = dis[u] + w;dfs(v, u);}pv[u].second = id - 1;}void calc(int root) {dfs(root, -1);for (int j = 1; j < m; ++j)for (int i = 0; i < n; ++i)if (int pa = p[i][j - 1]; pa != -1)p[i][j] = p[pa][j - 1];}int get_kth_ancestor(int u, int k) {while (k && u != -1) {u = p[u][__builtin_ctz(k)];k &= k - 1;}return u;}int get_lca(int u, int v) {// 返回 u 和 v 的最近公共祖先(节点编号从 0 开始)if (d[u] > d[v])swap(u, v);// 使 u 和 v 在同一深度v = get_kth_ancestor(v, d[v] - d[u]);if (v == u)return v;for (int j = m - 1; j >= 0; --j) {int pu = p[u][j], pv = p[v][j];if (pu != pv)u = pu, v = pv;}return p[u][0];}bool is_ancestor(int u, int v) {return pv[u].first < pv[v].first && pv[v].first <= pv[u].second;}
} ta;class Solution {
public:vector<int> findMedian(int n, vector<vector<int>>& edges, vector<vector<int>>& queries) {ta.init(n);for (auto& e : edges)ta.add_edge(e[0], e[1], e[2]);ta.calc(0);vector<int> ans;for (auto& q : queries) {int u = q[0], v = q[1];if (u == v) {ans.push_back(u);continue;}int fa = ta.get_lca(u, v);ll dt = ta.dis[u] + ta.dis[v] - (ta.dis[fa] << 1);ll half = (dt + 1) >> 1;ll dr = ta.dis[u] - ta.dis[fa];// cout << "dt:" << dt << ";half:" << half << ";dr:" << dr << '\n';if (dr >= half) {int ut = u;for (int j = ta.m - 1; j >= 0; --j)if (ta.p[ut][j] != -1 && ta.d[ta.p[ut][j]] >= ta.d[fa] && ta.dis[u] - ta.dis[ta.p[ut][j]] < half)ut = ta.p[ut][j];ans.push_back(ta.p[ut][0]);} else {int ut = v;for (int j = ta.m - 1; j >= 0; --j)if (ta.p[ut][j] != -1 && ta.d[ta.p[ut][j]] >= ta.d[fa] && ta.dis[u] + ta.dis[ta.p[ut][j]] - (ta.dis[fa] << 1) >= half)ut = ta.p[ut][j];ans.push_back(ut);}}return ans;}
};