第八十篇 大数据开发基石:深入解析栈结构及其生活化应用(附全流程图解)
目录
- 🧱 一、栈的核心定义与操作原理
- 🌍 二、生活案例:栈的智慧无处不在
- 1. 浏览器历史记录管理
- 2. 文档编辑器的撤销/重做功能
- 3. 餐厅自助餐盘管理
- 💻 三、栈在技术领域的核心应用
- 1. 函数调用栈(程序运行基石)
- 2. 括号匹配算法(编译器核心校验)
- 3. 大数据场景应用
- ⚖️ 四、栈的实现方案对比
- 💡 五、为什么选择栈?决策树
- 📌 六、总结:栈的思维模型
摘要:栈(Stack)作为计算机科学的核心数据结构,其后进先出(LIFO) 特性不仅支撑着程序运行的基础逻辑,更隐藏在我们日常生活的各种场景中。本文通过生活化案例解析栈的运作机制,结合专业流程图详解技术实现,并阐述其在大数据开发中的关键作用。
🧱 一、栈的核心定义与操作原理
栈是一种限制性线性表,仅允许在栈顶(Top) 进行插入(Push)和删除(Pop)操作,另一端称为栈底(Bottom)。
核心操作:
- Push:向栈顶添加元素
- Pop:移除并返回栈顶元素
- Peek:查看栈顶元素(不移除)
- isEmpty:判断栈是否为空
▲ 栈操作流程图:验证LIFO(后进先出)原则
🌍 二、生活案例:栈的智慧无处不在
1. 浏览器历史记录管理
▲ 浏览器双栈协作机制:历史栈实现后退,前进栈实现前进
运作逻辑:
- 访问新页面 → URL压入历史栈
- 点击后退 → 历史栈弹出URL → 压入前进栈
- 点击前进 → 前进栈弹出URL → 压回历史栈
2. 文档编辑器的撤销/重做功能
- 撤销栈:记录每次操作(输入、删除、格式调整)
- 重做栈:存储被撤销的操作
- LIFO体现:连续按
Ctrl+Z时,从最近的操作开始依次撤销
3. 餐厅自助餐盘管理
- Push:服务员将洗净的盘子叠放在最上方
- Pop:顾客总是取走最顶部的盘子
- LIFO优势:保证最新清洁的盘子最先被使用
💻 三、栈在技术领域的核心应用
1. 函数调用栈(程序运行基石)
▲ 递归函数调用栈:每次调用创建新栈帧
关键点:
- 函数调用 → 新栈帧压入栈顶
- 函数返回 → 弹出当前栈帧 → 恢复上一栈帧
- 栈溢出:递归过深导致栈空间耗尽
2. 括号匹配算法(编译器核心校验)
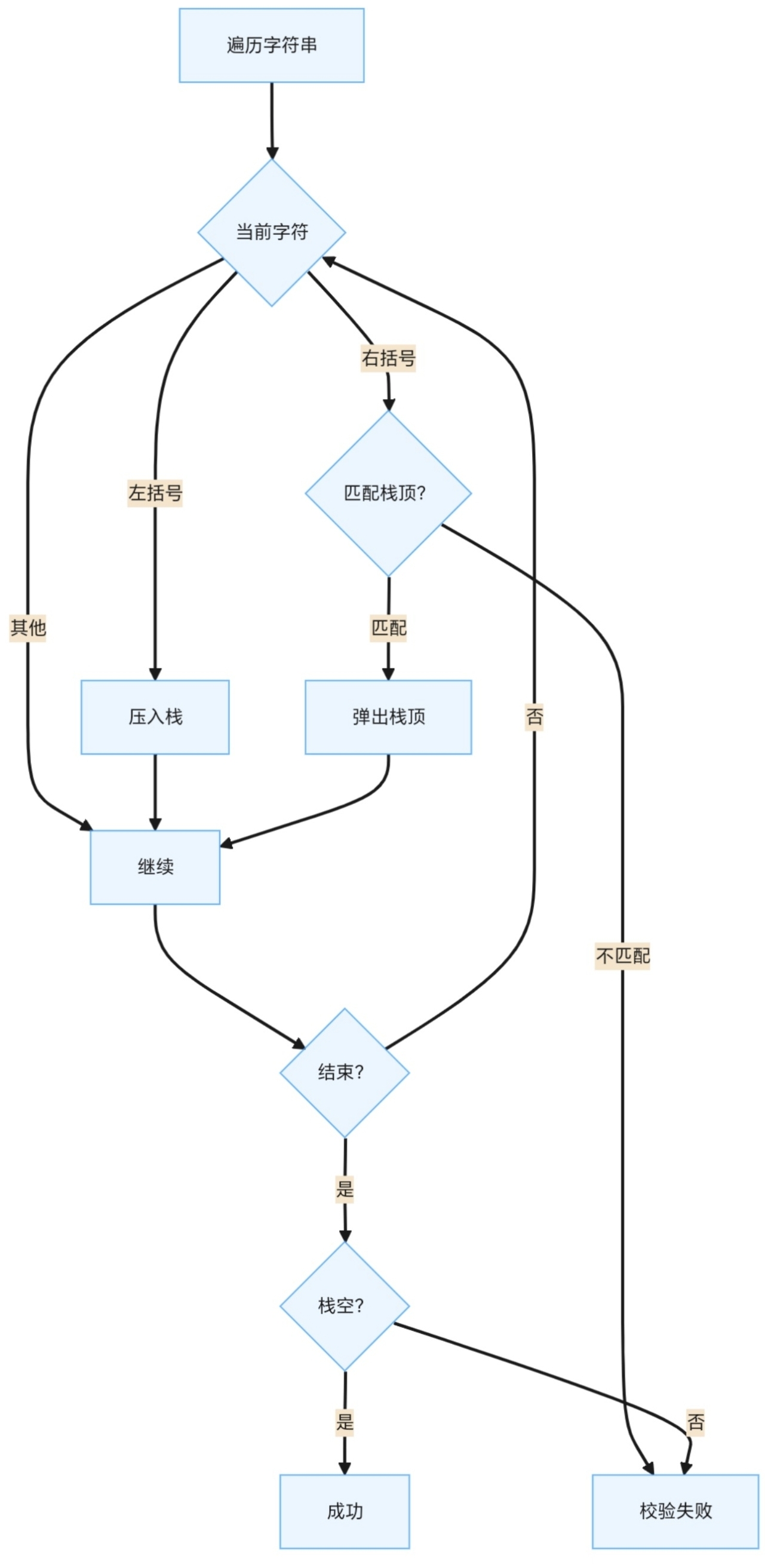
▲ 括号匹配算法流程图:处理嵌套结构
执行示例:
- 输入
{[()]} { [ (依次入栈 → 栈状态:(, [, {)匹配栈顶(→ 弹出(]匹配栈顶[→ 弹出[}匹配栈顶{→ 弹出{- 栈空 → 校验通过
3. 大数据场景应用
- 深度优先搜索(DFS):用栈记录访问路径,实现图数据遍历
- 表达式求值:双栈(操作数栈+运算符栈)解析复杂计算
- 消息回溯:流处理中按时间逆序处理延迟到达的数据
⚖️ 四、栈的实现方案对比
| 实现方式 | 时间复杂度 | 空间特性 | 适用场景 |
|---|---|---|---|
| 基于数组 | Push/Pop: O(1) | 固定大小,可能浪费 | 元素数量可预估的场景 |
| 基于链表 | Push/Pop: O(1) | 动态扩容无上限 | 元素数量不定的场景 |
💡 五、为什么选择栈?决策树
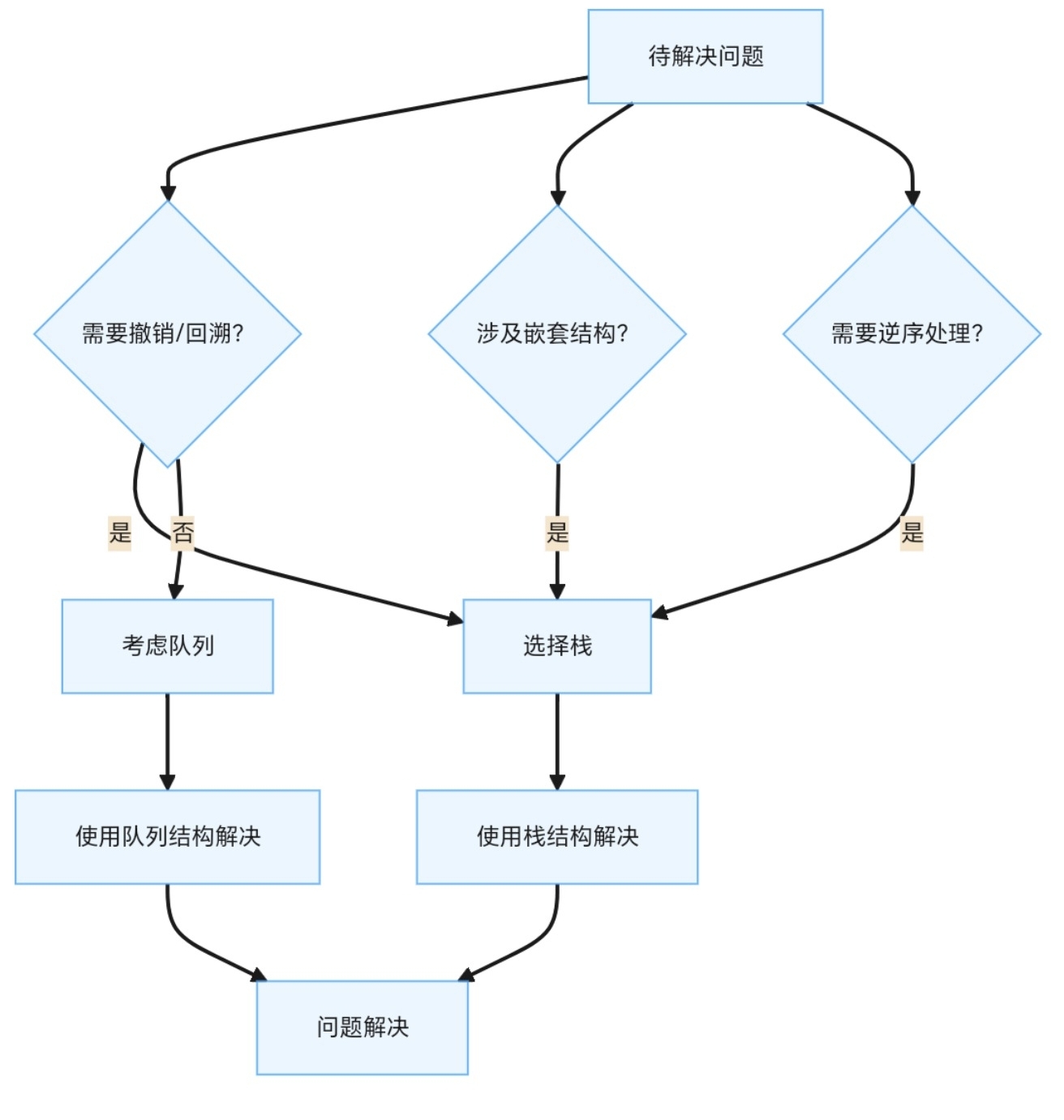
▲ 栈的适用场景决策树
选择栈当:
- 需要“撤销”或“回溯”机制(如编辑器操作)
- 处理嵌套关系(如代码块、JSON解析)
- 按反向顺序处理数据(如DFS回溯)
📌 六、总结:栈的思维模型
栈的LIFO特性本质上是一种时间逆序处理的思维模型:
- 现实映射:浏览器后退、文档撤销、餐盘管理都遵循“最后发生的先处理”
- 技术本质:函数调用、括号匹配、DFS都依赖栈管理执行顺序
- 大数据应用:在流处理中实现数据回溯,在分布式计算中管理任务状态
关键洞察:当问题呈现“操作可逆”、“结构嵌套”、“顺序依赖”特征时,栈往往是最高效的解决方案。理解栈不仅是为了掌握数据结构,更是培养“逆序处理”的计算机思维。
🎯下期预告:《数据结构-队列》
💬互动话题:人之处于患难,只有一个处置。尽人谋之后,却须泰然处之
🏷️温馨提示:我是[随缘而动,随遇而安], 一个喜欢用生活案例讲技术的开发者。如果觉得有帮助,点赞关注不迷路🌟