“交错推理”降低首token耗时,并且显著提升推理准确性!!
摘要:长思维链(CoT)显著增强了大型语言模型(LLM)的推理能力。然而,广泛的推理痕迹导致了效率低下以及首次输出时间(Time-to-First-Token,TTFT)的增加。我们提出了一种新颖的训练范式,利用强化学习(RL)指导推理型LLM在多跳问题中交替进行思考和回答。我们观察到,模型本身具备交替推理的能力,这种能力可以通过强化学习进一步增强。我们引入了一种简单而有效的基于规则的奖励机制,以激励正确的中间步骤,该机制通过利用交替推理过程中生成的中间信号,引导策略模型走向正确的推理路径。我们在五个多样化的数据集和三种强化学习算法(PPO、GRPO和REINFORCE++)上进行了广泛的实验,结果表明,与传统的思考-回答推理方式相比,我们的方法具有一致的改进效果,且无需外部工具。具体而言,我们的方法平均将TTFT降低了超过80%,并将Pass@1准确率提高了高达19.3%。此外,我们的方法仅在问答和逻辑推理数据集上进行训练,却展现出对复杂推理数据集(如MATH、GPQA和MMLU)的强大泛化能力。此外,我们还进行了深入分析,揭示了关于条件奖励建模的几个有价值的见解。
本文目录
一、研究背景
二、核心贡献
三、实现方法
3.1 多跳问题分解
3.2 思考与回答的区分
3.3 交错推理模板
3.4 奖励函数设计
四、实验结论
4.1 性能显著提升
4.2 中间答案有效性
4.4 奖励策略分析
五、总结
一、研究背景
大模型在复杂多跳任务中通过长推理链表现出强大的推理能力。但是传统的“思考-回答”范式有两个关键问题:
- 时间延迟问题:模型需要完成完整的推理链后才能生成答案,导致首次生成答案的时间(Time-to-First-Token, TTFT)显著增加,这在实时 AI 应用(如对话助手)中会破坏交互流畅性,影响用户体验。
- 错误传播问题:由于延迟生成答案,模型可能会沿着错误的中间步骤推理,导致最终答案不准确,推理效率低下,例如过度思考(overthinking)或思考不足(underthinking)。
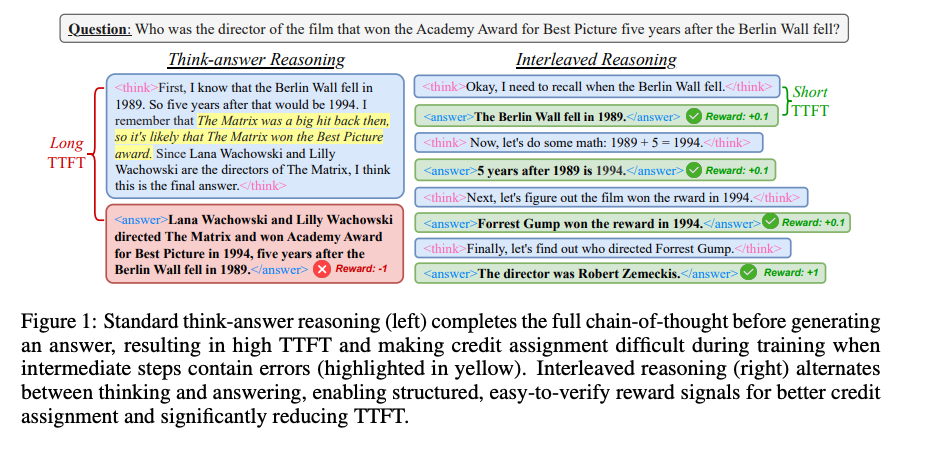
基于上述问题,文章提出了一种新的训练范式——交错推理(Interleaved Reasoning),即让模型在推理过程中交替进行思考和回答,类似于人类在对话中逐步提供反馈的方式。显著降低了首token的耗时,并且提升了推理准确性。
二、核心贡献
1、通过强化学习引导 LLMs 在多跳问题中交替进行思考和回答,显著减少了 TTFT(平均减少超过 80%),同时提高了推理的准确性(最高提升 19.3% 的 Pass@1 准确率)。
2、引入一种简单而有效的基于规则的奖励机制,激励模型生成正确的中间步骤,从而引导模型走向正确的推理路径。这种奖励机制通过中间信号为模型提供密集的监督信号,进一步提升模型的推理能力。
3、仅在问答和逻辑推理数据集上进行训练的模型,能够泛化到复杂的推理数据集(如 MATH、GPQA 和 MMLU),展现出强大的泛化能力。
三、实现方法
3.1 多跳问题分解
交错推理方法的核心是将复杂的多跳问题分解为一系列中间步骤,每个步骤生成一个“子答案”。这些子答案是模型在推理过程中逐步得出的部分结论,能够帮助模型更清晰地组织推理过程。
-
子答案的定义:子答案是模型在推理的每个阶段自信地得出的、对用户有意义的信息或部分结论。例如,在数学问题中,子答案可以是一个中间计算结果;在多跳问答中,子答案可以是解决第一个跳转问题的结论。
-
问题分解:将多跳问题的解答过程视为一个序列,每个中间步骤都生成一个子答案,逐步构建完整的推理链。
3.2 思考与回答的区分
在交错推理中,模型的行为被分为“思考”(thinking)和“回答”(answering)两种模式
-
思考(Thinking):模型内部的推理过程,这部分对用户不可见,主要用于模型自身的逻辑推导。
-
回答(Answering):模型生成的对用户有意义的结论,这部分是用户可见的,并且是模型与用户交互的核心内容。
-
交替模式:交错推理模型生成的序列交替包含思考部分和回答部分

3.3 交错推理模板
为了引导模型采用交错推理过程,文章设计了一个特定的指令模板,模板中包含 <think> 和 <answer> 标签,分别用于推理和提供答案。模板的具体形式如下,该模版在训练和推理过程中都使用,帮助模型理解和遵循交错推理的要求。
You are a helpful assistant. You reason through problems step by step before providing an answer. You conduct your reasoning within <think></think> and share partial answers within <answer></answer> as soon as you become confident about the intermediate results. You continue this pattern of <think></think><answer></answer> until you reach the final answer.
3.4 奖励函数设计
-
格式奖励:检查模型生成的序列是否正确地交替使用
<think>和<answer>标签,并且格式是否完整。 -
最终准确性奖励:评估模型生成的最终答案是否与真实答案一致。
-
条件中间准确性奖励:在满足一定条件下(如最终答案正确、格式有效、训练进度良好),为正确的中间答案提供额外奖励。
四、实验结论
4.1 性能显著提升
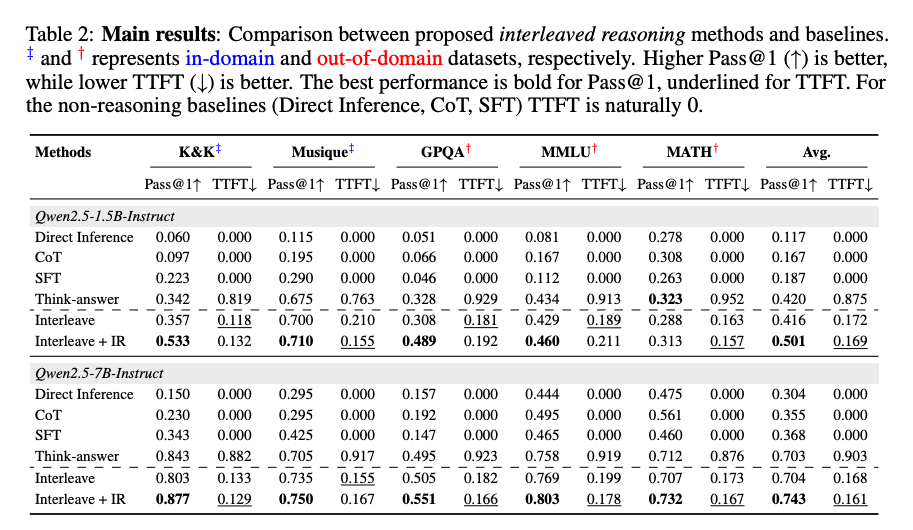
- TTFT 显著降低:交错推理方法(Interleave 和 Interleave + IR)在所有数据集上均显著降低了 TTFT,平均降低超过 80%。例如,在 K&K 数据集上,1.5B 模型的 TTFT 从 0.819 降低到 0.118,7B 模型的 TTFT 从 0.882 降低到 0.129。
- Pass@1 准确率提升:引入条件中间奖励(Interleave + IR)后,模型的 Pass@1 准确率显著提升。例如,在 K&K 数据集上,1.5B 模型的 Pass@1 准确率从 0.342 提升到 0.533,7B 模型的 Pass@1 准确率从 0.843 提升到 0.877。
- 仅在问答和逻辑推理数据集上训练的模型能够泛化到复杂的推理任务(如 MATH、GPQA 和 MMLU),展现出强大的泛化能力。例如,在 GPQA 数据集上,1.5B 模型的 Pass@1 准确率从 0.328 提升到 0.489,7B 模型的 Pass@1 准确率从 0.495 提升到 0.551。
4.2 中间答案有效性
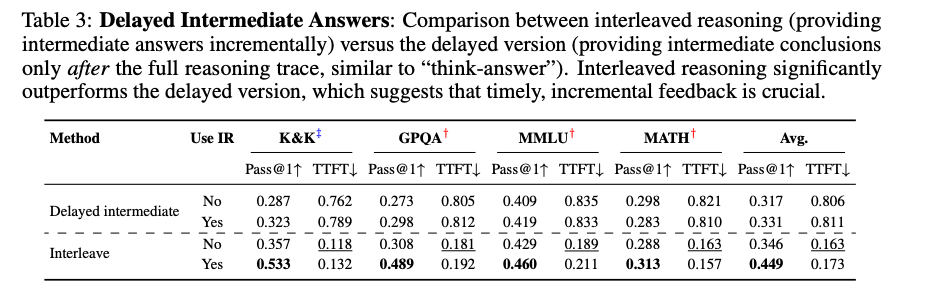
- 及时提供中间答案对模型性能至关重要。延迟提供中间答案会显著降低 Pass@1 准确率和增加 TTFT。例如,在 K&K 数据集上,延迟提供中间答案的 Pass@1 准确率从 0.357 降低到 0.287,TTFT 从 0.118 增加到 0.762。
- 条件中间奖励(IR)能够显著提升模型生成正确中间答案的能力,从而引导模型走向正确的推理路径。
4.4 奖励策略分析
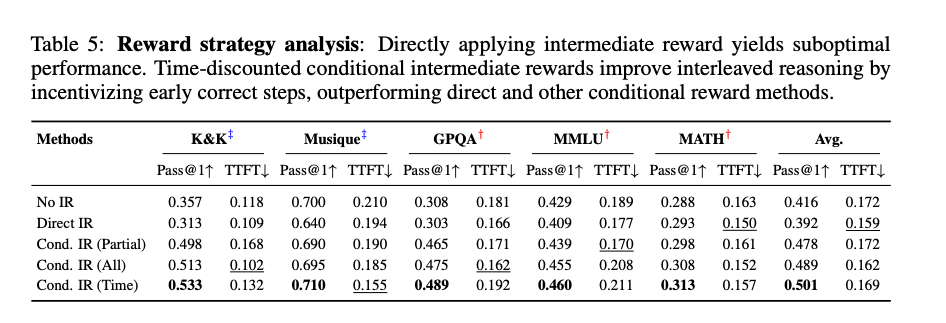
直接应用中间奖励:直接应用中间奖励会导致性能下降,因为模型可能会过度关注局部正确性,而忽略最终答案的正确性。
条件奖励策略:条件奖励策略(特别是时间折扣策略)能够有效提升模型性能。例如,在 K&K 数据集上,时间折扣策略的 Pass@1 准确率最高,达到 0.533。
五、总结
文章提出了一种新颖的交错推理训练范式,通过强化学习引导大语言模型在推理过程中交替思考和回答,显著提高了模型的推理效率和准确性。该方法通过简单的基于规则的奖励机制,激励模型生成有用的中间答案,为模型提供了额外的监督信号,从而改善了推理路径。