复习embedding编码范式及理解代理Agentic RAG及传统RAG的区别
[复习三种embedding编码范式]
现实中大量的 NLP 系统,都或多或少的利用到成对句子(或上下文)评分]
- RAG 系统
- QA 系统
- 文本查重检测系统等
业内用于处理此问题的三种常用方法:Bi-encoders、Cross-encoder、ColBERT三种。
比较直观的可视化如下:
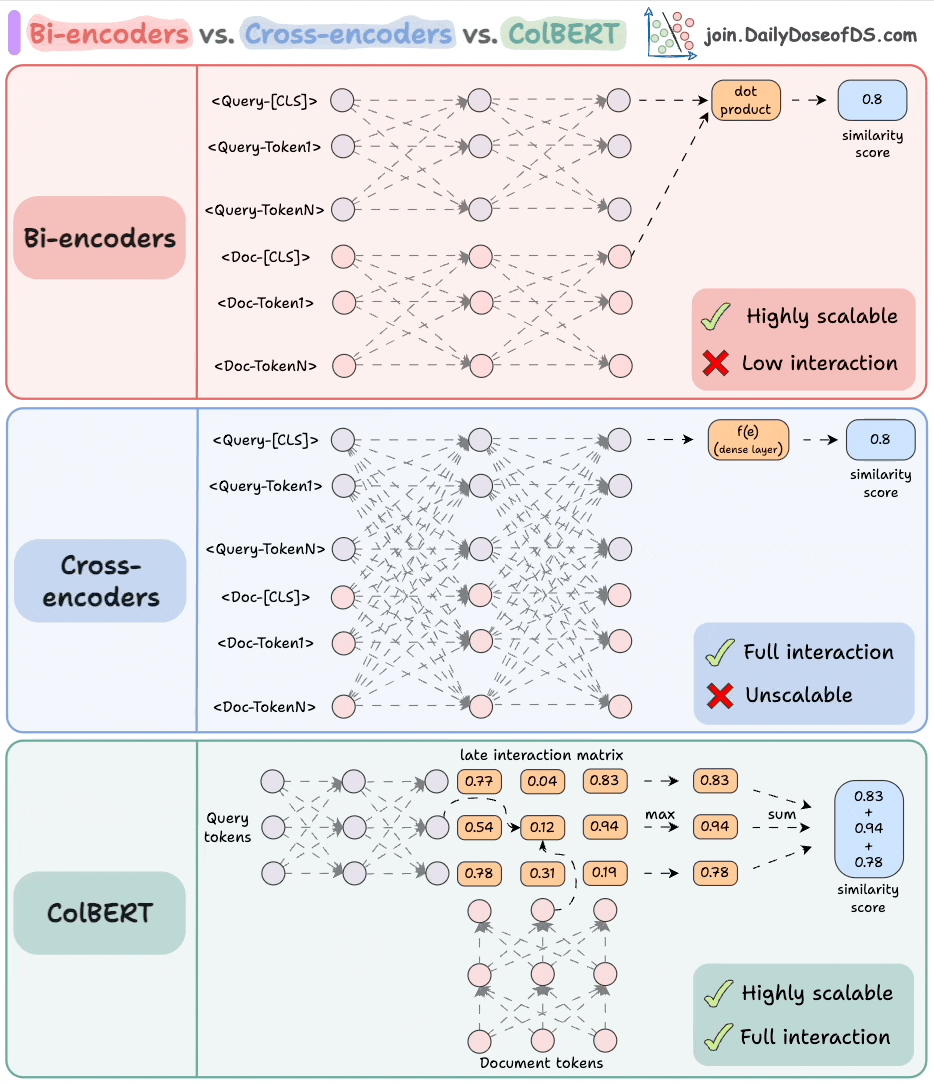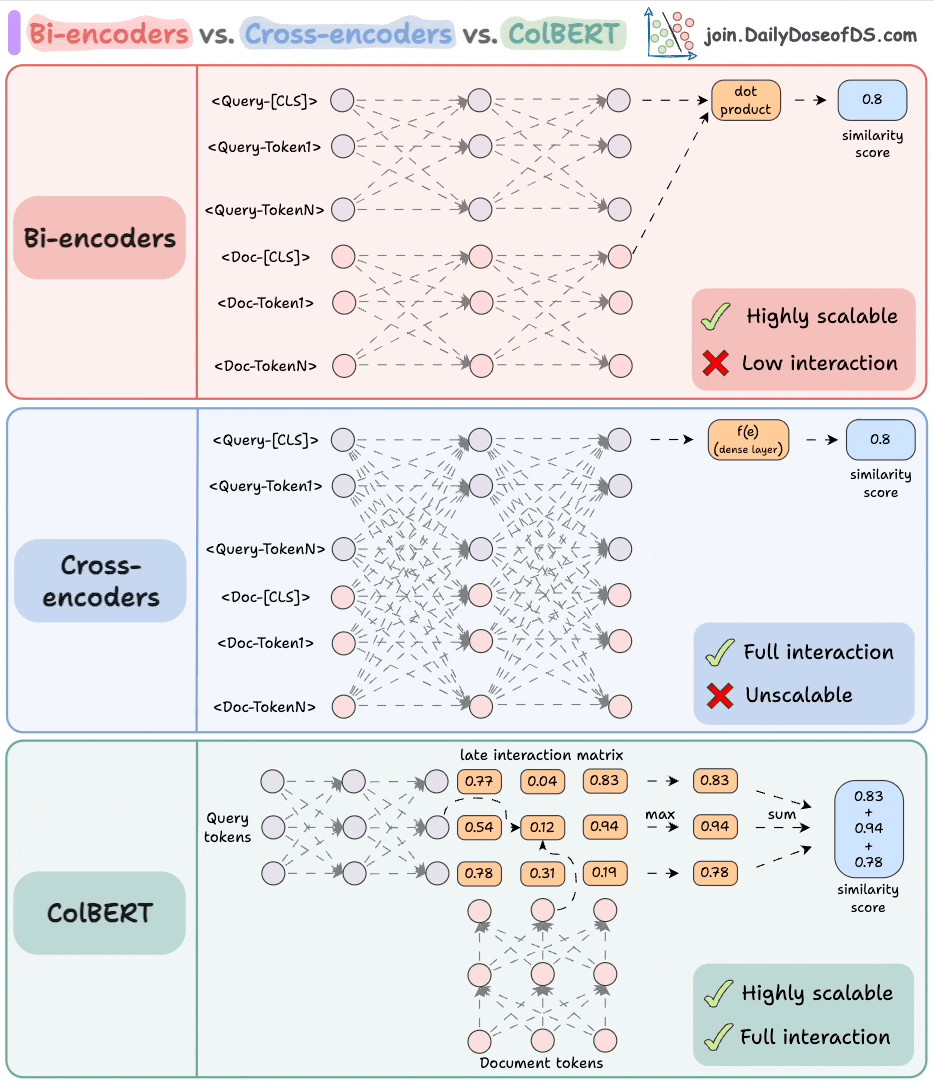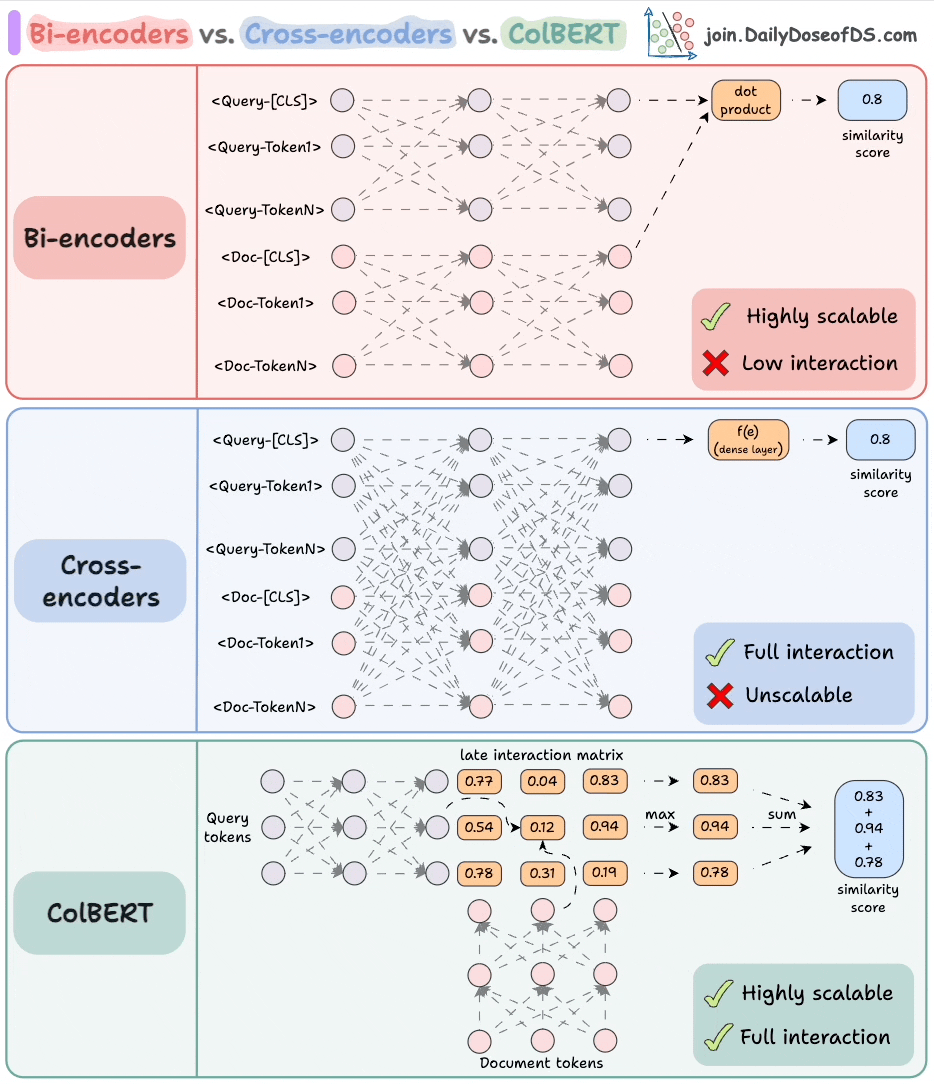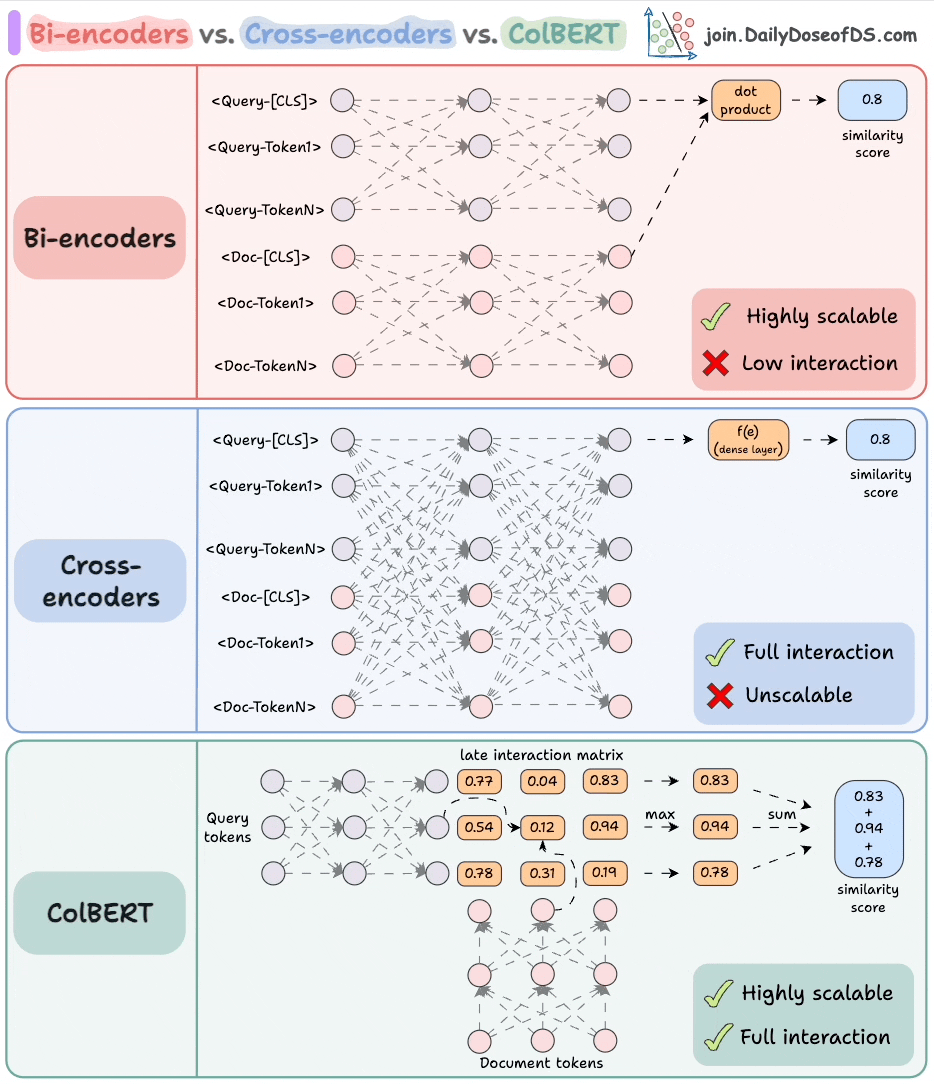
1) 交叉编码器
从概念上讲,这些是最强大的方法之一。
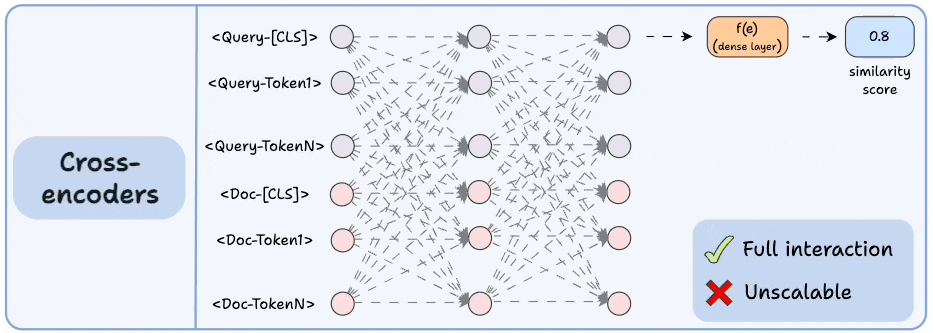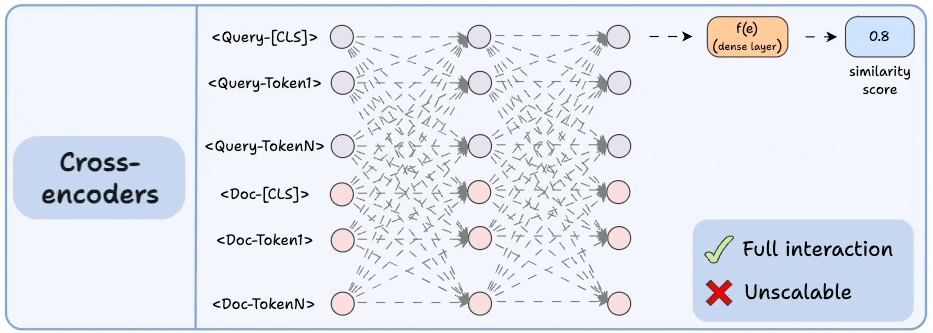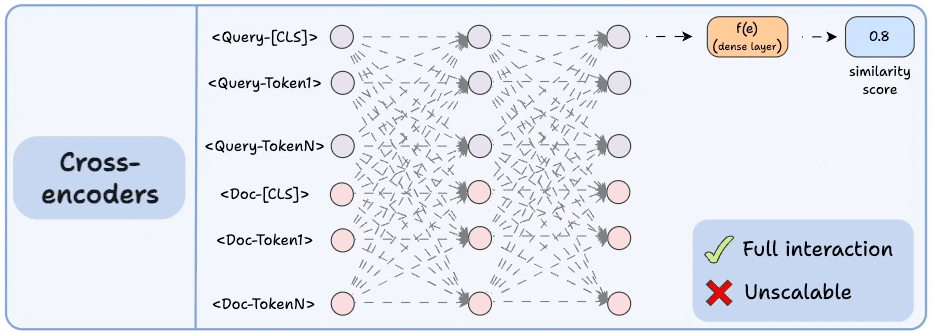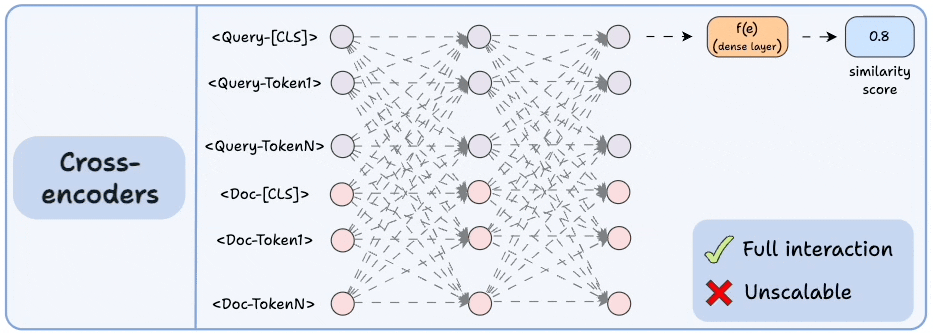
- 拼接查询文本和文档文本。
- 使用类似 BERT 的编码器模型对其进行编码。
- 将转换 (密集层) 应用于
`[CLS]`标记表示形式,以获得相似性分数。
由于该模型同时处理这两种上下文,因此会产生令人难以置信的语义表达表示。
但它无法扩展,因为如果您有 1B 文档,则必须执行 1B 前向传递以确定与查询最相关的文档。
2)Bi-encoders
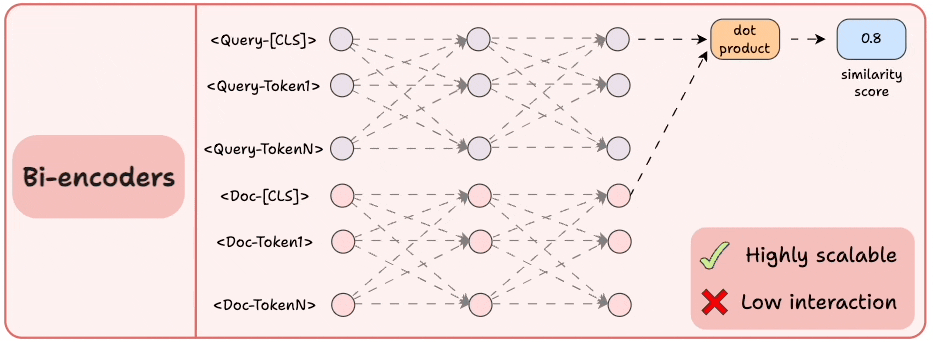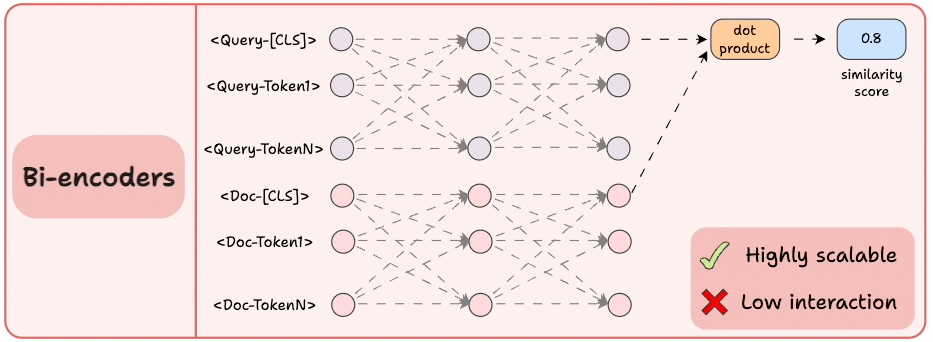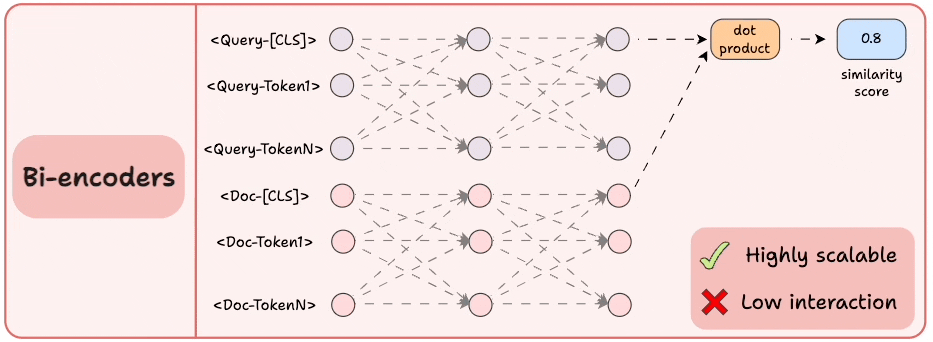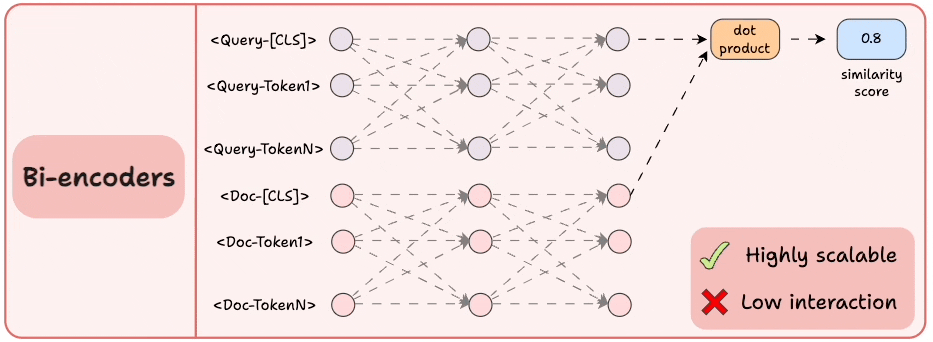
- 分别对查询和文档进行编码。
- 计算查询和文档的
`[CLS]`标记之间的余弦相似度。
这是高度可扩展的,因为文档嵌入可以离线计算。
但是我们失去了所有的交互, 假设可以通过有关查询和文档的全部信息在 `[CLS]` 令牌中得到很好的总结。
3) ColBERT
这结合了交叉编码器的强大功能和双编码器的可扩展性。
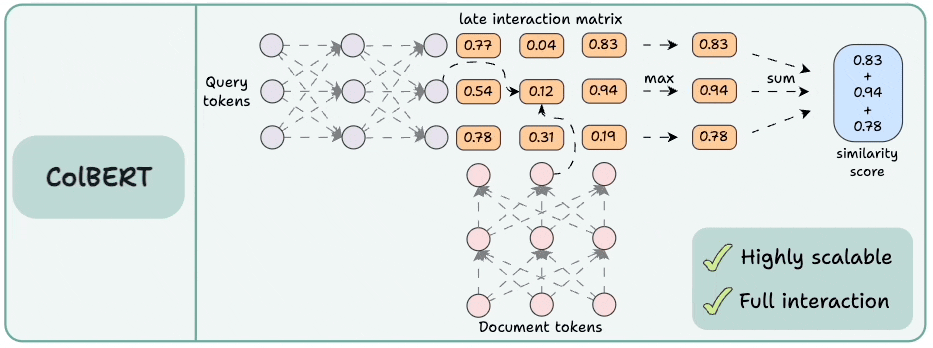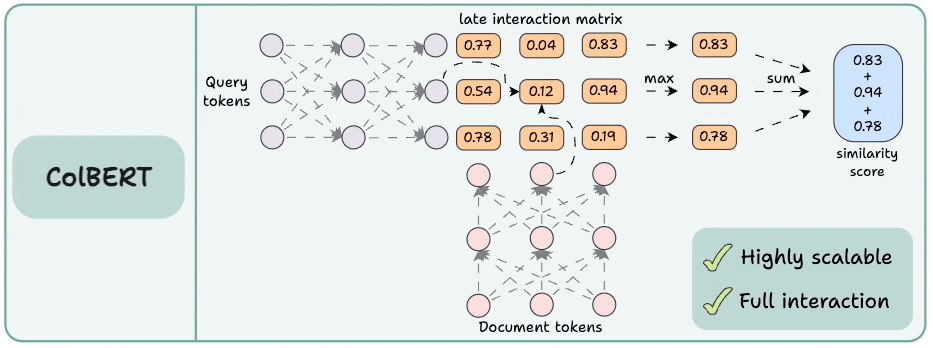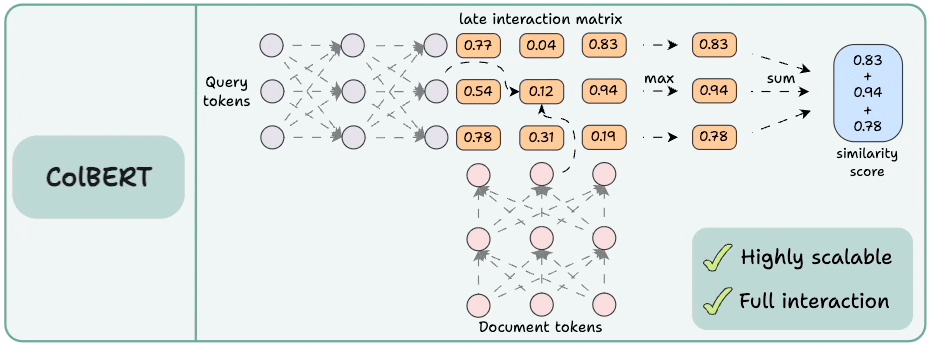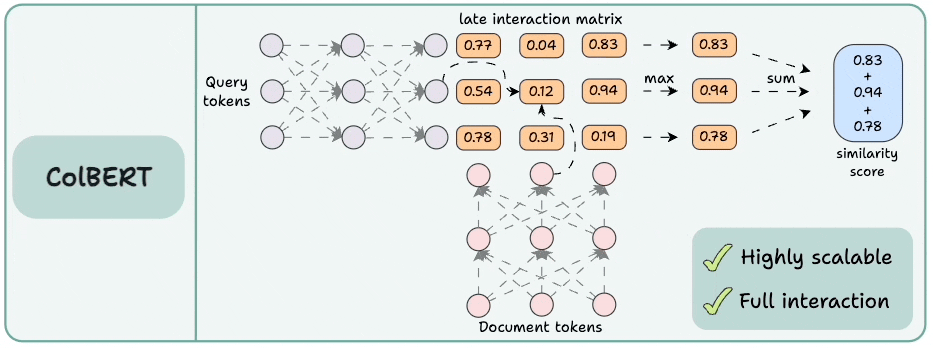
- 分别对查询和文档进行编码。
- 计算一个延迟交互矩阵,其中包含所有查询标记和所有文档标记之间的相似性分数(点积)。
- 对于每个令牌,确定所有文档令牌的最高分数。
- 将这些最高分数相加以获得匹配的分数。
优势:
- 与双编码器一样,它具有高度可扩展性,因为文档嵌入可以离线计算。
- 与跨编码器一样,它维护查询和文档令牌之间的交叉交互(称为延迟交互)。
理解代理RAG及其与代码RAG的区别
在大语言模型(LLMs)的领域中,检索增强生成(RAG)已成为一种变革性技术。传统的RAG虽然具有开创性,但通常遵循一种可预测的模式:根据用户的查询获取信息,然后利用这些信息生成回复。但是,如果我们能让这个过程更智能、更具适应性呢?这就引入了智能体RAG,这是一个重大飞跃,它与传统RAG的差异,就如同智能手机与翻盖手机的差异一样显著。
想象一下,向客服聊天机器人提出一个复杂的问题,这个问题需要来自多个来源的信息。传统的检索增强生成(RAG)可能难以提供全面的答案,但具有智能体的检索增强生成(Agentic RAG)借助其人工智能驱动的智能体,可以浏览知识库、产品手册和客户历史记录,以提供个性化的解决方案。这就是具有智能体的检索增强生成(Agentic RAG)的力量——它将大语言模型从被动的信息处理器转变为主动的知识探索者。
RAG 检索增强生成
检索增强生成(RAG)通过将大语言模型(LLMs)的生成能力与从外部知识源访问和检索相关信息的能力相结合,来提升大语言模型的性能。这种方法使大语言模型能够基于事实知识和现实世界数据,生成更具见地且全面的回复。
一个典型的RAG系统包含以下步骤:
- 问题编码: 用户的查询或提示被编码为一个向量表示,以捕捉其语义含义。
- 知识检索: 编码后的查询用于搜索外部知识库,该知识库可以是文档集合、数据库,甚至是互联网。检索与查询最相关的信息。
- 信息增强: 将检索到的信息与原始查询相结合,为大语言模型提供更丰富的上下文。
- 回复生成: 大语言模型(LLM)根据增强后的信息生成回复,确保输出基于事实知识且与用户查询相关。
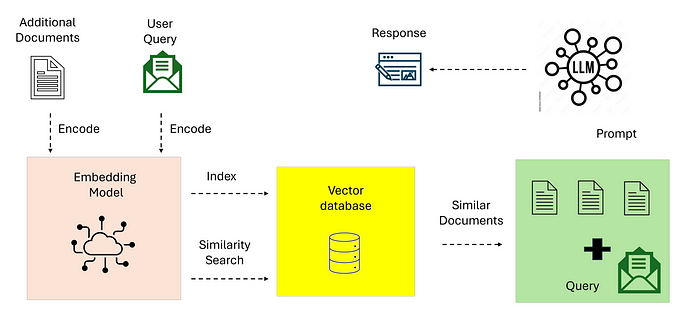
图像来源:https://arxiv.org/pdf/2501.09136
虽然检索增强生成(RAG)使大语言模型(LLM)在实际应用中更有用,但它通常遵循一个相对线性和直接的过程。RAG无法理解用户意图并规划检索策略,比如判断是应该在互联网上还是在知识库中进行搜索。由于遵循固定的流程,它解决当前问题的能力范围在很大程度上受到限制。
智能体增强检索(Agentic RAG)
智能体增强检索(Agentic RAG)将检索增强生成(RAG)的核心原则与人工智能智能体的能力相结合。这些智能体充当用户查询与外部知识源之间的中介,为信息检索提供了一种更动态、更细致入微的方法。这些智能体不再仅仅依赖关键词或语义相似性,而是能够理解用户意图、进行规划与推理,并即时调整策略。
但是智能体增强检索(Agentic RAG)是如何做到这一点的呢?让我们来详细分析一下:
- 提示: 一切都始于用户向大语言模型(LLM)发出的查询或请求。
- 大语言模型(LLM): 这是整个运作的核心,是一种基于用户查询和智能体检索到的信息生成回复的大语言模型。
- 智能体: 这些是由人工智能驱动的主力军,它们使用工具和功能从各种来源检索和处理信息以解决任务。
- 工具/函数: 这是智能体可支配的工具库,包括用于收集和处理信息的应用程序编程接口、数据库及其他外部资源。
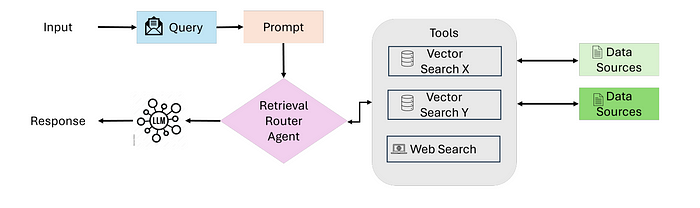
图片来源:https://arxiv.org/pdf/2501.09136
代码示例(概念性)
class Agent:def __init__(self, llm, tools):self.llm = llmself.tools = toolsdef solve_task(self, prompt):# 1. Understand the prompt using the LLMintent = self.llm.understand_intent(prompt)# 2. Plan retrieval strategy based on intentplan = self.llm.plan_retrieval(intent)# 3. Execute the plan using available toolsresults = self.execute_plan(plan)# 4. Generate a response using the LLMresponse = self.llm.generate_response(results)return response
智能体增强检索(RAG)架构的复杂程度各不相同,从充当路由器的单智能体系统,到具有更复杂交互的多智能体系统。在单智能体系统中,智能体充当路由器,决定从哪个知识源检索信息。多智能体系统涉及多个智能体,它们可以协作和通信以解决更复杂的任务。
此外,智能体增强检索(Agentic RAG)打破了标准增强检索(RAG)系统的线性流程,赋予智能体采取多个步骤来实现目标的能力。这使得智能体不仅能够检索信息,还能对查询进行调整、总结结果,甚至生成新数据,从而有效地回答问题。
使用Langchain编写代码
我将提供一个小型的概念验证,说明如何实现一个智能体增强检索(Agentic RAG),以及它为何更优。
from langchain.agents import initialize_agent, Tool
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationBufferMemory# Dummy KnowledgeBase class
class KnowledgeBase:def __init__(self):self.data = {"battery_issue": "Recent software updates may temporarily increase battery drain due to background processes.","battery_optimization_tips": "To improve battery life, try enabling Battery Saver mode and closing unused apps."}def search(self, query):# Search for relevant entries in the knowledge basefor key, value in self.data.items():if key in query.lower():return valuereturn "No relevant information found in the knowledge base."# Dummy ProductManual class
class ProductManual:def __init__(self):self.manual = {"battery_saver": "Battery Saver mode reduces power consumption by limiting background activity.","restart_steps": "To restart your phone, hold the power button for 5 seconds and select 'Restart'."}def search(self, query):# Search for relevant details in the product manualfor key, value in self.manual.items():if key in query.lower():return valuereturn "No relevant details found in the product manual."# Context analysis tool
def analyze_user_context(user_data):import astuser_data = ast.literal_eval(user_data)print(user_data)if user_data.get("recent_update", False):return "Recent updates may cause temporary background activity spikes. This is a known issue."if user_data.get("high_usage_hours", 0) > 8:return "Your usage pattern suggests heavy battery usage. Consider optimizing app usage and screen brightness."return "No specific context found for the provided data."# Initialize dummy data sources
knowledge_base = KnowledgeBase()
product_manual = ProductManual()# Define tools
tools = [Tool(name="KnowledgeBase",func=lambda query: knowledge_base.search(query),#biasing the invocation as we are using dictionary in knowledge base & product manual and not actual semantic similaritydescription="Searches the knowledge base for relevant product information. Some query are battery_issue, battery_optimization_tips",),Tool(name="ProductManual",func=lambda query: product_manual.search(query),#biasing the invocation as we are using dictionary in knowledge base & product manual and not actual semantic similaritydescription="Searches the product manual for device-specific instructions. Some query are battery_saver, restart_steps",),Tool(name="UserContextAnalyzer",func=lambda user_data: analyze_user_context(user_data),description="Analyzes user-provided data to give tailored insights.",),
]# Initialize LLM and memory
llm = ChatOpenAI(temperature=0)
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)# Create an agent
agent = initialize_agent(tools=tools,llm=llm,agent="zero-shot-react-description",memory=memory,verbose=True,
)# Simulated user query with context
user_query = "Why is my phone's battery draining so quickly?"
user_data = {"recent_update": True,"high_usage_hours": 2# Simulating light usage
}# Run the agent
response = agent.run(f"{user_query} User data: {user_data}"
)
print(response)
为了更清楚地说明差异以及上述代码的工作原理。想象一下,普丽娅,一位忙碌的职场人士,注意到她的新智能手机电池耗电比预期更快。她很沮丧,于是向客服聊天机器人询问:“为什么我的手机电池耗电快,我该如何解决这个问题?”
传统的检索增强生成(RAG)可能会从常见问题解答中检索到一个通用回复:“电池续航时间取决于使用情况。尝试关闭后台应用程序或降低屏幕亮度。” 虽然从技术上讲这是正确的,但这个答案过于宽泛,无法解决普里娅(Priya)的具体问题。
另一方面,智能体增强检索(我们刚刚实现的功能)则更深入。它首先检查所提供的数据以获取整个上下文,然后从知识库中提取有关电池优化的详细信息。接着,它会给出一个定制化的回复:“手机电池可能因为近期更新导致后台活动激增而耗电过快。启用省电模式并关闭未使用的应用程序,以优化电池续航。”
提供上述执行过程的日志。
We should analyze the user data provided to understand the context of the issue.
Action: UserContextAnalyzer
Action Input: {'recent_update': True, 'high_usage_hours': 10}{'recent_update': True, 'high_usage_hours': 10}Observation: Recent updates may cause temporary background activity spikes. This is a known issue.
Thought:We should provide the user with tips on battery optimization to help address the issue.
Action: KnowledgeBase
Action Input: battery_optimization_tips
Observation: To improve battery life, try enabling Battery Saver mode and closing unused apps.
Thought:The user should follow the battery optimization tips provided to improve battery life.
Final Answer: The phone's battery may be draining quickly due to recent updates causing background activity spikes. Enable Battery Saver mode and close unused apps to optimize battery life.> Finished chain.
The phone's battery may be draining quickly due to recent updates causing background activity spikes. Enable Battery Saver mode and close unused apps to optimize battery life.
智能体增强检索与生成(Agentic RAG)与传统检索与生成(Traditional RAG)的对比分析
虽然智能体增强检索生成(Agentic RAG)和传统检索生成(RAG)都旨在用外部知识增强大语言模型(LLMs),但它们在方法和能力上存在显著差异。以下是对它们主要区别的深入探讨:
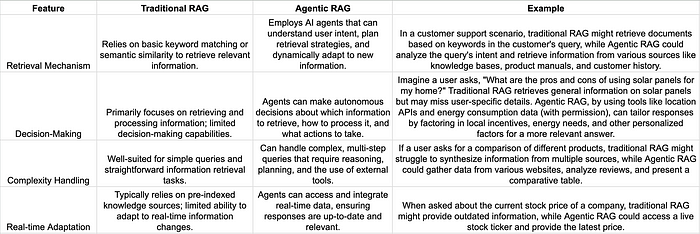
以截图作为媒介并不是制作表格的好方法
结论
智能体增强检索(Agentic RAG)是我们利用外部知识增强大语言模型方式的范式转变。它突破了传统增强检索(RAG)的局限,为创建能够更好地理解、推理信息并据此采取行动的人工智能系统开辟了新的可能性。这对从客户服务、内容创作到研究和决策等各个领域都具有重要意义。