51c自动驾驶~合集59
我自己的原文哦~ https://blog.51cto.com/whaosoft/13977368
#从图像生成到端到端轨迹规划
一、 扩散模型原理
扩散模型Diffusion Models是一种生成式模型,本质是去噪,噪音符合某种特定分布。其原理基于对数据分布的学习和模拟,主要包括正向扩散过程和反向生成过程。
其名字来源于一滴墨水滴进清水,以随机运动的方式弥散到清水乃至于彻底消融。
扩散模型学习这个弥散过程,目的是把融化进清水(纯噪音)里面的墨水(原始数据)恢复出来。
模型训练好后,给定一杯滴了墨水的清水,变魔术一般恢复出原始的墨水。这里的魔术只是某种学习了分布规律的神经网络。
正向扩散过程
从初始数据分布(如真实图像分布)开始,逐步向数据中添加噪声,这个过程遵循一个马尔可夫链。在每一步,根据前一步的状态和一个固定的噪声分布,生成下一个更具噪声的数据点。随着时间步的增加,数据逐渐变得更像噪声,最终达到一个近似纯噪声分布。
反向生成过程
从纯噪声开始,通过学习一个逆过程来逐步去除噪声,以恢复出原始数据。这个逆过程通过神经网络来参数化,网络的目标是根据当前带噪声的数据点和时间步,预测出前一个时间步的更接近原始数据的点。在训练过程中,通过最大化似然估计或其他损失函数来调整神经网络的参数,使得模型能够逐渐学会从噪声中生成真实的数据样本。
扩散模型通过正向扩散过程来定义数据的噪声化过程,然后通过反向生成过程来学习如何从噪声中恢复数据,从而实现对数据分布的建模和生成新的数据样本。
图 正向-反向diffusion过程,图片来自网络
马尔可夫链(Markov Chain)是一种具有马尔可夫性(无记忆性)的随机过程,描述系统在状态空间中随时间转移的规律。其核心特征是:未来状态的概率仅依赖于当前状态,与历史状态无关。所以马尔科夫性这个性质其实是个人为简化。
| 过程 | 公式 | 说明 |
| 正向单步 | ||
| 正向多步 | 累积噪声的线性组合 | |
| 反向单步 | 神经网络预测噪声驱动去噪,ϵ′ 为随机噪声 | |
| 损失函数 | 最小化预测噪声与真实噪声的均方差 |
扩散模型扩散过程每一层的概率分布类型通常是一样的,只是参数不一样。
在常见的扩散模型中,比如基于高斯分布假设的扩散模型,每一层(时间步)的条件概率分布通常都被建模为高斯分布。虽然不同层的均值和方差等参数会根据扩散过程而变化,但分布类型保持一致,这样的设定有助于模型的数学推导和计算。当然,也有一些扩散模型可能会采用其他类型的分布,如拉普拉斯分布等,在这种情况下,模型各层也会基于相同类型的分布来构建。
扩散模型(Diffusion Models)通常结合多种类型的神经网络来实现核心功能,包括去噪过程建模、概率分布学习和多尺度特征提取。其最常用的神经网络类型是u-net:
图 U-net架构图,来自网络
U-Net作为最核心架构,其结构特点完全是对称的,直观讲就是两个卷积神经网络尾对尾嫁接在一起。
编码器 - 解码器架构:编码器:通过卷积层逐步降低特征图分辨率,提取高层语义信息(如物体形状、纹理)。
解码器:通过上采样和跳跃连接恢复分辨率,将高层语义与低层细节结合。
跳跃连接:缓解深层网络的梯度消失问题,增强细节恢复能力。
其在扩散模型中的作用是作为去噪核心,功能是输入带噪声的图像和时间步长(表示噪声强度),输出去噪后的图像或预测噪声。
图像生成模型如 DALL-E 2、Stable Diffusion 均以U-Net 为骨干网络。
作为U-net的核心创新的跳跃连接,其思想非常类似resnet的残差链接,直接越过多层叠加。其操作是将编码器特征图Fi和解码器特征图Gj沿通道维度拼接,生成新的特征图 H。示例代码如下:
二、 扩散模型和生成对抗网络的对比
生成对抗网络(Generative Adversarial Networks,GANs) 是一种深度学习模型,由 生成器(Generator)和判别器(Discriminator)组成,通过两者的对抗博弈来学习数据分布并生成新样本。它于2014年由 Ian Goodfellow(就是人工智能花书的作者)等人提出,已广泛应用于图像生成、视频合成、数据增强等领域。
生成对抗网络和扩散模型都存在加噪和去噪过程,目的都是去噪。从输入输出角度看,二者有一定的可替换性。
目前并无文献表明二者谁更优。也有文献使用生成对抗网络来做自动驾驶的长尾场景生成。
生成对抗网络是在生成器的输入中加入噪声,可以使生成器更灵活地探索潜在空间,从而生成更加多样化的样本。
具体实现步骤如下:
- 在生成器的输入向量 ( z ) 中加入噪声。
- 噪声通常是从一个简单的分布(如标准正态分布 ( N(0, 1) ) 或均匀分布 ( U(-a, a) ))采样得到的。
图 生成对抗网络的加噪过程,来自网络
生成对抗网络(GAN)在自动驾驶领域的应用几乎和扩散模型重合,主要涵盖数据生成、场景仿真、感知增强和决策优化等方面。比如SurfelGAN(Google)利用激光雷达和摄像头数据生成逼真的相机图像,用于自动驾驶仿真模型训练。
扩散模型像"考古修复"(从碎片还原文物),GAN像"造假大师"(不断改进伪造技术)。
| 维度 | 扩散模型 | 生成对抗网络(GANs) |
| 核心机制 | 基于正向扩散与逆向去噪的概率建模 | 基于生成器与判别器的对抗博弈 |
| 训练方式 | 非对抗训练,仅需优化单一神经网络 | 对抗训练,需同时优化生成器和判别器 |
| 稳定性 | 训练更稳定,不易出现模式崩溃 | 训练难度高,易因梯度消失或模式崩溃失败 |
| 样本质量 | 生成图像通常更清晰、多样性更强(尤其高分辨率) | 早期 GANs 在高分辨率下可能出现模糊,需改进架构(如 StyleGAN) |
| 计算成本 | 训练和生成需多步迭代,计算复杂度高 | 生成阶段仅需单次前向传播,速度快 |
| 理论基础 | 基于热力学扩散过程和变分推断 | 基于博弈论和概率分布匹配 |
| 数学工具 | 随机微分方程(SDE)、马尔可夫链 | 概率分布散度(如 JS 散度、Wasserstein 距离) |
目前看扩散模型似乎比生成对抗网络更受欢迎,一个原因是生成对抗网络需要训练至少两个神经网络:生成器和判别器,计算量很大,训练好的模型体积也大。
但是生成对抗网络也有优势,就是其加噪过程往往融合多种分布类型的噪音,叠加的噪音更复杂;而不像基于马尔可夫链加噪的扩散模型,噪音分布类型在一般情况下不变,只是变化分布参数。
三、 扩散模型在自动驾驶领域的应用
扩散模型由于其去噪的本质,在自动驾驶领域的应用主要集中在数据生成、场景预测、感知增强和路径规划等方面。需要说明,扩散模型不仅可以用来对连续分布噪音进行去噪,也可以对离散分布噪音(和数据)去噪,所以它也可以用于离散问题,比如决策规划。
以下是具体的应用场景和技术优势:
1. 合成数据生成
扩散模型能够生成高度逼真的驾驶场景数据,解决真实数据不足或标注成本高的问题。
罕见场景生成,如极端天气(暴雨、大雾)、突发障碍物(行人横穿、车辆逆行)等,提升模型的泛化能力。
而且这种生成是可控的,通过条件控制(如BEV布局、3D标注)生成特定场景,例如NuScenes和KITTI数据集的扩展。
比如SynDiff-AD,基于潜在扩散模型的数据生成pipeline,显著提升模型在低光照、极端天气等条件下的性能。
2. 场景预测与视频生成
扩散模型可用于预测未来驾驶场景的动态变化,
包括多模态预测,也就是生成可能的交通参与者行为(如车辆变道、行人轨迹),支持决策系统。还有视频生成,比如DriveGenVLM结合视觉语言模型(VLMs)生成真实驾驶视频,用于仿真测试。
3. 感知任务优化
扩散模型在感知任务中可去除噪声并增强数据质量:
BEV去噪:利用扩散模型清理鸟瞰图(BEV)中的噪声,提升目标检测精度。
多传感器融合:生成一致的雷达与摄像头数据,改善感知鲁棒性。
4. 路径规划与决策
扩散模型通过概率建模支持多模态路径生成:
Diffusion Planner:清华AIR团队提出的规划算法,利用扩散模型的引导机制适应复杂路况,提升安全性和泛化能力。
实时端到端控制:DiffusionDrive通过截断扩散步骤实现实时决策,直接从人类驾驶数据学习。
其中所谓截断扩散就是跳跃性地去噪,本来去噪要像加噪过程一样经过多步打磨,现在则是直接越过几步,去噪时通过采样来模拟多步加噪的叠加分布,至于越过几步为好则是调参的艺术。
5. 端到端自动驾驶
扩散模型直接学习驾驶策略,简化传统模块化流程。
比如动作分布建模,也就是处理多模式驾驶行为(如避障或变道),避免传统方法的单一输出限制。
6. 小众应用
除了直接用于自动驾驶的扩散模型,还可以用于优化算法(也就是求最大或最小值),从而间接服务于自动驾驶。
自动驾驶有许多最小化优化问题,比如最小能量消耗路径,在商用车重卡领域用的非常多。其目标函数是:
其中F函数式车辆在速度vi下的单位距离能耗。
而Diffusion-ES(Diffusion Evolution Strategy) 是一种将扩散模型(Diffusion Model)与进化策略(Evolution Strategy, ES)相结合的优化算法,旨在利用扩散模型强大的生成能力和进化策略的全局搜索能力,高效求解复杂优化问题,比如上面的最小能量消耗路径求解。
技术优势总结
| 应用方向 | 技术优势 | 典型案例 |
| 合成数据生成 | 解决数据稀缺,支持可控生成 | SynDiff-AD 、ControlNet |
| 场景预测 | 多模态未来帧生成,动态适应性 | DriveGenVLM |
| 感知优化 | BEV去噪、多传感器一致性 | BEV-Guided Diffusion |
| 路径规划 | 多模态路径生成,高泛化能力 | Diffusion Planner |
| 端到端控制 | 实时性高,直接学习人类策略 | DiffusionDrive |
四、总结
扩散模型在自动驾驶中的应用仍处于快速发展阶段,未来可能与BEV、大语言模型(LLMs)进一步结合,推动全栈技术革新。
业界和学术多有基于扩散模型的技术方案,本文更偏重企业方案,列举三个:
毫末智行在2025 年 1 月 28 日,毫末智行联合清华大学 AIR 智能产业研究院等机构在 ICLR 2025 上发布了 Diffusion Planner。该算法基于 Diffusion Transformer,能高效处理复杂场景输入,联合建模周车运动预测与自车规划中的多模态驾驶行为。通过扩散模型强大的数据分布拟合能力,精准捕捉复杂场景中周车与自车的多模态驾驶行为,实现周车预测与自车规划的联合建模。在大规模真实数据集 nuPlan 的闭环评估中取得 SOTA 级表现,大幅降低了对后处理的依赖,并在 200 小时物流小车数据上验证了多种驾驶风格下的鲁棒性和迁移能力。目前,毫末团队已进入实车测试阶段,率先实现端到端方案在末端物流自动配送场景的应用落地。
地平线与香港大学等团队提出了 HE - Drive,这是首个以类人驾驶为核心的端到端自动驾驶系统。该系统利用稀疏感知技术生成三维空间表示,作为条件输入到基于条件去噪扩散概率模型(DDPM)的运动规划器中,生成具备时间一致性的多模态轨迹。然后,基于视觉语言模型引导的轨迹评分器从候选轨迹中选择最舒适的轨迹来控制车辆。HE - Drive 在 nuScenes 和 OpenScene 数据集上实现了 SOTA 性能和效率,同时在真实世界数据中提供了更舒适的驾驶体验。
理想汽车在 2025 年推出的下一代自动驾驶架构 MindVLA,整合了空间智能、语言智能和行为智能。该技术基于端到端和 VLM 双系统架构,通过 3D 空间编码器和逻辑推理生成合理的驾驶决策,并利用扩散模型优化驾驶轨迹。MindVLA 采用 3D 高斯作为中间表征,利用海量数据进行自监督训练,其 LLM 基座模型采用 MoE 混合专家架构和稀疏注意力技术。通过 Diffusion 模型将动作词元解码为优化轨迹,并结合自车行为生成和他车轨迹预测,提升复杂交通环境中的博弈能力。
最后,本文列举一个有代表意义的学术方案。
在2024年机器人顶会 CoRL 上,《One Model to Drift Them All: Physics-Informed Conditional Diffusion Model for Driving at the Limits》一文的作者们Franck Djeumou等提出利用包含多种车辆在多样环境下行驶轨迹的未标记数据集,训练一个高性能车辆控制的条件扩散模型。条件扩散模型(Conditional Diffusion Models, CDMs)是一类基于扩散过程的生成模型,在生成过程中引入了额外的条件信息,从而能够生成更为符合特定需求的样本,例如生成符合特定文本描述、类别标签或其他先验信息的图像。
这里的drift就是头文字D里面的飘移,在极限情况下的飘移动作(横向滑动),该模型能通过基于物理信息的数据驱动动态模型的参数多模态分布,捕捉复杂数据集中的轨迹分布。通过将在线测量数据作为生成过程的条件,将扩散模型融入实时模型预测控制框架中,用于极限驾驶。据报道,在丰田 Supra 和雷克萨斯 LC 500 上的实验表明,单一扩散模型可使两辆车在不同路况下使用不同轮胎时实现可靠的自动漂移,在对未知条件的泛化方面优于专家模型。
#VLA模型
元戎启行周光:携手火山引擎,基于豆包大模型打造物理世界Agent
2025年6月11日,元戎启行CEO周光受邀出席2025年火山引擎Force原动力大会,宣布元戎启行将携手火山引擎,基于豆包大模型,共同研发VLA等前瞻技术,打造物理世界的Agent。同时,周光宣布元戎启行的VLA模型将于2025年第三季度推向消费者市场,并展示了VLA模型的四大功能——空间语义理解、异形障碍物识别、文字类引导牌理解、语音控车,功能将随量产逐步释放。
元戎启行CEO周光
周光:“VLA的四大核心功能,相当于为AI汽车增加‘透视眼’‘百事通’‘翻译官’‘应答灵’等属性,让AI汽车更全面地了解驾驶环境,准确预测潜在驾驶危险因素,显著提升辅助驾驶的安全性。”
空间语义理解:驾驶“透视眼”
VLA模型能够全维度解构驾驶环境,精准破解桥洞通行、公交车遮挡视野等动静态驾驶盲区场景驾驶风险。
例如,在通过无红绿灯的路口时,VLA模型能提前识别到“注意横穿,减速慢行”的指示牌,即使公交车通行造成动态盲区,VLA也会结合公交车的动作去做出准确的决策。当公交车进行减速时,它会通过推理前方可能有行人穿行,并做出“立即减速、注意风险、谨慎通行”的决策。
,时长00:16
公交车动态盲区遮挡
异形障碍物识别:驾驶“百事通”
vla模型是一个超级学霸,它通过互联网迅速获取知识并转换成自己的经验,有自己的驾驶“知识库”,对驾驶过程中出现的各类障碍物了如指掌,准确判断潜在危险因素,行驶更安全。例如,VLA模型能够识别“变形”的超载小货车,结合实际路况,执行减速绕行或靠边驾驶。
,时长00:16
异形障碍物识别
文字引导牌理解:驾驶“翻译官”
搭载VLA模型的AI 汽车不仅能 “看见” 道路标识,更能 “读懂” 文字背后的通行规则,解析复杂路况里蕴含的路况信息,让复杂路况决策如 “开卷考试” 般从容。面对左转待行区、可变车道、潮汐车道等 “动态规则路段”,VLA模型能够读懂字符与图标的含义,高效匹配实时路况。在多车道复杂路口选道直行的场景中,能够准确识别车辆前方的文字及图案标识牌,从左转右转混杂的路口准确找到左转车道,并执行操作。
,时长00:14
特殊路标识别
语音交互控车:驾驶“应答灵”
通过VLA模型,AI汽车可以与用户高效交流,根据语音指令做出对应的驾驶决策,随叫随应,交互更拟人,体验更舒适。并且当用户意愿与导航信息相冲突时,VLA模型会优先采纳用户意愿。

语音控车指令
目前,元戎启行已完成VLA模型的真实道路测试,预计今年将有超5款搭载元戎启行VLA模型的AI汽车陆续推入市场。其中,VLA模型支持激光雷达方案与纯视觉方案,将率先搭载在NVIDIA Drive Thor芯片上,后续元戎启行还将通过技术优化,让VLA模型可以适配更多芯片平台。
火山引擎汽车总经理、智慧出行和具身研究院院长杨立伟表示:“元戎启行作为业内率先推出VLA模型的企业之一,对人工智能的理解极为深刻。火山引擎作为行业领先的云服务提供商,在云计算领域拥有深厚的技术实力和丰富的经验。我们非常期待与元戎启行携手合作,共同推动基于豆包大模型的物理世界Agent的落地应用,助力智慧出行领域的创新发展。”
周光强调:“VLA模型作为当下最先进的AI技术,可以连接视觉、语言、动作等多种模态,打通物理世界与数字世界的壁垒,具有完善的任务规划和执行能力,是实现物理世界 agent 的关键技术。元戎启行很高兴能够与火山引擎达成合作,基于VLA模型共同打造物理世界的Agent,让双方的先进技术在物理世界的各个领域落地,推动生产力进阶。”
#理想司机Agent的一些细节
整体评价: 基于司机Agent 这个产品定义主要专注于 封闭园区/地下车库场景下的多模态信息融合感知输出决策。
产品整体定义,细节都是做的很完善了。
举几个细节点:
1️⃣: 首先Agent 产品已经全模型化输出轨迹,除了部分兜底还会有少量的规则。因此和过去的AVP产品体验完全不一样。最为直观的感受就是你感觉到在园区/地下车库 AD Max 自己开车和人类司机开车体验几乎无差异
【当然还是没有人类老司机开得好】。
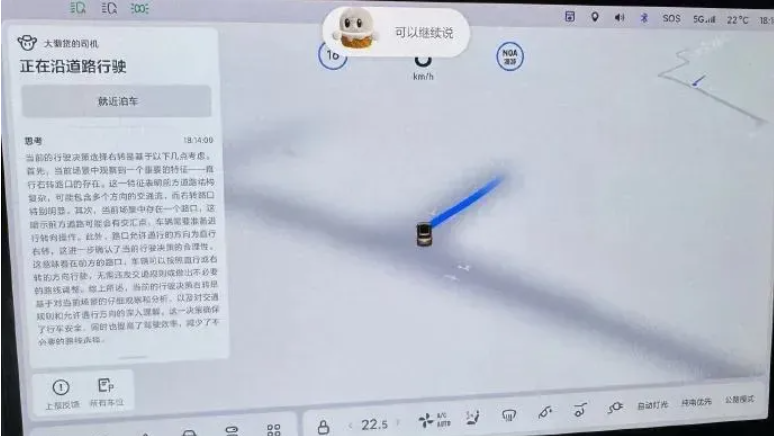
2️⃣:基于2D/3D 信息编码整合进模型后,Agent 具备理解道路标牌【例如,出口,上下坡道,左右转,电梯口,不允许通行,区域B12345,ABCDEFGG区 etc】的能力,和语音交互感知【左右转,靠边停车,掉个头,快点慢点,甚至给出先去A区再靠边,或者掉头后再去C区】的能力。简单指令场景依赖的是本地的多模态LLM,复杂指令是Token化后上云大参量的LLM,将任务拆解后转换成顺序任务后在本地LLM执行。
3️⃣:具备自建关联点的能力【我这里为什么不说建地图而是建关联点】有就几个原因:首先更多的是行车的关联结构,而并非记忆了精准的道路结构。因此车辆在调用这个关联点记忆很像人在地下车库开车【大概要往哪个地方开,而并非是像Hd map 具有严格的驾驶轨迹限定】,换句话说,关联点建好后。理论上,给Agent 需求后,会直接进行关联点分析,规划出一条最近的【可以符合通行逻辑】的地下/园区驾驶轨迹。 当然现在他能力还有限,还是偶尔会出现开错路,然后触发掉头再开【对因为行车模型化后,理论上可以触发无限制掉头,几乎不会卡死】
4️⃣:具备感知推理能力,而且怀疑整个AD Max Agent 场景是将行车感知摄像头和泊车【鱼眼】感知摄像头对齐后输入到模型里面。甚至还前融合了激光雷达的数据。
基本可以做到全向规则/不规则的环境感知能力。
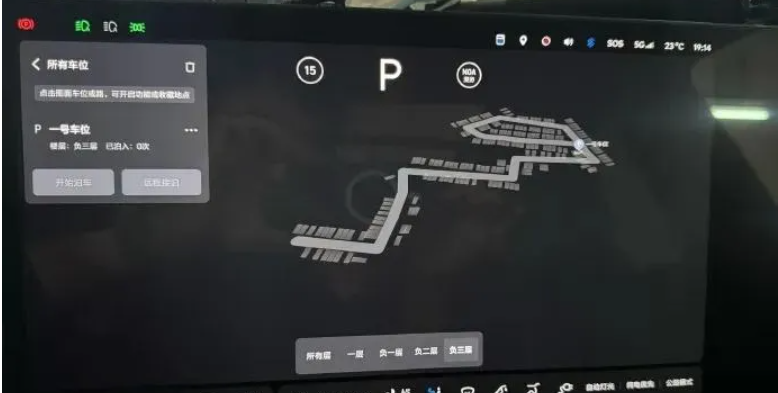
考虑到业内发展态势如此之快。从个人体验角度来看,我觉得AD Max 司机Agent 和 NIO AD 的NWM。
是目前唯二,将多模态感知信息整合到一个模型里实现复杂推理的应用场景。
NWM大家已经看到大量实测视频,地下寻路能力非常不错,而且多模态感知能力也非常好。
司机Agent。截至目前释放的范围:
1️⃣:多模态感知+语音交互;
2️⃣:地下车库收费杆感知,判断。衔接到封闭园区再到公开道路;
3️⃣:构建关联点记忆能力【第二次就不需要漫游出园区/地下车库】,直接可以跟着大概记忆走,记忆不对也会触发掉头,换路 etc。