高频面试之11Flink
11 Flink
文章目录
- 11 Flink
- 11.1 Flink基础架构组成?
- 11.2 Flink和Spark Streaming的区别?
- 11.3 Flink提交作业流程及核心概念
- 11.4 Flink的部署模式及区别?
- 11.5 Flink任务的并行度优先级设置?资源一般如何配置?
- 11.6 Flink的三种时间语义
- 11.7 你对Watermark的认识
- 11.8 Watermark多并行度下的传递、生成原理
- 11.9 Flink怎么处理乱序和迟到数据?
- 11.10 说说Flink中的窗口(分类、生命周期、触发、划分)
- 11.11 Flink的keyby怎么实现的分区?分区、分组的区别是什么?
- 11.12 Flink的Interval Join的实现原理?Join不上的怎么办?
- 11.13 介绍一下Flink的状态编程、状态机制?
- 11.14 Flink如何实现端到端一致性?
- 11.15 Flink分布式快照的原理是什么
- 11.16 Checkpoint的参数怎么设置的?
- 11.17 Flink内存模型(重点)
- 11.18 Flink常见的维表Join方案
- 11.19 FlinkCDC锁表问题
11.1 Flink基础架构组成?
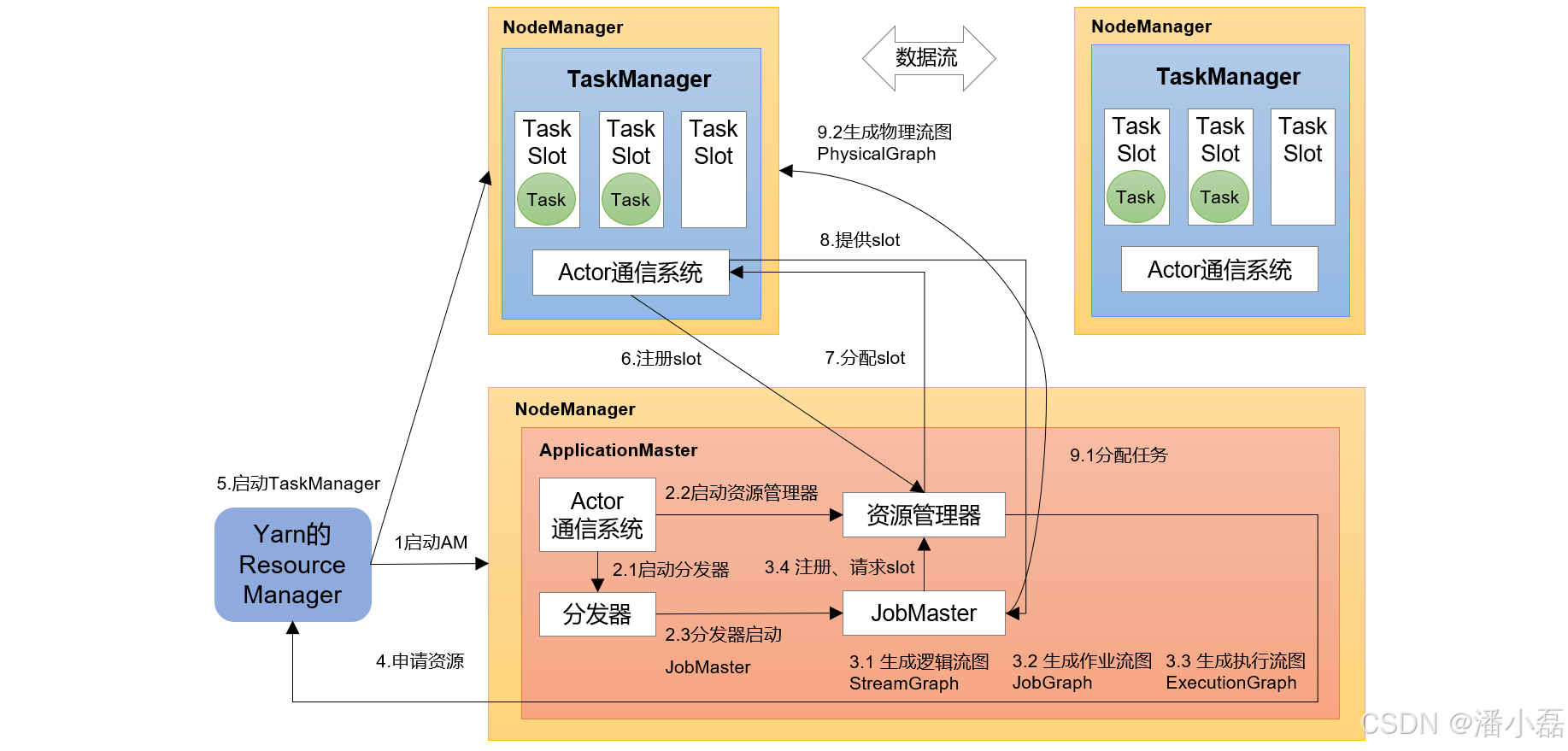
Flink程序在运行时主要有TaskManager,JobManager,Client三种角色。
JobManager是集群的老大,负责接收Flink Job,协调检查点,Failover 故障恢复等,同时管理TaskManager。 包含:Dispatcher、ResourceManager、JobMaster。
TaskManager是执行计算的节点,每个TaskManager负责管理其所在节点上的资源信息,如内存、磁盘、网络。内部划分slot隔离内存,不隔离cpu。同一个slot共享组的不同算子的subtask可以共享slot。
Client是Flink程序提交的客户端,将Flink Job提交给JobManager。
11.2 Flink和Spark Streaming的区别?
| Flink | Spark Streaming | |
|---|---|---|
| 计算模型 | 流计算 | 微批次 |
| 时间语义 | 三种 | 没有,处理时间 |
| 乱序 | 有 | 没有 |
| 窗口 | 多、灵活 | 少、不灵活(窗口长度必须是 批次的整数倍) |
| checkpoint | 异步分界线快照 | 弱 |
| 状态 | 有,多 | 没有(updatestatebykey) |
| 流式sql | 有 | 没有 |
11.3 Flink提交作业流程及核心概念
1)Flink提交流程(Yarn-Per-Job)
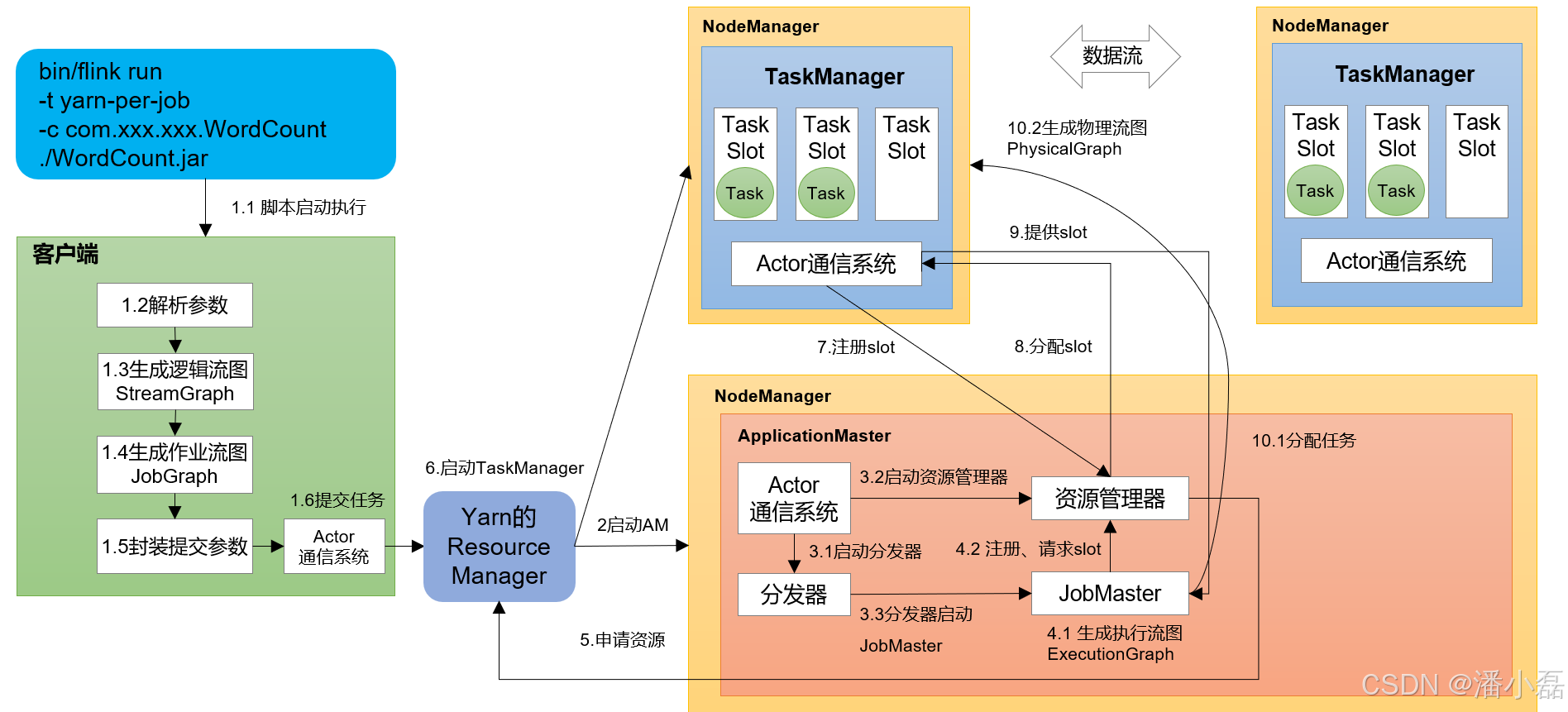
2)算子链路:Operator Chain
Flink自动做的优化,要求One-to-one,并行度相同。
代码disableOperatorChaining()禁用算子链。
3)Graph生成与传递
| 在哪里生成 | 传递给谁 | 做了什么事 | |
|---|---|---|---|
| 逻辑流图StreamGraph | Client | Client | 最初的DAG图 |
| 作业流图JobGraph | Client | JobManager | JobManager |
| 执行流图ExecutionGraph | JobManager | JobManager | 并行度的细化 |
4)Task、Subtask的区别
Subtask:算子的一个并行实例。
Task:Subtask运行起来之后,就叫Task。
5)并行度和Slot的关系
Slot是静态的概念,是指TaskMangaer具有的并发执行能力。
并行度是动态的概念,指程序运行时实际使用的并发能力。
设置合适的并行度能提高运算效率,太多太少都不合适。
6)Slot共享组了解吗,如何独享Slot插槽
默认共享组时default,同一共享组的task可以共享Slot。
通过slotSharingGroup()设置共享组。
11.4 Flink的部署模式及区别?
1)Local:本地模式,Flink作业在单个JVM进程中运行,适用于测试阶段
2)Standalone:Flink作业在一个专门的Flink集群上运行,独立模式不依赖于其他集群管理器(Yarn或者Kubernetes)
3)Yarn:
Per-job:独享资源,代码解析在Client
Application:独享资源,代码解析在JobMaster
Session:共享资源,一套集群多个job
4)K8s:支持云原生,未来的趋势
5)Mesos:国外使用,仅作了解
11.5 Flink任务的并行度优先级设置?资源一般如何配置?
设置并行度有多种方式,优先级:算子 > 全局Env > 提交命令行 > 配置文件
1)并行度根据任务设置:
(1)常规任务:Source,Transform,Sink算子都与Kafka分区保持一致
(2)计算偏大任务:Source,Sink算子与Kafka分区保持一致,Transform算子可设置成2的n次方,64,128…
2)资源设置:通用经验 1CU = 1CPU + 4G内存
Taskmanager的Slot数:1拖1(独享资源)、1拖N(节省资源,减少网络传输)
TaskManager的内存数:4~8G
TaskManager的CPU:Flink默认一个Slot分配一个CPU
JobManager的内存:2~4G
JobManager的CPU:默认是1
3)资源是否足够:
资源设置,然后压测,看每个并行度处理上限,是否会出现反压
例如:每个并行度处理5000/s,开始出现反压,比如我们设置三个并行度,我们程序处理上限15000/s
11.6 Flink的三种时间语义
事件时间Event Time:是事件创建的时间。数据本身携带的时间。
进入时间Ingestion Time:是数据进入Flink的时间。
处理时间Processing Time:是每一个执行基于时间操作的算子的本地系统时间,与机器相关,默认的时间属性就是Processing Time。
11.7 你对Watermark的认识
水位线是Flink流处理中保证结果正确性的核心机制,它往往会跟窗口一起配合,完成对乱序数据的正确处理。
💿水位线是插入到数据流中的一个标记,可以认为是一个特殊的数据
💿水位线主要的内容是一个时间戳,用来表示当前事件时间的进展
💿水位线是基于数据的时间戳生成的
💿水位线的时间戳必须单调递增,以确保任务的事件时间时钟一直向前推进
💿水位线可以通过设置延迟,来保证正确处理乱序数据
💿一个水位线Watermark(t),表示在当前流中事件时间已经达到了时间戳t,这代表t之前的所有数据都到齐了,之后流中不会出现时间戳t’ ≤ t的数据
11.8 Watermark多并行度下的传递、生成原理
1)分类:
间歇性:来一条数据,更新一次Watermark。
周期性:固定周期更新Watermark。
官方提供的API是基于周期的,默认200ms,因为间歇性会给系统带来压力。
2)生成原理:
Watermark = 当前最大事件时间 - 乱序时间 - 1ms
3)传递:
Watermark是一条携带时间戳的特殊数据,从代码指定生成的位置,插入到流里面。
一对多:广播。
多对一:取最小。
多对多:拆分来看,其实就是上面两种的结合。
11.9 Flink怎么处理乱序和迟到数据?
在Apache Flink中,迟到时间(lateness)和乱序时间(out-of-orderness)是两个与处理时间和事件时间相关的概念。它们在流处理过程中,尤其是在处理不按事件时间排序的数据时非常重要。
(1)迟到时间(lateness):迟到时间可以影响窗口,在窗口计算完成后,仍然可以接收迟到的数据
迟到时间是指事件到达流处理系统的延迟时间,即事件的实际接收时间与其事件时间的差值。在某些场景下,由于网络延迟、系统故障等原因,事件可能会延迟到达。为了处理这些迟到的事件,Flink提供了一种机制,允许在窗口计算完成后仍然接受迟到的数据。设置迟到时间后,Flink会在窗口关闭之后再等待一段时间,以便接收并处理这些迟到的事件。
设置迟到时间的方法如下:
在定义窗口时,使用allowedLateness方法设置迟到时间。例如,设置迟到时间为10分钟:
DataStream<T> input = ...;
input
.keyBy(<key selector>)
.window(<window assigner>)
.allowedLateness(Time.minutes(10))
.<window function>;
(2)乱序时间(out-of-orderness)
乱序时间是通过影响水印来影响数据的摄入,它表示的是数据的混乱程度。
乱序时间是指事件在流中不按照事件时间的顺序到达。在某些场景下,由于网络延迟或数据源的特性,事件可能会乱序到达。
Flink提供了处理乱序事件的方法,即水位线(watermark)。
水位线是一种表示事件时间进展的机制,它告诉系统当前处理到哪个事件时间。
当水位线到达某个值时,说明所有时间戳小于该值的事件都已经处理完成。
为了处理乱序事件,可以为水位线设置一个固定的延迟。
设置乱序时间的方法如下:
在定义数据源时,使用assignTimestampsAndWatermarks方法设置水位线策略。例如,设置水位线延迟为5秒:
DataStream<T> input = env.addSource(<source>);
input
.assignTimestampsAndWatermarks(WatermarkStrategy.<T>forBoundedOutOfOrderness(Duration.ofSeconds(5)).withTimestampAssigner(<timestamp assigner>))
.<other operations>;
11.10 说说Flink中的窗口(分类、生命周期、触发、划分)
1)窗口分类:
Keyed Window和Non-keyed Window
基于时间:滚动、滑动、会话。
基于数量:滚动、滑动。
2)Window口的4个相关重要组件:
assigner(分配器):如何将元素分配给窗口。
function(计算函数):为窗口定义的计算。其实是一个计算函数,完成窗口内容的计算。
triger(触发器):在什么条件下触发窗口的计算。
可以使用自定义触发器,解决事件时间,没有数据到达,窗口不触发计算问题,还可以使用持续性触发器,实现一个窗口多次触发输出结果,详细看连接
问题展示:https://www.bilibili.com/video/BV1Gv4y1H7F8/?spm_id_from=333.999.0.0&vd_source=891aa1a363111d4914eb12ace2e039af
问题解决:https://www.bilibili.com/video/BV1mM411N7uP/?spm_id_from=333.999.0.0&vd_source=891aa1a363111d4914eb12ace2e039af
evictor(退出器):定义从窗口中移除数据。
3)窗口的划分:如,基于事件时间的滚动窗口
Start = 按照数据的事件时间向下取窗口长度的整数倍。
end = start + size
比如开了一个10s的滚动窗口,第一条数据是857s,那么它属于[850s,860s)。
4)窗口的创建:当属于某个窗口的第一个元素到达,Flink就会创建一个窗口,并且放入单例集合
5)窗口的销毁:时间进展 >= 窗口最大时间戳 + 窗口允许延迟时间
(Flink保证只删除基于时间的窗口,而不能删除其他类型的窗口,例如全局窗口)。
6)窗口为什么左闭右开:属于窗口的最大时间戳 = end - 1ms
7)窗口什么时候触发:如基于事件时间的窗口 watermark >= end - 1ms
11.11 Flink的keyby怎么实现的分区?分区、分组的区别是什么?
分组和分区在 Flink 中具有不同的含义和作用:
分区:分区(Partitioning)是将数据流划分为多个子集,这些子集可以在不同的任务实例上进行处理,以实现数据的并行处理。
数据具体去往哪个分区,是通过指定的 key 值先进行一次 hash 再进行一次 murmurHash,通过上述计算得到的值再与并行度进行相应的计算得到。
分组:分组(Grouping)是将具有相同键值的数据元素归类到一起,以便进行后续操作(如聚合、窗口计算等)。key 值相同的数据将进入同一个分组中。
注意:数据如果具有相同的 key 将一定去往同一个分组和分区,但是同一分区中的数据不一定属于同一组。
11.12 Flink的Interval Join的实现原理?Join不上的怎么办?
底层调用的是keyby + connect ,处理逻辑:
(1)判断是否迟到(迟到就不处理了,直接return)
(2)每条流都存了一个Map类型的状态(key是时间戳,value是List存数据)
(3)任一条流,来了一条数据,遍历对方的map状态,能匹配上就发往join方法
(4)使用定时器,超过有效时间范围,会删除对应Map中的数据(不是clear,是remove)
Interval join不会处理join不上的数据,如果需要没join上的数据,可以用 coGroup+join算子实现,或者直接使用flinksql里的left join或right join语法。
11.13 介绍一下Flink的状态编程、状态机制?
(1)算子状态:作用范围是算子,算子的多个并行实例各自维护一个状态
(2)键控状态:每个分组维护一个状态
(3)状态后端:两件事=》 本地状态存哪里、checkpoint存哪里
1.13版本之前
本地状态 Checkpoint
内存 TaskManager的内存 JobManager内存
文件 TaskManager的内存 HDFS
RocksDB RocksDB HDFS
1.13版本之后
本地状态
Hashmap() TaskManager的内存
RocksDB RocksDB
Checkpoint存储 参数指定
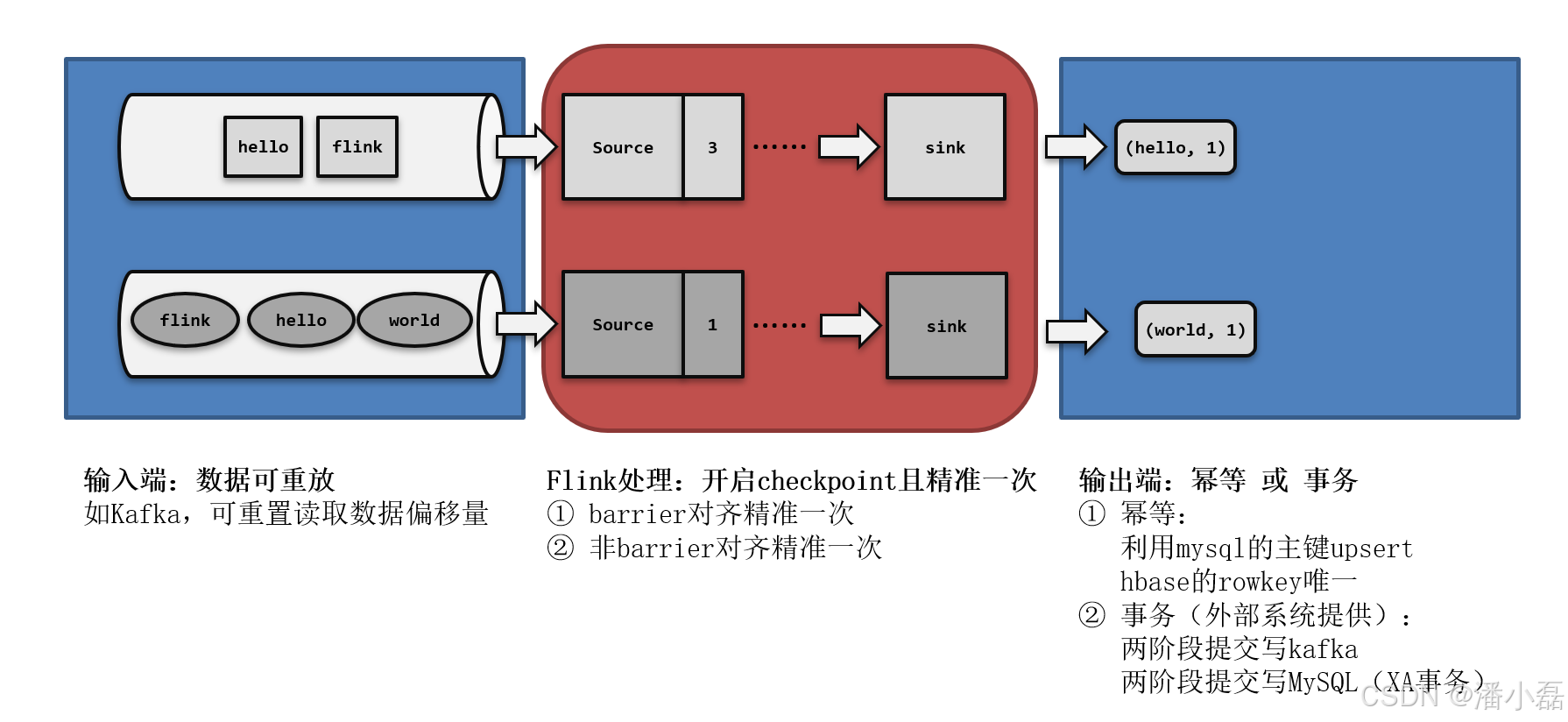
11.14 Flink如何实现端到端一致性?
11.15 Flink分布式快照的原理是什么
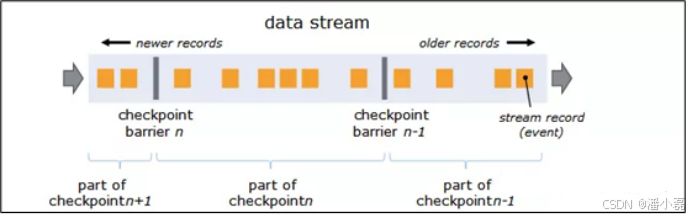
barriers在数据流源处被注入并行数据流中。快照n的barriers被插入的位置(我们称之为Sn)是快照所包含的数据在数据源中最大位置。
例如,在Kafka中,此位置将是分区中最后一条记录的偏移量。 将该位置Sn报告给checkpoint协调器(Flink的JobManager)。
然后barriers向下游流动。当一个中间操作算子从其所有输入流中收到快照n的barriers时,它会为快照n发出barriers进入其所有输出流中。
一旦Sink操作算子(流式DAG的末端)从其所有输入流接收到barriers n,它就向Checkpoint协调器确认快照n完成。
在所有Sink确认快照后,意味快照着已完成。一旦完成快照n,Job将永远不再向数据源请求Sn之前的记录,因为此时这些记录(及其后续记录)将已经通过整个数据流拓扑,也即是已经被处理结束。
11.16 Checkpoint的参数怎么设置的?
(1)间隔:兼顾性能和延迟,一般任务设置分钟级(1~5min),要求延迟低的设置秒级
(2)Task重启策略(Failover):
固定延迟重启策略:重试几次、每次间隔多久。
失败率重启策略:重试次数、重试区间、重试间隔。
无重启策略:一般在开发测试时使用。
Fallback重启策略:默认固定延迟重启策略。
11.17 Flink内存模型(重点)

11.18 Flink常见的维表Join方案
(1)预加载:open()方法,查询维表,存储下来 ==》 定时查询
(2)热存储:存在外部系统Redis、HBase等
(3)广播维表
(4)Lookup Join:外部存储,connector创建,SQL用法
11.19 FlinkCDC锁表问题
(1)FlinkCDC 1.x同步历史数据会锁表
设置参数不加锁,但只能保证至少一次。
(2)2.x 实现了无锁算法,同步历史数据的时候不会锁表
2.x在全量同步阶段可以多并行子任务同步,在增量阶段只能单并行子任务同步