yolo11学习笔记
文章目录
- yolov9
- 网络结构
- yolo系列, 以目标检测为例
- 代码
- 1.首先准备数据集,按照仓库要求的格式
- 2.训练方法
- 3.dataset处理流程
- 4. 训练
- 5.查看模型结构
- 6.detect loss
- 6.1 TaskAlignedAssigner
- 6.2 score loss
- 6.3 iou loss 和 dfl loss
- 6.4 dfl loss
- 6.5 完整的v8DetectionLoss
- 7. 推理后处理:得到(batch_size, min(max_det, anchors), 6)
yolov9
作者一直在说的是希望网络能够保留足够的信息做预测。
之前的方法包括利用残差,利用可逆函数,利用 dynamic binary mask(稀疏feature)
第二,信息肯定是丢失的,但是不要丢失和target相关的信息就好
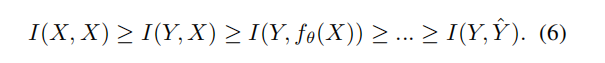
按照上图的路径丢失信息,是不影响预测的。
网络结构
(1)主分支,(2)辅助可逆分支,(3)多级辅助信息。
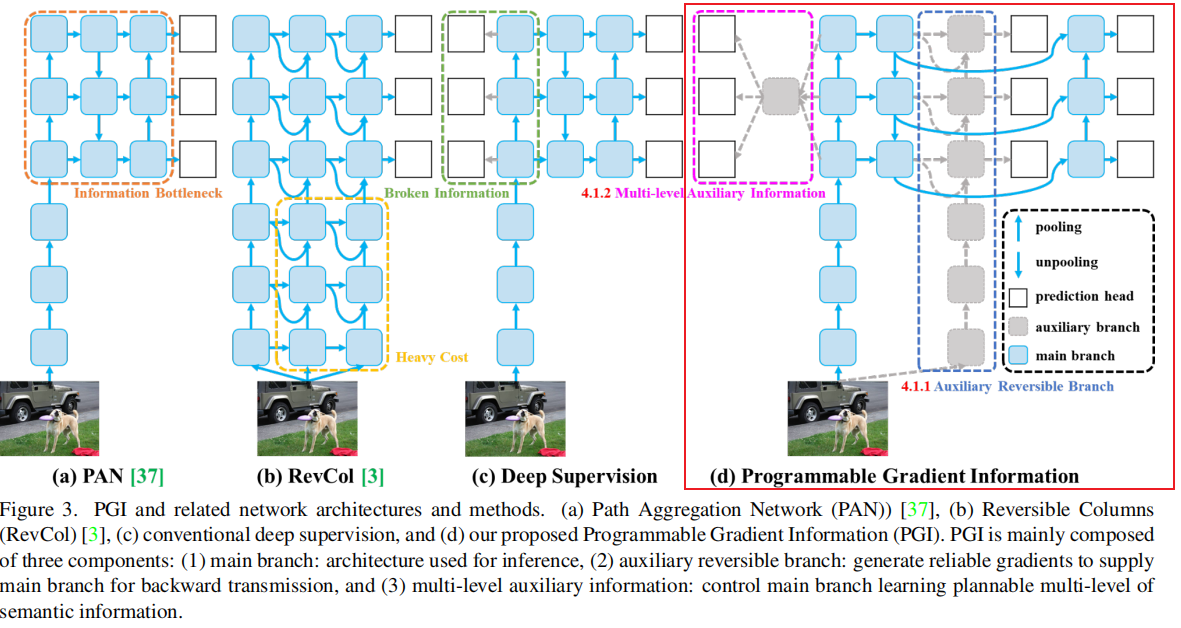
网络深,信息可能丢失。因此利用辅助分支进行监督,但是推理的时候只用主分支不增加复杂度。
多级辅助对不同的尺度或者金字塔特征层进行监督。
yolo系列, 以目标检测为例
代码
https://github.com/ultralytics
1.首先准备数据集,按照仓库要求的格式
有2种
一种是文件夹格式,3个文件夹train val test, 三个文件夹下有images和labels,分别是图像和对应的同名labels 标注文件。
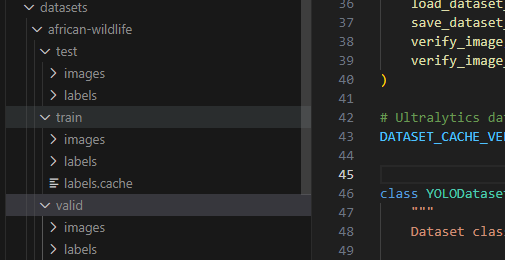
另一种是
文件列表格式
train.txt
val.txt
test.txt
里面存储图像文件路径
可以利用from ultralytics.data.split import autosplit函数生成txt文件
2.训练方法
from ultralytics import settingsfrom ultralytics import YOLO# Load a model
#model = YOLO("yolo11n.yaml") # build a new model from YAML
model = YOLO("./runs/detect/train2/weights/last.pt") # load a pretrained model (recommended for training)
#model = YOLO("yolo11n.yaml").load("yolo11n.pt") # build from YAML and transfer weights# Train the model
results = model.train(data="african-wildlife.yaml", epochs=10, imgsz=640,device = [0],patience=10, # Epochs to wait for no observable improvement for early stopping of training. default 100batch=8, # Number of images per batch. default 16, -1 for AutoBatch 60% GPU memory, 也可以指定batch=0.7表示使用70% GPU memoryoptimizer='AdamW', # Optimizer to use. default 'SGD', 'Adam' or 'AdamW' (Adam with weight decay)lr0=0.001, # Initial learning rate lrf=0.01, # Final learning rate (lr0 * lrf) after scheduler reaches max epochs. default 0.01close_mosaic=5, # 在训练完成前禁用最后 N 个epoch的马赛克数据增强以稳定训练workers=4, # Number of dataloader workers. default 8# hsv_h=0.015, #https://docs.ultralytics.com/zh/modes/train/#train-settings# hsv_s=0.7, # hsv_v=0.4, # degrees=180, # 旋转角度范围# translate=0.1, # 平移距离范围# scale=0.5, # 缩放比例范围# shear=0.0, # 错切角度范围# perspective=0.0, # 透视变换范围flipud=0.01, # 上下翻转概率fliplr=0.5, # 左右翻转概率mosaic=0.5, # 马赛克数据增强概率mixup=0.1, # 混合数据增强概率cutmix=0.1, # 随机裁剪数据增强概率resume=True, # 是否从上次训练中恢复)print('###################################################### Train Done ######################################################')
# Customize validation settings
metrics = model.val( data="african-wildlife.yaml",imgsz=640, batch=4, conf=0.25, # Confidence threshold for predictions模型预测的每个目标框(bounding box)的置信度分数(通常是目标存在的概率)必须大于该阈值,才会被保留下来作为有效检测结果iou=0.6, # iou 指的是非极大值抑制(NMS)中的 IoU 阈值,用于去除重叠度较高的冗余框。NMS 算法会对所有预测框按置信度排序,依次选出最大置信度的框,并去除与其 IoU 大于阈值的其他框。device="0",half=True, # 使用半精度浮点数进行计算,减少内存占用和计算时间plots=True, # 是否绘制验证结果图)
print('###################################################### Val Done ######################################################')
该仓库接口高度抽象,因此想了解具体步骤还是要跟着源码走一遍。
3.dataset处理流程
第一环节,我们准备了数据集文件夹
接下来通过ultralytics-main/ultralytics/data/base.py BaseDataset和 ultralytics-main/ultralytics/data/dataset.py YOLODataset
处理数据集
-
get_img_files(self, img_path): 返回 list of image file paths
-
get_labels 函数 返回List of label dictionaries
字典格式:{"im_file": im_file,"shape": shape,"cls": lb[:, 0:1], # n, 1"bboxes": lb[:, 1:], # n, 4"segments": segments,"keypoints": keypoint,"normalized": True,"bbox_format": "xywh",} -
矩形训练策略
self.rect = rect 位于 BaseDataset 类的 init 方法中
控制是否调用下面函数
batch_shapes返回每个batch设置的shape
batch返回每个图像的所属batch id
矩形训练是目标检测中用于提升训练效率的一种策略。传统训练方式会把所有输入图像调整为固定大小(如 640x640),这可能会引入大量填充区域,浪费计算资源。矩形训练会把同一批次的图像调整为合适的矩形尺寸,在保证长宽比的同时减少填充区域,从而提升训练效率。
当前版本默认在训练的时候不会被使用。 -
然后是build_transform 根据设置的超参数数据增强
def build_transforms(self, hyp=None):"""Builds and appends transforms to the list.Args:hyp (dict, optional): Hyperparameters for transforms.Returns:(Compose): Composed transforms."""if self.augment:hyp.mosaic = hyp.mosaic if self.augment and not self.rect else 0.0hyp.mixup = hyp.mixup if self.augment and not self.rect else 0.0hyp.cutmix = hyp.cutmix if self.augment and not self.rect else 0.0transforms = v8_transforms(self, self.imgsz, hyp)else:transforms = Compose([LetterBox(new_shape=(self.imgsz, self.imgsz), scaleup=False)])transforms.append(Format(bbox_format="xywh",normalize=True,return_mask=self.use_segments,return_keypoint=self.use_keypoints,return_obb=self.use_obb,batch_idx=True,mask_ratio=hyp.mask_ratio,mask_overlap=hyp.overlap_mask,bgr=hyp.bgr if self.augment else 0.0, # only affect training.))return transforms注意矩形训练 和 mosaic, mixup, cutmix数据增强不兼容。
然后v8_transforms是一系列数据增强
transforms = Compose([pre_transform,MixUp(dataset, pre_transform=pre_transform, p=hyp.mixup),CutMix(dataset, pre_transform=pre_transform, p=hyp.cutmix),Albumentations(p=1.0),RandomHSV(hgain=hyp.hsv_h, sgain=hyp.hsv_s, vgain=hyp.hsv_v),RandomFlip(direction="vertical", p=hyp.flipud),RandomFlip(direction="horizontal", p=hyp.fliplr, flip_idx=flip_idx),] )然后
transforms.append(Format(bbox_format="xywh",normalize=True,return_mask=self.use_segments,return_keypoint=self.use_keypoints,return_obb=self.use_obb,batch_idx=True,mask_ratio=hyp.mask_ratio,mask_overlap=hyp.overlap_mask,bgr=hyp.bgr if self.augment else 0.0, # only affect training.))经过以上,init基本完成
接着看__get_item__函数def __getitem__(self, index):"""Return transformed label information for given index."""return self.transforms(self.get_image_and_label(index))首先读取图像和resize,load image有一个参数rect_mode=True, 最长边resize到imgsz,短边等比例resize。 如果rect_mode=False,resize到imgsz*imgsz.
# load image有一个参数rect_mode=True, 最长边resize到imgsz,短边等比例resize。 如果rect_mode=False,resize到imgsz*imgsz label["img"], label["ori_shape"], label["resized_shape"] = self.load_image(index) # ratio_pad记录 resize比例, rect_shape记录刚才矩形训练得到的 batch shape label["ratio_pad"] = (label["resized_shape"][0] / label["ori_shape"][0],label["resized_shape"][1] / label["ori_shape"][1],) # for evaluation if self.rect:label["rect_shape"] = self.batch_shapes[self.batch[index]]然后调用transforms函数数据增强
具体做了哪些数据增强呢?根据超参数定义选择是否数据增强和增强参数。
数据增强的效果和原理可以在https://docs.ultralytics.com/zh/modes/train/#train-settings 查看然后经过Format类,主要是设置label bbox
Format(bbox_format="xywh",normalize=True,return_mask=self.use_segments,return_keypoint=self.use_keypoints,return_obb=self.use_obb,batch_idx=True,mask_ratio=hyp.mask_ratio,mask_overlap=hyp.overlap_mask,bgr=hyp.bgr if self.augment else 0.0, # only affect training.)最终得到的是label字典
4. 训练
ultralytics-main/ultralytics/models/yolo/detect/train.py
首先会初始化一些训练的配置_setup_train函数中
dataset, dataloader, optimizer之类的
接着dataset的数据流:会经过preprocess_batch函数
主要归一化和 是否多尺度训练(对图像进行随机缩放,训练的时候应该可以增加鲁棒性,感觉挺有用的,这里对图像缩放不需要改变bbox,因为bbox是归一化的)
# Forwardwith autocast(self.amp):batch = self.preprocess_batch(batch)loss, self.loss_items = self.model(batch)self.loss = loss.sum()if RANK != -1:self.loss *= world_sizeself.tloss = ((self.tloss * i + self.loss_items) / (i + 1) if self.tloss is not None else self.loss_items)# 再看preprocess_batch函数def preprocess_batch(self, batch):"""Preprocess a batch of images by scaling and converting to float.Args:batch (dict): Dictionary containing batch data with 'img' tensor.Returns:(dict): Preprocessed batch with normalized images."""batch["img"] = batch["img"].to(self.device, non_blocking=True).float() / 255if self.args.multi_scale:imgs = batch["img"]sz = (random.randrange(int(self.args.imgsz * 0.5), int(self.args.imgsz * 1.5 + self.stride))// self.stride* self.stride) # sizesf = sz / max(imgs.shape[2:]) # scale factorif sf != 1:ns = [math.ceil(x * sf / self.stride) * self.stride for x in imgs.shape[2:]] # new shape (stretched to gs-multiple)imgs = nn.functional.interpolate(imgs, size=ns, mode="bilinear", align_corners=False)batch["img"] = imgsreturn batch
接着就输入了model,从下图可知train和val的时候输入的是一个字典,包含img,bbox之类的数据。predict只传入一个图像即可
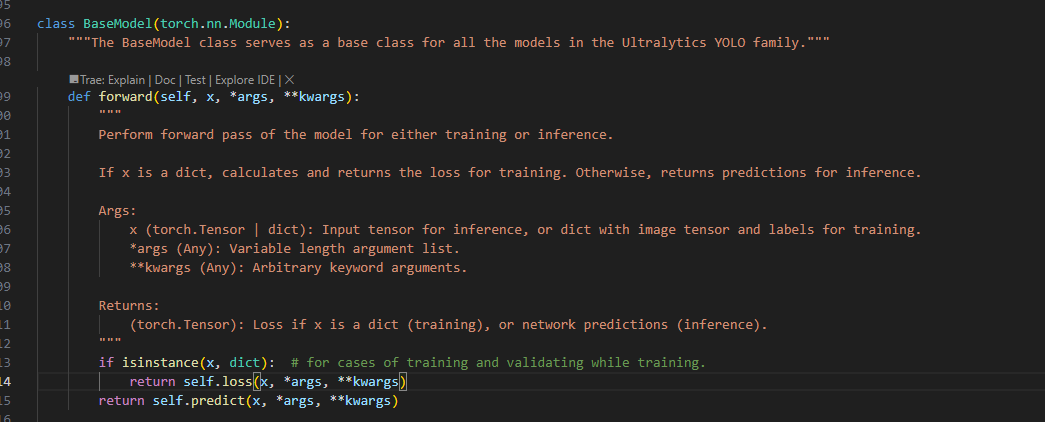
然后查看loss函数
def loss(self, batch, preds=None):"""Compute loss.Args:batch (dict): Batch to compute loss on.preds (torch.Tensor | List[torch.Tensor], optional): Predictions."""if getattr(self, "criterion", None) is None:self.criterion = self.init_criterion()preds = self.forward(batch["img"]) if preds is None else predsreturn self.criterion(preds, batch)
def init_criterion(self):"""Initialize the loss criterion for the DetectionModel."""return E2EDetectLoss(self) if getattr(self, "end2end", False) else v8DetectionLoss(self)
5.查看模型结构
导出onnx,然后通过netron查看结构, 模型架构的博客讲解也比较多。
from ultralytics import settingsfrom ultralytics import YOLO# Load a model
#model = YOLO("yolo11n.yaml") # build a new model from YAML
model = YOLO("yolo11n.pt") # 保存模型为 ONNX 格式
model.export(format="onnx")
举例
input shape (1, 3, 640, 640) BCHW and output shape(s) (1, 84, 8400)
84表示 80个种类的概率 , 4表示 归一化后的左边 xywh
8400 = 80x80 + 40 x 40 + 20x20 表示三种尺度的预测框的数量。
(1, 84, 8400) 是 推理模式下的输出
如果是训练模式:output是一个list [(1,4*16+80,20,20),(1,4*16+80,40,40),(1,4*16+80,80,80)]
6.detect loss
6.1 TaskAlignedAssigner
该函数,是找到 预测的ancher和gt之间的对应关系,找到对应关系了,才能建立loss.
主要原理参考我的另一篇博客:https://blog.csdn.net/tywwwww/article/details/148231289
6.2 score loss
就是预测的类别的loss
loss[1] = self.bce(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCE
6.3 iou loss 和 dfl loss
IOU loss:
class BboxLoss(nn.Module):"""Criterion class for computing training losses for bounding boxes."""def __init__(self, reg_max=16):"""Initialize the BboxLoss module with regularization maximum and DFL settings."""super().__init__()self.dfl_loss = DFLoss(reg_max) if reg_max > 1 else Nonedef forward(self, pred_dist, pred_bboxes, anchor_points, target_bboxes, target_scores, target_scores_sum, fg_mask):"""Compute IoU and DFL losses for bounding boxes."""weight = target_scores.sum(-1)[fg_mask].unsqueeze(-1)iou = bbox_iou(pred_bboxes[fg_mask], target_bboxes[fg_mask], xywh=False, CIoU=True)loss_iou = ((1.0 - iou) * weight).sum() / target_scores_sum# DFL lossif self.dfl_loss:target_ltrb = bbox2dist(anchor_points, target_bboxes, self.dfl_loss.reg_max - 1)# 转换为偏移量loss_dfl = self.dfl_loss(pred_dist[fg_mask].view(-1, self.dfl_loss.reg_max), target_ltrb[fg_mask]) * weightloss_dfl = loss_dfl.sum() / target_scores_sumelse:loss_dfl = torch.tensor(0.0).to(pred_dist.device)return loss_iou, loss_dfl
对比总结
指标 优化目标 优点 缺点
IoU 重叠区域 简单直观 无重叠时梯度为零
GIoU 重叠区域 + 最小封闭框 解决无重叠问题 对宽高比不敏感
DIoU 重叠区域 + 中心点距离 加速收敛 忽略宽高比
CIoU 重叠区域 + 中心点距离 + 宽高比 综合优化,精度最高 计算复杂
def bbox_iou(box1, box2, xywh=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-7):"""Calculate the Intersection over Union (IoU) between bounding boxes.This function supports various shapes for `box1` and `box2` as long as the last dimension is 4.For instance, you may pass tensors shaped like (4,), (N, 4), (B, N, 4), or (B, N, 1, 4).Internally, the code will split the last dimension into (x, y, w, h) if `xywh=True`,or (x1, y1, x2, y2) if `xywh=False`.Args:box1 (torch.Tensor): A tensor representing one or more bounding boxes, with the last dimension being 4.box2 (torch.Tensor): A tensor representing one or more bounding boxes, with the last dimension being 4.xywh (bool, optional): If True, input boxes are in (x, y, w, h) format. If False, input boxes are in(x1, y1, x2, y2) format.GIoU (bool, optional): If True, calculate Generalized IoU.DIoU (bool, optional): If True, calculate Distance IoU.CIoU (bool, optional): If True, calculate Complete IoU.eps (float, optional): A small value to avoid division by zero.Returns:(torch.Tensor): IoU, GIoU, DIoU, or CIoU values depending on the specified flags."""# Get the coordinates of bounding boxesif xywh: # transform from xywh to xyxy(x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, -1), box2.chunk(4, -1)w1_, h1_, w2_, h2_ = w1 / 2, h1 / 2, w2 / 2, h2 / 2b1_x1, b1_x2, b1_y1, b1_y2 = x1 - w1_, x1 + w1_, y1 - h1_, y1 + h1_b2_x1, b2_x2, b2_y1, b2_y2 = x2 - w2_, x2 + w2_, y2 - h2_, y2 + h2_else: # x1, y1, x2, y2 = box1b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, -1)b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, -1)w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + epsw2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps# Intersection areainter = (b1_x2.minimum(b2_x2) - b1_x1.maximum(b2_x1)).clamp_(0) * (b1_y2.minimum(b2_y2) - b1_y1.maximum(b2_y1)).clamp_(0)# Union Areaunion = w1 * h1 + w2 * h2 - inter + eps# IoU"""GIoU:计算最小封闭框的面积,用 IoU 减去最小封闭框面积与并集面积的差值除以最小封闭框面积。DIoU:计算最小封闭框的对角线平方 c2 和两个边界框中心点距离的平方 rho2,用 IoU 减去 rho2 / c2。CIoU:在 DIoU 的基础上,考虑边界框的宽高比,计算宽高比的惩罚项 v 和权重 alpha,用 IoU 减去 rho2 / c2 + v * alpha。对比总结指标 优化目标 优点 缺点IoU 重叠区域 简单直观 无重叠时梯度为零GIoU 重叠区域 + 最小封闭框 解决无重叠问题 对宽高比不敏感DIoU 重叠区域 + 中心点距离 加速收敛 忽略宽高比CIoU 重叠区域 + 中心点距离 + 宽高比 综合优化,精度最高 计算复杂"""iou = inter / unionif CIoU or DIoU or GIoU:cw = b1_x2.maximum(b2_x2) - b1_x1.minimum(b2_x1) # convex (smallest enclosing box) widthch = b1_y2.maximum(b2_y2) - b1_y1.minimum(b2_y1) # convex heightif CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1c2 = cw.pow(2) + ch.pow(2) + eps # convex diagonal squaredrho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2).pow(2) + (b2_y1 + b2_y2 - b1_y1 - b1_y2).pow(2)) / 4 # center dist**2if CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47v = (4 / math.pi**2) * ((w2 / h2).atan() - (w1 / h1).atan()).pow(2)with torch.no_grad():alpha = v / (v - iou + (1 + eps))return iou - (rho2 / c2 + v * alpha) # CIoUreturn iou - rho2 / c2 # DIoUc_area = cw * ch + eps # convex areareturn iou - (c_area - union) / c_area # GIoU https://arxiv.org/pdf/1902.09630.pdfreturn iou # IoU
6.4 dfl loss
class DFLoss(nn.Module):"""Criterion class for computing Distribution Focal Loss (DFL)."""def __init__(self, reg_max=16) -> None:"""Initialize the DFL module with regularization maximum."""super().__init__()# 定义最大的正则化值,即离散化的区间数量self.reg_max = reg_maxdef __call__(self, pred_dist, target):"""Return sum of left and right DFL losses from https://ieeexplore.ieee.org/document/9792391."""# pred_dist: 预测的分布,形状为 (batch_size, num_anchors, reg_max)# target: 目标值,形状为 (batch_size, num_anchors)# 将目标值限制在 [0, reg_max - 1 - 0.01] 范围内,避免取到 reg_max - 1 这个值# target 形状不变,仍为 (batch_size, num_anchors)target = target.clamp_(0, self.reg_max - 1 - 0.01)# 计算目标值的左相邻离散点,将目标值转换为长整型# tl 形状为 (batch_size, num_anchors)tl = target.long() # target left# 计算目标值的右相邻离散点,即左相邻离散点加 1# tr 形状为 (batch_size, num_anchors)tr = tl + 1 # target right# 计算左相邻离散点的权重,权重为右相邻离散点与目标值的差值# wl 形状为 (batch_size, num_anchors)wl = tr - target # weight left# 计算右相邻离散点的权重,权重为 1 减去左相邻离散点的权重# wr 形状为 (batch_size, num_anchors)wr = 1 - wl # weight right# 计算左相邻离散点的交叉熵损失,reduction="none" 表示不进行损失聚合# F.cross_entropy(pred_dist, tl.view(-1), reduction="none") 形状为 (batch_size * num_anchors,)# .view(tl.shape) 后形状变为 (batch_size, num_anchors)# 乘以左相邻离散点的权重 wlleft_loss = F.cross_entropy(pred_dist, tl.view(-1), reduction="none").view(tl.shape) * wl# 计算右相邻离散点的交叉熵损失,reduction="none" 表示不进行损失聚合# F.cross_entropy(pred_dist, tr.view(-1), reduction="none") 形状为 (batch_size * num_anchors,)# .view(tl.shape) 后形状变为 (batch_size, num_anchors)# 乘以右相邻离散点的权重 wrright_loss = F.cross_entropy(pred_dist, tr.view(-1), reduction="none").view(tl.shape) * wr# 将左右相邻离散点的损失相加,然后在最后一个维度上求均值,并保持维度# 最终返回的损失形状为 (batch_size, num_anchors, 1)return (left_loss + right_loss).mean(-1, keepdim=True)
6.5 完整的v8DetectionLoss
class v8DetectionLoss:"""Criterion class for computing training losses for YOLOv8 object detection."""def __init__(self, model, tal_topk=10): # model must be de-paralleled"""Initialize v8DetectionLoss with model parameters and task-aligned assignment settings."""device = next(model.parameters()).device # get model deviceh = model.args # hyperparametersm = model.model[-1] # Detect() moduleself.bce = nn.BCEWithLogitsLoss(reduction="none")self.hyp = hself.stride = m.stride # model stridesself.nc = m.nc # number of classesself.no = m.nc + m.reg_max * 4self.reg_max = m.reg_maxself.device = deviceself.use_dfl = m.reg_max > 1self.assigner = TaskAlignedAssigner(topk=tal_topk, num_classes=self.nc, alpha=0.5, beta=6.0)self.bbox_loss = BboxLoss(m.reg_max).to(device)self.proj = torch.arange(m.reg_max, dtype=torch.float, device=device)def preprocess(self, targets, batch_size, scale_tensor):"""Preprocess targets by converting to tensor format and scaling coordinates."""nl, ne = targets.shapeif nl == 0: # 若为 0,意味着当前批次的图像里没有目标对象。 输入目标标签数量为 0 的特殊情况,创建一个全零张量作为输出,保证后续的损失计算流程能正常运行。out = torch.zeros(batch_size, 0, ne - 1, device=self.device)else:i = targets[:, 0] # image index_, counts = i.unique(return_counts=True) # 统计每个图像的目标数量counts = counts.to(dtype=torch.int32)# batch_size 是当前批次中的图像数量。# counts.max() 是所有图像中目标数量的最大值,即这个维度的大小要能容纳单张图像中最多的目标数。# ne - 1 是每个目标的属性数量,ne 是 targets 张量的列数,减去 1 是因为去掉了图像索引列。out = torch.zeros(batch_size, counts.max(), ne - 1, device=self.device)for j in range(batch_size):matches = i == j # 标记出 i 中等于当前图像索引 j 的元素位置if n := matches.sum(): # 计算 matches 中 True 的数量,即当前图像中目标的数量 n。如果 n 大于 0,则执行下面的赋值操作。out[j, :n] = targets[matches, 1:]out[..., 1:5] = xywh2xyxy(out[..., 1:5].mul_(scale_tensor)) # 将目标框坐标从归一化形式转换为绝对坐标形式。return outdef bbox_decode(self, anchor_points, pred_dist):"""Decode predicted object bounding box coordinates from anchor points and distribution."""if self.use_dfl:b, a, c = pred_dist.shape # batch, anchors, channelspred_dist = pred_dist.view(b, a, 4, c // 4).softmax(3).matmul(self.proj.type(pred_dist.dtype))# pred_dist = pred_dist.view(b, a, c // 4, 4).transpose(2,3).softmax(3).matmul(self.proj.type(pred_dist.dtype))# pred_dist = (pred_dist.view(b, a, c // 4, 4).softmax(2) * self.proj.type(pred_dist.dtype).view(1, 1, -1, 1)).sum(2)return dist2bbox(pred_dist, anchor_points, xywh=False)def __call__(self, preds, batch):"""Calculate the sum of the loss for box, cls and dfl multiplied by batch size."""# 初始化一个长度为 3 的零张量,分别用于存储边界框损失、分类损失和 DFL 损失# shape: (3,)loss = torch.zeros(3, device=self.device) # box, cls, dfl# 若 preds 是元组,取第二个元素作为特征图;否则直接使用 preds# shape: 若 preds 是元组,feats 形状同 preds[1];否则同 predsfeats = preds[1] if isinstance(preds, tuple) else preds# 将特征图列表中的每个元素重塑为 (batch_size, self.no, -1) 形状,然后沿维度 2 拼接# 再按维度 1 分割成预测分布和预测分数两部分# pred_distri shape: (batch_size, self.reg_max * 4, num_anchors)# pred_scores shape: (batch_size, self.nc, num_anchors)pred_distri, pred_scores = torch.cat([xi.view(feats[0].shape[0], self.no, -1) for xi in feats], 2).split((self.reg_max * 4, self.nc), 1)# 交换 pred_scores 的维度,使维度顺序变为 (batch_size, num_anchors, self.nc),并确保内存连续# shape: (batch_size, num_anchors, self.nc)pred_scores = pred_scores.permute(0, 2, 1).contiguous()# 交换 pred_distri 的维度,使维度顺序变为 (batch_size, num_anchors, self.reg_max * 4),并确保内存连续# shape: (batch_size, num_anchors, self.reg_max * 4)pred_distri = pred_distri.permute(0, 2, 1).contiguous()# 获取 pred_scores 的数据类型dtype = pred_scores.dtype# 获取批次大小# shape: 标量batch_size = pred_scores.shape[0]# 计算图像尺寸,将特征图的高度和宽度乘以步长# shape: (2,)imgsz = torch.tensor(feats[0].shape[2:], device=self.device, dtype=dtype) * self.stride[0] # image size (h,w)# 生成锚点和对应的步长张量# anchor_points shape: (num_anchors=80*80+40*40+20*20, 2)# stride_tensor shape: (num_anchors,1)anchor_points, stride_tensor = make_anchors(feats, self.stride, 0.5)# Targets# 将批次索引、类别标签和边界框信息在维度 1 上拼接成一个张量# shape: (num_targets, 6),其中 6 = 1(batch_idx)+ 1(cls)+ 4(bboxes) # batch["batch_idx"] 代表每个目标标签所属图像在当前批次中的索引targets = torch.cat((batch["batch_idx"].view(-1, 1), batch["cls"].view(-1, 1), batch["bboxes"]), 1) # 该bbox所属的图像,所属的类别,具体边界框坐标# 对目标数据进行预处理,包括转换设备和缩放坐标# shape: (batch_size, max_num_targets_per_image, 5),其中 5 = 1(cls)+ 4(bboxes)targets = self.preprocess(targets.to(self.device), batch_size, scale_tensor=imgsz[[1, 0, 1, 0]])# 将预处理后的目标数据按维度 2 分割成真实标签和真实边界框两部分# gt_labels shape: (batch_size, max_num_targets_per_image, 1)# gt_bboxes shape: (batch_size, max_num_targets_per_image, 4)gt_labels, gt_bboxes = targets.split((1, 4), 2) # cls, xyxy# 生成一个掩码,标记哪些真实边界框是有效的(即框的坐标和大于 0)# shape: (batch_size, max_num_targets_per_image, 1)mask_gt = gt_bboxes.sum(2, keepdim=True).gt_(0.0)# Pboxes# 根据锚点和预测分布解码出预测的边界框# shape: (batch_size, num_anchors, 4)pred_bboxes = self.bbox_decode(anchor_points, pred_distri) # xyxy, (b, h*w, 4)# dfl_conf = pred_distri.view(batch_size, -1, 4, self.reg_max).detach().softmax(-1)# dfl_conf = (dfl_conf.amax(-1).mean(-1) + dfl_conf.amax(-1).amin(-1)) / 2# 使用分配器将预测结果与真实标签进行匹配,得到目标边界框、目标分数和前景掩码等# target_bboxes shape: (batch_size, num_anchors, 4)# target_scores shape: (batch_size, num_anchors, self.nc)# fg_mask shape: (batch_size, num_anchors)_, target_bboxes, target_scores, fg_mask, _ = self.assigner(# pred_scores.detach().sigmoid() * 0.8 + dfl_conf.unsqueeze(-1) * 0.2,pred_scores.detach().sigmoid(),(pred_bboxes.detach() * stride_tensor).type(gt_bboxes.dtype),anchor_points * stride_tensor,gt_labels,gt_bboxes,mask_gt,)"""fg_mask 张量的形状通常为 (batch_size, num_anchors),其中 batch_size 是当前批次的图像数量,num_anchors 是所有检测层的锚点总数。张量中的每个元素是一个布尔值:True:表示对应的锚点被分配给了某个前景对象,即该锚点负责预测一个目标物体。False:表示对应的锚点属于背景,不负责预测目标物体。"""# 计算目标分数的总和,确保最小值为 1,避免除零错误# shape: 标量target_scores_sum = max(target_scores.sum(), 1)# Cls loss# 计算分类损失,使用二元交叉熵损失函数,将损失总和除以目标分数总和进行归一化# loss[1] = self.varifocal_loss(pred_scores, target_scores, target_labels) / target_scores_sum # VFL way# shape: 标量loss[1] = self.bce(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCE# Bbox loss# 若存在前景掩码(即存在正样本),则计算边界框损失和 DFL 损失if fg_mask.sum():# 将目标边界框除以步长张量进行缩放# shape: (batch_size, num_anchors, 4)target_bboxes /= stride_tensor# 计算边界框损失和 DFL 损失# loss[0] shape: 标量# loss[2] shape: 标量loss[0], loss[2] = self.bbox_loss(pred_distri, pred_bboxes, anchor_points, target_bboxes, target_scores, target_scores_sum, fg_mask)# 将边界框损失乘以对应的增益系数# shape: 标量loss[0] *= self.hyp.box # box gain# 将分类损失乘以对应的增益系数# shape: 标量loss[1] *= self.hyp.cls # cls gain# 将 DFL 损失乘以对应的增益系数# shape: 标量loss[2] *= self.hyp.dfl # dfl gain# 将总损失乘以批次大小,并返回分离梯度的损失# loss * batch_size shape: (3,)# loss.detach() shape: (3,)return loss * batch_size, loss.detach() # loss(box, cls, dfl)
在DetectionModel中调用loss函数init_criterion
class DetectionModel(BaseModel):"""YOLO detection model."""def __init__(self, cfg="yolo11n.yaml", ch=3, nc=None, verbose=True):"""Initialize the YOLO detection model with the given config and parameters.Args:cfg (str | dict): Model configuration file path or dictionary.ch (int): Number of input channels.nc (int, optional): Number of classes.verbose (bool): Whether to display model information."""super().__init__()self.yaml = cfg if isinstance(cfg, dict) else yaml_model_load(cfg) # cfg dictif self.yaml["backbone"][0][2] == "Silence":LOGGER.warning("YOLOv9 `Silence` module is deprecated in favor of torch.nn.Identity. ""Please delete local *.pt file and re-download the latest model checkpoint.")self.yaml["backbone"][0][2] = "nn.Identity"# Define modelself.yaml["channels"] = ch # save channelsif nc and nc != self.yaml["nc"]:LOGGER.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}")self.yaml["nc"] = nc # override YAML valueself.model, self.save = parse_model(deepcopy(self.yaml), ch=ch, verbose=verbose) # model, savelistself.names = {i: f"{i}" for i in range(self.yaml["nc"])} # default names dictself.inplace = self.yaml.get("inplace", True)self.end2end = getattr(self.model[-1], "end2end", False)# Build stridesm = self.model[-1] # Detect()if isinstance(m, Detect): # includes all Detect subclasses like Segment, Pose, OBB, YOLOEDetect, YOLOESegments = 256 # 2x min stridem.inplace = self.inplacedef _forward(x):"""Perform a forward pass through the model, handling different Detect subclass types accordingly."""if self.end2end:return self.forward(x)["one2many"]return self.forward(x)[0] if isinstance(m, (Segment, YOLOESegment, Pose, OBB)) else self.forward(x)m.stride = torch.tensor([s / x.shape[-2] for x in _forward(torch.zeros(1, ch, s, s))]) # forwardself.stride = m.stridem.bias_init() # only run onceelse:self.stride = torch.Tensor([32]) # default stride for i.e. RTDETR# Init weights, biasesinitialize_weights(self)if verbose:self.info()LOGGER.info("")def _predict_augment(self, x):"""Perform augmentations on input image x and return augmented inference and train outputs.Args:x (torch.Tensor): Input image tensor.Returns:(torch.Tensor): Augmented inference output."""if getattr(self, "end2end", False) or self.__class__.__name__ != "DetectionModel":LOGGER.warning("Model does not support 'augment=True', reverting to single-scale prediction.")return self._predict_once(x)img_size = x.shape[-2:] # height, widths = [1, 0.83, 0.67] # scalesf = [None, 3, None] # flips (2-ud, 3-lr)y = [] # outputsfor si, fi in zip(s, f):xi = scale_img(x.flip(fi) if fi else x, si, gs=int(self.stride.max()))yi = super().predict(xi)[0] # forwardyi = self._descale_pred(yi, fi, si, img_size)y.append(yi)y = self._clip_augmented(y) # clip augmented tailsreturn torch.cat(y, -1), None # augmented inference, train@staticmethoddef _descale_pred(p, flips, scale, img_size, dim=1):"""De-scale predictions following augmented inference (inverse operation).Args:p (torch.Tensor): Predictions tensor.flips (int): Flip type (0=none, 2=ud, 3=lr).scale (float): Scale factor.img_size (tuple): Original image size (height, width).dim (int): Dimension to split at.Returns:(torch.Tensor): De-scaled predictions."""p[:, :4] /= scale # de-scalex, y, wh, cls = p.split((1, 1, 2, p.shape[dim] - 4), dim)if flips == 2:y = img_size[0] - y # de-flip udelif flips == 3:x = img_size[1] - x # de-flip lrreturn torch.cat((x, y, wh, cls), dim)def _clip_augmented(self, y):"""Clip YOLO augmented inference tails.Args:y (List[torch.Tensor]): List of detection tensors.Returns:(List[torch.Tensor]): Clipped detection tensors."""nl = self.model[-1].nl # number of detection layers (P3-P5)g = sum(4**x for x in range(nl)) # grid pointse = 1 # exclude layer counti = (y[0].shape[-1] // g) * sum(4**x for x in range(e)) # indicesy[0] = y[0][..., :-i] # largei = (y[-1].shape[-1] // g) * sum(4 ** (nl - 1 - x) for x in range(e)) # indicesy[-1] = y[-1][..., i:] # smallreturn ydef init_criterion(self):"""Initialize the loss criterion for the DetectionModel."""return E2EDetectLoss(self) if getattr(self, "end2end", False) else v8DetectionLoss(self)
E2EDetectLoss
class E2EDetectLoss:"""Criterion class for computing training losses for end-to-end detection."""def __init__(self, model):"""Initialize E2EDetectLoss with one-to-many and one-to-one detection losses using the provided model."""self.one2many = v8DetectionLoss(model, tal_topk=10)self.one2one = v8DetectionLoss(model, tal_topk=1)def __call__(self, preds, batch):"""Calculate the sum of the loss for box, cls and dfl multiplied by batch size."""preds = preds[1] if isinstance(preds, tuple) else predsone2many = preds["one2many"]loss_one2many = self.one2many(one2many, batch)one2one = preds["one2one"]loss_one2one = self.one2one(one2one, batch)return loss_one2many[0] + loss_one2one[0], loss_one2many[1] + loss_one2one[1]
7. 推理后处理:得到(batch_size, min(max_det, anchors), 6)
每个图像检测 max_det个bbox, (x,y,w,h, prop, classid)
ultralytics/nn/modules/head.py中
def postprocess(preds: torch.Tensor, max_det: int, nc: int = 80):"""Post-processes YOLO model predictions.Args:preds (torch.Tensor): Raw predictions with shape (batch_size, num_anchors, 4 + nc) with last dimensionformat [x, y, w, h, class_probs].max_det (int): Maximum detections per image.nc (int, optional): Number of classes. Default: 80.Returns:(torch.Tensor): Processed predictions with shape (batch_size, min(max_det, num_anchors), 6) and lastdimension format [x, y, w, h, max_class_prob, class_index]."""# 获取预测结果张量的形状,分别为批量大小、锚点数量和每个锚点的预测值数量batch_size, anchors, _ = preds.shape # i.e. shape(16,8400,84)# 将预测结果拆分为边界框信息和类别概率信息# boxes 形状为 (batch_size, num_anchors, 4),包含边界框的 [x, y, w, h] 信息# scores 形状为 (batch_size, num_anchors, nc),包含每个锚点对应各个类别的概率boxes, scores = preds.split([4, nc], dim=-1)# 找出每个锚点对应所有类别概率中的最大值,并选取前 min(max_det, anchors) 个最大概率对应的锚点索引# topk 函数返回值为 (values, indices),这里只取 indices 并在最后一维添加一个维度# index 形状为 (batch_size, min(max_det, anchors), 1)index = scores.amax(dim=-1).topk(min(max_det, anchors))[1].unsqueeze(-1)# 根据上述索引,从 boxes 张量中收集对应的边界框信息# index.repeat(1, 1, 4) 将索引在最后一维复制 4 次,以匹配 boxes 张量的最后一维维度# boxes 形状变为 (batch_size, min(max_det, anchors), 4)boxes = boxes.gather(dim=1, index=index.repeat(1, 1, 4))# 根据上述索引,从 scores 张量中收集对应的类别概率信息# index.repeat(1, 1, nc) 将索引在最后一维复制 nc 次,以匹配 scores 张量的最后一维维度# scores 形状变为 (batch_size, min(max_det, anchors), nc)scores = scores.gather(dim=1, index=index.repeat(1, 1, nc))# 将 scores 张量在第 1 维和第 2 维上展平,然后选取前 min(max_det, anchors) 个最大概率及其索引# scores 形状变为 (batch_size, min(max_det, anchors))# index 形状变为 (batch_size, min(max_det, anchors))scores, index = scores.flatten(1).topk(min(max_det, anchors)) # 其实是排序# 生成批量索引,形状为 (batch_size, 1)i = torch.arange(batch_size)[..., None] # batch indices# 拼接最终结果# boxes[i, index // nc] 根据批量索引和类别索引获取对应的边界框信息# scores[..., None] 在最后一维添加一个维度,将概率值变为列向量# (index % nc)[..., None].float() 计算类别索引并在最后一维添加一个维度,转换为浮点数# 最终返回的张量形状为 (batch_size, min(max_det, anchors), 6),最后一维格式为 [x, y, w, h, max_class_prob, class_index]return torch.cat([boxes[i, index // nc], scores[..., None], (index % nc)[..., None].float()], dim=-1)