Transformer 与 XGBoost 协同优化的时间序列建模
时间序列建模的目标
时间序列建模旨在基于过去时间点的数据预测未来的序列值。具体来说,给定一个时间序列 ,我们希望能够预测未来 h 个时间点的值
。
传统模型与现代方法
- 传统模型:如 ARIMA 等统计模型,基于时间序列的自相关性和平稳性假设,通过参数估计捕捉序列的线性关系,但在处理复杂非线性关系和长期依赖时存在局限。
- LSTM:早期深度学习方法,通过记忆单元和门控机制处理序列长期依赖,但在极长序列中面临梯度消失和计算效率问题。
- Transformer:近年因强大的序列建模能力被广泛应用,利用自注意力机制并行计算并有效捕捉长距离依赖。
Transformer 的时间序列建模
自注意力机制
Transformer 的核心是自注意力机制,用于捕捉序列中各时间点的长距离依赖:
- 输入序列:假设输入序列为
,其中 d 为特征维度。
- 计算 Query、Key、Value:对每个时间点
,计算其 Query、Key、Value:
其中
是参数矩阵。
- 注意力权重矩阵:计算注意力权重矩阵
:
模型通过相关性加权聚合信息。
- 输出隐状态序列:经多层自注意力和前馈网络后,输出隐状态序列
。
Transformer 预测
假设最后一层 Transformer 输出的隐藏状态为 ,通过线性层预测下一步:
其中 和
是线性层的权重和偏置。
XGBoost 的时间序列建模
特征构建
应用 XGBoost 需构建合适特征,包括:
- 原始时间序列的滞后窗口:如使用过去 w 个时间点的数据
作为特征。
- Transformer 预测:将 Transformer 的预测结果
作为特征之一。
- 时间特征:如时间周期(小时、天、周等)、节假日等信息。
XGBoost 拟合残差
XGBoost 是基于树模型的梯度提升算法,用于拟合残差并捕获非线性关系:
- 模型定义:设 F 是所有回归树的集合,XGBoost 模型表示为:
- 拟合残差:XGBoost 拟合 Transformer 的预测残差:
其中 y 是真实值,
是 Transformer 的预测值。
- 最终预测:结合 Transformer 和 XGBoost 的结果:
协同优化机制
损失函数设计
整体损失函数定义为:
其中:
是回归损失函数(如均方误差 MSE):
其中 和
分别是 Transformer 和 XGBoost 的参数集合,
和
是正则化系数。
训练流程
- 预训练 Transformer:用序列数据训练 Transformer,仅更新其参数,优化目标为最小化预测损失:
- 构造 XGBoost 特征:用预训练的 Transformer 预测训练数据,组合原始特征和预测结果为新特征矩阵,如每个样本的特征向量:
其中
是滞后窗口特征,
是时间特征。
- 训练 XGBoost 拟合残差:用构造的特征矩阵训练 XGBoost,拟合 Transformer 的预测残差,损失函数为 MSE:
其中
,
是 XGBoost 的预测残差。
- 联合微调(可选):结合 Transformer 和 XGBoost 的梯度信息,端到端联合微调,同时更新两者参数。
端到端微调推导
- 总预测:
- 损失函数(均方误差):
- 梯度计算:
- Transformer 参数的梯度:
- XGBoost 参数的梯度:基于树的近似二阶导数进行更新,通过提升树的方式优化。
- Transformer 参数的梯度:
总结
在时间序列建模中,Transformer 捕捉序列长依赖和基本趋势,提供全局序列理解;XGBoost 专注于拟合 Transformer 的预测残差,捕捉非线性细节和结构化信息,弥补 Transformer 在局部细节建模上的不足。通过协同训练,该方案提升了预测精度,增强了模型在复杂、噪声大的时间序列数据中的泛化能力和鲁棒性,为高精度时间序列建模提供了强大工具,尤其适用于动态特性复杂的应用场景。
完整流程
时间序列数据准备
我们的目标是使用包含趋势、季节性和噪声的时间序列数据。数据准备是整个流程的基础,需确保数据质量并提取有用特征。
-
数据加载与预处理:加载时间序列数据后,进行必要的清洗,包括处理缺失值和异常值。随后对数据进行归一化或标准化处理,使其数值范围更适合模型输入。
-
特征工程:构建滞后窗口特征,以便模型能够基于历史数据进行学习。同时提取时间相关特征,如小时、天、周等,帮助模型捕捉时间序列中的周期性模式。
Transformer 模型训练
利用 Transformer 模型提取复杂的时间序列特征。Transformer 擅长捕捉序列中的长距离依赖关系,对短期复杂依赖有很好的建模能力。
-
模型初始化与配置:根据数据特征设置 Transformer 模型的参数,包括输入维度、隐藏维度、注意力头数和层数等。
-
模型训练:使用预处理后的数据对 Transformer 进行训练,通过优化损失函数来更新模型参数。损失函数通常采用均方误差(MSE),优化器可选择 Adam 等适合深度学习模型的优化算法。
-
模型保存:完成训练后,保存 Transformer 模型,以便后续提取特征和进行协同训练。
中间特征提取
将训练好的 Transformer 模型应用于训练数据和测试数据,提取模型最后一层的输出作为深度特征。这些特征融合了时间序列的长短期依赖信息,能够为后续的 XGBoost 模型提供更丰富的输入。
-
特征提取:使用 Transformer 模型对数据进行前向传播,获取最后一层的输出结果。
-
特征整合:将提取的深度特征与原始特征相结合,形成一个综合特征集,作为 XGBoost 模型的输入。
XGBoost 建模
利用提取的综合特征进行回归建模。XGBoost 作为梯度提升树模型,能有效拟合残差并捕获非线性关系。
-
数据准备:将综合特征集和对应的目标变量组合成 XGBoost 的训练数据。
-
模型训练与优化:初始化 XGBoost 回归模型,并设置合适的超参数。通过交叉验证等方式优化超参数,提升模型的预测性能。
-
残差拟合:XGBoost 模型专注于拟合 Transformer 模型的预测残差,从而提高整体预测精度。
评估与可视化
对整个建模流程进行评估和可视化,以检验模型性能并获得深入见解。
-
模型评估:使用均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)和平均绝对百分比误差(MAPE)等指标,全面评估模型的预测精度。
-
可视化分析:绘制原始时间序列图,直观展示数据的整体趋势和季节性特征;绘制预测结果图,对比模型预测值与真实值,直观评估预测效果;绘制误差分布图,分析预测误差的分布情况,识别模型的优势和不足;绘制 XGBoost 的特征重要性图,了解各特征对预测结果的贡献程度;进行残差分析,绘制残差图,检查模型在不同时间点的预测误差变化情况,判断是否存在系统性偏差。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, mean_absolute_error
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
import xgboost as xgbsns.set(style="whitegrid")# 1: 生成虚拟时间序列数据集
def generate_data(n_samples=1000):np.random.seed(42)time = np.arange(n_samples)seasonal = 10 * np.sin(time * 2 * np.pi / 50)trend = 0.05 * timenoise = np.random.normal(scale=2, size=n_samples)signal = seasonal + trend + noisedf = pd.DataFrame({"timestamp": time, "value": signal})return dfdata = generate_data()# 可视化原始时间序列
def plot_original_series(df):plt.figure(figsize=(14, 6))plt.plot(df['timestamp'], df['value'], color='crimson')plt.title("Original Time Series")plt.xlabel("Time")plt.ylabel("Value")plt.grid(True)plt.show()plot_original_series(data)# 2: 构建数据集,用于Transformer训练(滑动窗口)
class TimeSeriesDataset(Dataset):def __init__(self, series, window_size):self.X = []self.y = []for i in range(len(series) - window_size):self.X.append(series[i:i+window_size])self.y.append(series[i+window_size])self.X = torch.tensor(self.X, dtype=torch.float32)self.y = torch.tensor(self.y, dtype=torch.float32)def __len__(self):return len(self.X)def __getitem__(self, idx):return self.X[idx], self.y[idx]# 3: 定义Transformer模型
class TransformerModel(nn.Module):def __init__(self, input_size=1, d_model=64, nhead=4, num_layers=2):super(TransformerModel, self).__init__()self.model_type = 'Transformer'self.input_linear = nn.Linear(input_size, d_model)encoder_layer = nn.TransformerEncoderLayer(d_model=d_model, nhead=nhead)self.transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)self.output_layer = nn.Linear(d_model, 1)def forward(self, src):src = self.input_linear(src)src = src.permute(1, 0, 2) # (batch, seq, feature) -> (seq, batch, feature)output = self.transformer_encoder(src)output = output[-1] # 使用最后时间步的输出output = self.output_layer(output)return output.squeeze()# 4: 训练Transformer模型
def train_transformer_model(data, window_size=24, epochs=30, lr=1e-3):dataset = TimeSeriesDataset(data['value'].values, window_size)train_size = int(len(dataset) * 0.8)train_dataset, test_dataset = torch.utils.data.random_split(dataset, [train_size, len(dataset) - train_size])train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)device = torch.device("cuda"if torch.cuda.is_available() else"cpu")model = TransformerModel().to(device)criterion = nn.MSELoss()optimizer = torch.optim.Adam(model.parameters(), lr=lr)for epoch in range(epochs):model.train()epoch_loss = 0for X_batch, y_batch in train_loader:X_batch = X_batch.unsqueeze(-1).to(device)y_batch = y_batch.to(device)optimizer.zero_grad()output = model(X_batch)loss = criterion(output, y_batch)loss.backward()optimizer.step()epoch_loss += loss.item()print(f"Epoch {epoch+1}, Loss: {epoch_loss / len(train_loader):.4f}")return model, test_loadermodel, test_loader = train_transformer_model(data)# 5: 提取Transformer中间表示作为XGBoost特征(协同优化)
def extract_transformer_features(model, data, window_size=24):model.eval()features = []targets = []with torch.no_grad():for i in range(window_size, len(data)):x_seq = torch.tensor(data[i-window_size:i].values, dtype=torch.float32).unsqueeze(0).unsqueeze(-1)output = model.input_linear(x_seq)output = output.permute(1, 0, 2)encoded = model.transformer_encoder(output)features.append(encoded[-1].squeeze().numpy())targets.append(data.iloc[i])return np.array(features), np.array(targets)X, y = extract_transformer_features(model, data['value'])# 6: 使用XGBoost进行回归预测
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False)
xgb_model = xgb.XGBRegressor(n_estimators=100, max_depth=3, learning_rate=0.1)
xgb_model.fit(X_train, y_train)
y_pred = xgb_model.predict(X_test)# 7: 评估模型性能
def evaluate_predictions(y_true, y_pred):print("MSE:", mean_squared_error(y_true, y_pred))print("MAE:", mean_absolute_error(y_true, y_pred))plt.figure(figsize=(12, 6))plt.plot(y_true, label='Actual', color='dodgerblue')plt.plot(y_pred, label='Predicted', color='orange')plt.title("Actual vs Predicted Values (XGBoost on Transformer features)")plt.legend()plt.grid(True)plt.show()evaluate_predictions(y_test, y_pred)# 图表2:误差分布
plt.figure(figsize=(8, 5))
sns.histplot(y_test - y_pred, kde=True, color="purple")
plt.title("Prediction Error Distribution")
plt.xlabel("Error")
plt.ylabel("Frequency")
plt.grid(True)
plt.show()# 图表3:特征重要性
xgb.plot_importance(xgb_model, height=0.5, importance_type='gain', title="Feature Importance")
plt.show()# 图表4:预测残差随时间分布
plt.figure(figsize=(12, 5))
plt.plot(np.arange(len(y_test)), y_test - y_pred, color="green")
plt.title("Residual over Time")
plt.xlabel("Time Index")
plt.ylabel("Residual")
plt.grid(True)
plt.show()数据可视化分析
1. 原始时间序列图:直观展示趋势+季节性结构
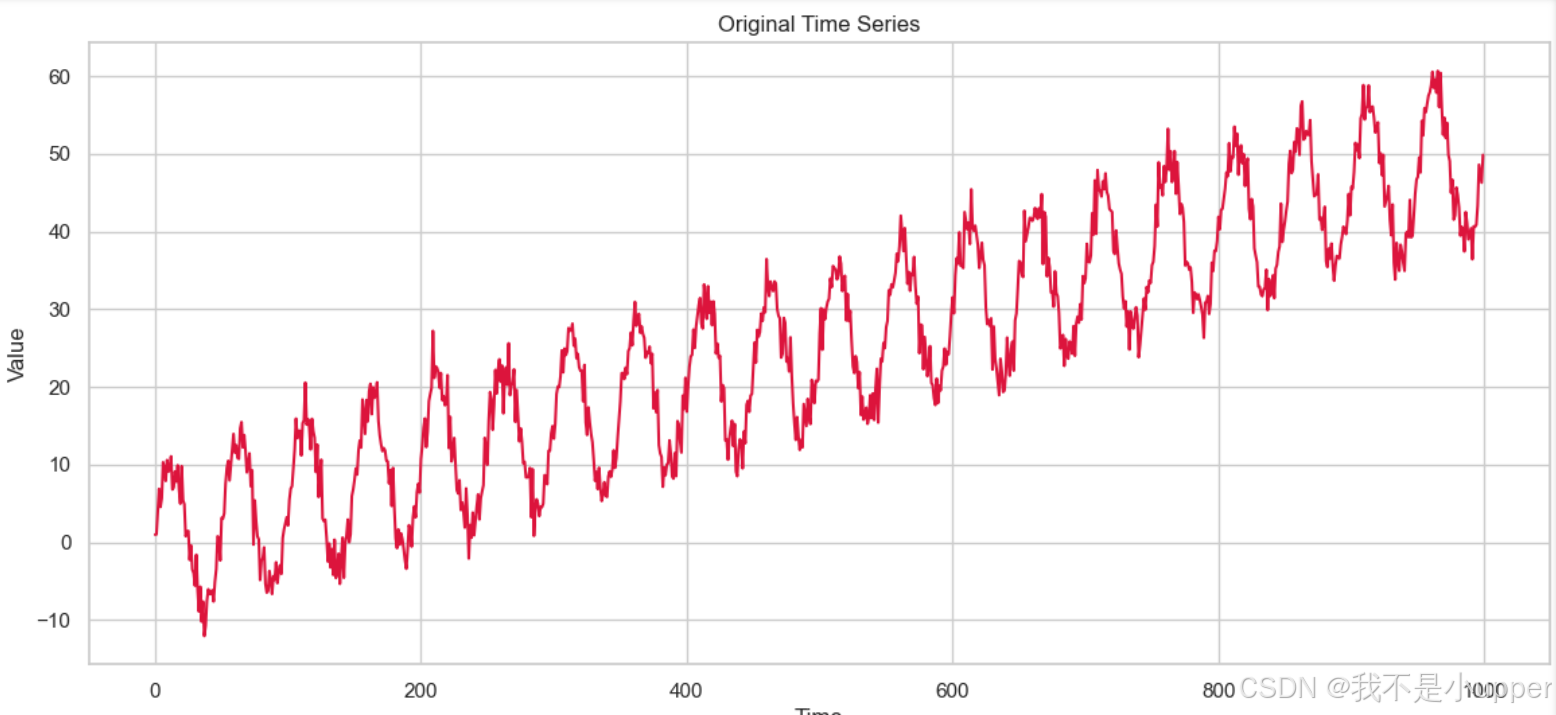
横轴是时间步(从 0 到 1000 ),纵轴是对应数值(范围 -10 到 60 )。红色波动曲线展示序列随时间变化情况,前期数值在低区间(如 0 附近及以下)波动,后逐渐向高值(如 30、50 )发展,整体呈现出复杂、无明显简单规律的波动形态,反映数据的时序特征与动态变化 。

2. 预测 vs 实际图:展示协同模型在测试集上的拟合能力。
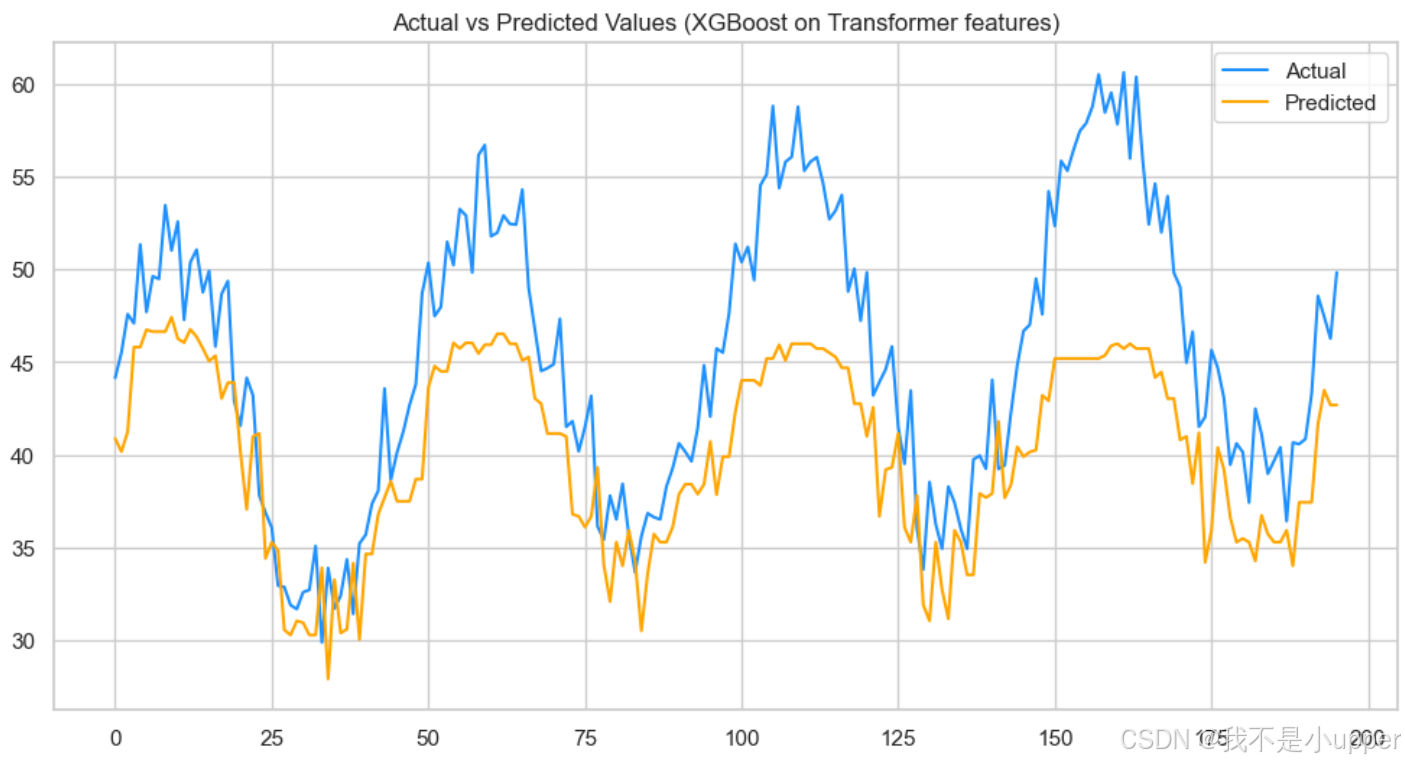
上图横轴是时间步(0 - 200),纵轴是数值(30 - 60) 。蓝色线代表实际值,橙色线代表预测值,可见二者整体趋势相近,但局部存在偏差,能直观展现模型预测效果,帮助判断预测值对实际值的拟合程度 。
3. 误差分布图:通过颜色和曲线展示模型误差的集中性和偏移。
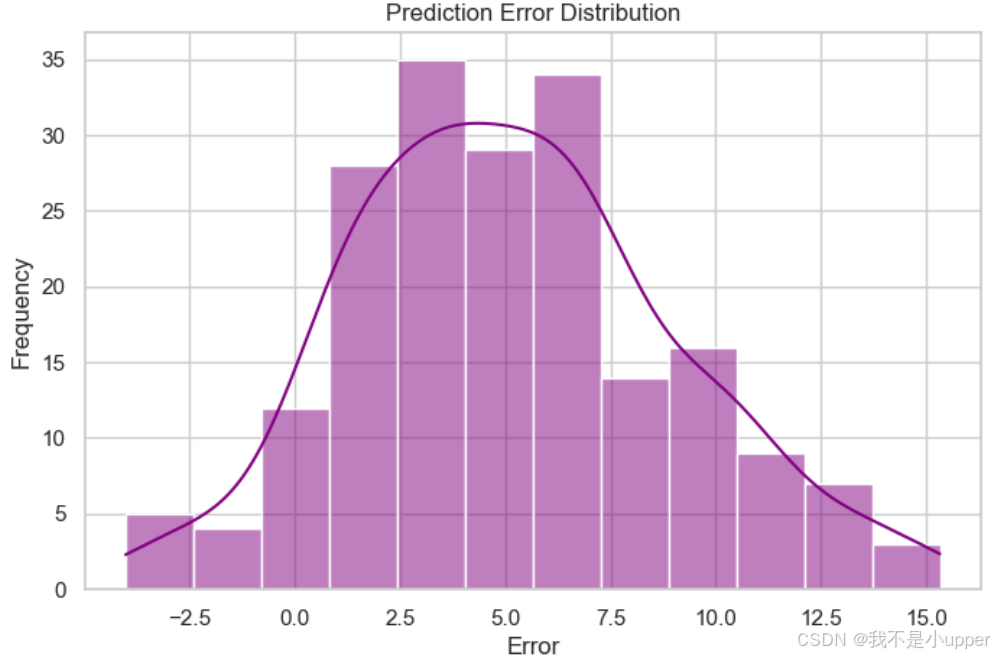
上图是预测误差分布的可视化,紫色柱状代表不同误差区间的出现频次,曲线是拟合的分布趋势。误差主要集中在 2.5 - 7.5 区间,呈现近似正态分布形态,能直观看出大部分预测误差的范围和集中程度,反映模型预测误差的分布特征,帮助判断误差是否稳定、是否存在异常大误差情况 。
4. 残差时间演化图:分析模型随时间是否有偏差或结构性失效。
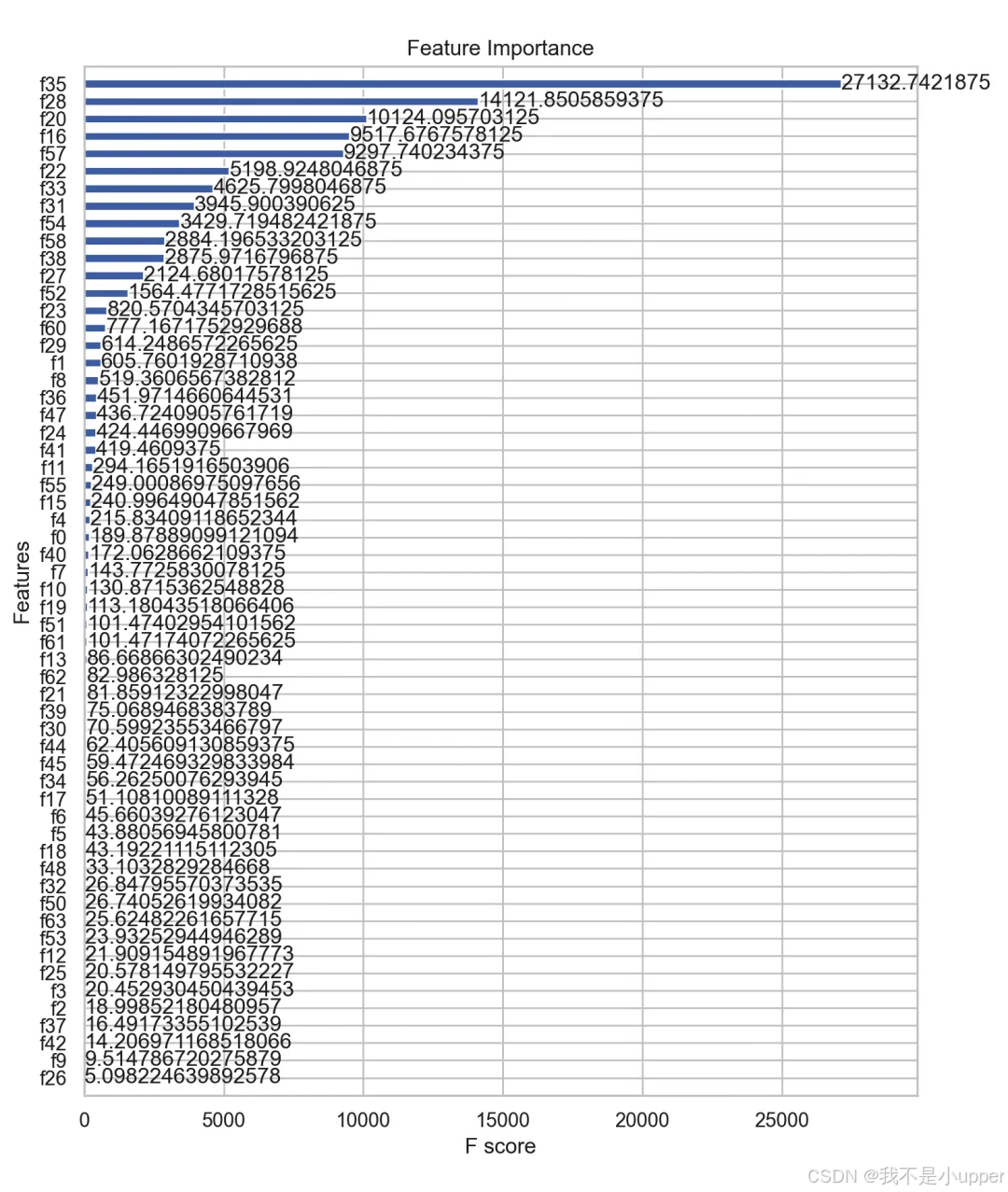
上图是特征重要性可视化图,横轴是 F 分数(体现特征重要程度,值越大越重要 ),纵轴是特征名称。不同特征对应蓝色条形长度不同,最长的条形代表该特征 F 分数最高、对模型决策影响最大,通过条形长度可直观看出各特征在模型中的重要性排序 。
5. 特征重要性图:展示Transformer提取的特征在XGBoost中的贡献。
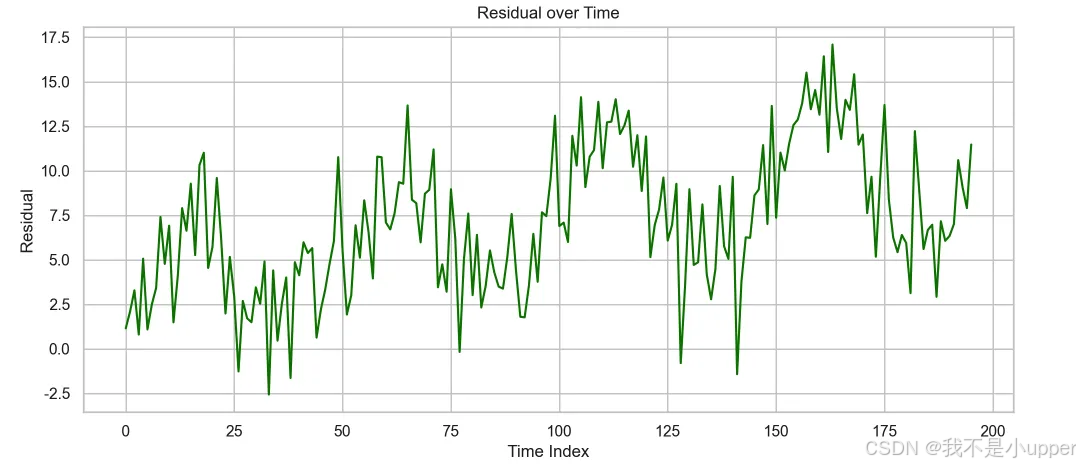
上图是残差随时间变化的可视化图,横轴为时间索引(从 0 到 200 ),纵轴是残差值(范围 -2.5 到 17.5 )。绿色曲线呈现残差在不同时间点的波动情况,可直观看到残差随时间的变化趋势、波动幅度,帮助判断模型预测误差是否稳定,是否存在随时间变化的规律或异常波动 。
优化建议
模型参数优化
-
Transformer 参数优化:
-
d_model:嵌入维度,控制模型对序列特征的表达能力。较大值可捕捉更复杂特征,但会增加计算量。建议从 64 或 128 开始,逐步调整。
-
nhead:注意力头数,影响模型并行计算能力和特征捕捉灵活性。通常取 8 或 16,可根据数据复杂度和计算资源调整。
-
num_layers:Transformer 层数,更多层能学习更深层特征抽象,但过深会导致过拟合。一般从 3 到 6 层开始尝试。
-
-
XGBoost 参数优化:
-
max_depth:树的最大深度,控制模型复杂度和过拟合风险。建议从 3 到 10 之间进行调整。
-
learning_rate:学习率,控制每棵树的贡献权重。通常取 0.01 到 0.3 之间,较小值需更多迭代次数。
-
subsample:子采样比例,用于防止过拟合和加速训练。建议从 0.7 到 0.9 之间调整。
-
colsample_bytree:每棵树列采样比例,增加模型随机性。建议从 0.7 到 0.9 之间调整。
-
-
特征工程优化:
-
周期特征:加入时间序列的周期性特征,如小时、天、周、月等,帮助模型捕捉周期性模式。
-
滚动平均:计算不同窗口大小的滚动平均值,平滑短期波动,突出长期趋势。
-
滞后值:增加多个滞后时间步的特征,提供时间序列的历史上下文信息。
-
-
Transformer 特征提取优化:
-
多时间步平均:提取 Transformer 最后多个时间步的输出并计算平均值,相比单点提取更稳定,能减少噪声影响。
-
-
防止过拟合:
-
EarlyStopping:在训练过程中使用早停技术,监控验证集误差,当误差在若干轮内不再下降时停止训练,防止过拟合。
-
调参流程
-
数据准备与初步划分:
-
使用时间序列交叉验证(TimeSeriesSplit)对数据进行划分,确保模型评估过程中没有数据泄露。这种方法能保持数据的时间顺序,使模型在训练时只能使用过去信息预测未来。
-
-
初始化模型结构:
-
根据数据特征初步设置 Transformer 和 XGBoost 的模型参数。先构建一个性能合理的基础模型。
-
-
固定 Transformer,调优 XGBoost:
-
使用 GridSearchCV 或 RandomizedSearchCV 对 XGBoost 的超参数(如 max_depth、learning_rate、subsample 等)进行系统搜索,找到使模型在验证集上表现最佳的参数组合。这一步的目的是让 XGBoost 模型在给定的特征(包括 Transformer 提取的特征)上达到最佳拟合效果。
-
-
固定 XGBoost 结构,微调 Transformer:
-
保持 XGBoost 模型结构不变,使用类似的方式对 Transformer 的参数(如 d_model、nhead、num_layers 等)进行调整。这一步旨在优化特征提取过程,为 XGBoost 提供更高质量的输入特征。
-
-
联合调优:
-
在分别优化两个模型的基础上,考虑两者参数的协同作用,进行小范围的联合调参,以进一步提升整体性能。
-
-
监控验证集误差与调整训练参数:
-
在训练过程中持续监控模型在验证集上的误差变化。根据误差曲线调整学习率与 batch_size:
-
学习率调整:若验证误差变化缓慢,适当提高学习率以加快收敛;若验证误差出现波动或发散,降低学习率以稳定训练。
-
batch_size 调整:较小的 batch_size 可提供噪声估计,有助于泛化,但增加训练时间;较大的 batch_size 提供稳定梯度估计,加快收敛。根据硬件资源和模型训练状态进行动态调整。
-
-
-
特征与领域知识整合:
-
在特征工程阶段,尽可能添加与领域知识相关的辅助特征。例如,在金融时间序列预测中,可添加宏观经济指标、市场情绪指数等。此外,拓展模型为多变量时间序列分析,利用变量间的相互关系提高预测精度。
-
通过上述优化建议和调参流程,我们可以更系统地提升 Transformer 与 XGBoost 协同模型在时间序列建模中的性能,使其在复杂的预测任务中发挥更大的潜力。