PPO、DPO和GRPO的区别
一、 核心思想一句话概括
首先,我们用三个比喻来快速理解它们的核心思想:
-
PPO (近端策略优化): 「比武招亲」
- 模型(AI)通过试错和与裁判(奖励模型)的互动来学习。它生成多个回答,裁判给每个回答打分(奖励),模型的目标是调整自己,使自己更可能生成高分的回答,同时避免与之前的自己差别太大(“近端”的含义)。
-
DPO (直接偏好优化): 「父母撮合」
- 直接给模型看人类标注的“好答案”和“坏答案”的成对样本(
(winner, loser))。模型不需要通过裁判打分,而是直接学习模仿“好答案”的风格和模式,并远离“坏答案”。它直接优化了偏好排序的概率。
- 直接给模型看人类标注的“好答案”和“坏答案”的成对样本(
-
GRPO (全局回报优化): 「非诚勿扰」
- 这是 DeepSeek 团队提出的新方法。它像 DPO 一样使用成对偏好数据,但整个训练过程被组织成一场“竞赛”。模型生成的多个回答相互竞争,基于一个全局的、稀疏的奖励(比如只有一个回答被选中)来更新策略,更适合长文本、多回合的复杂对齐任务。
二、 详解其原理
1. PPO (Proximal Policy Optimization)
目标: 在不知道真实奖励函数的情况下,通过一个代理奖励模型 (Reward Model) 来优化策略(模型本身)。
流程(以微调LLM为例):
- 准备奖励模型 (RM): 首先需要训练一个独立的奖励模型。这个RM通过人类对回答的偏好(如 A > B)数据训练而成,学会给好的回答打高分,坏的回答打低分。
- 微调过程:
- 采样 (Sampling): 让当前需要微调的模型(策略模型)针对同一个提示 (Prompt) 生成多个回答。
- 评分 (Scoring): 用训练好的奖励模型 (RM) 为每一个生成的回答计算一个奖励分数 (Reward)。
- 优化 (Optimization): 模型的目标是最大化这个奖励的期望。关键约束是 「近端」:在更新参数时,要确保新的策略(模型)不会与旧的策略偏离太远,以防止训练崩溃(生成乱码)。这是PPO稳定性的核心。
优点: 非常通用和强大,是强化学习领域的标杆算法。
缺点:
- 流程复杂: 需要额外训练一个高精度的奖励模型 (RM),成本高。
- 稳定性挑战: 虽然叫“近端”优化,但训练过程中仍需精心调参来保持稳定。
- 奖励黑客 (Reward Hacking): 模型可能会学会生成迎合奖励模型但不合人类直觉的回答(例如,包含某些高分关键词但内容空洞)。
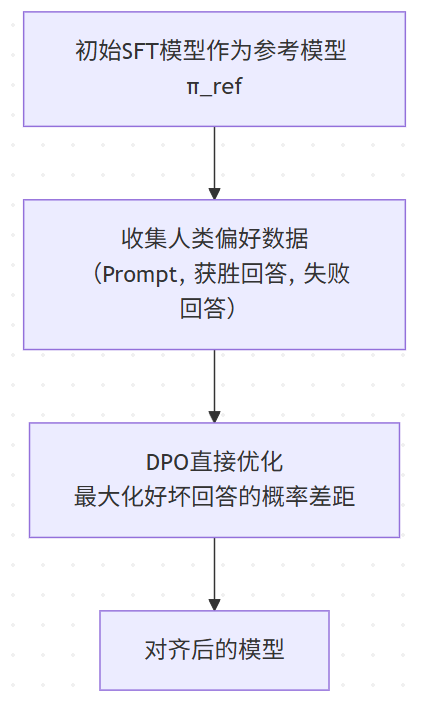
2. DPO (Direct Preference Optimization)
目标: 省去训练奖励模型 (RM) 的步骤,直接从人类偏好数据中优化模型。
核心洞察: 作者发现,在一定的约束条件下,最优策略(我们想要的对齐后的模型)和最优奖励函数之间存在着解析解关系。这意味着我们可以绕过奖励建模,直接通过数学变换将偏好数据嵌入到损失函数中。
流程:
- 准备数据: 只需要成对的偏好数据
(x, y_w, y_l),其中对于提示x,y_w是人类偏好的回答(winner),y_l是被拒绝的回答(loser)。不需要奖励分数。 - 优化损失函数: 使用一个非常巧妙的损失函数,其核心是 Bradley-Terry 模型:
L_DPO = -E[(x, y_w, y_l)] [ log σ( β * log(π_θ(y_w|x) / π_ref(y_w|x)) - β * log(π_θ(y_l|x) / π_ref(y_l|x)) ) ]π_ref: 是初始的参考模型(SFT模型),在训练中固定不变。π_θ: 是当前正在被优化的模型。β: 是一个温度参数,控制模型偏离参考模型的程度。
直观理解: 这个损失函数是在最大化模型赋予“好回答” y_w 的概率与“坏回答” y_l 的概率之间的差距。模型通过不断拉大这个差距来学习人类的偏好。
优点:
- 极其简单: 无需训练奖励模型,直接端到端微调,大大简化了训练流程。
- 非常稳定: 由于损失函数直接依赖于参考模型,训练过程比PPO稳定得多,不易崩溃。
- 效果卓越: 在许多基准测试上,效果达到甚至超过了PPO。
缺点:
- 严重依赖于高质量的偏好数据。数据中的噪声会对训练产生较大影响。
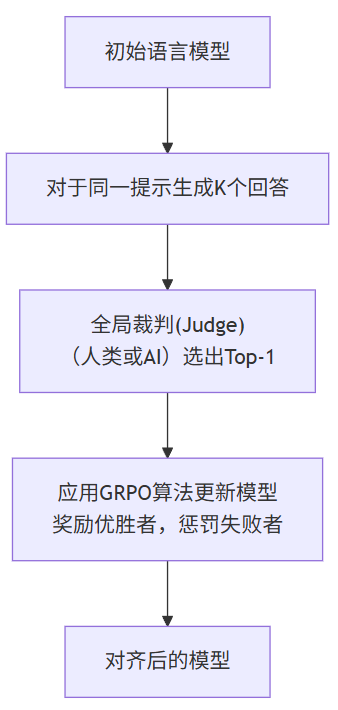
3. GRPO (Global Reward Optimization)
目标: 解决在长文本、多回合对话等复杂任务中,奖励稀疏化和全局一致性的问题。
核心思想: 在复杂任务中,一个回答的“好”不是由局部决定的,而是需要全局考量。GRPO将对话或长文本生成视为一个竞赛环境。
流程:
- 采样: 对于同一个提示
x,让当前模型生成 K 个 完整的回答(例如 K=4)。这 K 个回答构成一个“竞赛组”。 - 评判: 由一个评判者 (Judge) 从这 K 个回答中选出一个唯一的优胜者 (Top-1)。这个评判者可以是人类标注员,也可以是一个强大的AI裁判(如GPT-4)。注意,这里只产生一个全局的、稀疏的奖励信号( winner = 1, losers = 0),而不是给每个回答打分。
- 优化: 使用一种称为 「分组策略梯度 (Group-wise Policy Gradient)」 的算法。只有获胜的回答会获得正反馈,模型会学习增加生成该回答的概率;而失败的回答获得负反馈,模型会降低生成它们的概率。同样,它也有约束来防止策略偏离太远。
为什么适合长文本? 因为它评判的是整个回答的全局质量,而不是一句话中的一个词或一个片段。这避免了在长文本生成中频繁进行不连贯的局部优化。
优点:
- 解决稀疏奖励: 特别适用于奖励信号稀疏的复杂任务(写小说、长对话)。
- 全局一致性: 鼓励模型生成整体上更一致、更优秀的回答。
- 高效: 相比需要为每个片段打分的某些方法,GRPO的评判成本相对较低(只需选最优)。
缺点:
- 需要能够进行可靠全局评判的“裁判”(人类或超强AI),成本可能较高。
- 目前还比较新,实践和验证相对PPO/DPO较少。
三、 对比与总结
| 特性 | PPO | DPO | GRPO |
|---|---|---|---|
| 核心思想 | 通过奖励模型代理优化 | 直接从偏好数据中优化 | 在全局竞赛中优化 |
| 所需数据 | 需要奖励模型(或人类评分) | 成对偏好数据 (winner, loser) | 成组回答及其全局排名/选择 |
| 训练复杂度 | 高(需先训RM,再PPO微调) | 低(直接端到端训练) | 中(需采样组并进行全局评判) |
| 稳定性 | 较低,需精心调参 | 高,得益于显式约束 | 中等,依赖于评判质量 |
| 奖励信号 | 稠密(每个回答都有分数) | 隐含在损失函数中 | 稀疏(仅全局Top-1获胜) |
| 适用场景 | 通用,但更成熟 | 通用,尤其适合迭代式偏好学习 | 长文本、多回合复杂任务 |
| 比喻 | 比武招亲 | 父母撮合 | 非诚勿扰 |
演进关系
可以看作是一个不断简化和专业化的过程:
- PPO 是奠基性的工作,证明了RLHF(基于人类反馈的强化学习)的可行性,但流程复杂。
- DPO 是革命性的突破,它发现了PPO目标的数学本质,省去了复杂的奖励建模步骤,极大地降低了偏好对齐的门槛,成为当前的主流方法。
- GRPO 是针对PPO/DPO在长上下文、稀疏奖励场景下的不足提出的专业化解决方案。它不是为了替代DPO,而是为了处理DPO可能不擅长的特定任务。
如何选择?
- 对于大多数通用对话和指令跟随任务,DPO 是目前的最佳选择,因为它简单、稳定、高效。
- 如果你需要处理长文写作、多轮对话对齐等任务,并且有强大的评判能力,可以探索 GRPO。
- PPO 仍然非常强大和通用,在许多工业级应用中,由于其成熟度,依然被广泛使用。