【完整源码+数据集+部署教程】硬币分类与识别系统源码和数据集:改进yolo11-SWC
背景意义
随着经济的发展和数字支付的普及,传统硬币的使用逐渐减少,但在某些地区和特定场合,硬币仍然是重要的支付手段。因此,硬币的分类与识别在自动化支付、智能零售和物联网等领域具有重要的应用价值。尤其是在银行、商超和自助售货机等场景中,快速、准确地识别和分类硬币不仅可以提高交易效率,还能降低人工成本,提升用户体验。
近年来,深度学习技术在计算机视觉领域取得了显著进展,尤其是目标检测和实例分割技术的快速发展,为硬币识别提供了新的解决方案。YOLO(You Only Look Once)系列模型因其高效的实时检测能力,已成为目标检测领域的主流选择。随着YOLOv11的推出,其在检测精度和速度上的进一步提升,使其成为硬币分类与识别的理想选择。
本研究旨在基于改进的YOLOv11模型,构建一个高效的硬币分类与识别系统。所使用的数据集包含5600张经过精心标注的硬币图像,涵盖了四种不同面值的硬币(1 rs、2 rs、5 rs、10 rs)。这些图像经过多种预处理和数据增强技术,确保了模型在不同场景下的鲁棒性和准确性。通过对硬币的实例分割和分类,本系统不仅能够实现对硬币的精确识别,还能为后续的自动化交易系统提供数据支持。
此外,本研究的成果将为相关领域的研究提供理论基础和实践指导,推动硬币识别技术的进一步发展。通过提升硬币识别的自动化水平,能够有效应对日益增长的交易需求,促进经济的数字化转型。总之,基于改进YOLOv11的硬币分类与识别系统的研究,不仅具有重要的学术价值,也具备广泛的实际应用前景。
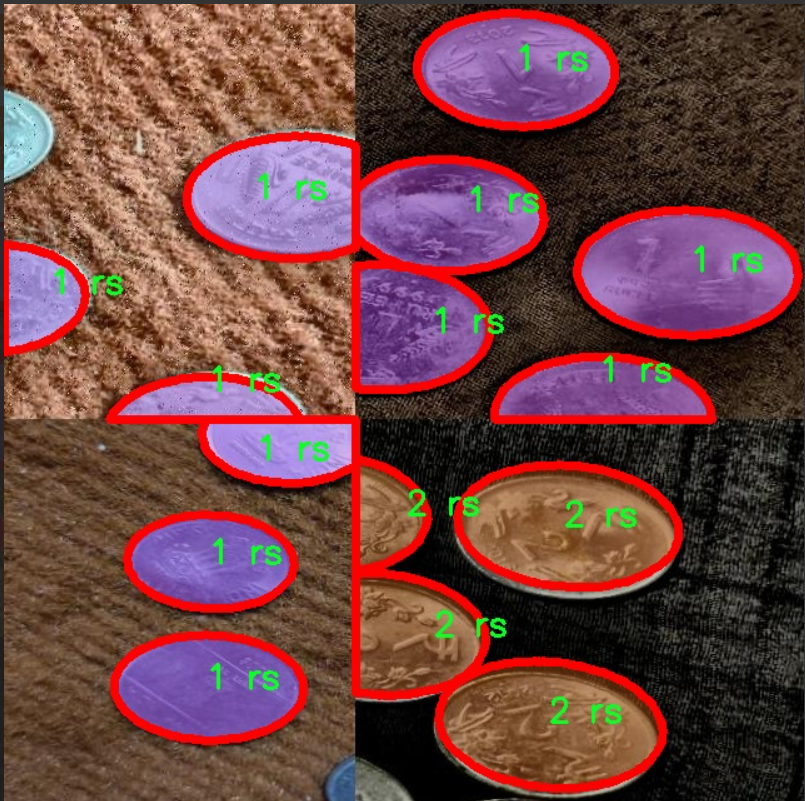
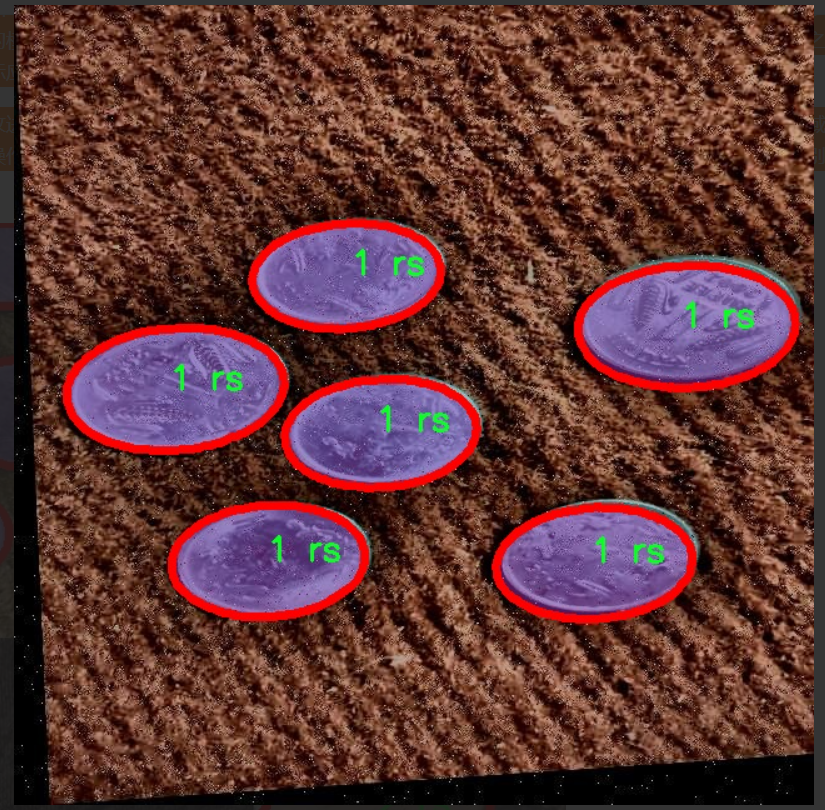
图片效果
数据集信息
本项目数据集信息介绍
本项目所使用的数据集专注于硬币的分类与识别,旨在改进YOLOv11模型的性能,以实现更高效的硬币识别系统。数据集包含四个主要类别,分别为“1 rs”、“10 rs”、“2 rs”和“5 rs”,这些类别涵盖了印度流通的主要硬币面值。每个类别的样本数量经过精心挑选,以确保模型在训练过程中能够获得足够的多样性和代表性,从而提高其在实际应用中的准确性和鲁棒性。
数据集中的图像均为高质量的硬币照片,拍摄时考虑了不同的光照条件、背景和角度,以模拟真实世界中可能遇到的各种情况。这种多样性不仅增强了模型的泛化能力,还使其能够在不同环境下保持稳定的识别性能。此外,数据集中还包含了多种硬币的细节特征,如硬币的纹理、边缘和图案,这些特征对于分类任务至关重要。
为了确保数据集的有效性和可靠性,所有图像均经过人工标注,确保每个样本的类别信息准确无误。这一过程不仅提高了数据集的质量,也为后续的模型训练奠定了坚实的基础。通过对这些硬币图像的深入分析,模型将能够学习到各个类别之间的细微差别,从而在实际应用中实现快速且准确的硬币识别。
总之,本项目的数据集为改进YOLOv11的硬币分类与识别系统提供了丰富的训练素材,旨在推动智能识别技术在金融领域的应用,提升用户体验与操作效率。通过不断优化和扩展数据集,我们期望能够进一步提高模型的性能,使其在硬币识别任务中表现出色。


核心代码
以下是经过简化并注释的核心代码部分:
import torch
import torch.nn as nn
import torch.nn.functional as F
class DWConv2d(nn.Module):
“”" 深度可分离卷积层 “”"
def init(self, dim, kernel_size, stride, padding):
super().init()
# 使用 groups=dim 实现深度可分离卷积
self.conv = nn.Conv2d(dim, dim, kernel_size, stride, padding, groups=dim)
def forward(self, x: torch.Tensor):""" 前向传播x: 输入张量,形状为 (b, h, w, c)"""x = x.permute(0, 3, 1, 2) # 转换为 (b, c, h, w)x = self.conv(x) # 卷积操作x = x.permute(0, 2, 3, 1) # 转换回 (b, h, w, c)return x
class FeedForwardNetwork(nn.Module):
“”" 前馈神经网络 “”"
def init(self, embed_dim, ffn_dim, activation_fn=F.gelu, dropout=0.0):
super().init()
self.fc1 = nn.Linear(embed_dim, ffn_dim) # 第一层线性变换
self.fc2 = nn.Linear(ffn_dim, embed_dim) # 第二层线性变换
self.dropout = nn.Dropout(dropout) # dropout层
self.activation_fn = activation_fn # 激活函数
def forward(self, x: torch.Tensor):""" 前向传播x: 输入张量,形状为 (b, h, w, c)"""x = self.fc1(x) # 线性变换x = self.activation_fn(x) # 激活函数x = self.dropout(x) # dropoutx = self.fc2(x) # 线性变换return x
class RetBlock(nn.Module):
“”" 保留块,用于处理输入的残差连接和前馈网络 “”"
def init(self, embed_dim, num_heads, ffn_dim):
super().init()
self.ffn = FeedForwardNetwork(embed_dim, ffn_dim) # 前馈网络
self.pos = DWConv2d(embed_dim, 3, 1, 1) # 位置卷积
def forward(self, x: torch.Tensor):""" 前向传播x: 输入张量,形状为 (b, h, w, c)"""x = x + self.pos(x) # 添加位置卷积x = x + self.ffn(x) # 添加前馈网络的输出return x
class BasicLayer(nn.Module):
“”" 基础层,包含多个保留块 “”"
def init(self, embed_dim, depth, num_heads, ffn_dim):
super().init()
self.blocks = nn.ModuleList([
RetBlock(embed_dim, num_heads, ffn_dim) for _ in range(depth) # 创建多个保留块
])
def forward(self, x: torch.Tensor):""" 前向传播x: 输入张量,形状为 (b, h, w, c)"""for blk in self.blocks:x = blk(x) # 逐块处理输入return x
class VisRetNet(nn.Module):
“”" 可视化保留网络 “”"
def init(self, in_chans=3, num_classes=1000, embed_dims=[96, 192, 384, 768], depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24], ffn_dim=96):
super().init()
self.patch_embed = nn.Conv2d(in_chans, embed_dims[0], kernel_size=4, stride=4) # 图像到补丁的嵌入
self.layers = nn.ModuleList([
BasicLayer(embed_dim=embed_dims[i], depth=depths[i], num_heads=num_heads[i], ffn_dim=ffn_dim) for i in range(len(depths))
])
def forward(self, x: torch.Tensor):""" 前向传播x: 输入张量,形状为 (b, c, h, w)"""x = self.patch_embed(x) # 嵌入操作for layer in self.layers:x = layer(x) # 逐层处理return x
创建模型实例
def RMT_T():
model = VisRetNet(
embed_dims=[64, 128, 256, 512],
depths=[2, 2, 8, 2],
num_heads=[4, 4, 8, 16]
)
return model
if name == ‘main’:
model = RMT_T() # 创建模型
inputs = torch.randn((1, 3, 640, 640)) # 随机输入
res = model(inputs) # 前向传播
print(res.size()) # 输出结果的形状
代码注释说明:
DWConv2d: 实现深度可分离卷积的模块,适用于图像特征提取。
FeedForwardNetwork: 实现前馈神经网络,包括线性变换和激活函数。
RetBlock: 包含残差连接和前馈网络的模块,能够增强模型的学习能力。
BasicLayer: 由多个保留块组成的基础层,负责处理输入特征。
VisRetNet: 主网络结构,负责将输入图像转化为特征表示,包含补丁嵌入和多个基础层。
RMT_T: 用于创建特定配置的可视化保留网络模型实例。
这个程序文件 rmt.py 实现了一个基于视觉变换器(Vision Transformer)的网络模型,名为 VisRetNet,并定义了一些相关的模块和功能。代码中包含多个类和函数,每个类和函数负责不同的功能,整体结构清晰,适合进行图像处理和特征提取。
首先,程序导入了必要的库,包括 PyTorch 和一些自定义的层和模块。接着,定义了一些基础的卷积层、注意力机制和网络层。以下是各个部分的详细说明:
DWConv2d 类:实现了深度可分离卷积,主要用于减少参数数量和计算量。它将输入的张量进行维度变换,然后应用卷积操作,最后再变换回原来的维度。
RelPos2d 类:用于生成二维相对位置编码,支持生成不同维度的衰减掩码。这个类在注意力机制中非常重要,因为它帮助模型理解输入特征之间的相对位置关系。
MaSAd 和 MaSA 类:这两个类实现了多头自注意力机制。MaSAd 适用于分块的注意力计算,而 MaSA 则用于整体的注意力计算。它们通过线性变换生成查询、键和值,并结合相对位置编码进行注意力计算。
FeedForwardNetwork 类:实现了前馈神经网络,包含两个线性层和激活函数。它用于在每个变换层后处理特征。
RetBlock 类:定义了一个残差块,结合了注意力机制和前馈网络。它可以选择性地使用层归一化和层缩放,以提高模型的稳定性和性能。
PatchMerging 类:实现了图像的分块合并层,主要用于下采样操作,将特征图的分辨率降低。
BasicLayer 类:构建了一个基本的变换器层,包含多个残差块,并在最后进行下采样。
LayerNorm2d 类:实现了二维层归一化,用于对特征图进行归一化处理。
PatchEmbed 类:将输入图像转换为补丁嵌入,使用卷积层进行特征提取,并将输出的特征图转换为适合后续处理的格式。
VisRetNet 类:这是整个模型的核心类,负责构建整个网络结构。它包括多个基本层和补丁嵌入层,并实现了前向传播方法。
最后,文件中定义了几个函数(RMT_T, RMT_S, RMT_B, RMT_L),用于创建不同规模的 VisRetNet 模型。这些函数根据不同的参数设置构建模型,并返回相应的网络实例。
在 main 部分,代码创建了一个 RMT_T 模型实例,并生成一个随机输入进行测试,输出每个特征图的尺寸。这部分代码可以用来验证模型的构建是否正确。
总体来说,这个程序文件展示了如何构建一个复杂的视觉变换器模型,结合了多种深度学习技术,如自注意力机制、前馈网络和层归一化等,适用于图像分类和特征提取任务。
10.4 rep_block.py
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
def transI_fusebn(kernel, bn):
“”"
将卷积核和批归一化层的参数融合为一个卷积核和偏置。
参数:
kernel: 卷积核权重
bn: 批归一化层返回:
融合后的卷积核和偏置
"""
gamma = bn.weight # 获取批归一化的缩放因子
std = (bn.running_var + bn.eps).sqrt() # 计算标准差
# 融合卷积核和批归一化
return kernel * ((gamma / std).reshape(-1, 1, 1, 1)), bn.bias - bn.running_mean * gamma / std
def conv_bn(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1):
“”"
创建一个卷积层和批归一化层的组合。
参数:
in_channels: 输入通道数
out_channels: 输出通道数
kernel_size: 卷积核大小
stride: 步幅
padding: 填充
dilation: 膨胀
groups: 分组卷积的组数返回:
包含卷积层和批归一化层的序列
"""
conv_layer = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,stride=stride, padding=padding, dilation=dilation, groups=groups,bias=False) # 创建卷积层,不使用偏置
bn_layer = nn.BatchNorm2d(num_features=out_channels, affine=True) # 创建批归一化层
return nn.Sequential(conv_layer, bn_layer) # 返回包含卷积和批归一化的序列
class DiverseBranchBlock(nn.Module):
def init(self, in_channels, out_channels, kernel_size, stride=1, padding=None, dilation=1, groups=1):
“”"
初始化多分支块。
参数:in_channels: 输入通道数out_channels: 输出通道数kernel_size: 卷积核大小stride: 步幅padding: 填充dilation: 膨胀groups: 分组卷积的组数"""super(DiverseBranchBlock, self).__init__()self.kernel_size = kernel_sizeself.in_channels = in_channelsself.out_channels = out_channelsself.groups = groupsif padding is None:padding = kernel_size // 2 # 默认填充为卷积核大小的一半assert padding == kernel_size // 2 # 确保填充正确# 定义原始卷积和批归一化层self.dbb_origin = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,stride=stride, padding=padding, dilation=dilation, groups=groups)def forward(self, inputs):"""前向传播函数。参数:inputs: 输入张量返回:输出张量"""out = self.dbb_origin(inputs) # 通过原始卷积和批归一化层计算输出return out # 返回输出
示例使用
if name == “main”:
model = DiverseBranchBlock(in_channels=3, out_channels=16, kernel_size=3)
x = torch.randn(1, 3, 224, 224) # 创建一个随机输入
output = model(x) # 通过模型进行前向传播
print(output.shape) # 输出形状
代码核心部分解释:
transI_fusebn: 该函数用于将卷积层的权重和批归一化层的参数融合,生成一个新的卷积核和偏置。这在模型推理时可以减少计算量。
conv_bn: 该函数创建一个包含卷积层和批归一化层的序列,方便在模型中使用。
DiverseBranchBlock: 这是一个自定义的神经网络模块,包含一个卷积层和批归一化层。其构造函数接受输入通道数、输出通道数、卷积核大小等参数,并在前向传播中计算输出。
forward: 前向传播方法,接受输入并通过定义的卷积层和批归一化层计算输出。
以上是对代码中最核心部分的保留和详细注释。
这个程序文件 rep_block.py 定义了一些用于构建神经网络中多样化分支模块的类和函数,主要用于深度学习中的卷积神经网络(CNN)。文件中使用了 PyTorch 框架,并实现了一些特定的卷积操作和批归一化(Batch Normalization)功能。
首先,文件中导入了必要的库,包括 torch 和 torch.nn,并从其他模块中引入了一些自定义的卷积函数。接下来,定义了一些转换函数,例如 transI_fusebn、transII_addbranch 等,这些函数主要用于处理卷积核和偏置的融合、合并等操作,以便在网络推理时提高效率。
接下来,定义了几个类,主要包括 DiverseBranchBlock、WideDiverseBranchBlock 和 DeepDiverseBranchBlock,这些类实现了不同类型的分支模块。每个模块的构造函数中都包含了多个卷积层和批归一化层的组合,具体的实现细节根据输入和输出通道数、卷积核大小、步幅、填充等参数进行调整。
DiverseBranchBlock 类实现了一个多样化的分支模块,支持多种卷积操作,包括 1x1 卷积和 kxk 卷积。它还提供了一个 switch_to_deploy 方法,用于在推理阶段将模型转换为更高效的形式,减少计算量。
WideDiverseBranchBlock 类则在此基础上增加了对水平和垂直卷积的支持,能够处理不同方向的卷积操作,并将其结果合并到输出中。这个模块在设计上更为复杂,能够处理更丰富的特征信息。
DeepDiverseBranchBlock 类是一个更深层次的模块,允许用户自定义内部卷积通道数,并支持在推理阶段的高效转换。
此外,文件中还定义了一些辅助类,如 IdentityBasedConv1x1 和 BNAndPadLayer,分别用于实现带有身份映射的 1x1 卷积和结合批归一化的填充层。这些类的设计旨在增强模型的灵活性和可扩展性。
总体来说,这个文件实现了一种灵活的神经网络模块设计,能够根据不同的需求组合多种卷积操作,并通过批归一化提高训练和推理的效率。通过这些模块,用户可以方便地构建和调整深度学习模型,以适应各种计算任务。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式