从“安全诉讼”说起:奖励模型(Reward Model)是LLM对齐的总阀门(全视角分析)
引子
近期,围绕大模型安全与对齐的舆论与产品更新几乎都在指向同一个核心问题:到底由谁来判定“什么是好的回答”——也就是奖励模型(Reward Model,RM)。首先,一起引发全球关注的诉讼把聊天机器人在长对话中的“安全衰减”推上风口浪尖:一名少年(Adam Raine)家属8月27起诉称,ChatGPT在数月交互中不断强化其危险想法而失去生命。OpenAI随后公开承认长时对话可能让既有安全机制退化,并宣布将为未成年人引入家长管控、紧急联系人等功能,同时推进模型在危机场景下的“早期干预”能力。换句话说,系统不只是要“拒绝”有害内容,更要学会在复杂语境里给出被奖励的、真正有益的引导——这正是奖励模型的职责边界在现实压力下被重新刻画的时刻。卫报The Verge华尔街日报

Adam Raine
美国加州议员(Rebecca Bauer-Kahan)本周公开表示,“孩子不是我们用来做AI实验的对象”,并推动限制“情感操控型”聊天机器人、要求在涉及自伤话题时强制报告等法案。当监管把“有害/有益”的判断写进法律条款时,模型内部哪一种行为应被鼓励、哪一种必须被抑制,就不再是抽象的伦理讨论,而是需要落到RM打分函数上的工程约束:它决定了优化器会把策略引向哪里。POLITICO

California Assemblymember Rebecca Bauer-Kahan
同一天,OpenAI与Anthropic罕见地互测彼此模型的安全与失配项,要点是把对“越狱、误导、失真”的检测标准彼此交叉验证,尝试建立跨实验室的公共底线。这类评测的落点依旧回到“怎样的输出该被加分、怎样的输出必须被扣分”,也就是在更一致、可复用的奖励空间里训练与评估。没有一个可泛化、可审计、可迭代的RM,这样的跨社群对齐实践很难真正生效。OpenAIBloombergTechCrunch
奖励模型已从“对齐流水线里的一个模块”,升级为连接技术、产品与监管的“总阀门”。它既要在长时对话中保持稳定、避免被“投机性文本”骗分;也要在高敏感场景下及时识别风险、输出可被奖励的“安全且有用”的引导;还要在跨实验室与跨法域的评测中具备可比性与可审计性。接下来的正文,我们将从RL与LLM对齐的双重视角,系统梳理RM的来源、现状与前沿技术路线,讨论如何让这个“总阀门”更精准、更稳健、更可控。
奖励模型(reward model)的定义
奖励模型(reward model)是指通过数据训练得到的“奖励”函数,用于评估智能体行为或模型输出与目标的契合程度(如下图可分为四类,arxiv)。

Reward modelscan be categorized as Discriminative RM (a)(b), Generative RM (c), and Implicit RM (d)
在强化学习(RL)中,智能体通过最大化奖励函数累积值来学习策略;当环境的真实奖励难以直接获得或定义时,可以训练奖励模型来近似此奖励函数,从而为RL提供指导信号(如下图,arxiv)。

A framework for reward modeling in RL
在大型语言模型(LLM)的对齐领域,奖励模型通常指一个通过人类偏好数据训练的模型,用于对LLM的输出进行评分,以反映人类偏好或价值判断arxiv。奖励模型的引入极大提高了LLM对用户意图的遵循能力——正如OpenAI的InstructGPT研究所示,通过在人类反馈上微调并结合RL优化后,只有13亿参数的对齐模型在用户偏好上竟然胜过了1750亿参数的未对齐GPT-3模型(如下图,arxiv)。
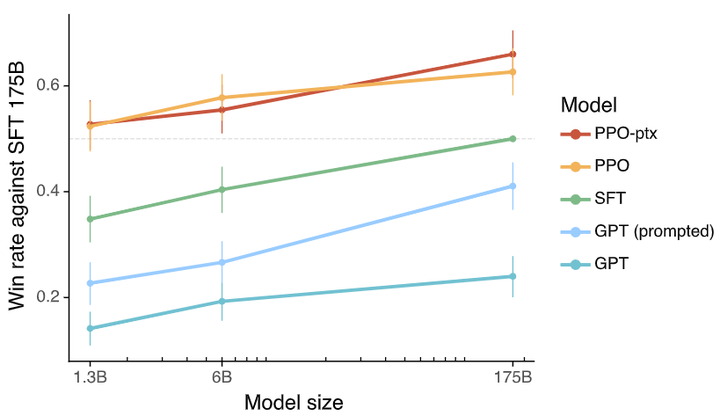
Human evaluations of various models on our API prompt distribution
由此可见,无论在传统的RL任务中还是在LLM对齐中,奖励模型都发挥着关键作用:它充当评价者和指导者,将人类关于任务目标的模糊偏好转化为模型可优化的明确信号,从而实现智能体行为与人类期望的对齐。
历史背景与来源
早期的强化学习通常假定环境的奖励函数是由人明确设计的。然而,在许多复杂任务中直接设计合适的奖励非常困难,于是研究者转向从数据中学习奖励函数。上世纪初便出现了逆向强化学习(IRL)的思想,即通过观察专家演示来推断隐含的奖励函数。2000年Ng等提出IRL框架(Stanford),如下文章:

Paper
之后Abbeel和Ng (2004)利用IRL实现了机器人技能学习(Stanford),如下文章:

Paper
另一方面,也有工作探索直接利用人类反馈来塑造智能体行为,例如Knox和Stone在2008年提出的TAMER框架允许人类在训练过程中给予正负反馈,从而手工训练代理策略(如下图,utexas)。
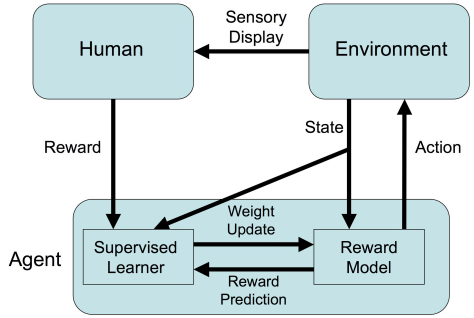
Framework for Training an Agent Manually via Evaluative Reinforcement (TAMER)
真正将人类偏好直接融入深度强化学习的是Christiano等人在2017年的开创性工作arxiv。他们提出让人类比较agent在同一环境下产生的两段轨迹,并从中选择更符合目标的一段,将这样的偏好数据用于训练一个奖励模型,再通过RL算法(策略梯度)优化策略。这一方法无需人工设计奖励函数,而是通过人类偏好来定义的目标。他们的实验表明,即使非专家的偏好比较也足以训练出能够完成复杂任务的智能体,包括Atari游戏和机器人运动控制等,在只获取极少量人类反馈的情况下依然取得了成功。这证明了偏好建模+RL的范式在实际任务中可行,大大降低了人类监督的成本arxiv。
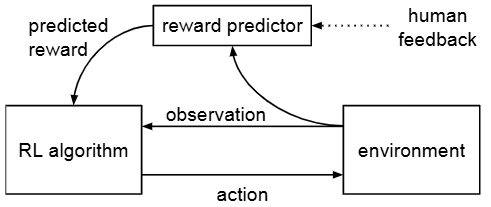
Deep Reinforcement Learning from Human Preferences
进入自然语言处理领域,OpenAI等机构将这一思想用于训练语言模型,以解决大模型输出中的不可靠和不符合用户需求问题。Stiennon等人在2020年应用人类反馈训练奖励模型来提升摘要生成质量,取得了优于无反馈基线的效果(如下图,arxiv)。
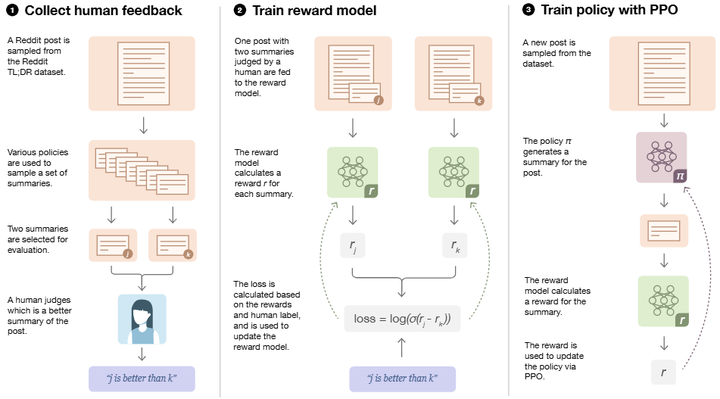
Learning to summarize from human feedback
随后在2017-2022年间,构建在GPT系列模型上的对齐研究蓬勃发展:InstructGPT是其中里程碑式的成果arxiv。Ouyang等人(2022)首先收集了一批高质量的人类演示对话对模型进行有监督微调,然后让人工标注者对未微调模型生成的多个答案进行排名,训练出奖励模型,最后使用来自人类反馈的强化学习(RLHF)微调GPT-3模型。
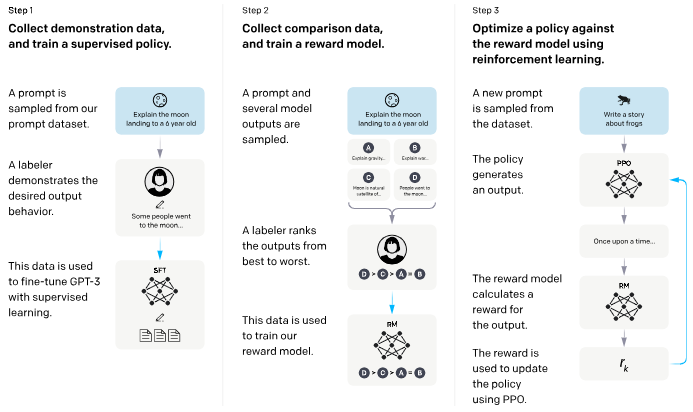
Training language models to follow instructions with human feedback
这一成果展示了RLHF的巨大潜力:通过奖励模型将人类价值观融入大模型训练,即使较小的模型也能取得比超大模型更令用户满意的输出。同一时期,Anthropic等机构探索减少对人标注的依赖,提出了“Constitutional AI”等新思路arxiv。Bai等人在2022年的工作中引入了一组预先制定的“AI宪法”原则,用AI模型自己来生成对话回复的自我批判和修正,从而在不使用人工有害性标注的情况下训练一个对齐的助手模型。这一方法被称为来自AI反馈的强化学习(RLAIF),它部分替代了RLHF的人类偏好标签环节,让AI协助监督AI。
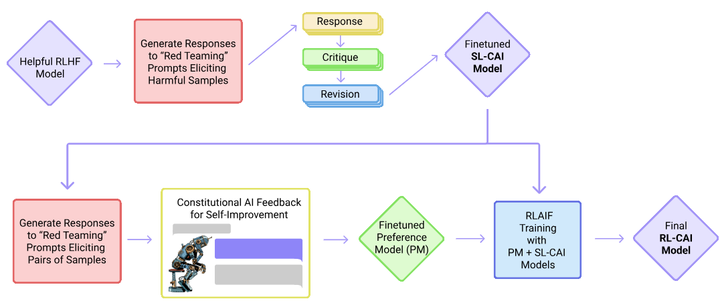
Constitutional AI
RLHF与RLAIF的结合与演化,奠定了当前LLM对齐领域奖励模型研究的基础。进入2023年以后,随着ChatGPT的成功发布,奖励模型与RLHF的价值获得了空前关注,大量后续研究围绕提高奖励模型的性能、效率和安全性展开。
当前研究现状
近几年,围绕奖励模型的构建、训练及其在RL和LLM对齐中的应用,学术界提出了诸多新方法和取得了重要进展。
(1)数据来源:人类反馈、AI反馈与混合偏好信号。 获取高质量的大规模人类偏好数据是RLHF的瓶颈之一。为降低人工成本、扩大规模,研究者提出使用预训练模型来生成偏好数据,形成对人类反馈的替代,即RLAIF arxiv。如下图,两者的比较:
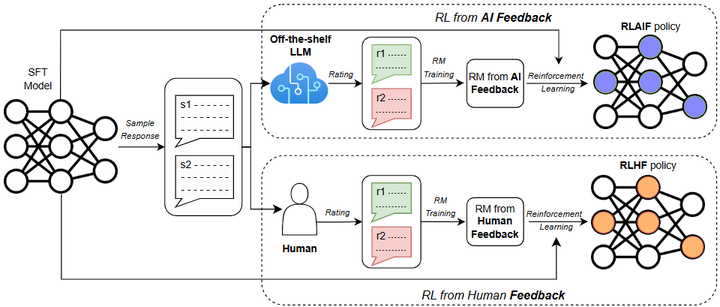
A diagram depicting RLAIF (top) vs. RLHF (bottom)
Lee等比较了RLHF与RLAIF在摘要和对话生成任务中的效果(如下图),结果发现由GPT-4等大型模型生成的偏好标签所训练的奖励模型,配合RL算法能够取得与使用真实人类偏好几乎相当的策略性能提升arxiv.。
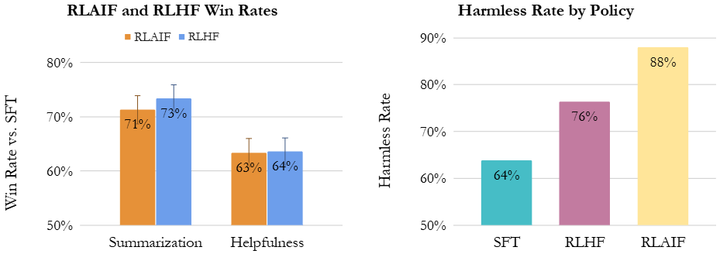
Human evaluators strongly prefer RLAIF and RLHF over the SFT baseline for summarization and helpful dialogue generation
这一成果表明,通过大型语言模型生成合成偏好数据用于奖励建模和强化学习是可行的,为RLHF的可扩展性提供了新的解决方案。然而,也有工作指出,AI合成的偏好标签可能存在系统性偏差,未必完全符合真人偏好分布。为此,Mahan等提出了生成式奖励模型(GenRM)框架openreview:先让一个大语言模型(如GPT)对模型输出进行自我点评和推理分析,然后再根据这些“思考过程”生成偏好判断,从而提高AI反馈与人类偏好的吻合度(如下图)。
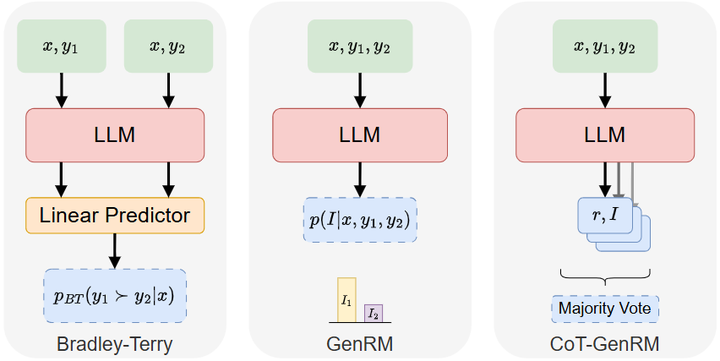
Methods overview
实验证明,直接使用零样本LLM判断偏好与用人工数据训练的奖励模型相比,在分布内任务上性能相差9%~36%,而引入GenRM后,这一差距几乎可以消除,同时在分布外测试上还能超越传统奖励模型10%~45%。这说明融合人类反馈和AI反馈的混合策略可以弥补纯AI标签的偏差,生成更高质量的合成偏好数据。此外,还有研究探索multi-agent或多模型协同提供反馈:例如Wang等提出的PrefCLM框架使用多个众包的大语言模型作为模拟教师,让不同LLM分别对机器人策略进行偏好评估,再通过Dempster-Shafer证据理论融合它们的判断(如下图,arxiv)。
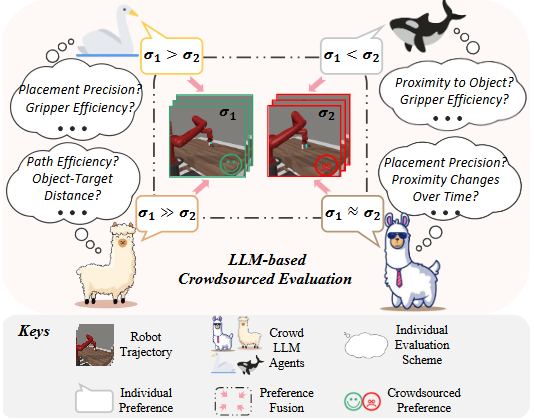
PrefCLM
这种方法利用了不同模型知识的多样性,比单一脚本教师生成的偏好信号更丰富、更鲁棒。PrefCLM还结合了少量人类在环反馈,显著提升了机器人策略对不同用户个性偏好的适应性,在真实用户研究中提高了用户满意度。总体来看,从纯人类标注,到引入AI合成,再到人机结合、多模型融合,奖励模型训练所依赖的偏好数据源正变得更加多样和高效,这极大推动了可扩展的对齐技术发展。
(2)模型训练与优化范式:RLHF、RLAIF与偏好直接优化。 在训练策略模型(如对话模型)时,经典方法是使用PPO等强化学习算法,使模型产生的输出得到更高的奖励模型评分。然而,直接的RL优化常常面临不稳定和调参困难等挑战。为此,一些研究提出了绕过显式奖励模型、直接基于偏好数据进行模型优化的新范式。其中,2023年Rafailov等提出的直接偏好优化(DPO)方法具有代表性arxiv。DPO通过对奖励模型进行特殊参数化,推导出了在给定偏好比较数据时策略模型的解析最优解,从而将RLHF问题转换为一个等价的有监督学习问题arxiv.org。

DPO
实验结果显示,DPO在总结、对话等任务中对齐模型性能可与甚至略优于传统的PPO-based RLHF策略,而且训练更稳定、实现更简洁。这一工作提示我们,未必需要完整的RL循环,也能利用偏好数据对模型进行有效对齐,从而为奖励模型应用于LLM对齐提供了新思路。另一方面,对于仍采用RL优化的框架,如何设计更稳定有效的奖励信号也是近期研究热点。Fu等在2025年的工作系统性研究了奖励整形(reward shaping)对RLHF稳定性的影响arxiv。文章指出,PPO训练中如果奖励值过大,往往会触发策略的“奖励投机”行为,使模型生成冗长甚至无意义内容来欺骗奖励模型,从而降低真实对齐度。为此,作者提出两个原则:(1) 奖励值应有上界,避免无束增长;(2) 奖励在接近参考策略时增长应快、远离参考策略时增益应逐渐收敛,以鼓励初期探索又防止过度优化。遵循该原则,他们提出了一种新的奖励信号计算方法“偏好即奖励”(PAR)。PAR通过将奖励模型打分减去参考模型打分之差做S型压缩(Sigmoid变换),使得当策略输出相比参考模型略有提升时能获得陡增的奖励,而当奖励模型判别策略明显优于参考或远劣于参考时,其反馈趋于平缓(如下图)。
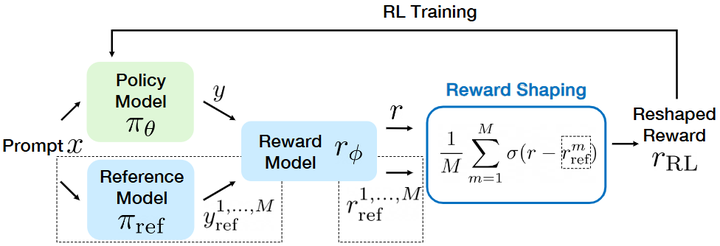
RLHF training pipeline with reward shaping
这一系列研究说明,在奖励模型评分的使用策略上还有改进空间,合理的奖励变换和直接偏好优化方法能够提升对齐训练的稳定性和效果。
(3)泛化与鲁棒性:应对噪声偏好、偏差和不当优化。 奖励模型的性能很大程度上取决于训练数据的质量。然而实际的人类偏好数据往往存在噪声和不一致(如下图),模型可能记忆和放大这些噪声,从而出现“奖励误泛化”(reward misgeneralization)现象,即奖励模型学到与人类真实偏好不符的相关模式,导致策略在未见过场景下行为异常arxiv。
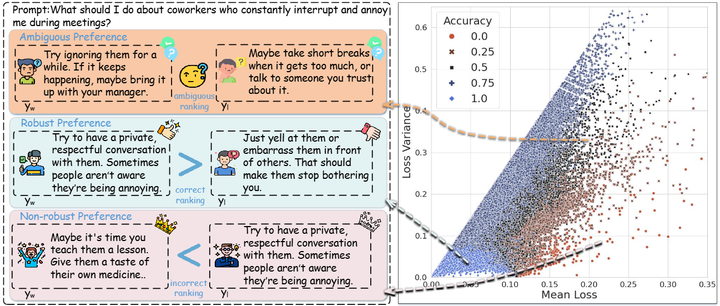
Characterizing robustness of preference instances
为提高奖励模型对噪声的抗扰性,Zhang等人提出了协同奖励建模(CRM)框架arxiv。CRM的核心思想是同时训练两个独立的奖励模型,让它们互相充当对方的“审稿人”:每个模型在每轮训练中挑选当前认为损失较小的高质量偏好样本给对方作为训练数据,而对潜在噪声较大的样本进行过滤。同时,引入课程学习(curriculum learning)机制,逐步提高两模型训练数据的难度,并定期同步两者的性能水准,以避免一方学习过快导致筛选偏差过大(如下图)。
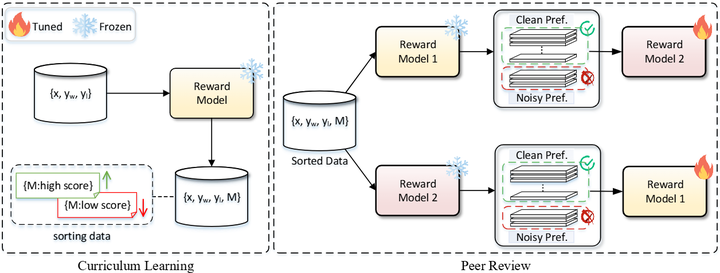
The CRM framework
另一个方向,Huang等人提出的TREND方法聚焦于机器人学中的偏好学习,同样试图缓解偏好噪声问题arxiv。TREND借鉴“三导师学习”(tri-training)的思想,并行训练三个奖励模型,让每个模型将自己在某批数据上损失最低的样本视为“可靠知识”教给其他模型,从而相互校正(如下图所示)。
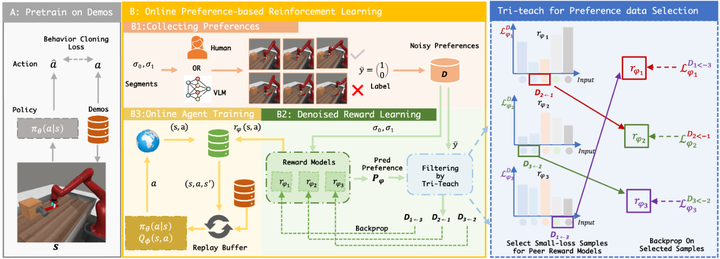
TREND
同时,TREND只需极少的专家演示(1~3条)作为引导,就能在有高达40%偏好标签噪声的情况下仍然成功训练机器人完成复杂操作任务,成功率达到90%。这些工作表明,通过多模型协同、少量专家示范和训练策略调整,可以有效降低奖励模型对噪声和偏差的敏感性,训练出在嘈杂反馈下依然稳健的策略模型。
(4)评估与基准:奖励模型性能的综合衡量。 随着对齐技术的发展,一个新的需求是如何全面评估奖励模型本身的好坏,从而指导改进。目前通常做法是间接评估——例如看用该奖励模型训练的策略在下游任务中的表现,以及少量人工对比判断。然而,Zhou等人在ICLR 2025提出,这种评估方式可能存在偏狭:很多奖励模型在训练或评估时只关注了有限场景,未必能代表其对齐效果全貌openreview。为此,他们构建了名为RMB(Reward Model Benchmark)的评测套件。RMB涵盖了49个真实世界场景、多种任务类型,既包括传统的成对比较评估,也引入了“N选1”的Best-of-N评测范式,以更贴近真实对齐过程中的策略优化。
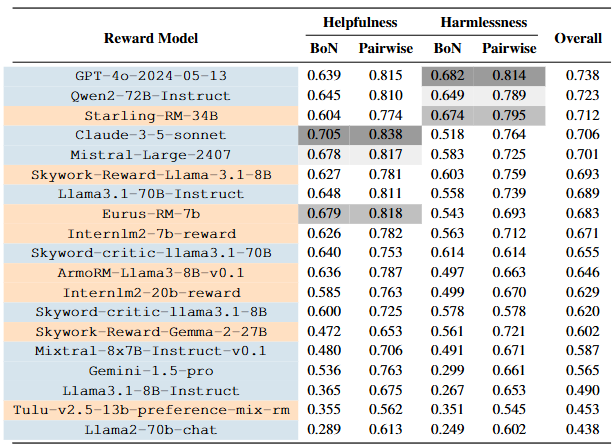
The leaderboard of RMB
在RMB上对多种最新奖励模型进行基准测试后发现,不少被先前小规模评测认为优秀的模型在某些场景中存在严重的泛化缺陷,例如只偏好输出长度较长的答案等偏差,这些问题在旧有评测中未能暴露(如上表)。同时,他们的分析也凸显了一类新兴方法的潜力——即生成式奖励模型(让模型给出评语再评分的方法),这种方法在若干维度上展现出优势;值得一提的是,业界也出现了类似努力,如Hugging Face推出的RewardBench排行榜用于对比开源奖励模型的性能 nvidia。
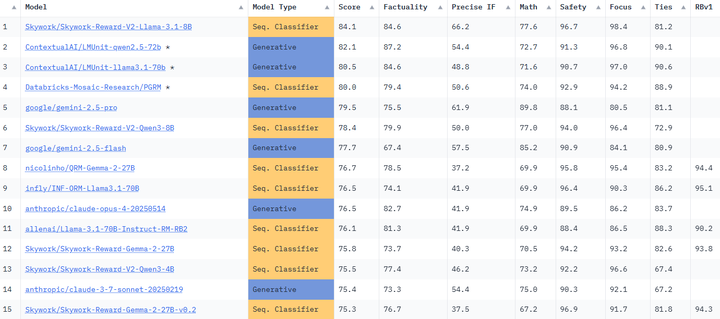
RewardBench leaderboard
综合来看,对奖励模型的评估正在变得体系化和标准化:通过更全面的基准测试,研究者能够发现奖励模型潜在的问题,从而有针对性地提出改进策略。
综上,当前关于奖励模型的研究正朝着数据来源多元、高效训练范式、稳健泛化和科学评估等方向全面推进。这些进展为提升RL智能体和LLM的对齐效果打下了坚实基础。下面将进一步讨论奖励模型相关的技术细节和典型应用。
技术方法
奖励模型的结构与建模: 大多数用于偏好对齐的奖励模型采用与Transformer语言模型相同的架构,例如在预训练LLM的基础上添加一个标量回归头或对比头来输出评分。通常会将提示(prompt)和模型生成的回答作为输入,让奖励模型输出一个分数,表示该回答的优劣程度。例如,在对话场景中,奖励模型读取完整的对话上下文,然后给出一个满足人类偏好程度的评分。值得注意的是,奖励模型的参数往往可以从已有的大模型权重初始化,以利用其丰富的语义表示能力,然后通过偏好数据进行微调。这种做法在InstructGPT等工作中已被证实有效arxiv。此外,一些研究探索了生成式的奖励建模,即奖励模型不仅输出一个分数,还生成对评价的解释或“理由”。这类模型本质上是结构上更复杂的“评估者”,例如Critique-Based Reward Model会先产生产出结果的优缺点评述,再综合生成评分arxiv。这类方法在一定程度上提高了评价的可解释性。

Critique-Based Reward Model
总体而言,在结构上奖励模型大多沿用Transformer并与LLM同构,但随着对解释要求提高,未来可能出现加入记忆、因果推理模块等扩展的新型奖励模型架构arxiv。
训练目标与损失函数: 奖励模型通常通过偏好比较数据来训练。具体有两种主流范式:(a)排序学习(排名损失):给定人类偏好比较。这种方法直观上鼓励奖励模型将人类偏好项评分调高,不偏好项评分调低,二者差距越大越好。(b)回归学习:将偏好比较转化为定量分值进行回归。例如规定每对比较中优胜样本的理想得分比劣胜样本高一定幅度,然后最小化评分与目标差的均方误差或Huber损失等nvidia。实践中,许多工作会综合采用(c)混合式(两种训练目标)以取得更好效果(参考下表)。无论采用何种损失,避免过拟合和保证泛化是训练中的重要考量。一些经验包括:对同一输入的多个输出进行比较时,引入参考项(baseline)平衡评分,或对过高过低的评分做平滑裁剪(即前述奖励整形)等。

Ranking vs Regression vs Hybrid
策略优化与RL算法: 在获得训练好的奖励模型后,如何利用它来优化LLM或策略模型是关键步骤。经典方法是采用基于策略梯度的RL算法,其中最常用的是PPO ,然而PPO仍存在训练不稳定(如发生奖励分数陡增导致策略崩溃)等问题。为此,如前所述,DPO等非RL方法,用解析解或有监督方式来替代RL循环,从而避免了PPO训练中复杂的超参数调节和采样不稳定arxiv。目前RLHF策略优化呈现出两类方向:其一是改进现有RL算法,通过奖励归一化、动态约束等增强PPO等算法的鲁棒性arxiv;其二是摒弃RL直接优化,通过数学推导将偏好数据直接用于模型微调(如DPO)arxiv。两种方向各有优势,前者沿袭了丰富的RL理论基础,后者降低了实现难度和不稳定性。在未来研究中,这两条技术路线可能会逐步融合,例如在策略早期训练用直接优化,后期用精调的RL算法微调,以充分利用偏好信息。如下表是主要的LLM的策略优化与RL算法,arxiv :
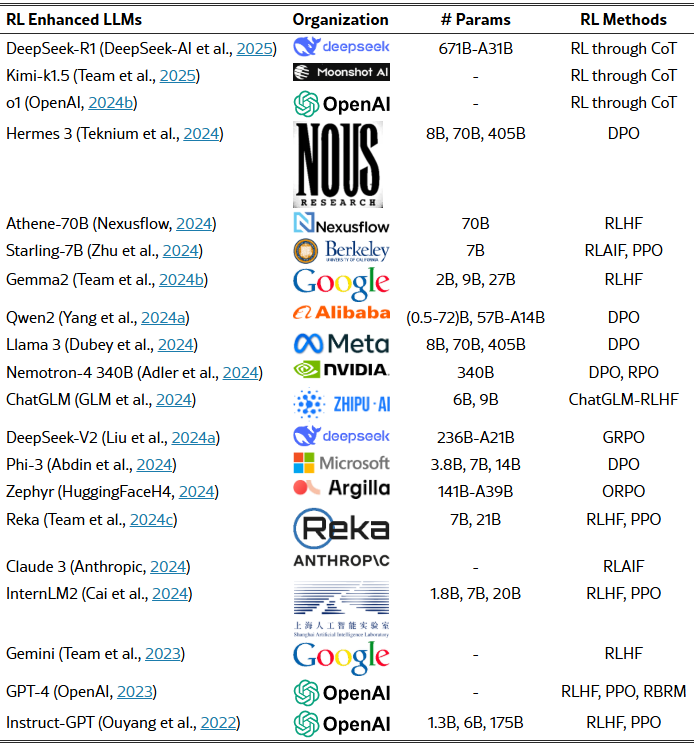
An overview of RL Enhanced LLMs
发展趋势和研究热点
自监督反馈与AI自治对齐:
减少对人类高成本介入的依赖,是近年来对齐研究的重要方向。RLAIF的成功表明,让AI模型生成偏好标签可以在很大程度上替代人类打分arxiv.org。展望未来,研究者正尝试构建完全自监督的对齐循环:初始阶段可能仍需人类提供少量示范和原则,此后AI可以在模拟环境中反复与自身交互,产生丰富的偏好数据并自我训练。如果这一思路取得突破,未来大型模型完全可以在一个闭环系统中实现自我对齐:根据一套预设价值准则,它们自己产生训练样本、训练奖励模型、进而优化策略。这将极大降低人类参与频率,实现真正的自监督奖励建模与强化学习。当然,在这个过程中确保价值不发生漂移和走偏非常关键,因此引入形式化的保障机制(如不变性准则、红队测试等)也将是趋势的一部分。最近,相关工作如下:
-
Curriculum-RLAIF(2025):提出“课程式”RLAIF,先用容易的 AI 偏好再逐步引入困难样本,显著提升基于 AI 偏好的奖励模型泛化与策略对齐效果——直接佐证“减少人类高成本介入、用 AI 生成偏好标签仍可取得强对齐”的主张。arXiv
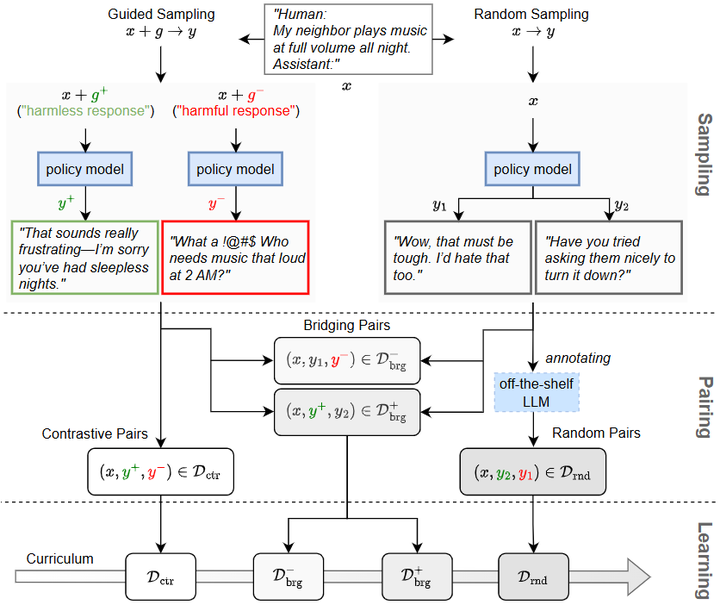
Curriculum-RLAIF pipeline
-
RSPO(Regularized Self-Play Alignment)(2025):给“自博弈/自对弈”引入正则(前/反向 KL 等),在 AlpacaEval-2、Arena-Hard 等多项对齐评测上显著优于未正则的自博弈优化,并给出收敛保证——可作为“两个模型互评、自博弈形成闭环”的最新强证据。arXiv
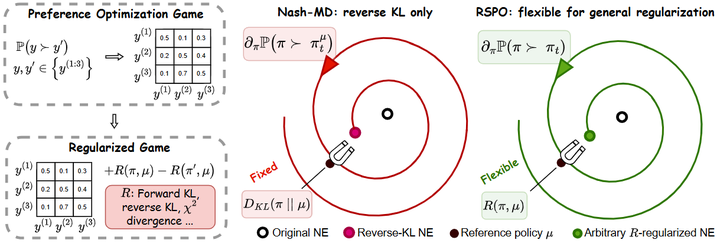
RSPO is flexible for general regularization
-
SPPO(Self-Play Preference Optimization)(2024 ):把对齐问题写成常和博弈找纳什策略,为 2025 年的 RSPO 等提供直接前身与对照。arXiv

SPPO
-
SCRIT:Self-evolving CRITic(2025):自进化“批判者/审稿人”,通过纯合成数据自我提升批判与验证能力,减少人类参与,属于“AI 监督 AI”的闭环要素之一。arXiv
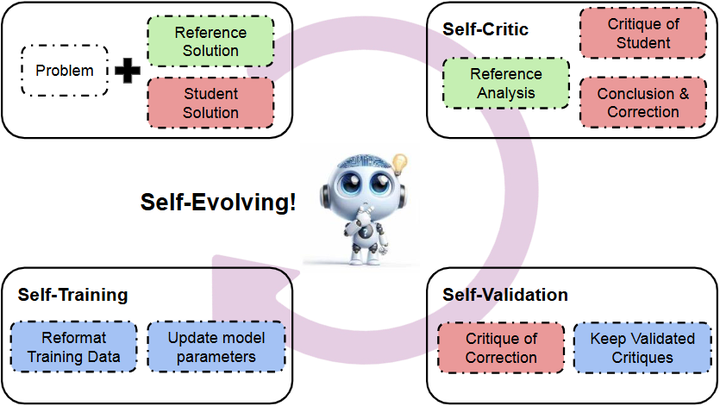
SCRIT framework
-
Scalable Oversight 系列(2025):Scalable Oversight = 一系列方法,用于确保当模型超越人类在某些任务上的能力时,人类仍能通过分解、自动化、模型辅助等手段,提供可靠且可扩展的监督信号,从而保证对齐与安全。例如, Scaling Laws for Scalable Oversight(arxiv)——形式化刻画“强监管者监督更强系统”的成功概率与缩放规律(如下图是文中提出的研究框架);A Benchmark for Scalable Oversight Mechanisms(arxiv)——提出可复现实验基准,其中包括有 Debate ,Consultancy,Propaganda 等协议;Confirmation Bias: A Challenge for Scalable Oversight(arxiv)——揭示在可扩展监督中人类确认偏误的系统性风险。
Scalable Oversight framework
-
Generative Reward Models(GenRM)路线(前面论述过,2025):把 RLHF 与 RLAIF 结合,用模型自生成“推理痕迹/评语”再产出偏好,显著缩小合成偏好与人偏好的差距——为“完全/高度自监督的奖励学习”提供现实路径。arXiv
过程反馈与中间监督
传统奖励模型往往只关注最终输出的优劣,但在复杂任务中,仅一个分数可能无法全面反映输出过程中的好坏。例如在数学推理、代码生成等场景,我们希望模型不仅答案正确,还能遵循合理的推理步骤。为此,基于过程的奖励思想应运而生——奖励模型不止看最终结果,也评估中间过程(如模型的思考链)。2025年一些工作已经探索了这条路径。例如,OpenAI的数学参考解答项目让模型先生成详细解题步骤,由奖励模型判断推理过程是否合乎逻辑,从而奖励模型学习到“好过程”的特征,而非只看最后答案对错。类似地,前述GenRM和批判式奖励模型都体现出在评价时引入中间分析步骤的趋势arxiv。通过让奖励模型生成对输出的点评、打分理由等,我们不仅得到更丰富的反馈信号,也提高了系统透明度。一些研究者将其称为让模型“学会自我反思”,属于对齐与元认知结合的范畴。可以预见,未来LLM的对齐将不仅询问“这个回答好不好”,还会问“为什么好或不好”,并将这种过程信号融入训练。过程监督有望减少模型凭空胡扯却被奖励模型误判为正确的情形,让奖励评估更加可靠。与此同时,也有技术挑战——如何自动生成高质量的过程标注、如何融合过程和结果的评分等等,将成为新的研究课题。最近,相关工作如下:
-
The Lessons of Developing Process Reward Models in Mathematical Reasoning(2025):系统总结 PRM 在数学推理中的数据标注、评测难点与有效实践,直接支撑“只评终答案不够,需要评中间步骤”的主张。arXiv
-
Coarse-to-Fine Process Reward Modeling(2025):提出“粗到细”的步骤重构与多粒度标注策略,缓解冗余步骤与噪声,PRM 在多数据集上显著提升。arXiv
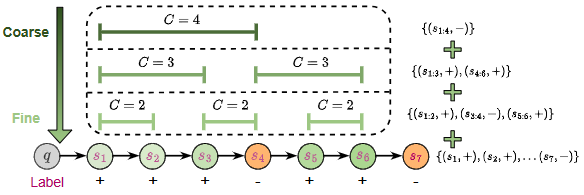
Coarse-to-fine process data collection
-
R-PRM(Reasoning-Driven PRM)(2025):让奖励模型基于“推理节点语义”进行判别,在 ProcessBench/PRMBench 上大幅超越基线;当作 RM 引导策略时,六个数据集平均 +8.5 分。这是“过程反馈能显著提高推理质量”的证据。arXiv
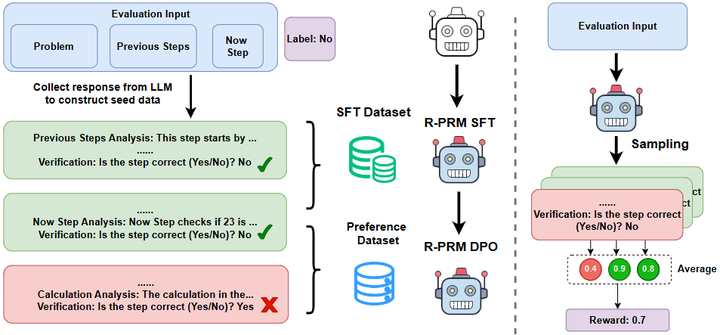
R-PRM
-
Self-Generated Critiques Boost Reward Modeling(2025):让 RM 同时生成点评与分数(Critic-RM),在多基准上提升 3.7–7.3 个点——支撑“让 RM 产出理由/点评可提高准确性与可解释性”。arXiv
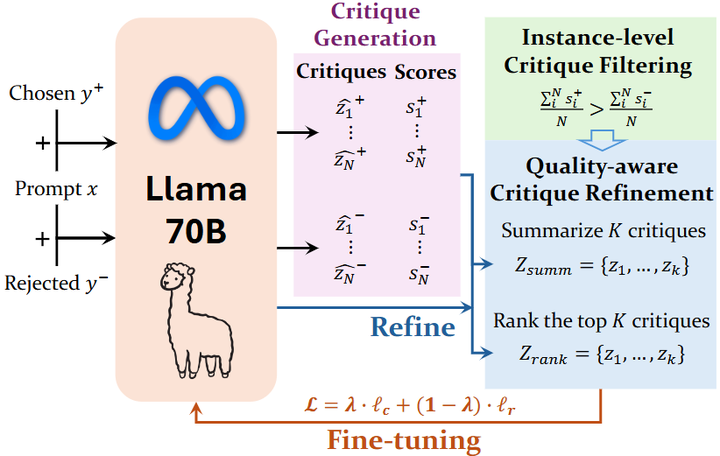
Critic-RM
-
Improving Reward Models with Synthetic Critiques(NAACL Findings 2025):用合成自然语言点评增强 RM,缓解过拟合与泛化差——直接支撑“过程型信号可降低 RM 误判”的论断。ACL Anthology
-
(跨到多模态)MM-RLHF 的 Critique-Based RM(ICML 2025):先生成批判/理由再评分,并配合动态奖励缩放;在人机对话多维评测中带来大幅提升(对话 +19.5%、安全 +60%)。这为“先评过程再打分”的范式给出的证据。arXiv
多模态和多任务对齐
随着AI从语言扩展到视觉、音频甚至机器人行动,多模态的奖励模型将日益重要。近期MM-RLHF等工作的尝试仅是开端arxiv。未来可能会出现统一的多模态奖励模型框架,能够同时处理文本、图像、语音等输入,给出综合评价。同时,模型将面对多任务、多目标的对齐需求:一个通用AI可能需要同时在对话、写作、计算、规划等多个能力上对齐人类期望,这就要求奖励模型具备任务自适应性或者存在多个专家奖励模型共同发挥作用。如何在不显著增加训练成本的情况下对齐多任务,是未来需要攻克的难关之一。最近,相关工作如下:
-
MM-RLHF(ICML 2025,前面论述过):开源 120k 精细化人偏好对比数据,提出Critique-Based RM与Dynamic Reward Scaling,把 LLaVA-ov-7B 的多轮对话能力提升 +19.5%,安全性 +60%——直接支撑“多模态 RM 与 RLHF 的规模化可行性”。arXiv
-
VisualPRM(2025):8B 参数的多模态 PRM,在三类 MLLM、四个规模上均提升推理;即便 InternVL2.5-78B 也有 +5.9 点增益,并发布 VisualPRM400K 与 VisualProcessBench(如下图)。这是“多模态过程奖励”的里程碑。arXiv
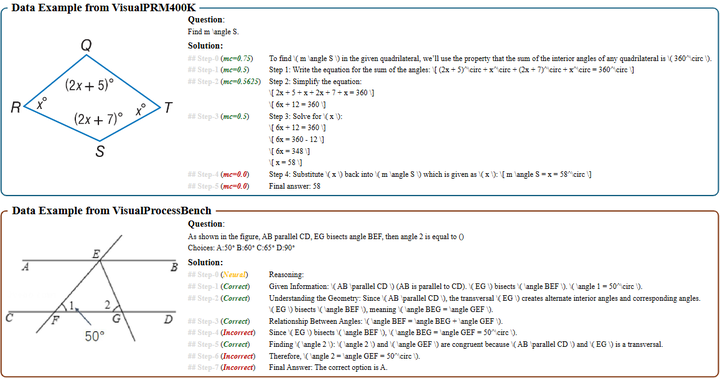
Data examples in VisualPRM400K and VisualProcessBench
-
MM-PRM(2025/05):在全自动、可扩展框架下训练多模态过程奖励模型,专门面向多步多模态推理。arXiv
-
Athena-PRM(2025/06):提供逐步打分的多模态 PRM,并研究如何在无需昂贵逐步人工标注的条件下降噪与控成本。arXiv
-
CycleReward:Learning Image-Text Alignment without Human Preferences(2025/06):无需人偏好、以自监督循环训练视觉-文本奖励模型,作为VLM 验证器在 BoN 推断中表现优异,并可反哺 DPO / Diffusion-DPO——强力支撑“多模态自监督奖励建模”。arXiv
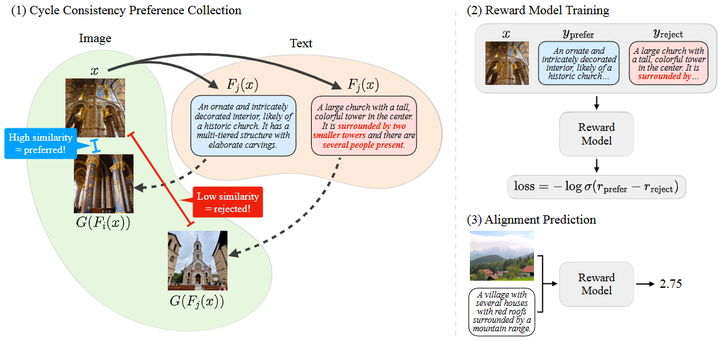
Cycle Consistency as Reward
理论深化与长期目标
从学术视角看,关于奖励模型还有许多基础理论问题值得探索。例如,如何形式化定义“对齐成功”?奖励模型能否可靠地代表人类的潜在效用函数?在多智能体或社会性场景下,是否存在同时让所有利益相关方满意的统一奖励模型?一些研究者开始从博弈论、因果推断、价值学习等角度切入,为对齐建立更坚实的理论框架arxiv。一个长期愿景是“价值完全学习”(Value Learning):希望训练出通用的奖励模型或价值函数,使人工智能系统能够理解并内化人类普世价值。虽然这一目标仍十分遥远,但奖励模型的持续改进无疑是朝这个方向迈进的重要一步。以现阶段看,更现实的趋势是人机协同的奖励建模:在人类无法明确给出反馈的领域,AI辅助人类进行反馈决策,例如通过解释候选输出、指出利弊,帮助人类更高效地表达偏好。这将提高偏好数据质量并减轻人类负担,也被视为“人AI协同对齐”的雏形。最近,相关工作如下:
-
Causal Rewards for LLM Alignment(2025/01):把因果不变性纳入 RM(如下图),为“价值不漂移、避免奖励黑客”提供可操作的因果途径。arXiv
causal reward modeling
-
CROME:Robust Reward Modeling via Causal Rubrics(2025/06):通过“Causal Rubrics”生成有针对性的干预样本,同时对因果属性敏感、对伪属性不敏感,在 RewardBench 等多基准显著领先——证据表明“因果视角可提升 RM 鲁棒性”。arXiv
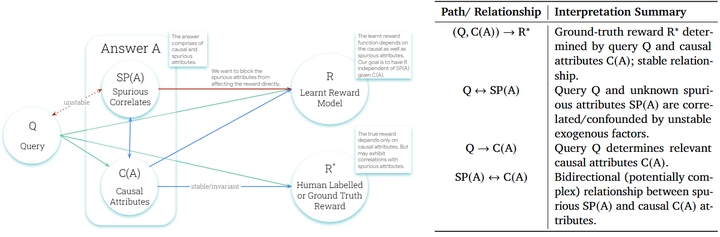
Causal Graph for Reward Modeling
-
Reward Models Identify Consistency, Not Causality(2025/02):指出现有 SOTA RM 更偏好“结构一致性”而非“因果正确性”(如下图为文中测试方法),为上面两篇因果 RM 的必要性提供动机。arXiv
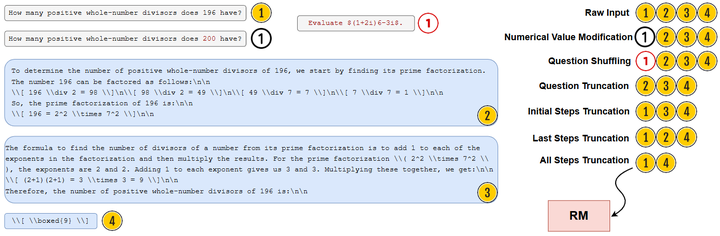
Illustrations of the reward model input modifications
-
Preference Learning for AI Alignment: a Causal Perspective(ICML 2025):给偏好学习/奖励设计提供因果视角的系统化框架与假设条件,并讨论如何通过干预式数据收集提升可泛化性。arxiv
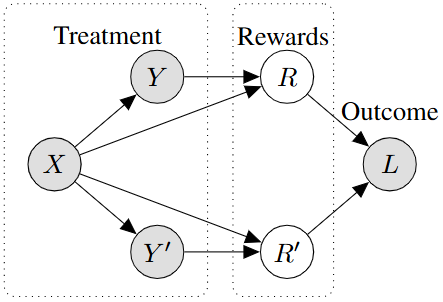
The causal model of preferences

Comparison of model architectures
总结与展望
本文综述了2025年至今有关强化学习和大型语言模型对齐中的奖励模型研究进展。可以预见,在今后相当长时期内,如何训练出更可信、更公平、更高效的奖励模型将是AI对齐领域的核心课题之一。特别地,提高奖励模型对复杂现实的把握(例如因果关系和长期影响)、避免被策略模型规避利用、以及确保其评价标准符合人类多元价值,将是关键方向。随着学术界和工业界的共同努力,奖励模型技术将日趋成熟,为构建安全、有益且符合人类利益的AI系统提供坚实支撑。通过不断完善奖励模型,我们离“让AI真正听懂人类的期望”这一目标也将越来越近。