GoogLeNet:深度学习中的“卷积网络变形金刚“
大家好!今天我们要聊一个在深度学习领域掀起革命的经典网络——GoogLeNet(又称Inception v1)。这个由Google团队在2014年提出的模型,不仅拿下了ImageNet竞赛冠军,更用"网络中的网络"设计理念彻底改变了卷积神经网络(CNN)的架构思路。
一、为什么需要GoogLeNet?
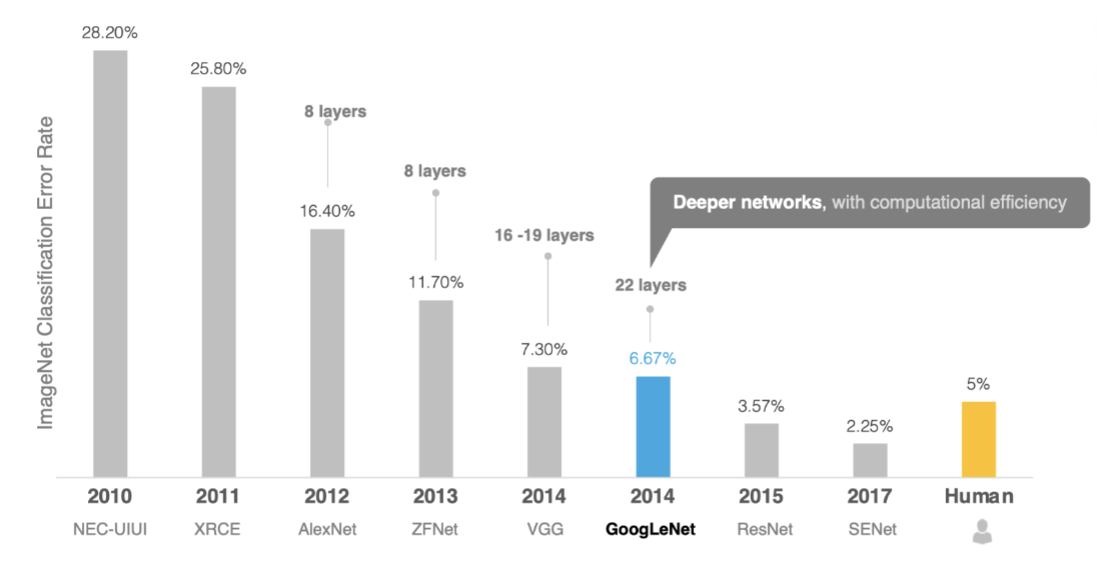
在GoogLeNet之前,主流思路是不断增加网络深度(层数)来提升性能。AlexNet(8层)、VGG(16-19层)都是这一思路的代表。但层数增加带来三大问题:
- 1.计算量爆炸 💥 - 参数过多导致训练和推理速度慢
- 2.梯度消失 📉 - 深层网络难以训练,梯度反向传播时逐渐衰减
- 3.过拟合风险 🎯 - 模型复杂度过高,容易记住训练数据而非学习泛化特征
GoogLeNet的解决之道是:“宽”而非“深”。它通过Inception模块在同一层级上并行提取多尺度特征,大幅提升特征表达能力而不显著增加计算量。
二、Inception模块:GoogLeNet的心脏
1. 原始构想:多尺度特征融合
GoogLeNet中的基础卷积块叫作Inception块,得名于同名电影《盗梦空间》(Inception)。
Inception块在结构比较复杂。如下图:
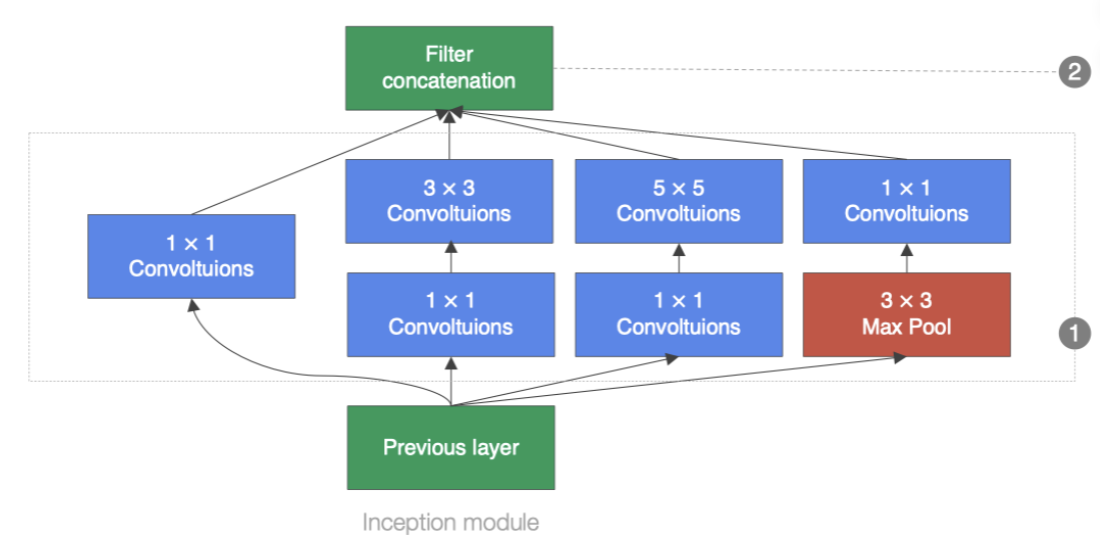
Inception块里有4条并行线路。
前3条线路使用窗口大小分别为1×1 、3×3 和5×5 的卷积层来抽取不同空间尺寸下的信息,其中中间2个线路会对输入先做 1×1卷积来减少输入通道数,以降低模型复杂度。
第4条线路则使用 3×3最大池化层,后接1×1 卷积层来改变通道数。
4条线路都使用了合适的填充来使输入与输出的高和宽一致。最后我们将每条线路的输出在通道
维上连结,并向后进行传输。
2. 致命问题:计算量爆炸!
😱 问题来了:5×5卷积的计算量是3×3的2.78倍!直接并行会导致计算成本剧增。
3. 神来之笔:1×1卷积降维
GoogLeNet的解决方案是在大卷积前插入1×1卷积进行降维:
# 改进后的Inception分支
branch3 = sequential(conv1x1(in_channels, ch5x5red), # 降维:减少通道数conv5x5(ch5x5red, ch5x5) # 正常卷积
)1×1卷积的三大作用:
- 1.通道降维:减少后续卷积的输入通道数,降低计算量
- 2.增加非线性:配合ReLU激活函数提升模型表达能力
- 3.跨通道信息整合:融合不同通道的特征信息
4. 最终Inception模块结构
四条并行路径:
- 1.1×1卷积 → 直接输出
- 2.1×1卷积 + 3×3卷积 → 先降维再卷积
- 3.1×1卷积 + 5×5卷积 → 先降维再卷积
- 4.3×3最大池化 + 1×1卷积 → 池化后降维
关键技巧:所有分支使用适当填充(padding),确保输出特征图尺寸一致,便于通道拼接。
三、GoogLeNet整体架构剖析 🧠
GoogLeNet(又称Inception v1)由9个Inception模块堆叠而成,如下图:
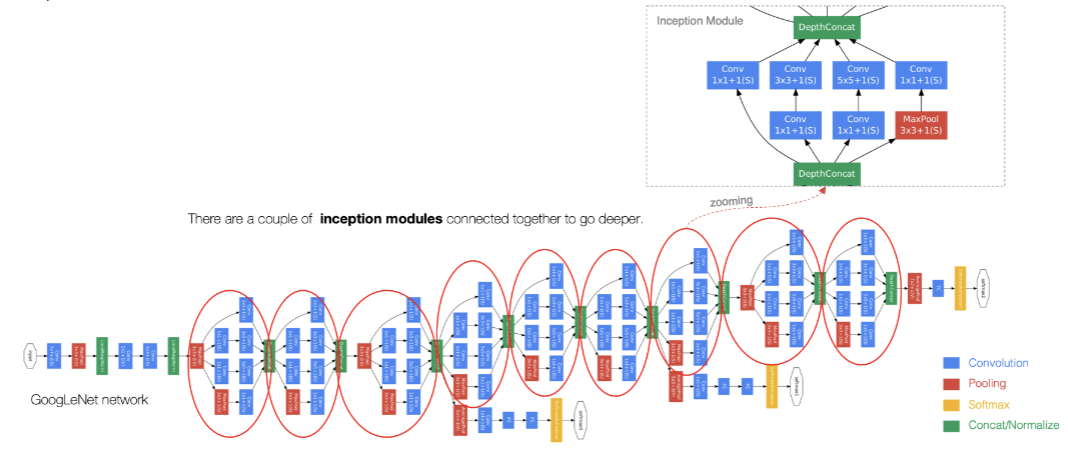
整个网络架构我们分为五个模块,每个模块之间使用步幅为2的 最大池化层来减小输出高
宽。
Stage 1:基础特征提取
第一模块使用一个64通道的7×7 卷积层。
Conv2d(3, 64, kernel=7x7, stride=2) # 输出112×112×64
MaxPool(3x3, stride=2) # 输出56×56×64Stage 2:特征细化
第二模块使用2个卷积层:首先是64通道的1×1 卷积层,然后是将通道增大3倍的 3×3 卷积
层。
Conv2d(64, 64, kernel=1x1) # 保持56×56×64
Conv2d(64, 192, kernel=3x3, padding=1) # 输出56×56×192
MaxPool(3x3, stride=2) # 输出28×28×192Stage 3:Inception模块堆叠(2个)
- Inception3a:输出28×28×256
(64+128+32+32=256) - Inception3b:输出28×28×480
(128+192+96+64=480) - MaxPool:输出14×14×480
Stage 4:深层特征提取(5个Inception)
- 包含Inception4a到4e
- 核心创新点:在此阶段插入辅助分类器
Stage 5:最终分类
Inception5a → Inception5b
GlobalAveragePooling() # 替代全连接层
Dropout(0.4)
Linear(1024, num_classes)🔍 关键技术亮点:
- 辅助分类器(Auxiliary Classifiers)
位置:插入在Inception4a和Inception4d之后
作用:
缓解梯度消失(反向传播时提供额外梯度)
正则化效果(防止过拟合)
利用中间层特征进行分类
训练时:主分类器权重1.0,辅助分类器各0.3
测试时:仅保留主分类器
class AuxiliaryClassifier(nn.Module):def __init__(self, in_channels, num_classes):super().__init__()self.avgpool = nn.AdaptiveAvgPool2d((4,4))self.conv = nn.Conv2d(in_channels, 128, kernel_size=1)self.fc1 = nn.Linear(128 * 4 * 4, 1024)self.fc2 = nn.Linear(1024, num_classes)def forward(self, x):x = self.avgpool(x)x = self.conv(x)x = x.view(x.size(0), -1)x = F.relu(self.fc1(x))x = self.fc2(x)return x- 全局平均池化(Global Average Pooling)
替代传统全连接层:
对每个特征图取平均值 → 得到1×1×通道数的输出
优势:
大幅减少参数量(VGG全连接层占参数90%+)
降低过拟合风险
增强空间平移不变性
四、Inception家族的进化 🚀
GoogLeNet成功后,研究者们持续改进Inception架构:
1. Inception v2/v3
- 引入批量归一化(Batch Normalization)
加速训练收敛,提高稳定性 - 卷积分解技术:
- 5×5卷积 → 两个3×3卷积(计算量减少28%)
- 3×3卷积 → 1×3卷积 + 3×1卷积(非对称分解)
- 更高效的降维方式
在分支开头使用并行降维
2. Inception v4
- 结合残差连接(ResNet思想)
解决深层网络梯度消失问题 - 统一模块设计
标准化Inception模块类型 - Stem模块优化
改进初始特征提取部分
3. Xception(Extreme Inception)
- 深度可分离卷积
将标准卷积分解为:- 逐通道卷积(Depthwise Convolution)
- 逐点卷积(Pointwise Convolution)
- 计算效率提升3-4倍
五、GoogLeNet的优缺点分析 ⚖️
✅ 显著优势:
- 参数效率极高
500万参数实现22层深度(AlexNet参数6000万,仅8层) - 多尺度特征融合
Inception并行结构捕获丰富特征 - 计算量优化
1×1卷积降维大幅减少计算成本 - 训练稳定性提升
辅助分类器缓解梯度消失问题
❌ 固有局限:
- 结构复杂
模块内多分支设计增加调试难度 - 通道数配置经验性强
各路径通道比例依赖人工经验 - 计算资源需求高
虽参数少,但并行计算需求大(尤其早期硬件)
六、实战:PyTorch实现GoogLeNet
import torch
import torch.nn as nn
import torch.nn.functional as Fclass Inception(nn.Module):def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):super().__init__()# 分支1:1x1卷积self.branch1 = nn.Sequential(nn.Conv2d(in_channels, ch1x1, kernel_size=1),nn.BatchNorm2d(ch1x1),nn.ReLU(inplace=True))# 分支2:1x1卷积 -> 3x3卷积self.branch2 = nn.Sequential(nn.Conv2d(in_channels, ch3x3red, kernel_size=1),nn.BatchNorm2d(ch3x3red),nn.ReLU(inplace=True),nn.Conv2d(ch3x3red, ch3x3, kernel_size=3, padding=1),nn.BatchNorm2d(ch3x3),nn.ReLU(inplace=True))# 分支3:1x1卷积 -> 5x5卷积self.branch3 = nn.Sequential(nn.Conv2d(in_channels, ch5x5red, kernel_size=1),nn.BatchNorm2d(ch5x5red),nn.ReLU(inplace=True),nn.Conv2d(ch5x5red, ch5x5, kernel_size=5, padding=2),nn.BatchNorm2d(ch5x5),nn.ReLU(inplace=True))# 分支4:3x3池化 -> 1x1卷积self.branch4 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=1, padding=1),nn.Conv2d(in_channels, pool_proj, kernel_size=1),nn.BatchNorm2d(pool_proj),nn.ReLU(inplace=True))def forward(self, x):branch1 = self.branch1(x)branch2 = self.branch2(x)branch3 = self.branch3(x)branch4 = self.branch4(x)return torch.cat([branch1, branch2, branch3, branch4], 1)# 完整GoogLeNet实现代码见原博客[6](@ref)七、总结与影响 💡
GoogLeNet的革命性贡献在于:
- 开创多尺度特征融合范式
Inception思想影响后续众多网络设计 - 证明参数效率的重要性
用更少参数实现更好性能成为新追求 - 推动模块化网络设计
网络由可复用模块堆叠而成
🌟 关键启示:
在深度学习领域,结构创新有时比单纯增加深度更能带来突破。GoogLeNet通过巧妙的Inception模块设计,实现了“少即是多”(Less is More)的哲学,为后续MobileNet、EfficientNet等高效网络奠定基础。
时至今日,虽然Transformer等新架构崛起,但Inception的思想精髓——并行多尺度特征融合——仍在许多现代网络中闪耀光芒。理解GoogLeNet,就是理解CNN进化史上的关键一跃!
互动时间:你用过GoogLeNet或其变体吗?在哪些场景下效果显著?欢迎在评论区分享你的经验!👇
📢 关注我的CSDN博客,下期将解剖更现代的EfficientNet网络,教你如何用"复合缩放"打造极致效率的模型!🚀