Python数据分析案例75——基于图神经网络的交通路段流量时间序列预测
背景
传统的基于循环神经网络系列模型的的时间序列案例都做烂了,我前面的案例太多了,什么RNN,LSTM,GRU,双向的BILSTM,BiGRU,Transformer,还有加上CNN,注意力机制,模态分解,优化算法 去缝合的,太多了........,数不过来,已经被我做烂了,没任何意义。
人不可能总是在自己的舒适圈, 虽然我现在上班也用不上这一套代码,但是总得学点新东西。
图结构最近还是很火热的,图结构和我们传统的表格数据不一样,是很抽象的,又叫复杂网络,社区挖掘,团伙关联,知识图谱.......反正各行各业都有自己的名字,但是本质来说都是图结构。就是节点和边的关联。
如果还有的同学不知道图结构是什么,不知道什么是图数据,以为是图片.......建议多去问问AI再来。本文的图需要了解一些基础的概念,例如图里面的节点,边,属性,同构图, 异构图, 有向边,无向边。最大子图等.......建边的方法,构图的方法.......
因为之前的时间序列预测都是对于一个表格数据或者一个地方的单条序列(或者是多变量)去进行预测,如果我们有很多条时间序列,例如,同一个网站上相互导航过去的商品,同一个地区不同站点观测到的降雨量,还有例如本文案例的很多相互交叉的街道的交通流量。 他们分别相互关联,能够形成一个复杂的网络图结构,那么我们使用图结构的神经网络去训练预测是不是能够比单独每一个个去预测得到更好的效果呢?
本文主要就是演示一下怎么构建图神经网络去预测时间序列。多条时间序列之间构建图结构再进行模型的训练和预测。
数据介绍
本文的数据来源这个论文: Yu, Bing, Haoteng Yin, and Zhanxing Zhu. "Spatio-temporal graph convolutional networks: a deep learning framework for traffic forecasting." Proceedings of the 27th International Joint Conference on Artificial Intelligence, 2018.
我们使用名为 PeMSD7 的真实世界交通速度数据集。的是由 Yu 等人收集和准备的版本,
数据由两个文件组成:
PeMSD7_W_228.csv 包含加州第 7 区 228 个站点之间的距离。 PeMSD7_V_228.csv 包含这些站点在 2012 年 5 月和 6 月工作日收集的交通速度。 数据集的完整描述可参见 Yu 等人的论文。
就两个CSV文件,一个是不同道路的每一时刻的交通流量速度,这个就是具体我们要构建时间序列预测的表格。还有另外一个表格是不同街道之间的距离,这个是我们用来构图,建立边关系的数据。
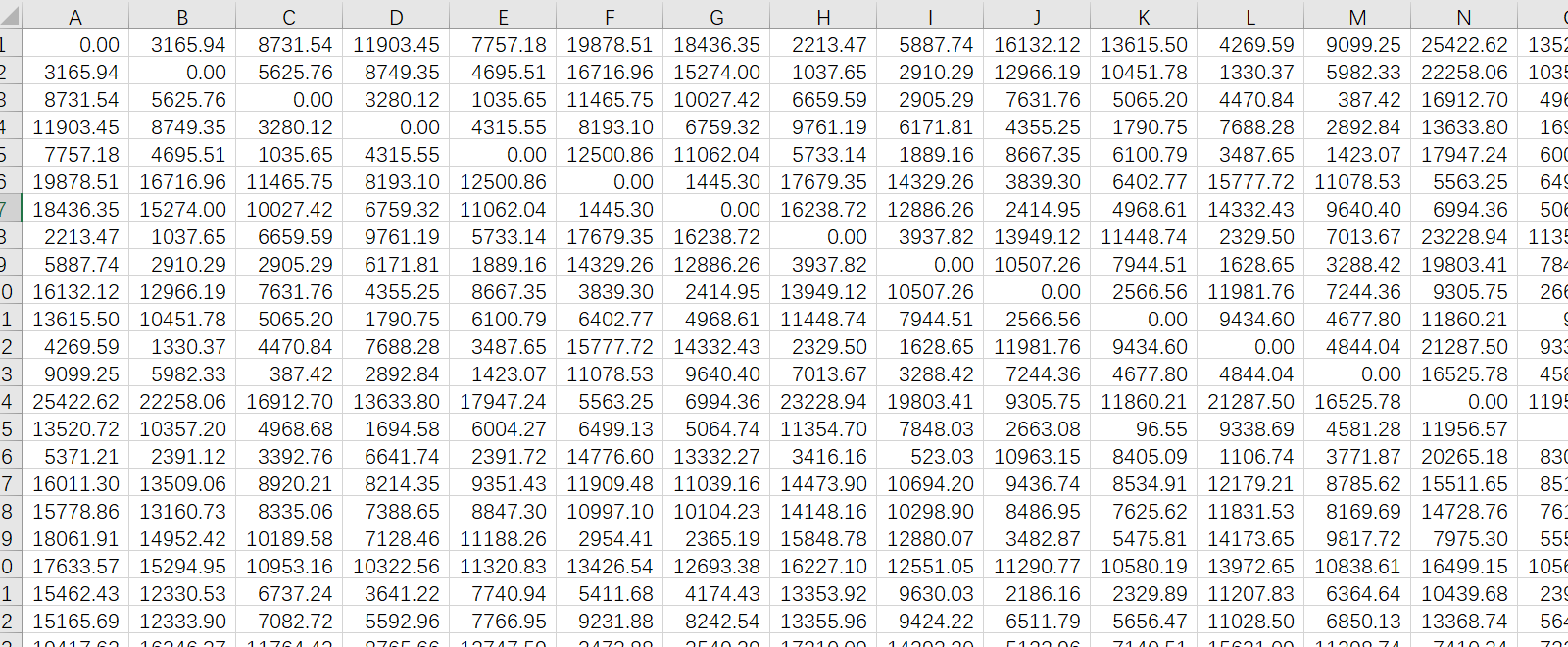
上图是PeMSD7_W_228,不同道路距离的矩阵,对角线上的全是零,因为自己跟自己的距离肯定是零。
下面在代码处理的时候会详细介绍两个数据集的形状和特点。
当然本文所用到的数据集和全部代码文件都可以从这里获取:图交通流量预测
代码实现
本例展示了如何使用图神经网络和 LSTM 预测交通状况。具体来说,我们感兴趣的是根据一组路段的交通速度历史数据预测交通速度的未来值。
解决这个问题的一种常用方法是将每个路段的交通速度视为一个单独的时间序列,并利用同一时间序列的过去值来预测每个时间序列的未来值。 就是分开建模,每个路径一条数据做一个模型区去预测。
然而,这种方法忽略了一个路段的交通速度与相邻路段交通速度的相关性。为了能够考虑到相邻道路上的交通速度之间复杂的相互作用,我们可以将交通网络定义为一个图,并将交通速度视为该图上的一个信号。在本示例中,我们实现了一种神经网络架构,可以处理图上的时间序列数据。首先,我们将展示如何处理数据,并创建一个 tf.data.Dataset 用于对图形进行预测。然后,我们使用图卷积和 LSTM 层实现一个模型,对图进行预测。
先导包,还是TensorFlow和keras深度学习框架。
import pandas as pd
import numpy as np
import os,typing
import matplotlib.pyplot as pltimport tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers载入数据
数据是啥我都备注在代码后面了
route_distances = pd.read_csv("PeMSD7_W_228.csv", header=None).to_numpy() #路距离矩阵,描述不同道路之间的距离
speeds_array = pd.read_csv( "PeMSD7_V_228.csv", header=None).to_numpy() # 每个道路的流量速度
print(f"道路距离矩阵的形状={route_distances.shape}")
print(f"交通流速数据形状={speeds_array.shape}")
- (228, 228)描述的是每个道路两两之间的距离
- (12672, 228)描述的是228条街道的 12672 个时刻点的观察交通速度
数据还是很简洁的,就这么2个矩阵,单变量。
道路下采样
为了缩小问题规模并加快训练速度,我们将只从数据集中的 228 条道路中抽取 26 条道路作为样本。下采样 减少数据量(全量数据的话,家用小电脑一般跑不动)。我们选择道路的方法是从道路 0 开始,选择离它最近的 5 条道路,然后继续这个过程,直到得到 25 条道路。您可以选择任何其他道路子集。我们这样选择道路是为了增加道路速度时间序列相关性的可能性。 sample_routes 包含所选道路的 ID。
sample_routes = [0, 1, 4, 7, 8, 11, 15, 108, 109, 114, 115, 118, 120,123, 124, 126, 127, 129,130, 132, 133, 136, 139, 144, 147, 216, ]
route_distances = route_distances[np.ix_(sample_routes, sample_routes)]
speeds_array = speeds_array[:, sample_routes]print(f"道路距离矩阵的形状={route_distances.shape}")
print(f"交通流速数据形状={speeds_array.shape}")
这样我们就从原来的228条道路减少到了26条,数据量小很多。
数据可视化
以下是其中两条路线的行车速度时间序列(选择的26条路里面的第一条和最后一条)
plt.figure(figsize=(12, 4),dpi=128)
plt.plot(speeds_array[:, [0, -1]])
plt.legend(["route_0", "route_25"])
plt.show()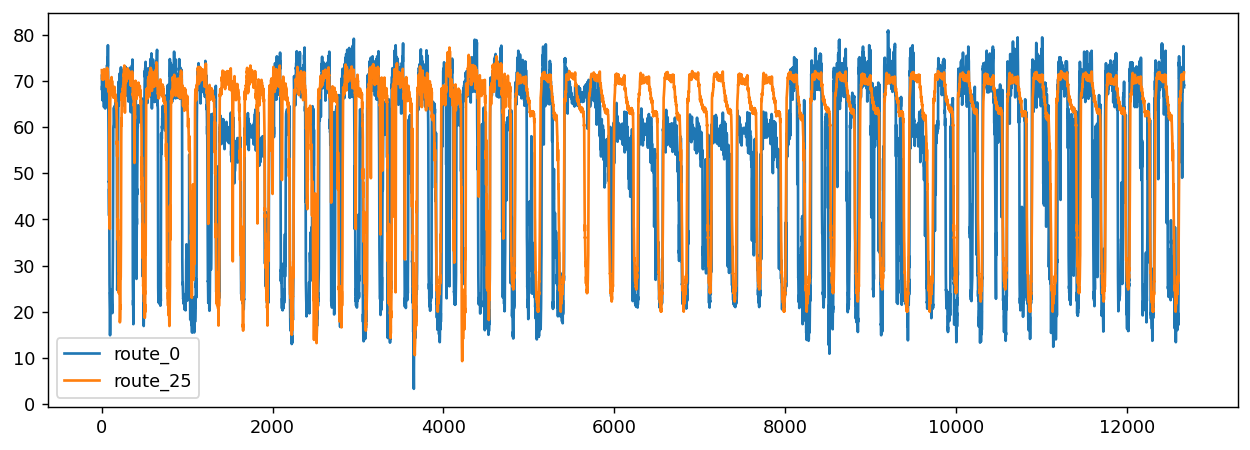
我们还可以直观地看到不同路线的时间序列之间的相关性
plt.figure(figsize=(6,6),dpi=128)
plt.matshow(np.corrcoef(speeds_array.T), 0)
plt.xlabel("road number")
plt.ylabel("road number")
plt.show()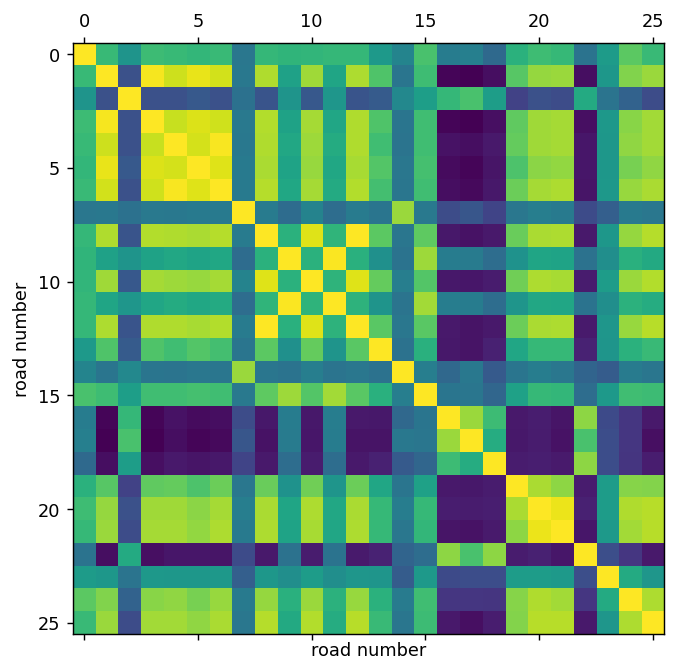
利用这张相关热图,我们可以看到,例如,4、5、6 号路线的速度高度相关。
分割和规范化数据
接下来,我们将速度值数组拆分为训练集/验证集/测试集,并对得到的数组进行归一化处理:
train_size, val_size = 0.5, 0.2 #50%训练,20%验证,30%测试def preprocess(data_array: np.ndarray, train_size: float, val_size: float):"""将数据拆分为训练集/验证集/测试集,并对数据进行标准化处理。参数:data_array:形状为“(num_time_steps, num_routes) ”的ndarray。train_size: 一个介于 0.0 和 1.0 之间的浮点数值,表示要在训练分割中包含的数据集比例。 val_size: 一个介于 0.0 和 1.0 之间的浮点数值,表示要包含在验证分割中的数据集比例。返回值train_array`、`val_array`、`test_array`。"""num_time_steps = data_array.shape[0]num_train, num_val = (int(num_time_steps * train_size),int(num_time_steps * val_size),)train_array = data_array[:num_train]mean, std = train_array.mean(axis=0), train_array.std(axis=0)train_array = (train_array - mean) / stdval_array = (data_array[num_train : (num_train + num_val)] - mean) / stdtest_array = (data_array[(num_train + num_val) :] - mean) / stdreturn train_array, val_array, test_arraytrain_array, val_array, test_array = preprocess(speeds_array, train_size, val_size)print(f"训练集形状: {train_array.shape}")
print(f"验证集形状: {val_array.shape}")
print(f"测试集形状: {test_array.shape}")
创建 TensorFlow 数据集合
接下来,我们为预测问题创建数据集。预测问题可表述如下:给定 t+1、t+2、......、t+T 时间的道路速度值序列,我们希望预测 t+T+1、......、t+T+h 时间的未来道路速度值。因此,对于每个时间 t,我们模型的输入是大小为 N 的 T 个向量,目标是大小为 N 的 h 个向量,其中 N 是道路的数量。
我们使用 Keras 内置函数 timeseries_dataset_from_array()。下面的函数 create_tf_dataset() 将 numpy.ndarray 作为输入,并返回一个 tf.data.Dataset。在这个函数中,input_sequence_length=T 和 forecast_horizon=h。
参数 multi_horizon 需要更多解释。假设 forecast_horizon=3。如果 multi_horizon=true,那么模型将对时间步骤 t+T+1、t+T+2、t+T+3 进行预测。因此目标的形状为(T,3)。但如果 multi_horizon=False 时,模型将只对时间步长 t+T+3 进行预测,因此目标形状为(T,1)。
需要注意:每个批次的输入张量都有形状(batch_size、input_sequence_length、num_routes、1)。是四维数据!添加最后一个维度是为了使模型更通用:在每个时间步长,每个区间的输入特征可能包含多个时间序列。例如,除了使用速度的历史值作为输入特征外,还可以使用别的特征。 但在本例中,输入的最后一个维度始终为 1。因为是单变量的模型,就是交通速度(多变量还可以添加什么天气,温度,风速等特征输入)
比起传统的三维循环神经网络数据,这里多了一个num_routes维度,因为是多条道路,相当于有了一定的空间上的信息,只不过是一维空间(一条线上的不同道路)。要是再复杂一点的话,还可以二维空间(一个平面上不同的坐标点),那就是五维数据了。
我们使用每条道路最近 12 个速度值来预测未来 3 个时间步长的速度,也就是滑动窗口为12,多步预测的步长为3。用过去12个点数据预测未来3个点的数据。
from tensorflow.keras.preprocessing import timeseries_dataset_from_arraybatch_size = 64
input_sequence_length = 12
forecast_horizon = 3
multi_horizon = Falsedef create_tf_dataset( data_array: np.ndarray, input_sequence_length: int, forecast_horizon: int,batch_size: int = 128, shuffle=True, multi_horizon=True, ):"""从 numpy 数组创建 tensorflow 数据集。此函数创建一个数据集,其中每个元素都是一个元组 `(输入X, 目标y)`。输入X是一个张量,形状为 `(batch_size, input_sequence_length, num_routes, 1)` 的张量,包含每个节点的时间序列的 `input_sequence_length` 过去值。目标Y是形状为`(batch_size, forecast_horizon, num_routes)` 形状的张量,包含每个节点的时间序列的未来值。参数:data_array:形状为`(num_time_steps, num_routes) `的 np.ndarrayinput_sequence_length: 输入序列的长度(滑动窗口时间步长)。forecast_horizon: 如果 `multi_horizon=True`,目标值将是 1 到 `forecast_horizon` 时间序列的值。时间步的时间序列值。如果 `multi_horizon=False`,目标值将是时间序列 `forecast_horizon` 的值。时间序列(只有一个值)。batch_size(批量大小): 随机梯度下降中的每个批次中的时间序列样本数。shuffle(打乱,是否对输出样本进行打乱,或按时间顺序排列。multi_horizon: 参见 `forecast_horizon`。返回值:一个 tf.data.Dataset 实例。"""#输入数据X构建 inputs = timeseries_dataset_from_array(np.expand_dims(data_array[:-forecast_horizon], axis=-1), None,sequence_length=input_sequence_length,shuffle=False,batch_size=batch_size, )# 目标y构建target_offset = ( input_sequence_length if multi_horizon else input_sequence_length + forecast_horizon - 1 )target_seq_length = forecast_horizon if multi_horizon else 1targets = timeseries_dataset_from_array( data_array[target_offset:], None, sequence_length=target_seq_length,shuffle=False, batch_size=batch_size, )dataset = tf.data.Dataset.zip((inputs, targets))if shuffle:dataset = dataset.shuffle(100)return dataset.prefetch(16).cache()# 训练集和验证集 ,64为一批
train_dataset, val_dataset = ( create_tf_dataset(data_array, input_sequence_length, forecast_horizon, batch_size)for data_array in [train_array, val_array]
)
# 测试集 ,全量作为一批
test_dataset = create_tf_dataset( test_array, input_sequence_length, forecast_horizon, batch_size=test_array.shape[0],shuffle=False, multi_horizon=multi_horizon,)这样我们就得到了三个tf对象的数据,测试集,验证集和训练集。
## 简单查看一下数据的形状是什么样子的
for batch_x, batch_y in test_dataset.take(1):print("X shape:", batch_x.shape) # 输入特征print("y shape:", batch_y.shape) # 目标值
X就是(批量大小,时间窗口步长,道路数量,特征数量),y就是(批量大小,预测时间步长,道路数量)
道路的图结构
从这里开始我们要对不同的路进行构图,建边关联。
如前所述,我们需要对不同的路段构成一个图结构的数据。PeMSD7 数据集包含路段距离。
下一步是根据这些距离创建图邻接矩阵。根据 Yu 等人这篇文章(公式 10),我们假设如果相应道路之间的距离小于阈值,则图中两个节点之间存在一条边。
def compute_adjacency_matrix(route_distances: np.ndarray, sigma2: float, epsilon: float
):"""根据距离矩阵计算邻接矩阵。具体实现遵循该论文。参数:route_distances:形状为“(num_routes, num_routes) ”的 np.ndarray。该数组的i行,j列 取值是i和j之间的距离。sigma2: 决定应用于平方距离矩阵的高斯核的宽度。ε:指定两个节点之间是否存在边的阈值。具体来说,`A[i,j]=1如果`np.exp(-w2[i,j] / sigma2)>= epsilon`,则`A[i,j]=0`。为邻接矩阵,`w2=路由间距 * 路由间距`为邻接矩阵。返回 布尔图邻接矩阵。"""num_routes = route_distances.shape[0]route_distances = route_distances / 10000.0w2, w_mask = (route_distances * route_distances,np.ones([num_routes, num_routes]) - np.identity(num_routes),)return (np.exp(-w2 / sigma2) >= epsilon) * w_mask函数 compute_adjacency_matrix() 返回一个布尔邻接矩阵,其中 1 表示两个节点之间有一条边。我们使用以下类来存储有关图的信息。
class GraphInfo:def __init__(self, edges: typing.Tuple[list, list], num_nodes: int):self.edges = edgesself.num_nodes = num_nodessigma2 = 0.1 ; epsilon = 0.5 #构图的超参数
adjacency_matrix = compute_adjacency_matrix(route_distances, sigma2, epsilon) #创建图矩阵
node_indices, neighbor_indices = np.where(adjacency_matrix == 1)
graph = GraphInfo( edges=(node_indices.tolist(), neighbor_indices.tolist()),num_nodes=adjacency_matrix.shape[0],
)
print(f"节点的数量: {graph.num_nodes}, 边的数量: {len(graph.edges[0])}")
可以看到我们这个图有26个节点,也是26个道路,它是一个同构图,并且我们构建了150个边,是无向边。
有兴趣的同学可以用networks库去可视化一下这个道路之间的边的关系。放在自己的论文里面也是不错的工作量。
You'll only be my friend.
模型网络架构设计
我们的图预测模型由一个图卷积层和一个 LSTM 层组成。下面介绍,并且实现。
图卷积层
我们对图卷积层的实现类似于 Keras 示例中的实现。请注意在该示例中,该官网的该层的输入是一个二维形状张量(num_nodes,in_feat),而在我们的示例中,该层的输入是一个四维形状张量(num_nodes,batch_size,input_seq_length,in_feat)。所以要自己重写改造
图卷积层执行以下步骤:
- 在 self.compute_nodes_representation() 中,通过将输入特征乘以 self.weight 来计算节点的表示。
- 在 self.compute_aggregated_messages() 中,通过首先聚合邻居的表示,然后将结果乘以 self.weight 来计算聚合邻居的信息。
- 该层的最终输出在 self.update() 中通过合并节点表示和邻居的聚合信息进行计算
# 定义图卷积层
class GraphConv(layers.Layer):def __init__(self,in_feat,out_feat,graph_info: GraphInfo,aggregation_type="mean",combination_type="concat",activation: typing.Optional[str] = None,**kwargs,):super().__init__(**kwargs)self.in_feat = in_featself.out_feat = out_featself.graph_info = graph_infoself.aggregation_type = aggregation_typeself.combination_type = combination_typeself.weight = tf.Variable(initial_value=keras.initializers.glorot_uniform()(shape=(in_feat, out_feat), dtype="float32"),trainable=True,)self.activation = layers.Activation(activation)#可以应用不同的算子来聚合图结构的信息def aggregate(self, neighbour_representations: tf.Tensor):aggregation_func = {"sum": tf.math.unsorted_segment_sum,"mean": tf.math.unsorted_segment_mean,"max": tf.math.unsorted_segment_max,}.get(self.aggregation_type)if aggregation_func:return aggregation_func(neighbour_representations,self.graph_info.edges[0],num_segments=self.graph_info.num_nodes,)raise ValueError(f"Invalid aggregation type: {self.aggregation_type}")def compute_nodes_representation(self, features: tf.Tensor):"""计算每个节点的表示。通过将特征张量与自己的权重相乘。self.weight 的形状为`(in_feat, out_feat)`。参数特征: 形状为 `(num_nodes, batch_size, input_seq_len, in_feat)` 的张量。返回 形状为`(num_nodes、batch_size、input_seq_len、out_feat)`的张量 """return tf.matmul(features, self.weight)def compute_aggregated_messages(self, features: tf.Tensor):neighbour_representations = tf.gather(features, self.graph_info.edges[1])aggregated_messages = self.aggregate(neighbour_representations)return tf.matmul(aggregated_messages, self.weight)def update(self, nodes_representation: tf.Tensor, aggregated_messages: tf.Tensor):if self.combination_type == "concat":h = tf.concat([nodes_representation, aggregated_messages], axis=-1)elif self.combination_type == "add":h = nodes_representation + aggregated_messageselse:raise ValueError(f"Invalid combination type: {self.combination_type}.")return self.activation(h)def call(self, features: tf.Tensor):"""前向传播参数:特征: 张量形状: `(num_nodes, batch_size, input_seq_len, in_feat)`返回:张量形状 `(num_nodes, batch_size, input_seq_len, out_feat)`"""nodes_representation = self.compute_nodes_representation(features)aggregated_messages = self.compute_aggregated_messages(features)return self.update(nodes_representation, aggregated_messages)LSTM 加图卷积层
通过对输入张量应用图卷积层,我们可以得到另一个包含节点随时间变化的表征的张量(另一个 4D 张量)。在每个时间步长内,节点的表示都会参考其邻居的信息。
但要想做出好的预测,我们不仅需要来自邻居的信息,还需要处理随时间变化的信息。所以我们可以通过递归层传递每个节点的张量。下面的 LSTMGC 层,首先对输入应用图卷积层,然后将结果通过 LSTM 层,再经过全连接层,重述形状输出。
class LSTMGC(layers.Layer):"""这个层包括前面写的卷积层,然后是 LSTM 层和密集层"""def __init__(self,in_feat,out_feat,lstm_units: int,input_seq_len: int,output_seq_len: int,graph_info: GraphInfo,graph_conv_params: typing.Optional[dict] = None,**kwargs,):super().__init__(**kwargs)# graph conv layer #额外的参数,可以修改图结构信息聚合方式if graph_conv_params is None:graph_conv_params = {"aggregation_type": "mean","combination_type": "concat","activation": None,}self.graph_conv = GraphConv(in_feat, out_feat, graph_info, **graph_conv_params)self.lstm = layers.LSTM(lstm_units, activation="relu")self.dense = layers.Dense(output_seq_len)self.input_seq_len, self.output_seq_len = input_seq_len, output_seq_lendef call(self, inputs):"""前向传播参数:输入: TF张量,形状为 `(batch_size, input_seq_len, num_nodes, in_feat)`返回:张量,形状为 `(batch_size, output_seq_len, num_nodes)`."""# 数据转化为 (num_nodes, batch_size, input_seq_len, in_feat)inputs = tf.transpose(inputs, [2, 0, 1, 3])gcn_out = self.graph_conv(inputs) # GCN层 输出形状: (num_nodes, batch_size, input_seq_len, out_feat)shape = tf.shape(gcn_out)num_nodes, batch_size, input_seq_len, out_feat = ( shape[0], shape[1], shape[2], shape[3],)# LSTM只接受3维数据输入,所以要重构形状gcn_out = tf.reshape(gcn_out, (batch_size * num_nodes, input_seq_len, out_feat))lstm_out = self.lstm( gcn_out ) # lLSTM层 输出形状为: (batch_size * num_nodes, lstm_units)dense_output = self.dense( lstm_out) # 全连接层 输出 形状: (batch_size * num_nodes, output_seq_len)output = tf.reshape(dense_output, (num_nodes, batch_size, self.output_seq_len)) #重构形状回到3维return tf.transpose(output, [1, 2, 0] ) # 返回数据的形状为 (batch_size, output_seq_len, num_nodes)模型具体每一步干什么以及数据形状什么转化的,我都写到备注里面了,还是很清楚的。
与传统的循环神经网络系列的神经网络不一样,是因为lstm这些神经网络都只接受三维的输入。然而我们的图神经网络要加上节点和边,还有坐标道路不同的位置,所以数据维度是很高的,数据在里面不同神经网络的层进去后,流通的形状会变来变去,尤其是需要注意。
模型训练
对模型参数初始化,然后构建keras 的模型,使用RMSProp优化器,由于是时间序列预测,所以说这是一个回归问题,就用常见的mse损失函数。
in_feat = 1
batch_size = 64
epochs = 20
input_sequence_length = 12
forecast_horizon = 3
multi_horizon = False
out_feat = 10
lstm_units = 64
graph_conv_params = {"aggregation_type": "mean", # 均值聚合"combination_type": "concat", # 直接拼接"activation": None,
}st_gcn = LSTMGC(in_feat, #单变量out_feat, #GCN层输入形状lstm_units, #lstm隐藏层神经元数量input_sequence_length, #输入滑动时间窗口大小forecast_horizon, #预测步长大小graph, #道路的图结构信息graph_conv_params, #图参数
)
inputs = layers.Input((input_sequence_length, graph.num_nodes, in_feat)) # 初始化输入形状
outputs = st_gcn(inputs) # LSTMGC层model = keras.models.Model(inputs, outputs)
model.compile(optimizer=keras.optimizers.RMSprop(learning_rate=0.0002),loss=keras.losses.MeanSquaredError(),)model.fit(train_dataset, validation_data=val_dataset,epochs=epochs, callbacks=[keras.callbacks.EarlyStopping(patience=10)], #早停机制
)
训练了20轮,可以看到验证集的损失基本上没有太多变化,模型基本上已经拟合到位了。
对测试集进行预测
现在我们可以使用训练完成的模型对测试集进行预测。下面计算模型的 MAE,并将其与naive预测的 MAE 进行比较。naive预测值是每个节点速度的最后一个值。(naive预测就是最简单的MA(1)模型,毕竟是4维数据,传统的LSTM,RNN,GRU对比不是很方便)
(不知道什么是MA(1),也不知道为什么要和它对比的看我之前的博客:Python数据分析案例70——基于神经网络的时间序列预测(滞后性的效果,预测中存在的问题)_时间序列滞后窗口-CSDN博客
画图受限于篇幅就只要第0条道路的对比图:
x_test, y = next(test_dataset.as_numpy_iterator())
y_pred = model.predict(x_test)
plt.figure(figsize=(12, 4),dpi=128)
plt.plot(y[:, 0, 0]) # 第一条道路的t+1值
plt.plot(y_pred[:, 0, 0]) # 第一条道路的t+1预测值
plt.legend(["actual", "forecast"],loc='upper right')naive_mse, model_mse = (np.square(x_test[:, -1, :, 0] - y[:, 0, :]).mean(), #MA(1)模型np.square(y_pred[:, 0, :] - y[:, 0, :]).mean(), #我们的预测模型,全部道路误差的的平均
)
print(f"naive MAE: {naive_mse}, model MAE: {model_mse}")
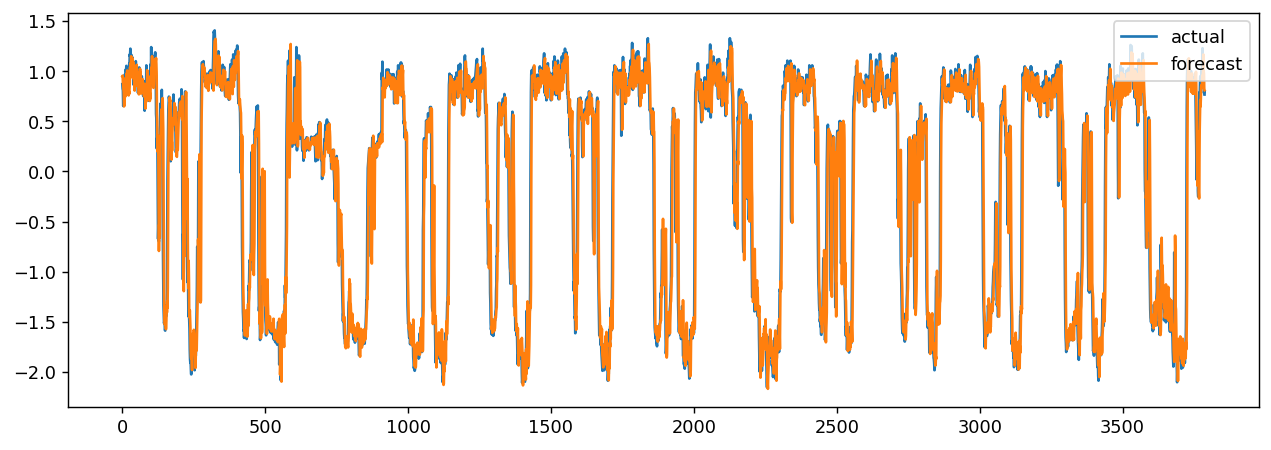
这个数据算MSE和画图的时候都是经过了标准化,所以坐标轴上有负数。
当然,本文这里的目的是演示该方法,而不是达到最佳性能。为了提高模型的准确性,应仔细调整所有模型超参数。此外,还可以叠加几个 LSTMGC 块,以提高模型的表示能力。
总结
简单来说,这是一个比较粗糙的案例,主要是演示图结构的LSTM等模型的时间序列预测。没有我之前的那些普通的循环神经网络的案例那么高度封装以及那么完善的评估体系和标准画图方法。
因为之前都是单个序列单个站点的时间序列预测,这里预测了26个站点,想要全面评估,并且逆标准化回去计算所有的道路的真实值和预测值的误差指标,然后再一条条的跟普通的循环神经网络模型去做对比,还是有点麻烦。
简单来说,主要是演示图结构的LSTM等模型的时间序列预测。是市面上几乎没有的代码。(图结构过于抽象,截止到2025年网上基本没多少资源)
传统的,简单的,普通的三维数据的时间序列预测看我之前的博客案例就行了,网上资源也不少。
后面有空把这个第0条道路使用标准的单LSTM,GRU模型去实验预测对比一下,看看是不是真的使用图结构信息去预测有更好的效果......
创作不易,看官觉得写得还不错的话点个关注和赞吧,本人会持续更新python数据分析领域的代码文章~(需要定制类似的代码可私信)