土耳其Koç大学指令驱动的智能综述,从文本表达到任务执行的系统探索

-
作者: ABDULFATTAH SAFA, TAMTA KAPANADZE, ARDAU ZUNOĞLU, GÖZDEGÜL ŞAHIN
-
单位:土耳其Koç大学KUIS AI实验室,土耳其Koç大学,约翰·霍普金斯大学
-
论文标题:ASystematic Survey on Instructional Text: From Representation Formats to Downstream NLP Tasks
-
论文链接:https://arxiv.org/pdf/2410.18529
主要贡献
-
本文是首个对复杂指令文本(如多步骤的程序性文本)进行全面系统性综述的研究,填补了该领域的空白,为研究人员提供了宝贵的研究背景知识和统一的研究视角。
-
通过构建数据表示类型和下游任务的分类体系,清晰地展示了该领域研究的全貌,帮助研究人员快速了解不同研究方向之间的联系与区别,为未来的研究方向提供了指引。
-
通过分析研究论文的分布情况(如时间、地理、主题等),揭示了该领域的发展趋势,如近年来在指令解析、过程生成、问答等任务上的研究增长,以及在不同国家和地区的研究热点分布。
-
指出了当前研究中存在的挑战,如数据集规模有限、模型对复杂指令的理解能力不足、多模态数据的利用不足等,为后续研究提供了明确的改进方向。
引言
研究背景与动机
-
自然语言编程的愿景:如果能够让机器通过自然语言编程,将彻底改变人类与计算机之间的关系。然而,目前只有不到1%的人类具备编程技能,而机器大多被视为具有固定技能的预编程设备。未来可编程的机器需要具备出色的理解指令的能力,这是实现自然语言编程的关键一步。
-
大语言模型(LLM)的进展:近年来,自然语言处理(NLP)领域取得了显著进展,特别是LLM在理解简单指令方面表现出色。这主要通过“指令调整”(instruction tuning)实现,即在基础语言模型上使用大量指令-响应对进行监督微调。然而,这些模型主要处理单句指令,描述的通常是单步任务,而在现实世界中,任务往往更为复杂,包含多个相互关联的指令。
-
复杂指令理解的挑战:理解复杂指令需要对事件、事件之间的关系、参与者以及环境有更深入的理解,并且能够进行多跳的常识推理。目前,不同领域(如计算语言学、NLP、机器人学、商业智能和计算机视觉等)对复杂指令的理解和处理进行了研究,但这些领域使用不同的术语、表示方法和研究重点,导致了研究资源的分散和新研究人员的入门难度增加。
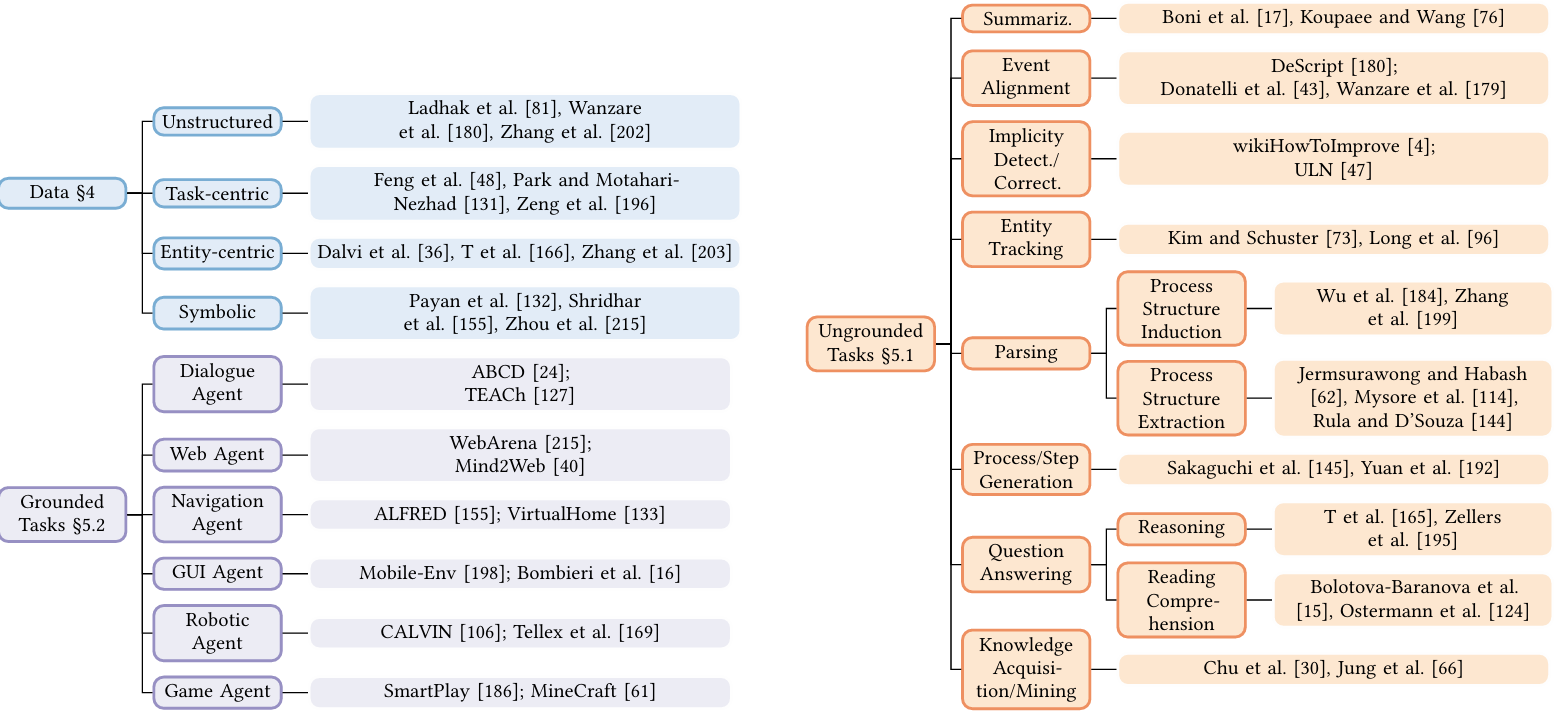
研究目标
-
提供系统性综述:本文旨在为AI/NLP研究人员提供一个全面的、系统的复杂指令理解领域的综述。通过分析177篇相关论文,识别该领域的趋势、挑战和机遇,为研究人员提供必要的背景知识和统一的研究视角。
- 回答研究问题:文章提出了以下四个研究问题(RQ),并围绕这些问题展开研究:
-
RQ1:不同学科中常见的长形式(多步骤)指令文本的表示方式有哪些?有哪些可用的语料库(原始或结构化)?
-
RQ2:哪些下游任务与指令文本相关?它们在领域、方法和评估指标上有什么不同?
-
RQ3:这些出版物的文献学特征是什么,例如它们在时间、地理和主题上的分布情况如何?
-
RQ4:文献中关于这个主题的常见主题和挑战是什么?
-
研究意义
-
推动复杂指令理解研究:通过系统性地分析复杂指令理解领域的现状,本文为研究人员提供了一个全面的研究框架,有助于推动该领域的进一步发展。
-
促进跨学科研究:通过整合不同领域的研究成果,本文为跨学科研究提供了基础,有助于打破学科壁垒,促进复杂指令理解技术在多个领域的应用。
-
为未来研究提供指导:通过识别当前研究中的挑战和机遇,本文为未来的研究方向提供了明确的指引,有助于研究人员更好地规划和开展相关研究工作。
相关工作
事件理解
-
定义与研究范围:事件理解是计算语言学和NLP中的一个重要领域,主要涉及从文本中提取事件信息。事件理解的研究范围包括事件的检测、分类、属性分析以及事件之间的关系分析等。
-
现有综述与方法:Xiang和Wang 提供了一个关于从文本中提取事件信息的综述,涵盖了从模式匹配到高级机器学习模型的各种方法。Chen等人提供了一个关于事件中心信息提取、预测和知识获取的全面教程,重点关注事件中心任务和方法。Li等人调查了深度学习技术在事件提取中的应用,探讨了用于检测、分类和分析事件的复杂模型。
-
与本文的区别:这些综述主要关注从文本中提取单个事件信息,而本文则更侧重于长程序性文本中事件之间的高级关系,例如事件之间的先后顺序、条件关系、并发关系等,以及事件的参与者和环境之间的关系。
指令的语义定位
-
定义与研究范围:指令的语义定位是指将语言与外部知识或现实世界上下文(如图像、知识库、机器人手臂或操作系统)联系起来的任务。该领域涉及将自然语言指令映射到具体的动作或操作,以便在特定环境中执行。
-
现有综述与方法:Ch等人讨论了“语义定位”一词的演变,并将其与认知科学联系起来。Cohen等人调查了不同意义表示方法在机器人语言导航和操作任务中的应用。Wang等人讨论了LLM代理在语义定位任务中的各种方面。
-
与本文的区别:这些综述主要关注特定环境或方法中的语义定位,而本文的目标是全面调查各种应用和环境中复杂指令的语义定位,提供一个跨学科的统一视角。
其他相关领域
-
脚本和规划:本文还提到了与复杂指令理解相关的脚本(script)和规划(planning)领域。脚本是一系列事件,涉及多个参与者,而规划则是生成一个可行的(且希望是最小的)步骤序列以实现特定目标。尽管这些领域与复杂指令理解有交集,但本文主要关注的是复杂指令的表示和理解,而不是脚本生成或规划的具体方法。
-
教程和资源:Zhang提供了一个关于程序性文本的教程,编译了一系列包含程序的资源和选定的应用程序。与之相比,本文提供了更广泛的研究方法、表示类型和任务的系统性方法和分类,旨在为研究人员提供一个全面的研究框架。
小结
-
跨学科视角:本文通过整合不同领域的研究成果,提供了一个跨学科的视角来研究复杂指令理解。这种视角有助于打破学科壁垒,促进不同领域之间的交流和合作。
-
填补空白:尽管已有研究关注事件理解和指令的语义定位,但目前还没有一个全面的综述专门针对程序性文本。本文通过系统性地分析复杂指令理解领域的现状,填补了这一空白。
-
为未来研究提供基础:通过识别现有研究中的不足和挑战,本文为未来的研究方向提供了明确的指引,有助于研究人员更好地规划和开展相关研究工作。
研究方法
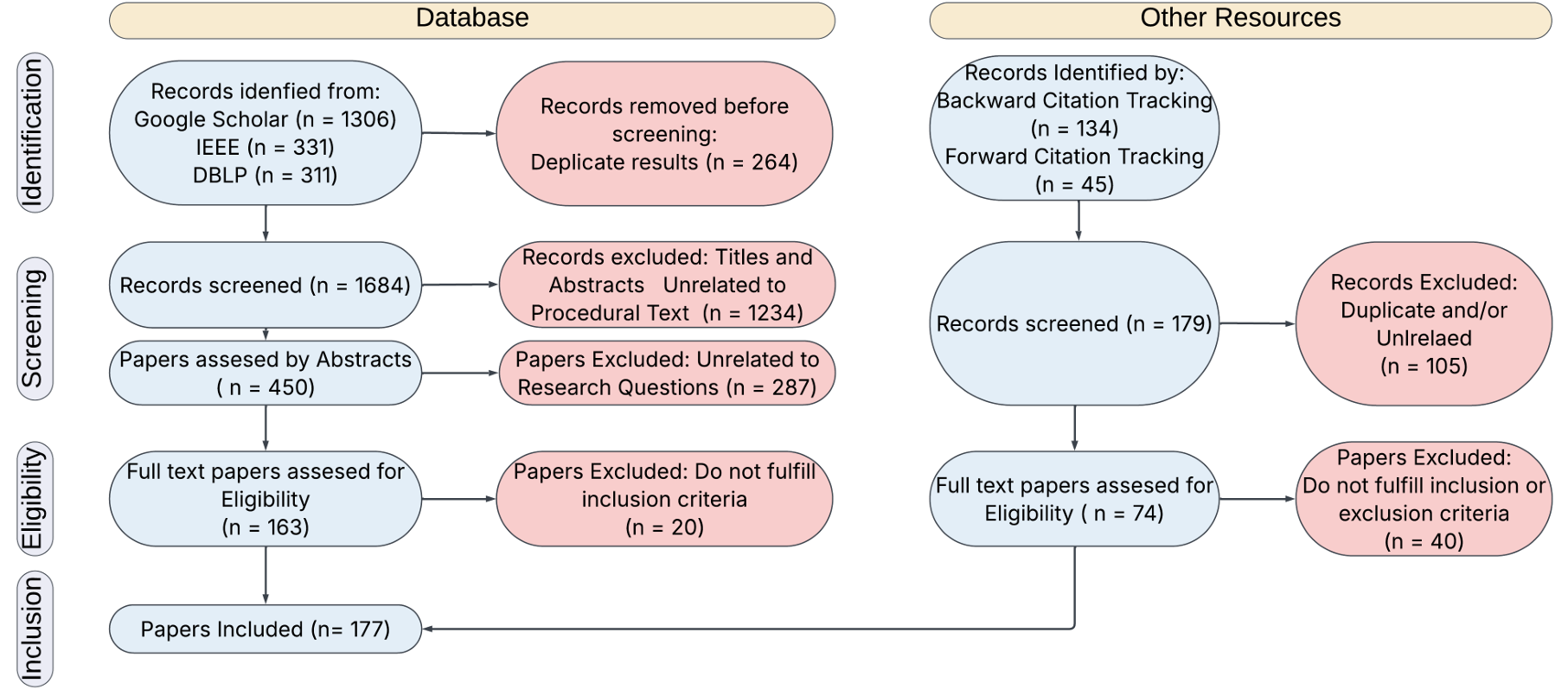
研究方法概述
-
论文采用PRISMA指南进行系统性综述,整个过程包括四个主要步骤:识别(Identification)、筛选(Screening)、资格检查(Eligibility Check)和纳入(Inclusion)。
-
这些步骤确保了研究的系统性和全面性,同时帮助论文识别和筛选出与复杂指令文本相关的高质量研究。
识别
-
数据来源:论文从多个数据库中收集文献,包括DBLP、IEEE Xplore、Google Scholar和ArXiv。这些数据库涵盖了计算机科学、NLP、机器人学、机器学习和工业工程等多个领域。
-
搜索策略:论文使用了一系列关键词进行搜索,包括“procedural text”、“instructional text”、“natural language instruction”等。这些关键词旨在覆盖与复杂指令文本相关的各种研究方向。
-
时间范围:研究的时间范围为2010年至2024年,以确保涵盖该领域的最新进展。
-
结果:通过上述数据库的搜索,论文共检索到1948篇论文。在去除重复项后,剩余1684篇论文。
筛选
-
初步筛选:论文首先对论文的标题和摘要进行手动审查,以去除明显不相关的论文。这一阶段主要关注论文是否包含与复杂指令文本相关的关键词,如“dataset”、“evaluation set”、“benchmark”等。
-
结果:经过初步筛选,论文数量减少到450篇。
资格检查
-
详细审查:在这一阶段,论文对筛选后的论文进行更详细的审查,以确保它们与研究问题(RQ1和RQ2)相关。这一过程涉及对论文内容的深入分析,以确定它们是否提供了关于复杂指令文本表示或下游任务的相关信息。
-
结果:经过资格检查,论文数量进一步减少到163篇。
纳入
-
最终筛选:论文对通过资格检查的论文进行了全面的全文审查,并进一步筛选出与研究问题最相关的论文。此外,论文还通过向前和向后引用追踪,识别了额外的34篇论文。
-
最终结果:最终纳入研究的论文总数为177篇。
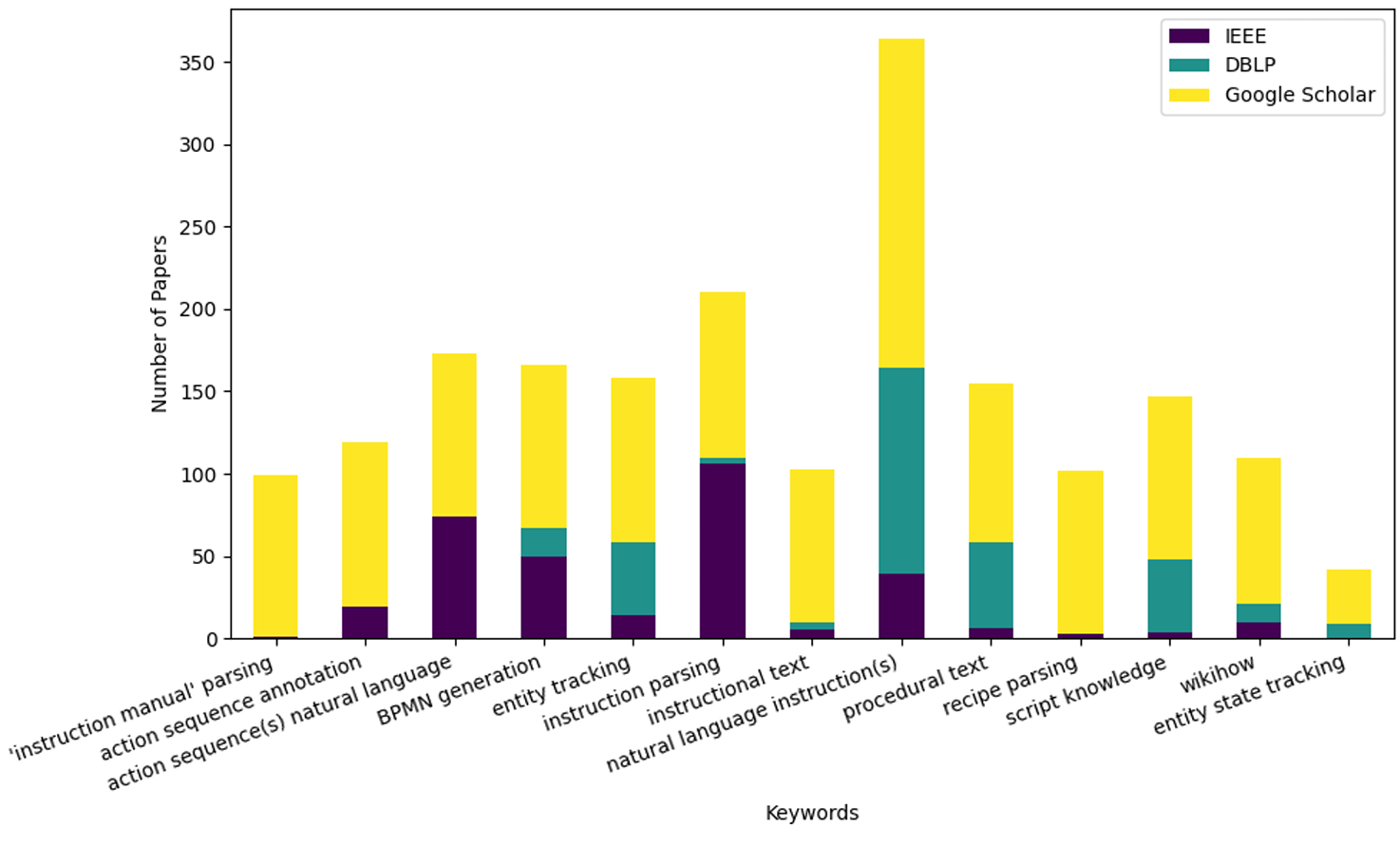
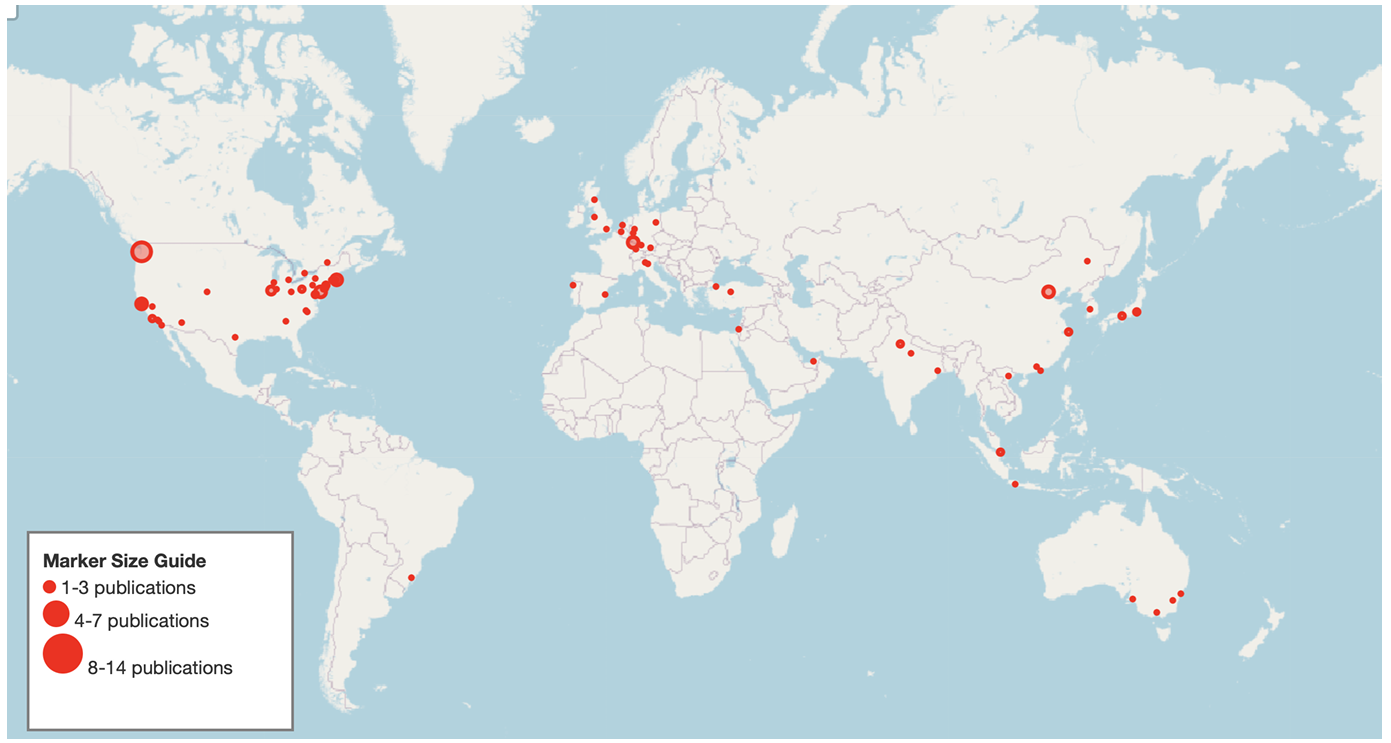
RQ3:文献特征
-
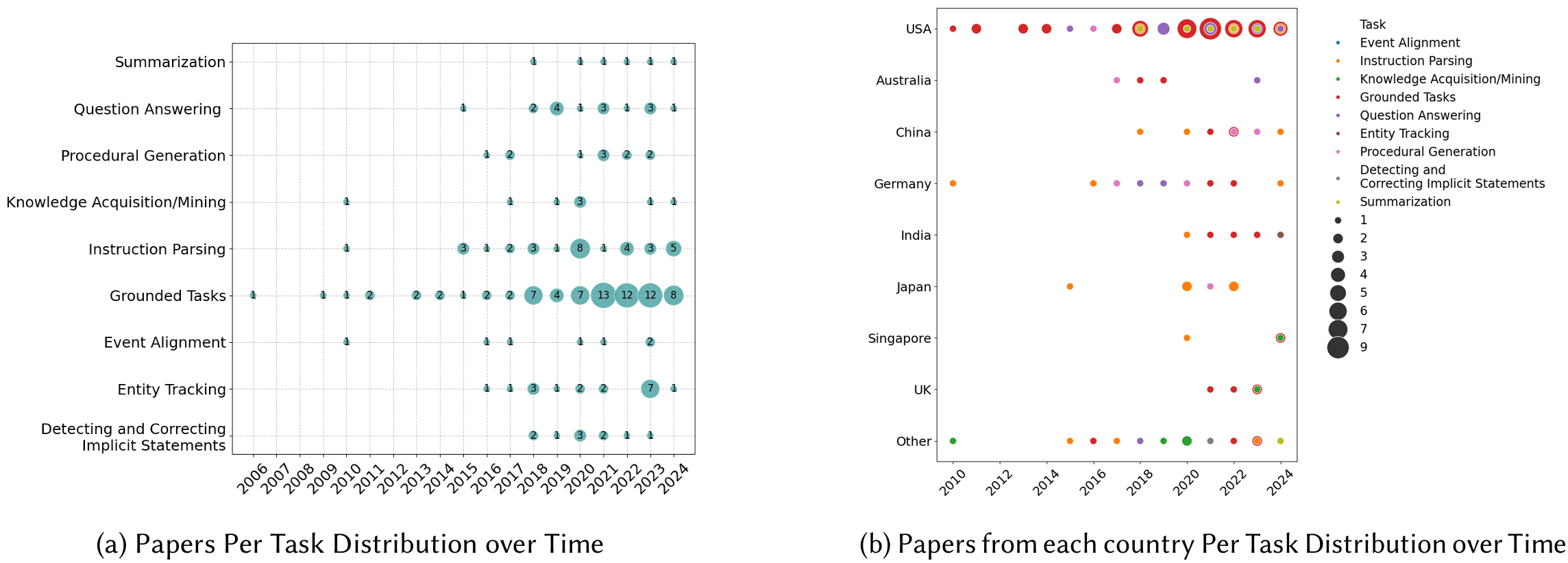
地理分布:论文分析了这些论文的地理分布,发现大部分论文来自斯坦福大学、西雅图、纽约市和北京等著名研究枢纽。这表明研究努力主要集中在这些城市,反映了这些地区在NLP领域的强大研究能力。
-
时间分布:论文还分析了论文的时间分布,发现自2018年以来,问答(Question Answering)和指令解析(Instruction Parsing)等领域的研究逐渐增多,而实体跟踪(Entity Tracking)和事件对齐(Event Alignment)等传统领域的研究则相对稳定。
-
领域分布:论文进一步分析了不同领域(如Web、导航、机器人、游戏等)的研究分布,发现近年来在Web和机器人领域的研究显著增加,反映了这些领域对复杂指令理解的需求和应用前景。
小结
-
通过遵循PRISMA指南,论文系统地识别、筛选和纳入了与复杂指令文本相关的高质量研究。这一过程不仅确保了研究的全面性和系统性,还为后续章节的详细分析提供了坚实的基础。
-
此外,通过分析论文的地理、时间和领域分布,论文揭示了该领域的发展趋势和研究热点,为未来的研究方向提供了重要的参考。
数据
无结构化数据
无结构化数据是指没有明确结构的文本数据,通常直接从网页或其他来源抓取。这些数据在复杂指令文本的研究中非常常见,因为它们提供了丰富的自然语言样本。论文将无结构化数据的来源分为三类:网页语料库、众包数据和合成数据生成。
网页语料库
-
WikiHow:WikiHow是研究复杂指令文本最常用的资源之一。它包含了大量的“how-to”文章,每篇文章都有明确的结构,包括目标、方法和步骤。尽管被称为“无结构化”,但WikiHow文章遵循严格的写作风格,具有一定的文件结构。例如,每篇文章都有一个目标(如“如何销毁一台旧电脑?”)、几种实现目标的方法(如“完全销毁电脑”、“为回收而销毁”)以及执行每种方法的步骤(如“1. 擦除硬盘,2. 拆除电池”)。此外,每篇文章还包含社区问答和提示/警告部分,供遵循文章的人寻求帮助。WikiHow的优点包括:严格的写作风格便于抓取、高领域覆盖率(19个领域和子领域)、大规模(超过235,000篇文章)、多语言性、多模态性(每步描述都配有图片)和高质量(专家编辑的文章)。
-
其他网页资源:除了WikiHow,其他一些网站如Instructables、iFixit、Allrecipes、Cookpad、HaoDou、Food和Xiachufang等也被用于构建无结构化语料库。这些资源在复杂指令文本的研究中也发挥着重要作用。
众包数据
-
DeScript:DeScript是一个小规模的众包语料库,包含40个日常任务(如购物、乘坐公交车、理发和洗澡)的逐步描述。每个任务由100名不同的众包工作者描述,这些描述随后被对齐以生成事件序列描述。
-
Task2Dial和ABCD:这些研究利用众包工作者生成基于指令文档(如食谱和呼叫中心指南)的对话数据集。通过为众包工作者分配不同的角色(如呼叫中心员工、信息提供者),这些研究能够生成与指令文档相关的对话数据。
-
众包的局限性:由于众包的成本较高,这种方法主要用于生成脚本、基于对话的数据或为现有语料库添加小的注释层。例如,DeScript和对齐数据虽然公开可用,但在相关下游任务(如事件释义或对齐)中的使用较少。
合成数据生成
-
Weston等人:Weston等人通过在模拟世界中生成故事来评估不同的语言和推理能力,如共指解析、时间和空间推理。这些故事是通过手动编写规则(例如,如果饿了就找食物)在预定义的实体集(具有预定义的属性,如位置和大小)上生成的。
-
Kim和Schuster:Kim和Schuster定义了一组实体(如书、帽子等)、属性(如位置)和一组动作(如移动),通过简单的Python脚本生成关于在不同盒子之间移动实体的合成程序。这些程序用于评估大语言模型的实体状态跟踪能力。
-
TextWorld:TextWorld是一个用于强化学习代理的指令遵循游戏环境,用于测量代理的规划和探索能力。与上述研究类似,TextWorld的环境由固定的房间、实体、动作和实体属性定义,但游戏是交互式的,分步骤进行。
使用LLM生成数据
-
Yuan等人:Yuan等人利用InstructGPT生成了55,000个程序(例如,为糖尿病患者制作蛋糕的程序),然后通过约束进行过滤,创建了一个受限规划数据集(CoScript)。
以事件为中心的表示
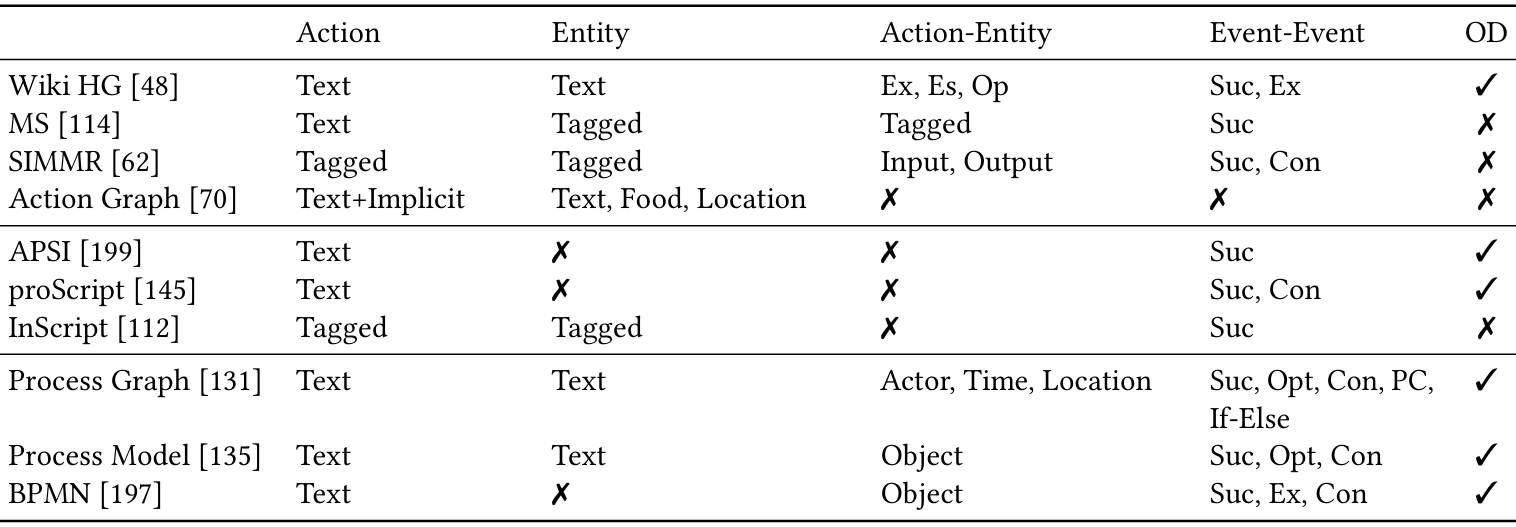
事件中心表示将指令中的每个步骤视为一个事件,重点关注事件之间的关系。论文通过分析不同研究中的表示方法,总结了事件中心表示的多样性。这些表示方法在动作和实体的格式、实体相对于动作的角色以及事件之间的关系方面存在差异。
动作和实体
-
动作:动作通常被定义为指令中的一个步骤,包含一个动词短语,用于完成一个子目标。例如,“烤(bake)”是一个动作。大多数研究假设一个步骤只包含一个动作,但也有研究使用更复杂的动作表示,如包含多个谓词和参数的动词短语。
-
实体:实体是动作的参与者,如动作的宾语或工具。在事件中心表示中,实体通常被标记或提取,但也有研究忽略实体的隐含信息。例如,在“混合a、b、c,然后烘烤”中,“混合物”是一个隐含的实体。
动作-实体关系
-
角色:实体在动作中扮演的角色对于任务表示至关重要。一些研究定义了高度细粒度的实体类型,包括关于关系的信息(如“material_of”)。然而,大多数研究没有明确表示实体的角色,尤其是“行动者”角色,因为指令文本通常是祈使句。
-
关系表示:一些研究使用未标记的依赖链接来表示动作-实体关系,将实体作为动作的输入。这种方法允许将实体与多个动作链接起来,表示隐含的实体(如混合物)。

事件-事件关系
-
关系类型:事件中心表示的一个重要特点是事件之间的丰富关系,如“先后顺序”、“条件关系”、“并发关系”和“可选关系”。这些关系对于理解复杂指令至关重要,但大多数研究只使用简单的“先后顺序”关系。
-
层次和条件:层次和条件关系在复杂指令中也很重要,但目前的研究对这些关系的关注较少。例如,WikiHow中的不同方法之间的选择通常没有明确说明,需要读者自己推断。

以实体为中心的表示
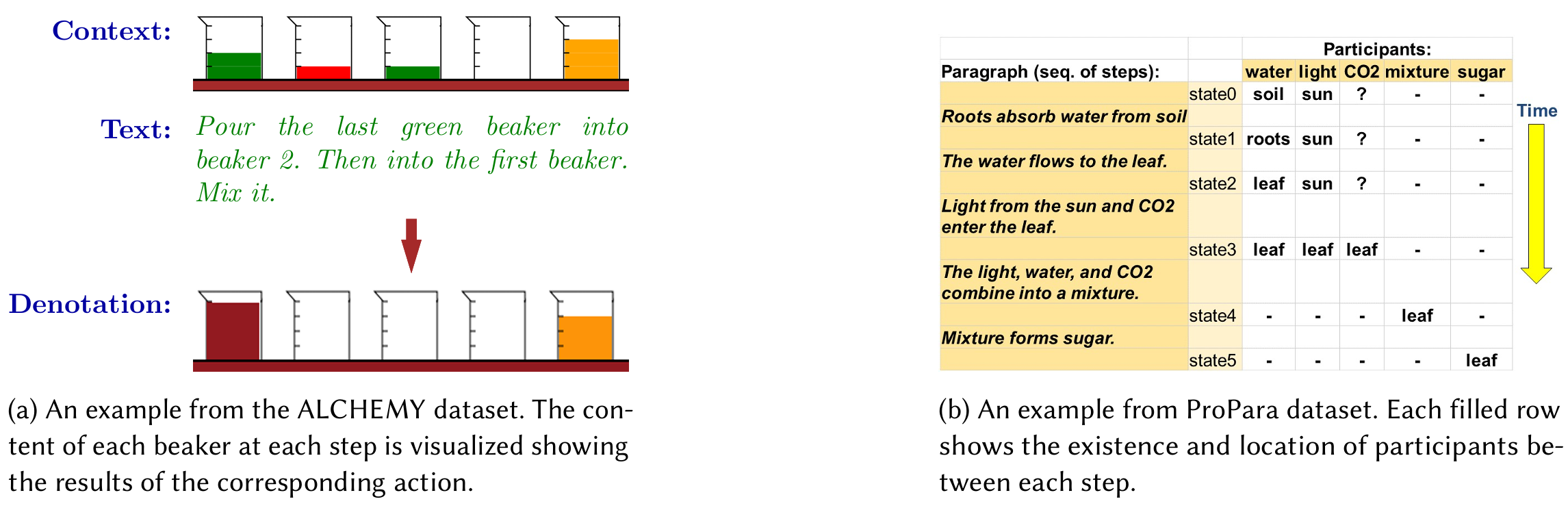
实体中心表示将指令中的实体及其属性作为重点,跟踪这些实体在指令执行过程中的状态变化。与事件中心表示不同,实体中心表示更关注实体的内在属性和状态变化。
实体类型和状态
-
实体类型:实体中心表示通常预定义一组实体类型,如“容器”、“工具”、“食材”等。这些实体类型在不同领域中有所不同,但通常数量有限。
-
状态:实体的状态是实体的属性,如“位置”、“存在性”、“烹饪程度”等。状态可以是二元的(如“可食用”、“存在”)、分类的(如“形状”、“颜色”)或自由文本(如“位置”)。
动作和状态变化
-
动作:实体中心表示中的动作通常是对实体进行的操作,如“创建”、“移动”、“改变状态”等。这些动作的数量也有限,通常与实体类型相关。
-
状态变化:状态变化是实体在动作执行后的结果。例如,在“将水倒入杯子”中,“水”的状态从“在容器中”变为“在杯子中”。
数据集
-
ProPara v1.0:ProPara v1.0是一个用于跟踪实体状态变化的数据集,包含多个实体类型和状态变化。
-
OpenPI:OpenPI是一个开放领域的实体跟踪数据集,包含多个领域的实体和状态变化。
-
NPN:NPN是一个用于烹饪领域的实体跟踪数据集,包含多个实体类型和状态变化。
符号表示
符号表示将自然语言指令转换为机器可读的符号语言,以便在特定环境中执行。这种表示方法通常用于指令的语义定位任务。
符号语言
-
PDDL:PDDL(Planning Domain Definition Language)是一种用于规划任务的符号语言,常用于机器人导航和操作任务。
-
LTL:LTL(Linear Temporal Logic)是一种用于表示时间逻辑的符号语言,常用于机器人任务的语义定位。
-
FOL:FOL(First-Order Logic)是一种用于表示一阶逻辑的符号语言,常用于机器人任务的语义定位。
任务
无映射任务
-
无映射任务是指那些仅依赖于文本数据的任务,不需要与外部环境进行交互。
-
这些任务主要关注文本内容的理解和生成。
摘要生成
-
任务描述:从单个或多个程序性文档中提取关键指令,可以是提取式的(直接从源文本中选择关键句子)或生成式的(生成新的短语来总结内容)。
-
数据资源:主要使用WikiHow和HowSumm数据集。
-
方法和评估:早期研究使用序列到序列模型生成摘要,后来的研究则主要使用基于Transformer架构的预训练模型(如T5、mBART、BART和Pegasus)。评估指标主要包括ROUGE、BLEU、BERTScore和METEOR。
-
挑战:保持步骤的顺序、捕捉具体细节(如测量值)、生成一致的摘要以及处理不同写作风格和语言的多样性。
事件对齐
-
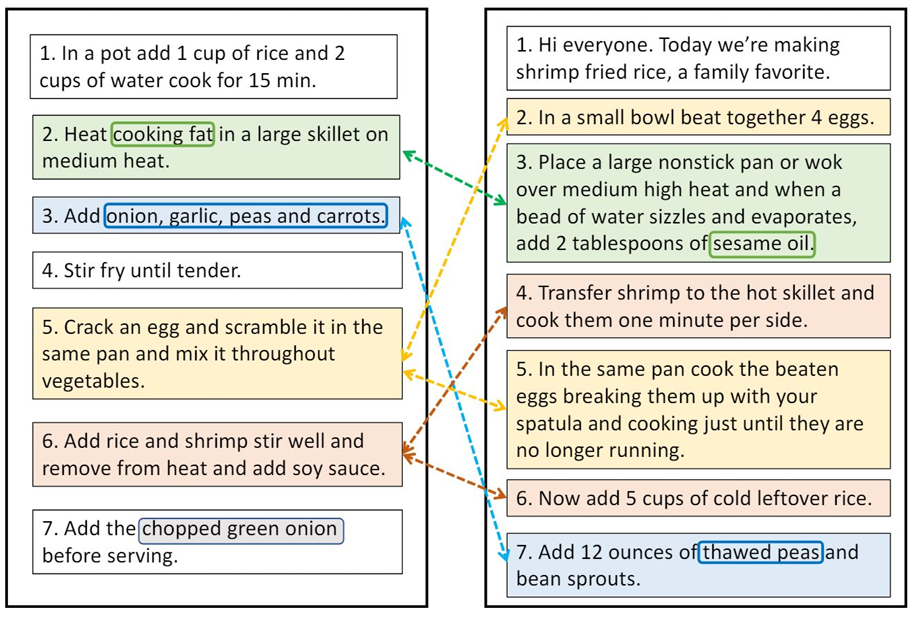
任务描述:识别和匹配不同指令集中的对应动作或步骤,可以是一对一(paraphrasing)或一对多。
-
数据资源:主要使用烹饪食谱和日常任务的数据集,如Recipe1M+、RecipeNLG和DeSCRIPT。
-
方法和评估:大多数研究使用无监督学习算法,如BERT和LSTM网络。评估指标包括准确率、精确率、召回率和F1分数。
-
挑战:缺乏大规模的标注数据集,模型在对齐任务上的表现仍有待提高。
检测和纠正隐含指令
-
任务描述:识别和纠正指令文本中的隐含或不明确的陈述,包括补充缺失信息或澄清模糊表达。
-
数据资源:基于WikiHow修订的语料库,如wikiHowToImprove和KIDSCOOK。
-
方法和评估:早期模型依赖于符号方法(如语义角色标注和VerbNet),最近的研究则主要使用预训练语言模型。评估指标包括精确率、召回率和F1分数。
-
挑战:模型在处理动态、多上下文推理和隐含的时序及因果关系方面存在困难。
实体状态跟踪
-
任务描述:跟踪指令中实体(如食材、工具)及其属性(如颜色、位置)在每一步中的变化。
-
数据资源:包括ProPara v1.0、OpenPI、NPN等数据集。
-
方法和评估:使用神经网络(如Neural Process Networks)和预训练模型(如BERT)。评估指标包括准确率、精确率、召回率和F1分数。
-
挑战:开放领域实体跟踪对模型的挑战较大,尤其是在处理复杂任务和稀疏属性数据时。
指令解析
-
任务描述:将自然语言指令解析为结构化数据表示,如树、图或BPMN。
-
数据资源:涉及烹饪食谱、日常任务、技术手册等领域的数据集。
-
方法和评估:使用基于规则的方法、神经架构(如Bi-LSTM和CNN)和预训练模型(如BERT、DEBERTA)。评估指标包括精确率、召回率和F1分数。
-
挑战:缺乏大规模标注数据集,模型在生成BPMN模型质量保证和完整性约束方面存在困难。
过程生成
-
任务描述:生成程序性文本,如烹饪食谱或日常任务的步骤。
-
数据资源:使用WikiHow、食谱数据集等。
-
方法和评估:使用序列到序列模型(如LSTM和GRU)和预训练语言模型(如T5和GPT-3)。评估指标包括BLEU、ROUGE、BERTScore和METEOR。
-
挑战:模型在生成连贯、逻辑有序的脚本方面存在困难,尤其是在开放场景中。
问答
-
任务描述:要求模型理解动作序列、因果关系,并从程序性文本中回答问题。
-
数据资源:包括WikiHowQA、MCScript、RecipeQA等数据集。
-
方法和评估:使用基于LSTM的架构和预训练模型(如BERT、RoBERTa)。评估指标包括准确率、精确率、召回率和F1分数。
-
挑战:模型在多步推理和处理错误场景方面存在困难。
知识获取/挖掘
-
任务描述:从非结构化文本中构建语义知识结构,以支持AI系统更好地推理、规划和执行程序性任务。
-
数据资源:主要使用WikiHow和任务手册。
-
方法和评估:使用规则系统、预训练模型(如BERT)和强化学习。评估指标包括准确率和召回率。
-
挑战:缺乏大规模标注数据集,模型在动态适应新对象或动作方面存在困难。
有映射任务
-
有映射任务是指那些需要将指令与外部环境(如数据库、文档或模拟环境)进行交互的任务。
-
这些任务通常需要理解并利用上下文信息和领域特定知识。
Web环境
-
任务描述:模拟真实世界中的Web交互,如信息检索和电子商务。
-
数据资源:包括WebArena、Mind2Web等数据集。
-
方法和评估:使用语言模型(如GPT-4)和强化学习技术。评估指标包括精确率、召回率和成功率。
-
挑战:Web环境的复杂性差异较大,模型在处理多页交互和复杂任务时存在困难。
导航/家庭环境
-
任务描述:在模拟环境中执行导航任务,如家庭助理和虚拟导航。
-
数据资源:包括VirtualHome、ALFRED等数据集。
-
方法和评估:使用序列到序列模型和预训练语言模型。评估指标包括成功率和路径长度。
-
挑战:模型在处理部分可观测环境和复杂任务时存在困难。
机器人环境
-
任务描述:使真实机器人理解并执行基于自然语言的指令。
-
数据资源:包括CALVIN等数据集。
-
方法和评估:使用概率和神经符号方法。评估指标包括任务成功率和序列完成率。
-
挑战:机器人环境的复杂性较高,模型在处理长视野任务和动态环境时存在困难。
游戏环境
-
任务描述:在游戏环境中模拟真实世界的挑战,如战略规划和协作构建。
-
数据资源:包括Minecraft、TextWorld等数据集。
-
方法和评估:使用强化学习和预训练语言模型。评估指标包括任务成功率和通信效率。
-
挑战:游戏环境的多样性和多模态信息的整合对模型提出了较高要求。
GUI环境
-
任务描述:在移动设备上执行基于自然语言的指令,如系统级任务和教育应用。
-
数据资源:包括Mobile-Env、AndroidEnv等数据集。
-
方法和评估:使用预训练语言模型和视觉模型。评估指标包括准确率和召回率。
-
挑战:模型在处理多样化应用界面和实时执行时存在困难。
与代码合成的关系
-
任务描述:将自然语言指令转换为可执行代码,如Python或SQL。
-
数据资源:包括InstructExcel等数据集。
-
方法和评估:使用预训练语言模型和代码生成技术。评估指标包括准确率和召回率。
-
挑战:模型在处理复杂编程任务和动态环境时存在困难。
基于任务的对话
-
任务描述:在特定领域(如导航、烹饪、数据可视化)中执行基于对话的任务。
-
数据资源:包括ABCD、Task2Dial等数据集。
-
方法和评估:使用预训练语言模型和检索增强生成模型。评估指标包括准确率、召回率和成功率。
-
挑战:模型在处理多轮对话和动态环境时存在困难。
结论与未来工作
- 结论:
-
本文通过系统性综述,全面分析了复杂指令文本的研究现状,揭示了该领域的发展趋势和挑战。
-
研究结果表明,虽然在复杂指令理解方面已经取得了一些进展,但在数据表示、模型性能、多模态数据利用等方面仍存在许多问题需要解决。
-
- 未来工作:未来的研究可以从以下几个方面展开:
-
数据集建设:构建更大规模、更高质量的复杂指令数据集,以覆盖更多领域和更复杂的指令类型,为模型训练和评估提供更充分的数据支持。
-
模型改进:开发更强大的模型架构,提高模型对复杂指令的理解能力,特别是在多步骤推理、常识推理等方面的能力。同时,探索如何更好地利用多模态数据,以提高模型对复杂指令的理解和执行效果。
-
跨学科研究:加强与机器人学、商业智能、计算机视觉等学科的交叉研究,借鉴其他领域的研究成果和方法,推动复杂指令理解技术的发展。
-
应用拓展:将复杂指令理解技术应用于更多实际场景,如智能家居、智能教育、智能医疗等,为人们的生活和工作带来更多的便利。
-
