KingBase数据库迁移利器:KDTS工具 MySQL数据迁移到KingbaseES实战
一、引言:国产化数据库的崛起与数据迁移的痛点
在数字化转型的浪潮中,数据库作为企业核心数据的载体,其重要性不言而喻。然而,随着国产化替代进程的加速,许多企业面临一个关键问题:如何将原有Oracle、MySQL等国外数据库的数据,平滑迁移至国产数据库(如KingBase)?
传统迁移方式往往存在以下痛点:
- 兼容性差:不同数据库的语法、数据类型、存储过程差异大,手动转换易出错。
- 效率低下:大表迁移耗时长,断点续传困难,网络波动易导致任务失败。
- 风险不可控:缺乏完善的容错机制,迁移失败后难以定位问题根源。
- 学习成本高:DBA需熟悉多种数据库特性,迁移工具操作复杂。

针对这些痛点,金仓推出的KingBase数据库及其配套工具KDTS(Kingbase Data Transformation Service),提供了一套从评估、迁移到验证的全栈式解决方案。本文将详细讲解KDTS的实战操作,轻松完成国产化数据迁移。
环境准备见上篇文章(KDTS 迁移版本矩阵 和 KDTS 环境准备工作):
KingBase数据库迁移利器:KDTS工具深度解析与实战指南
二、KingBase数据库 && KDTS 数据迁移工具

2.1 KingBase的起源与发展
KingBase数据库由中国人民大学研发,后由中电科金仓(中国电科集团成员企业)持续迭代优化。作为国内最早的自主知识产权数据库,KingBase已形成覆盖单机版、集群版、云原生版的完整产品线,累计部署超100万套,广泛应用于金融、能源、政务等关键领域。
2.2 核心特性:高兼容、高可靠、高性能
(1)多语法兼容模式
KingBase支持Oracle、MySQL、SQL Server、PostgreSQL等主流数据库的语法兼容,例如:
Oracle模式:兼容PL/SQL存储过程、触发器、序列等对象。
MySQL模式:支持AUTO_INCREMENT自增字段、ENGINE=InnoDB等特性。
SQL Server模式:适配TOP N分页、WITH (NOLOCK)提示等语法。
(2)高可用架构
共享存储集群(RAC):多节点对等写,支持RPO=0(零数据丢失)、RTO≈0(秒级故障恢复)。
读写分离集群(RWC):自动分离读写负载,提升并发性能。
分布式集群(TDC):跨地域多活,支持PB级数据存储。
(3)高可靠
通过国家信息安全等级保护四级认证,支持三权分立(数据库管理员、安全管理员、审计管理员分离)。
提供透明数据加密(TDE)、动态数据脱敏等安全功能。
2.3 KDTS 简介和优势

KDTS是一款高效的数据库迁移工具,利用智能翻译和并行任务调度,可“一键”将国内外数据库对象和数据迁移至KingbaseES数据库,操作简便稳定。
三、数据迁移(离线迁移)-MySQL至KingbaseES
接上文环境准备之后
KingBase数据库迁移利器:KDTS工具深度解析与实战指南
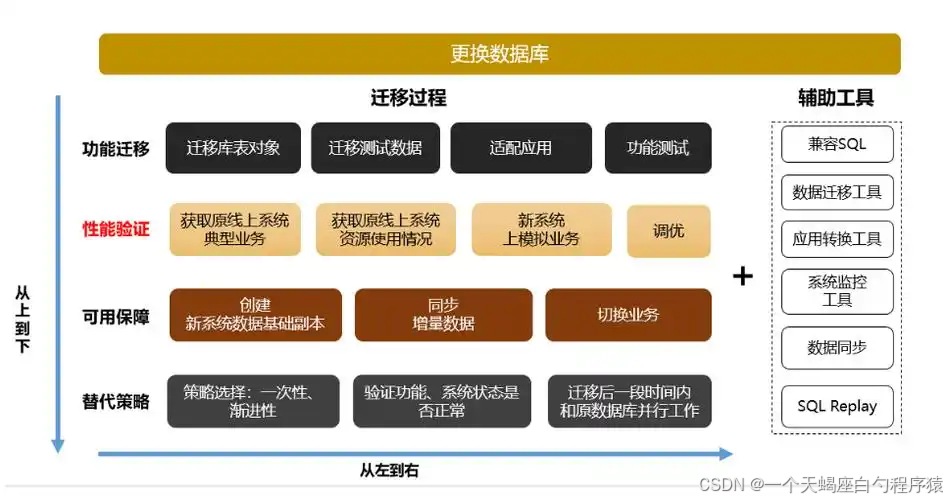
可使用 KDTS 进行数据的离线迁移,KDTS 提供了两种形态(WEB、SHELL),用户可根据需要进行选择,博主将分别介绍WEB、SHELL版本进行MySQL迁移的具体步骤
3.1 迁移准备工作
KingbaseES 数据迁移工具 KDTS 动态加载待迁移的数据库访问接口,方便用户定制和使用。KingbaseES 数据同步工具 KFS 支持同、异构数据源之间的数据迁移同构数据源间数据迁移:支持KingbaseES V7和V8R3到KingbaseES V9的数据迁移。异构数据源之间的数据迁移:支持MySQL5、MySQL8 到KingbaseES V9的数据迁移。KingbaseES 数据同步工具 KFS 支持结构迁移、支持全量数据迁移、支持列名映射,支持数据迁移过滤,在配置数据任务时,可以对迁移的表配置where条件、通过匹配的where条件过滤需要迁移的数据。数据库迁移时需要按照用户需求确定在线迁移还是离线迁移,若是离线迁移,使用KDTS完成MySQL的完整迁移; 若是在线迁移,目前支持使用 KFS 完成。
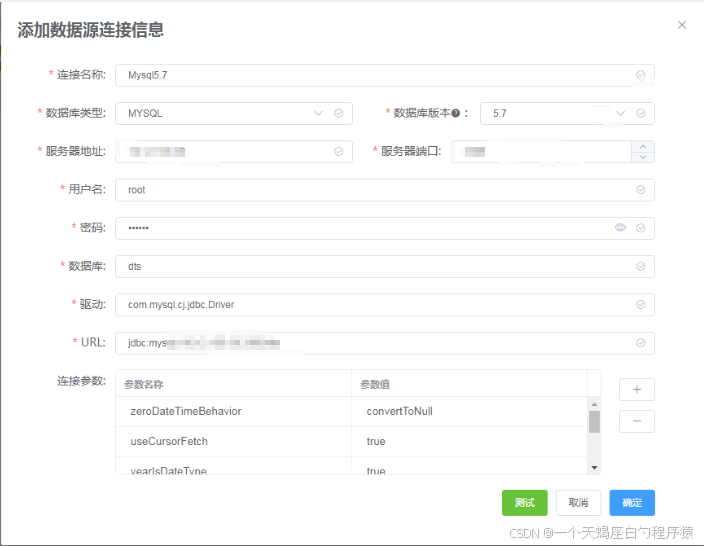
3.2 创建源数据库连接(WEB)
创建源数据库连接 ,创建数据库连接界面如下,填写数据源信息,包括: “连接名称”、“数据库类型”、“数据库版本”、“服务器地址”、“端口”、“用户名”、“密码”、“数据库”、“驱动”、“URL”、“连接参数”
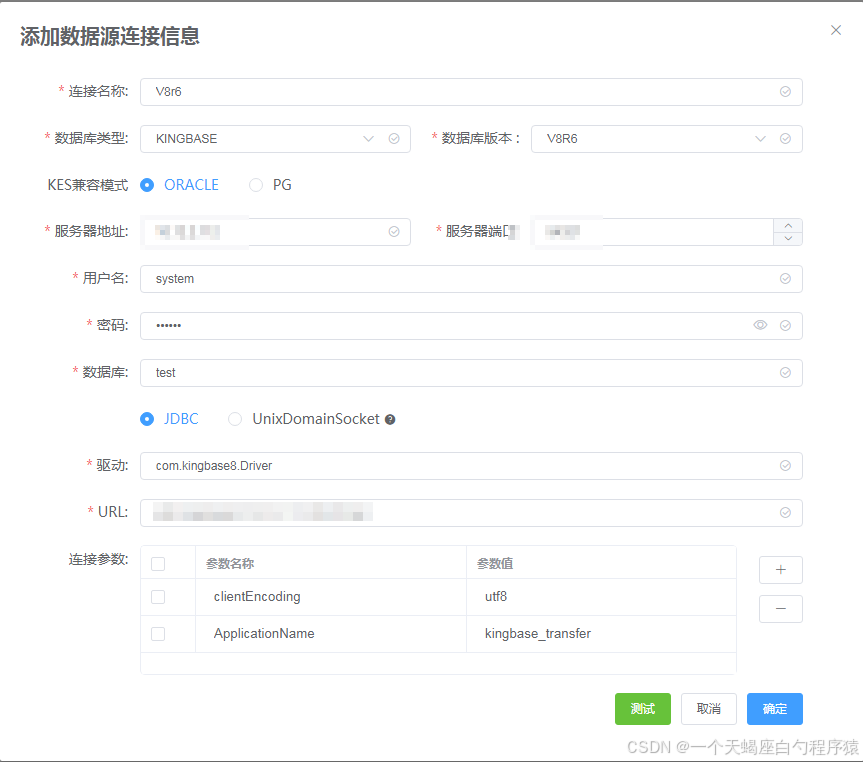
3.3 创建目标数据库连接(WEB)
创建数据库连接界面如下,填写数据源信息,包括: “连接名称”、“数据库类型”、“数据库版本”、“服务器地址”、“端口”、“用户名”、“密码”、“数据库”、“驱动”、“URL”、“连接参数”
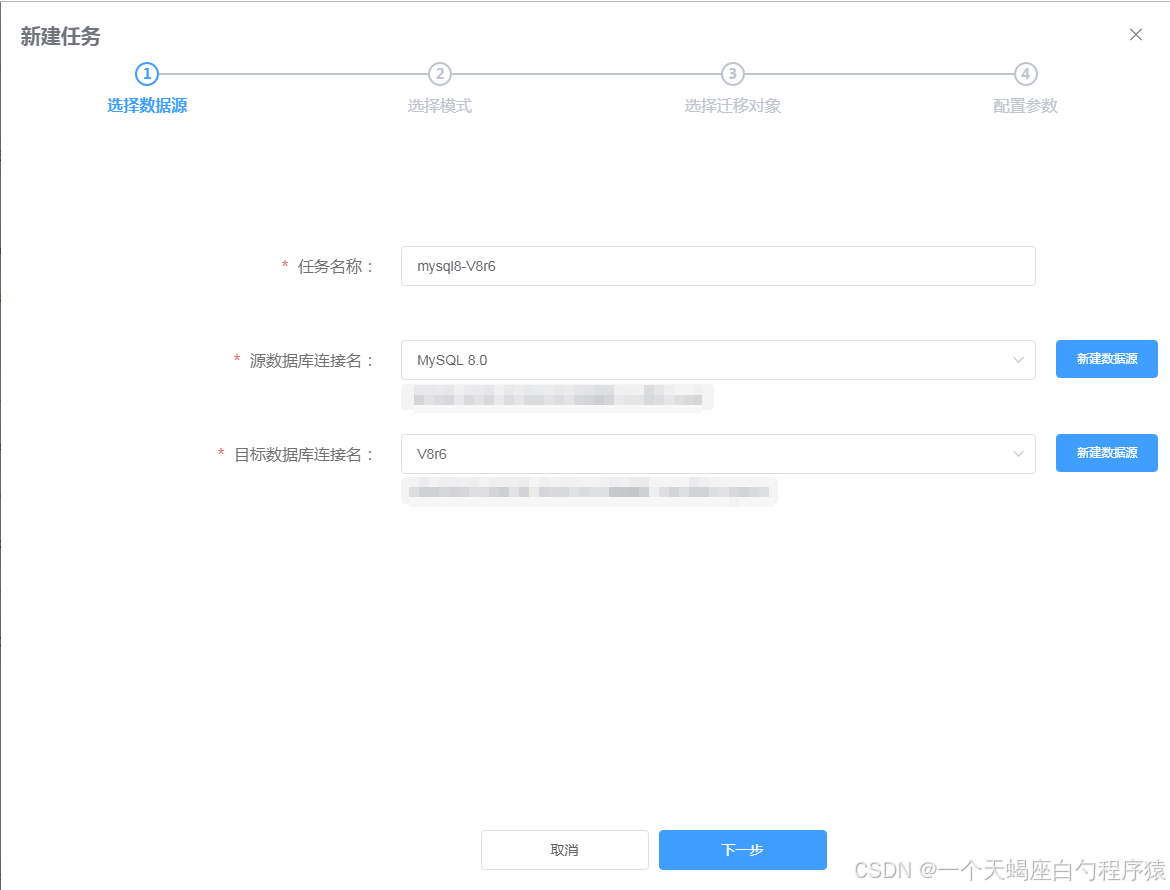
3.4 新建迁移任务(WEB)
KDTS 采用向导页的方式指导用户新建迁移任务,简单易用,用户依次配置“选择数据源”-“选择模式”-“选择迁移对象”-“配置参数”,即可快速配置一个迁移任务
- 选择数据源
填写自定义任务名称(任务名称不能重复),选择“源数据库”和“目标数据库”,或者选择“新建数据源”后使用
- 选择模式
选择需要迁移的模式(如需选择模式在系统模式中可选中“包含系统模式”复选框)的表结构、表数据、视图、序列、函数、存储过程、程序包、同义词、自定义类型等。当模式较多时也可以通过左上方的查询框进行检索。 请至少选择一种模式,否则将收到错误提示,以至于不能完成新建任务
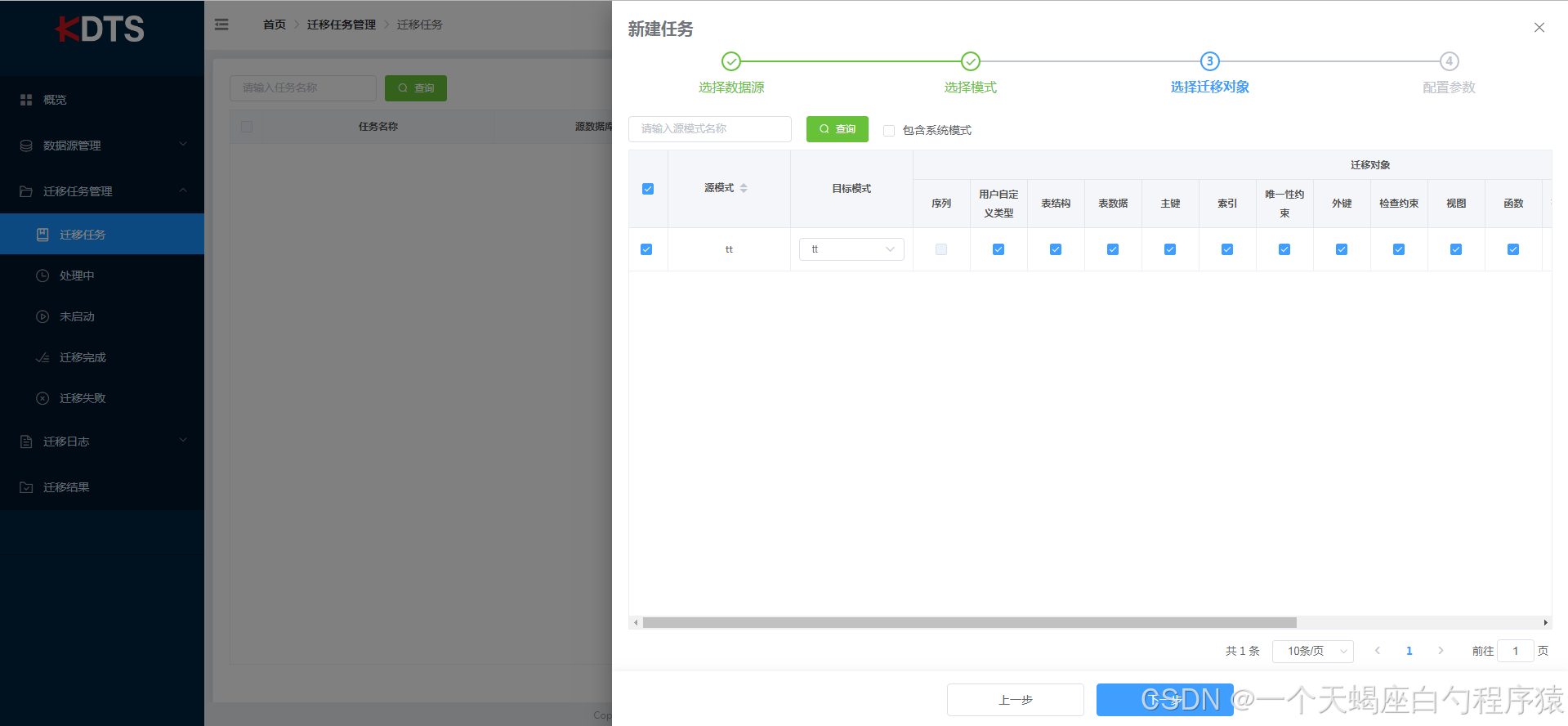
- 选择迁移对象
通过已选模式选择需要迁移数据的表,模式较多时可在已选模式搜索框内输入模式名关键字进行快速检索
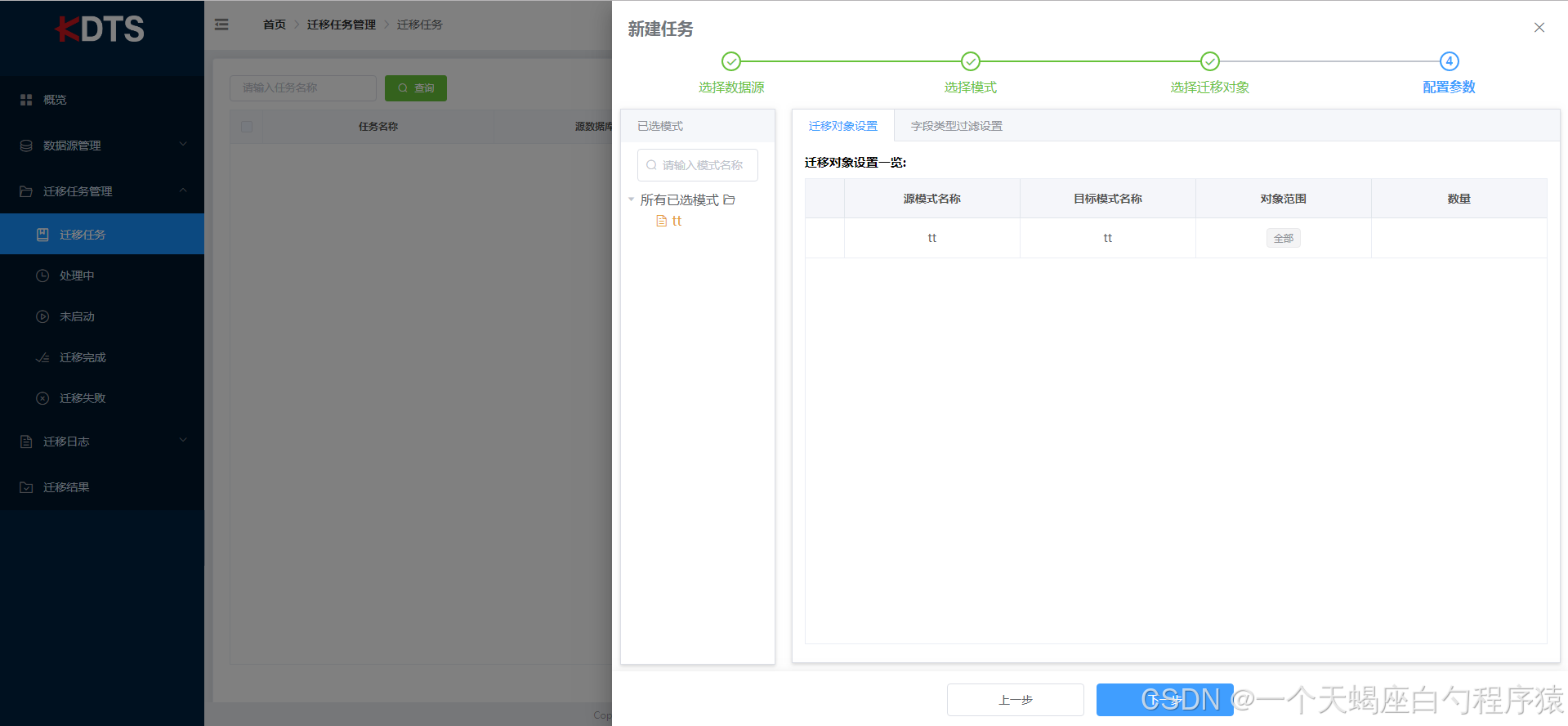
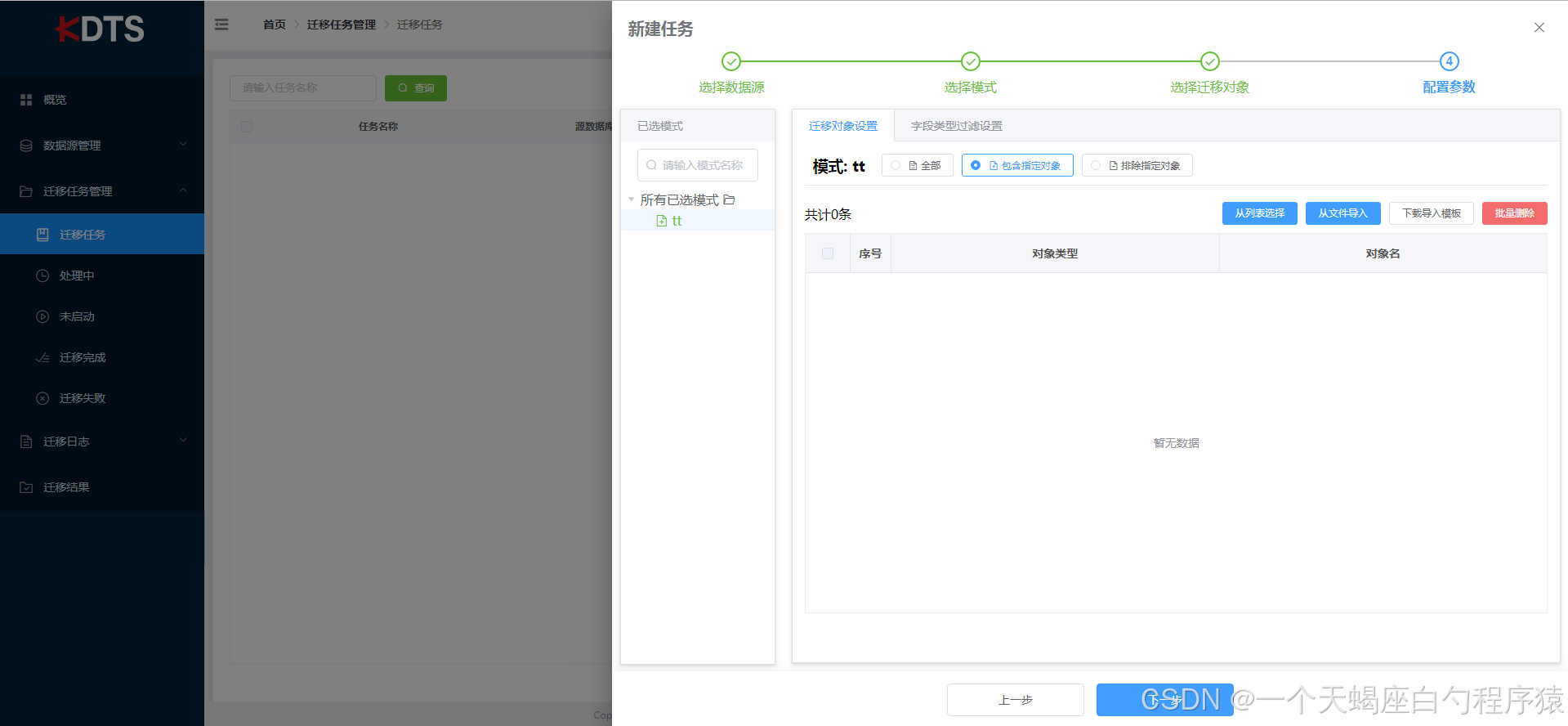
可迁移此模式下全部表,也可以指定或排除部份表,当选择“包含指定对象”或“排除指定对象”时,请通过“从列表选择”或“从文件导入”将数据添加到包含列表中
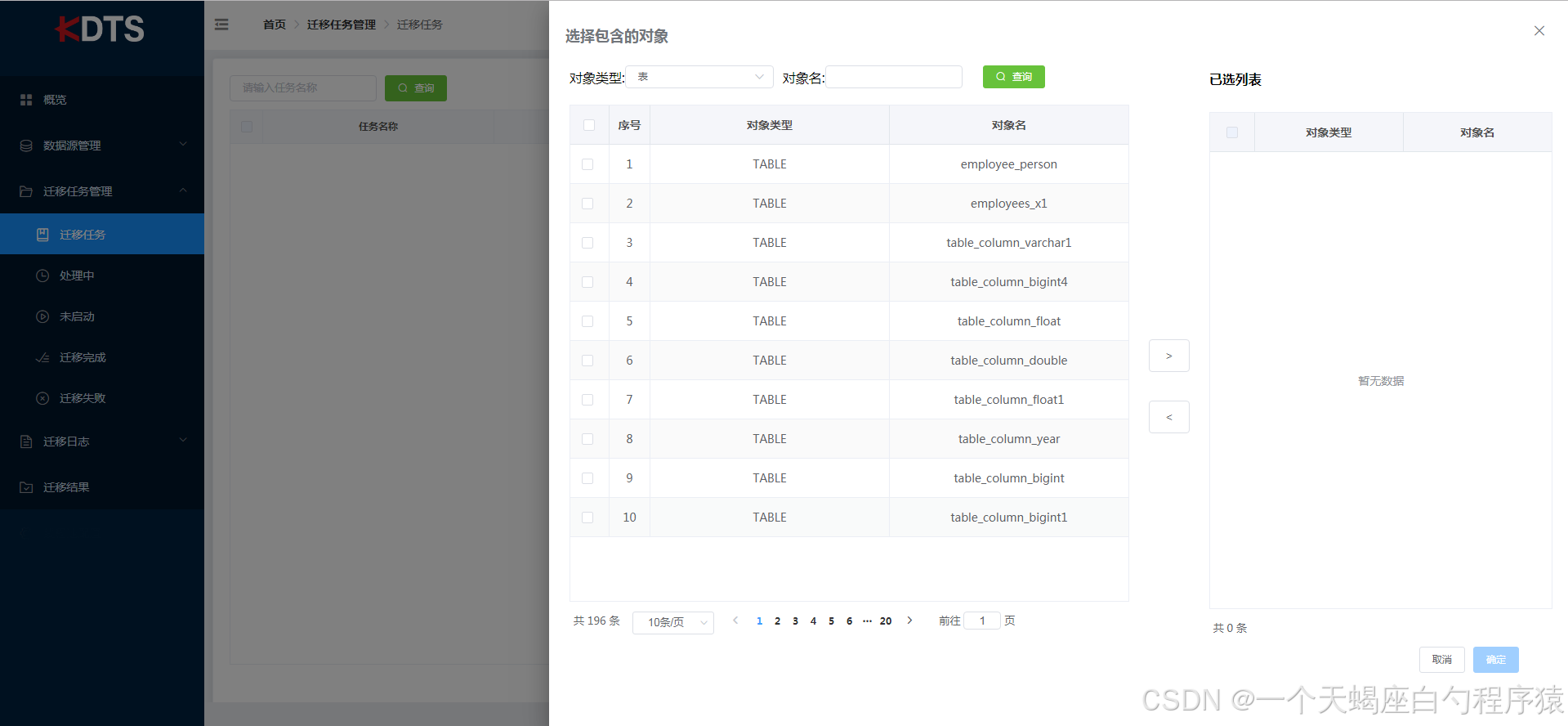
从列表选择对象时,可选择对应模式、检索对象名关键字进行快速检索对象。点击“添加”按钮后加入到已选列表,当想要移除部份表时可以选择对应的表点击“移除”按钮取消表。选择完成后点击确定
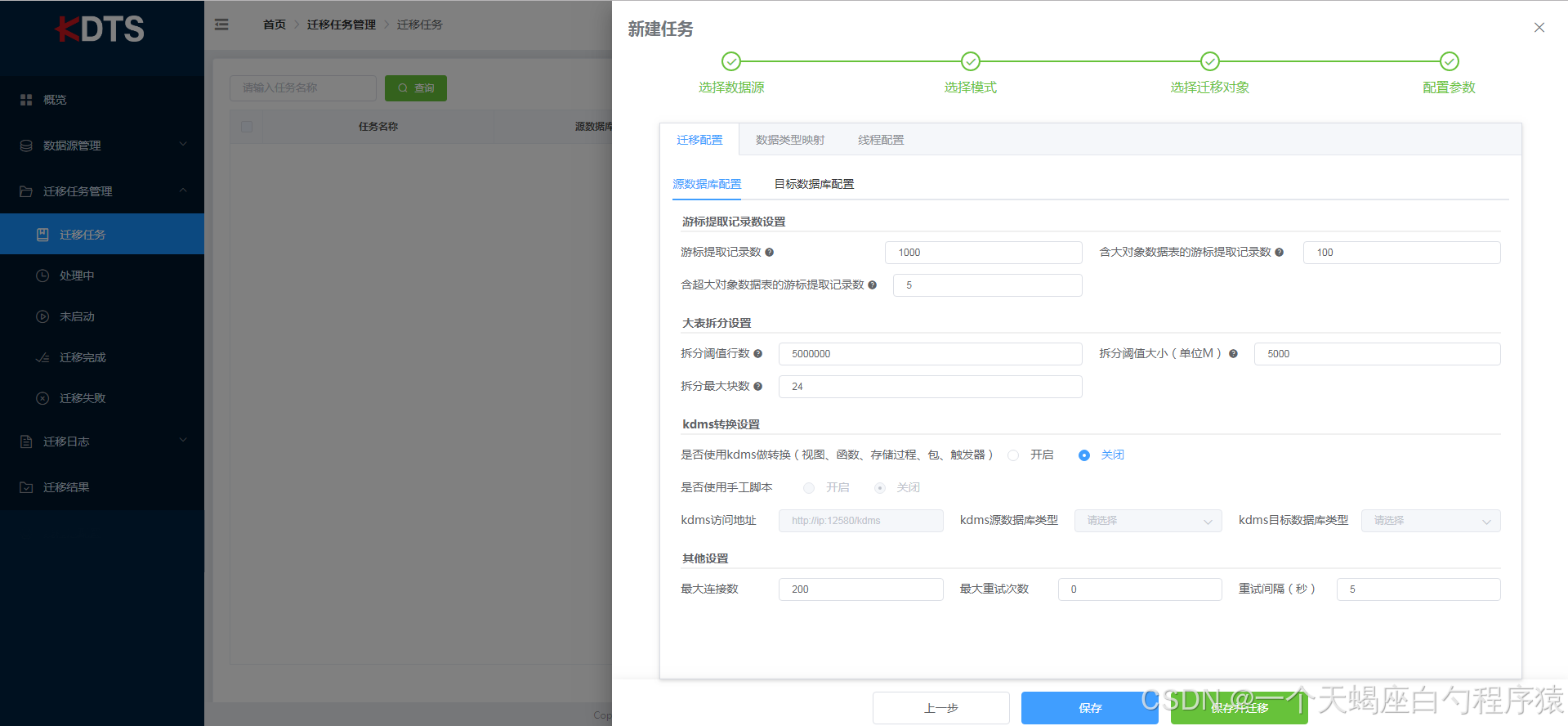
- 配置参数
迁移工具提供了一系列配置参数用于迁移方案的个性化配置,满足多种迁移场景。配置参数分为“迁移配置”、“数据类型映射”、“线程配置”三个方面
3.5 执行迁移任务(WEB)
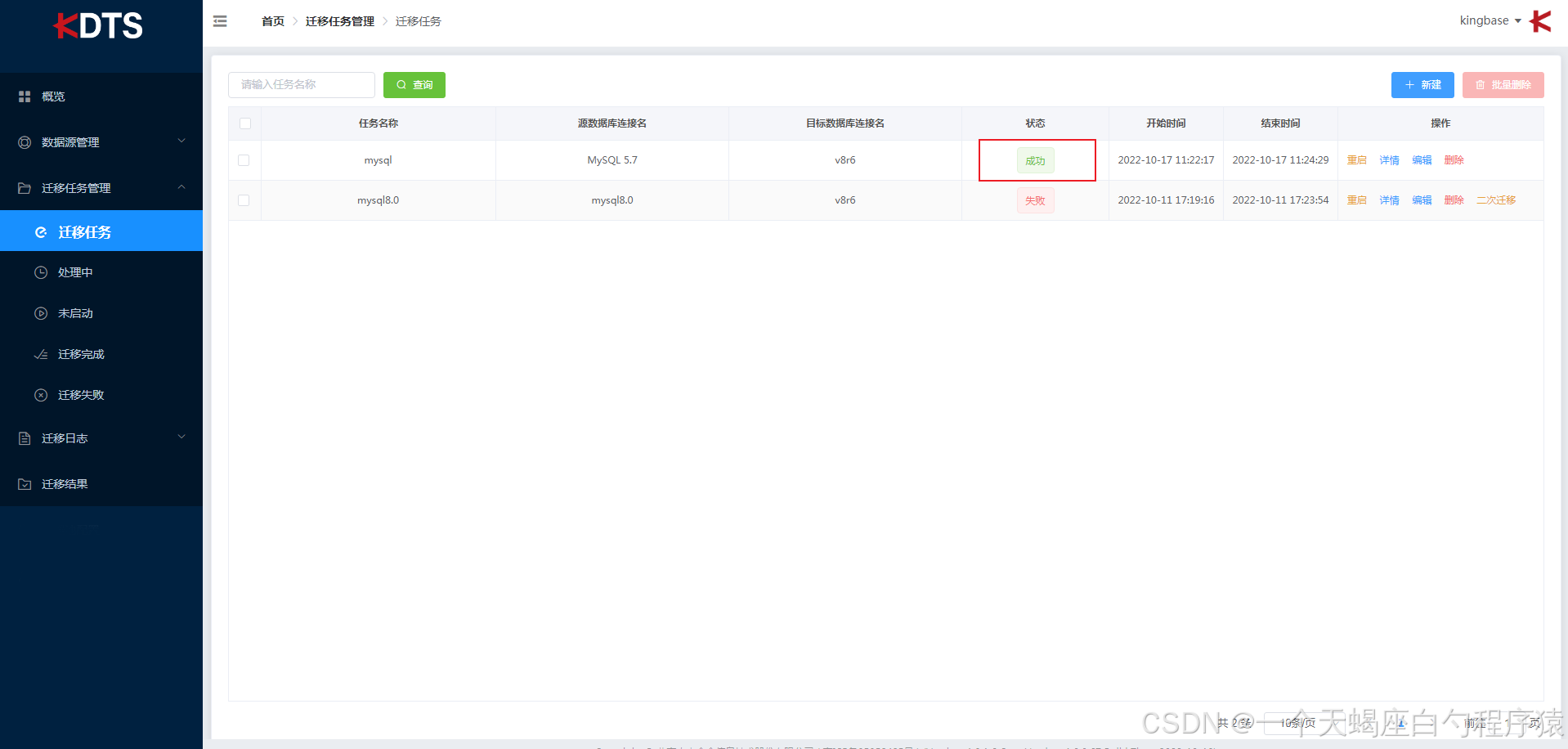
将此任务作为预迁移任务点击“保存”,或者作为执行任务点击“保存并迁移”。迁移完成后任务状态将变成:
迁移完成,迁移结束“状态”栏显示“完成”,则迁移任务成功。
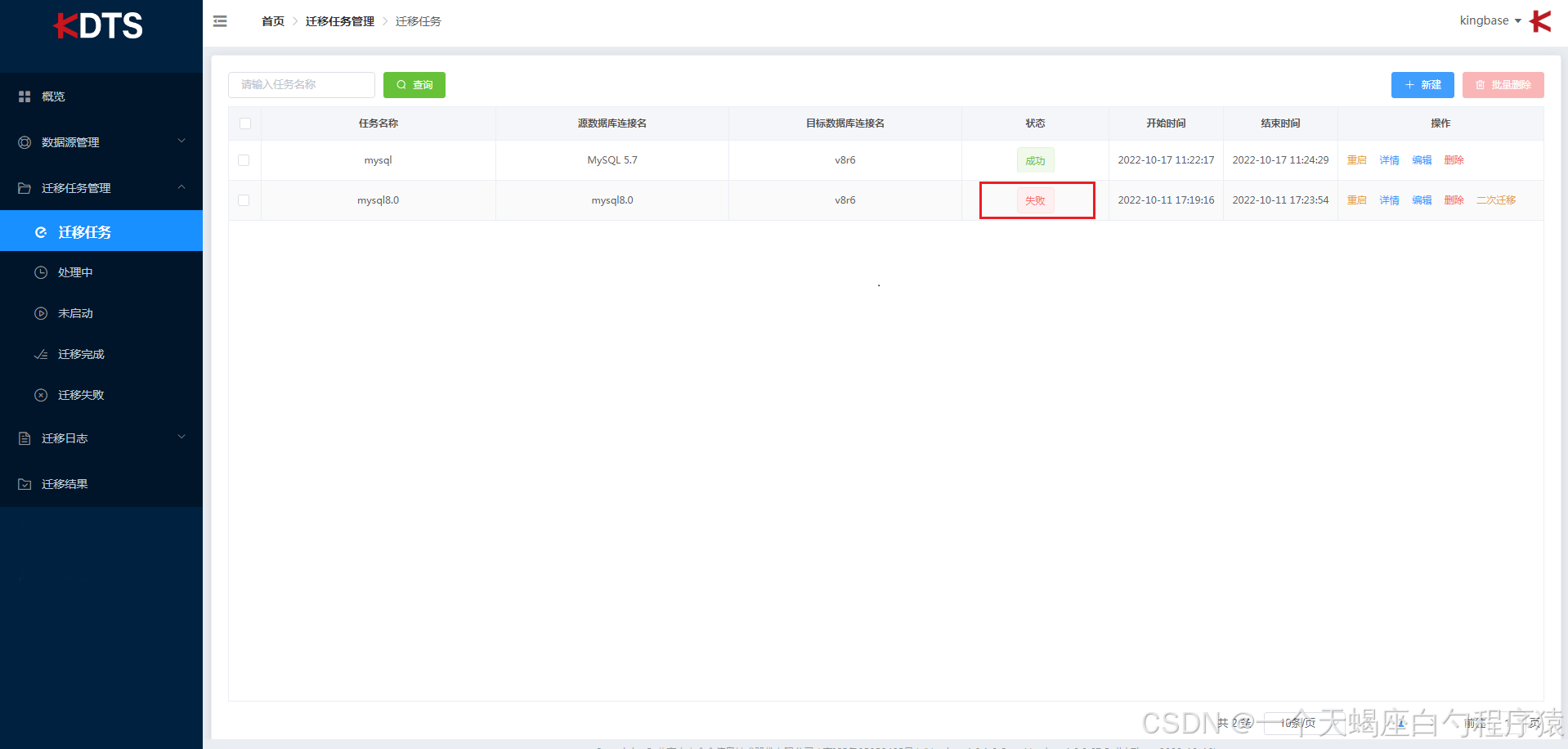
迁移失败,迁移结束“状态”栏显示“失败”,则迁移任务失败。失败后可点击详情查看日志进行解决
3.6 迁移报告及问题处理查看(WEB)
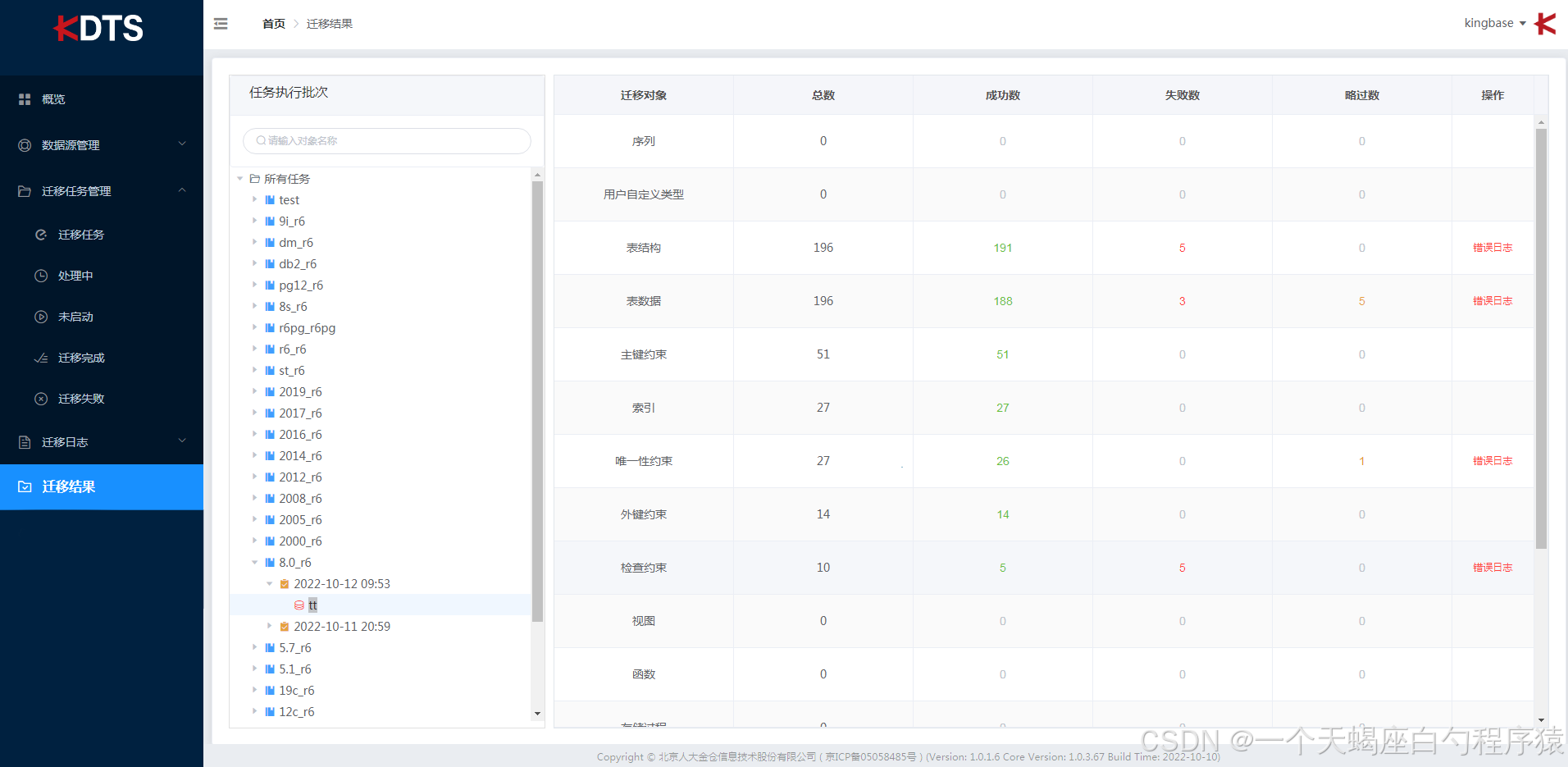
迁移完成后,需要确认执行结果,包括迁移数据量,是否有错误发生,可以通过迁移日志和迁移结果进行查看
“迁移结果”功能的工作区包括“任务执行批次”、“迁移对象”、“总数”、“成功数”、“失败数”、“略过数”、“操作”,可以查看历史迁移任务执行的每次记录,以及每次迁移的对象、成功数、失败数、查看失败任务的错误日志
3.7 配置数据库连接信息(SHELL)
配置步骤分为3步:激活配置文件、配置数据库连接、配置相关参数
(1)进入KDTS-CLI/conf目录下,打开application.yml文件,根据源库类型设置当前激活的源库配置(active: mysql)

在正确设置application.yml中的active项后,打开对应配置文件(datasource-mysql.yml),按实际运行环境进行配置
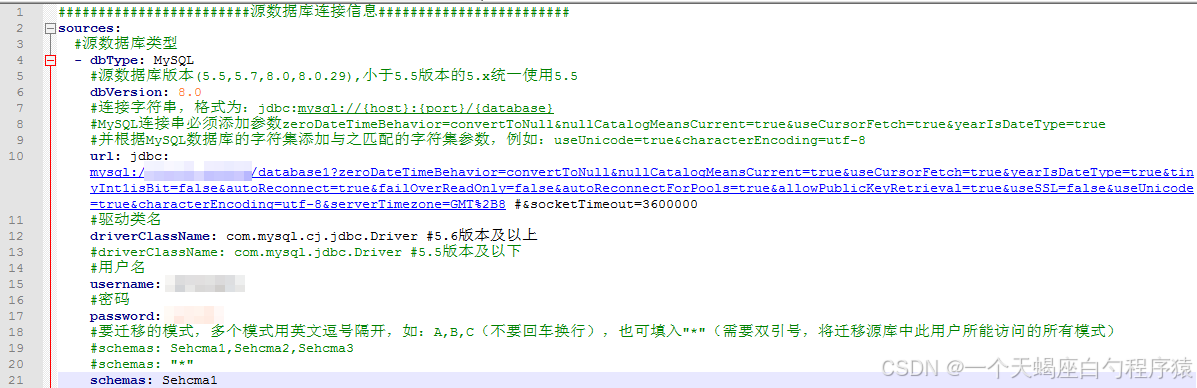
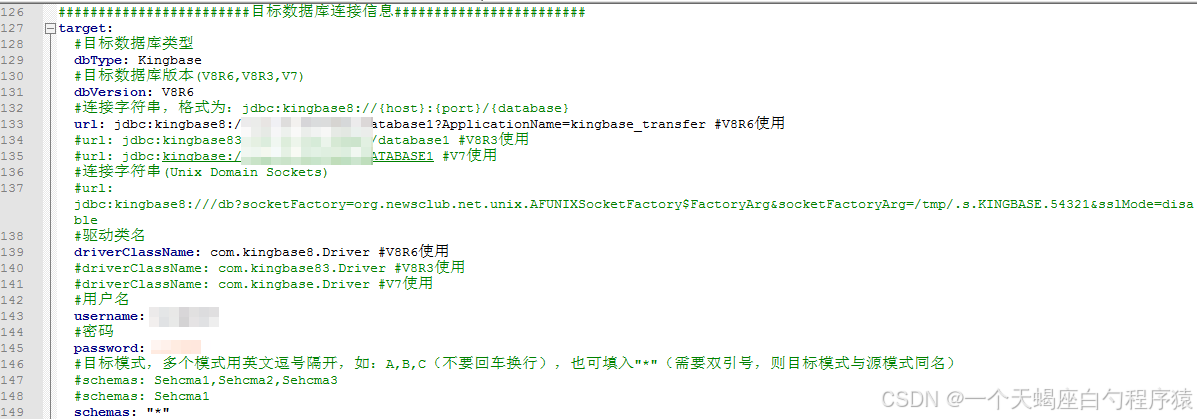
(2)配置源端数据库连接信息、目标数据库连接信息
编辑conf/datasource-mysql.yml文件,编辑源端和目标端连接信息,包括url、driver-class-name、username、password信息
(3)配置要迁移的源库模式,数据库对象,涉及到的参数如下

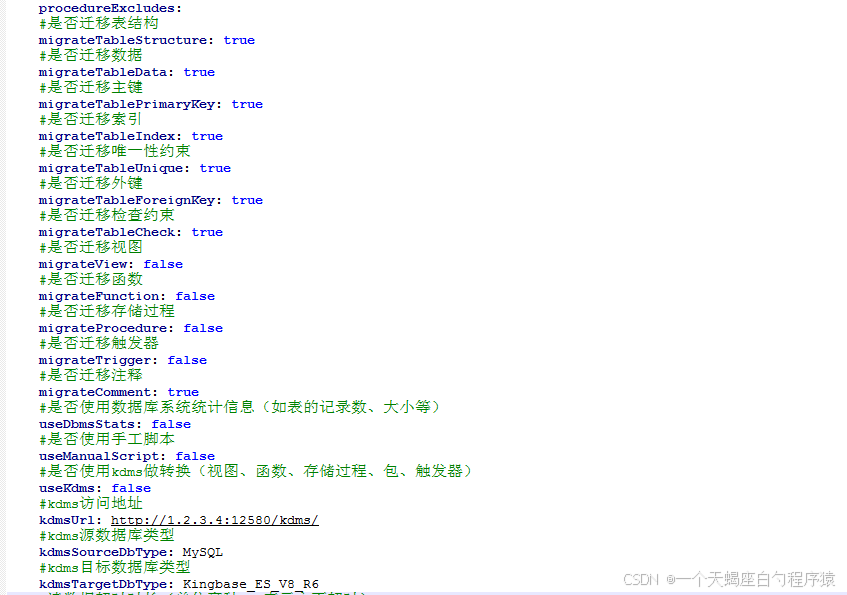
迁移配置参数整理
编辑conf/datasource-mysql.yml文件有多个配置参数,可灵活使用。以下列举常用的配置参数。fetchSize,游标提取记录数(每次和服务器交互提取的数据行数,加大该值可提升读取效率,但会增加内存开销(一次将指定数量的数据取回放在缓存中))。
tableWithLargeObjectFetchSize,含大对象数据表的游标提取记录数(同上,只是此参数针对有大对象字段的表)。
tableWithBigLargeObjectFetchSize,大表拆分阈值行数(当表的行数超过此值时,将对表进行拆分,每块的记录数为此值和表总记录数除以“拆分最大块数”中的最大值)。
largeTableSplitThresholdRows,大表拆分阈值行数(当表的行数超过此值时,将对表进行拆分,每块的记录数为此值和表总记录数除以“拆分最大块数”中的最大值)。
largeTableSplitThresholdSize,大表拆分阈值大小(单位为M)(当表的数据大小(普通字段+大对象字段)超过此值时,将对表进行拆分)。
largeTableSplitMaxChunkNum,大表拆分最大块数(每张表的最大拆分块数,应不超过总的读线程数)。
largeTableSplitConditionFile,大表拆分条件定义文件(优先于按行数和大小拆分)。
tableDataFilterConditionFile,表数据过滤条件定义文件。
useKdms,是否使用kdms做转换(视图、函数、存储过程、包、触发器)。
kdmsUrl,kdms访问地址,前提是useKdms: true。
writeBatchSize,批量提交记录数(行数据)。
writeBatchByteSize,批量提交数据大小(单位M)。
lobInMemoryThresholdSize,大对象数据读入内存阈值(单位兆,默认128M)。
dropExistingObject,删除目标库中已存在的对象(如表、视图等)。
truncateTable,是否默认清空目标库中已存在的表数据。
renameObject,目标数据库对象重命名,除表名、列名外的其他对象: pk、fk、constraint、unique constraint、index 等。
3.8 启动脚本(SHELL)
进入 KDTS-CLI/bin 目录下,编辑: startup.sh:
- 检查JDK的路径是否正确
JAVA_PATH=${BASE_PATH}/jdk
- 启动运行脚本
进入 KDTS-CLI/bin目录,执行: ./startup.sh
四、错误日志
4.1 日志路径
可以在运行日志(kdts_plus_***.log)中查看到迁移整个过程的信息,包括任务启动、迁移进程、结果汇总
可查看result下的迁移结果(在形如“result/2021-12-02_15-15-15/Sehcma1”目录下)
index.html–报告主页面
detail_XXX.html–XXX详细信息(如表结构、表数据、表主键等)
FailedScript–失败脚本目录
IgnoredScript–略过脚本目录
SuccessScript–成功脚本目录
在迁移过程中一旦某个对象创建失败,KDTS会将该对象的创建sql保留到本次迁移任务文件夹下的FailedScript目录下*.sql文件,可以手动修改后通过Ksql或者KStudio工具手动执行
4.2 常见问题
- 迁移速度慢
原因:网络带宽不足、并行度设置过低
处理:
增加read-thread和write-thread数值(建议不超过CPU核心数的2倍)。
使用万兆网卡或压缩传输(在KDTS配置中启用compress=true)。
- 字符集乱码
原因:源库与目标库字符集不一致(如MySQL的utf8mb4 vs KingBase的UTF8)。
处理:
在KDTS连接配置中显式指定字符集:
连接参数:characterEncoding=UTF8&useUnicode=true
五、结语:国产化迁移的未来趋势
通过一系列迁移操作以及全面的验证与优化,成功地将 MySQL 数据库迁移至 KingbaseES。在迁移过程中,通过 KDTS 工具实现了数据的高效迁移,经过严格的数据准确性校验,确保了迁移后数据的完整性和一致性,关键数据字段的准确率达到了 99% 以上。
然而,迁移过程并非一帆风顺,遇到了数据类型不兼容、语法差异等诸多问题。通过采取针对性的解决方案,更需要更加注重前期的调研和准备工作,充分了解源数据库和目标数据库的差异,制定更加详细和完善的迁移方案,以降低迁移风险,提高迁移成功率
应对迁移后需要进行全面的功能测试,并对测出问题及时分析、排查和修改。对那些很难定位的问题,可联系KingbaseES支持
未来,随着AI技术的融入,KDTS有望实现全自动化迁移评估、智能SQL优化、自适应性能调优,进一步推动国产数据库生态
金仓官方:https://www.kingbase.com.cn/