Spark学习记录
1、Spark基础介绍
1.1、Spark基础概念
Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎
1.2、Spark运行架构
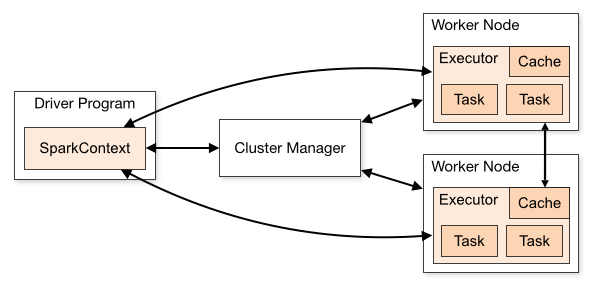
运行过程:
-
Driver 执行用户程序(Application)的
main()方法并创建 SparkContext,与 Cluster Manager 建立通信 -
Cluster Manager 为用户程序分配计算资源,返回可供使用的 Executor 列表
-
获取 Executor 资源后,Spark 会将用户程序代码及依赖包(Application jar)传递给 Executor
-
最后,SparkContext 发送 tasks(经拆解后的任务序列)到 Executor,由其执行计算任务并输出结果
Driver的职责:
-
作业解析与 DAG 生成:
-
将用户编写的 Spark 程序(如
JavaSparkContext)解析为有向无环图(DAG)。
-
-
任务调度:
-
将 DAG 划分为多个阶段(Stage)和任务(Task)。
-
为每个任务分配资源并调度到 Executor 上执行。
-
-
与集群管理器通信:
-
向集群管理器Cluster Manager申请资源(Executor)。
-
监控 Executor 的状态和资源使用情况。
-
-
结果收集:
-
接收 Executor 返回的计算结果。
-
Executor的职责:
-
执行计算任务:
-
接收 Driver 发送的任务(如
map、reduce等操作)。 -
在本地执行具体的计算逻辑。
-
-
内存管理:
-
缓存 RDD 和中间计算结果(如通过
persist()或cache())。 -
管理任务执行时的内存分配(如堆内 / 堆外内存)。
-
-
与 Driver 通信:
-
向 Driver 汇报任务状态(如完成、失败)。
-
返回计算结果给 Driver。
-
Cluster Manager的职责:
-
资源分配与调度:
-
接收 Driver 的资源请求,并在集群节点上启动相应的 Executor 进程
-
-
节点监控与故障恢复:
-
监控集群中各节点的健康状态,在节点故障时进行处理(如重新分配资源、重启 Executor)
-
1.3、Spark生态圈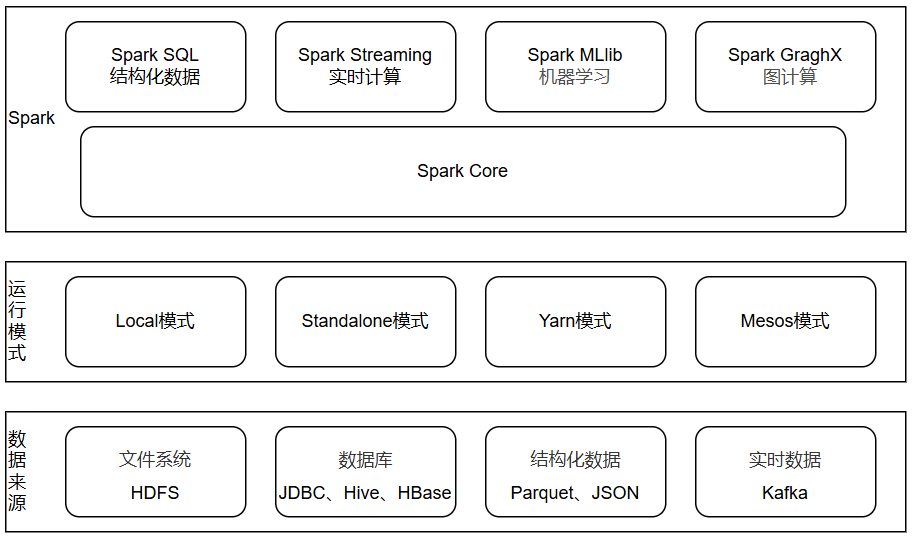
1.3.1、数据来源
Spark支持多种数据来源。包括文件系统、数据库、结构化数据、实时数据等。
1.3.2、运行模式
1.3.2.1、Local模式(单机)
Local模式就是运行在一台计算机上的模式,通常就是用于在本机上练手和测试。
1.3.2.2、Standalone模式(集群)
Standalone模式是Spark自带的资源调度引擎,构建一个由Master + Worker构成的Spark集群,Spark运行在集群中。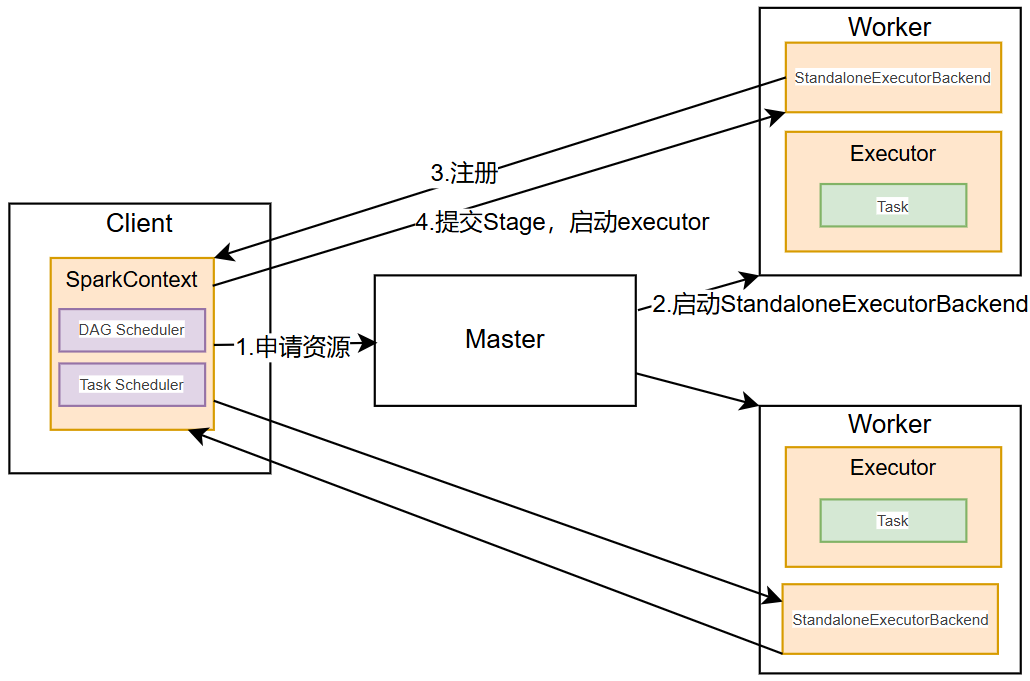
运行过程:
-
SparkContext连接到Master,向Master注册并申请资源(CPU Core 和Memory);
-
Master根据SparkContext的资源申请要求和Worker心跳周期内报告的信息决定在哪个Worker上分配资源,并在该Worker上获取资源,然后启动StandaloneExecutorBackend;
-
StandaloneExecutorBackend向SparkContext注册;
-
SparkContext将Applicaiton代码发送给StandaloneExecutorBackend;并且SparkContext解析Applicaiton代码,构建DAG图,并提交给DAG Scheduler分解成Stage,然后以Stage提交给Task Scheduler,Task Scheduler负责将Task分配到相应的Worker,最后提交给StandaloneExecutorBackend执行;
-
StandaloneExecutorBackend会建立Executor线程池,开始执行Task,并向SparkContext报告,直至Task完成。
-
所有Task完成后,SparkContext向Master注销,释放资源。
1.3.2.3、Yarn模式(集群)
Spark使用Hadoop的Yarn组件进行资源与任务调度。分为Yarn-client模式和Yarn-cluster模式。
(1)Yarn-client模式(默认)
Yarn-Client模式中,Driver在客户端本地运行,这种模式可以使得Spark Application和客户端进行交互,因为Driver在客户端,所以可以通过webUI访问Driver的状态,默认是http://{IP}:4040访问。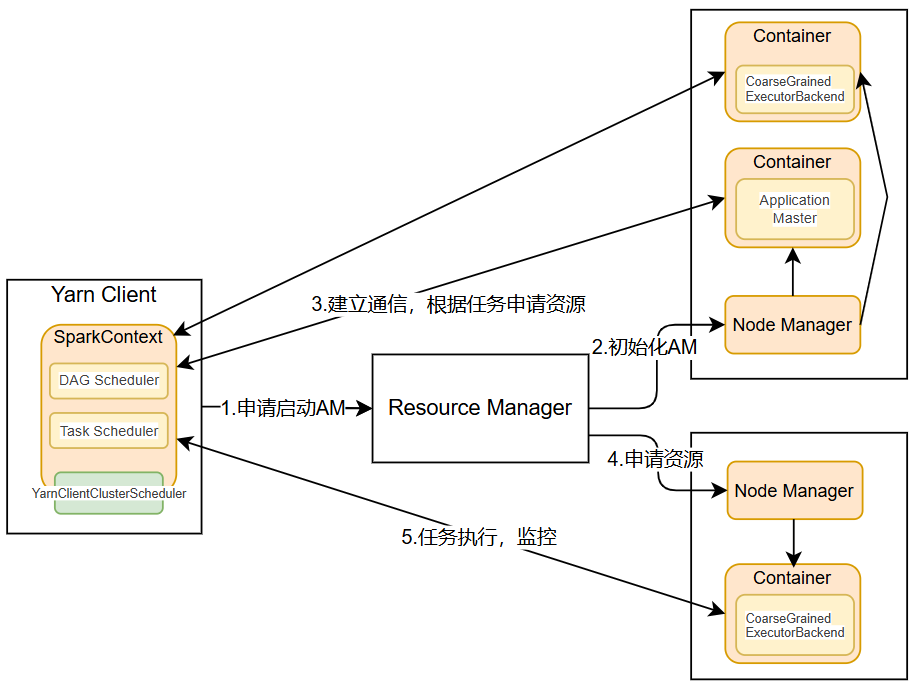
运行过程:
-
Client向Yarn的ResourceManager申请启动Application Master。同时在SparkContext初始化中将创建DAGScheduler和TASKScheduler等,由于我们选择的是Yarn-Client模式,程序会选择YarnClientClusterScheduler和YarnClientSchedulerBackend;
-
ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,与YARN-Cluster区别的是在该ApplicationMaster不运行SparkContext,只与SparkContext进行联系进行资源的分派;
-
Client中的SparkContext初始化完毕后,与ApplicationMaster建立通讯,向ResourceManager注册,根据任务信息向ResourceManager申请资源(Container);
-
一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向Client中的SparkContext注册并申请Task;
-
Client中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向Driver汇报运行的状态和进度,以让Client随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
-
应用程序运行完成后,Client的SparkContext向ResourceManager申请注销并关闭自己。
(2)Yarn-cluster模式
Yarn-cluster模式中,Driver程序运行在由ResourceManager启动的ApplicationMaster,适用于生产环境。
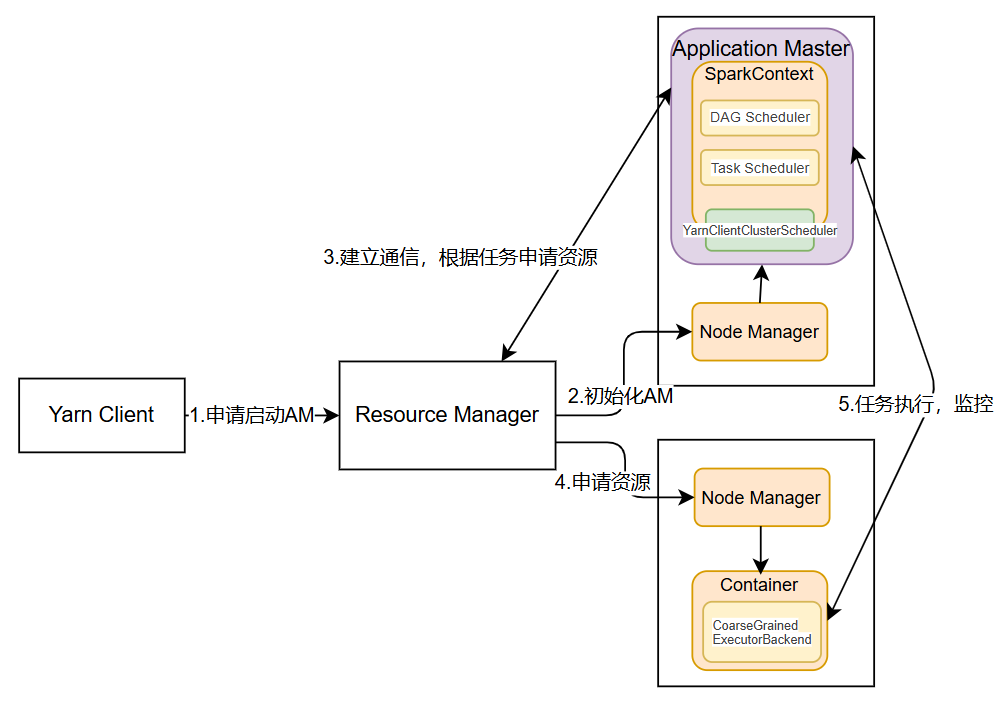
运行过程:
-
Client向Yarn中提交应用程序,包括ApplicationMaster程序、启动ApplicationMaster的命令、需要在Executor中运行的程序等;
-
ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,其中ApplicationMaster进行SparkContext等的初始化;
-
ApplicationMaster向ResourceManager注册,这样用户可以直接通过ResourceManage查看应用程序的运行状态,然后它将采用轮询的方式通过RPC协议为各个任务申请资源,并监控它们的运行状态直到运行结束;
-
一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向ApplicationMaster中的SparkContext注册并申请Task。
-
ApplicationMaster中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向ApplicationMaster汇报运行的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
-
应用程序运行完成后,ApplicationMaster向ResourceManager申请注销并关闭自己。
(3)Yarn-cluster 和 Yarn-client 区别与联系
-
从广义上讲,Yarn-cluster适用于生产环境;而Yarn-client适用于交互和调试,也就是希望快速地看到application的输出。
-
从深层次的含义讲,Yarn-cluster和Yarn-client模式的区别其实就是Application Master进程的区别,Yarn-cluster模式下,driver运行在AM(Application Master)中,它负责向YARN申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉Client,作业会继续在YARN上运行。然而Yarn-cluster模式不适合运行交互类型的作业。而Yarn-client模式下,Application Master仅仅向YARN请求executor,client会和请求的container通信来调度他们工作,也就是说Client不能离开。
1.3.2.4、Mesos模式(集群)
Spark使用Mesos平台进行资源与任务的调度。
1.3.3、Spark核心模块
(1)Spark Core:Spark的基础组件,提供了分布式数据处理的核心功能,包括任务调度、内存管理、错误恢复、与存储系统交互等模块。还包含了对弹性分布式数据集(Resilient Distributed DataSet,简称RDD)的API定义。
(2)Spark SQL:提供了对结构化数据的处理能力,支持SQL查询和Spark DataFrame API。
(3)Spark Streaming:用于处理实时数据流,支持高吞吐量的数据流处理。它可以将实时数据源如Kafka、Flume等集成到Spark应用中,实现实时数据处理和分析。
(4)Spark MLlib:机器学习库,提供了丰富的机器学习算法,包括分类、回归、聚类、协同过滤等。MLlib支持多种编程语言,如Scala、Java、Python和R。
(5)Spark GraghX:用于图数据处理和分析的库,支持图计算、图算法等。GraphX可以高效地处理大规模图数据,适用于社交网络分析、推荐系统等领域。
1.4、Spark与MapReduce
1.4.1、MapReduce框架
MapReduce 是一种分布式计算编程模型,由 Google 在 2004 年提出,用于大规模数据处理。
Hadoop MapReduce 是其开源实现,成为 Hadoop 生态的核心组件之一,用于在集群上并行处理海量数据。
数据处理流程是从数据源获取数据,经过分析计算后,将结果输出到指定位置,核心是一次计算,不适合迭代计算。
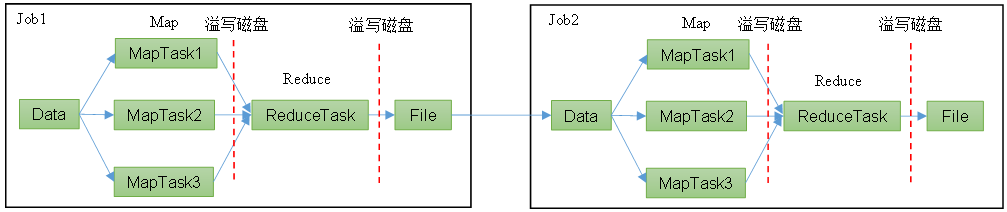
1.4.2、Spark框架
基于内存处理,可以将多个计算任务迭代,中间结果可以不落盘(注:Shuffle是落盘的)

1.4.3、Spark与MapReduce的区别
| 特性 | Spark | MapReduce |
| 开发语言 | Java+Scala | Java |
| 编程模型 | 多种API,多语言接口,多种操作方式(DataFrame、Dataset 和 SQL) | Map 和 Reduce |
| 延迟性 | 低 | 高 |
| 适用场景 | 迭代计算、实时处理 | 批处理 |
| 容错机制 | RDD 血统 | 检查点和重新计算 |
| 资源管理 | Stanalone、Yarn、Mesos | Hadoop Yarn |
| 数据处理类型 | 批处理、流处理、交互式查询 | 批处理 |
| 处理方式 | 在MR的基础上优化了计算过程 | 出现的较早,只考虑单一的操作 |
| 计算模式 | 内存计算为主 | 磁盘计算为主 |
1.5、Spark快速开始
1.5.1、安装包下载
下载地址:Downloads | Apache Spark
1.5.2、上传并解压安装包
tar -zxvf spark-3.3.1-bin-hadoop3.tgz1.5.3、执行官方示例
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.12-3.3.1.jar \
10参数解释:
bin/spark-submit:提交spark任务
--class org.apache.spark.examples.SparkPi:要执行程序的主类
--master local[2]:
(1)local:没有指定线程数,则所有计算都运行在一个线程当中,没有任何并行计算
(2)local[K]:指定使用K个Core来运行计算,比如local[2]就是运行2个Core来执行
(3)local[*]:自动帮你按照CPU最多核来设置线程数
./examples/jars/spark-examples_2.12-3.3.1.jar:要运行的程序
10:要运行程序的输入参数
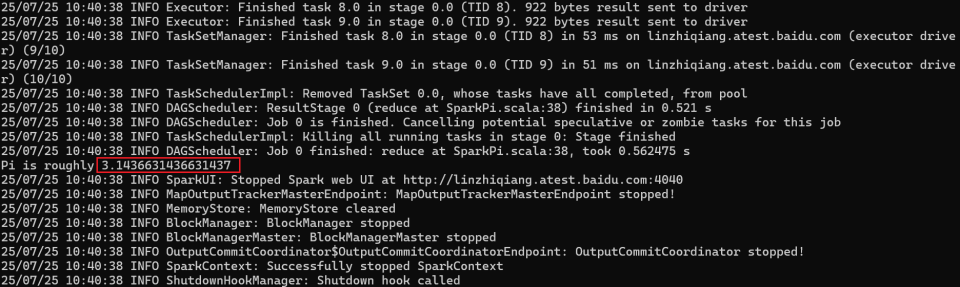
1.5.4、结果截图展示
2、Spark Core模块
Spark 计算框架为了能够进行高并发和高吞吐的数据处理,封装了三大数据结构,用于处理不同的应用场景。三大数据结构分别是:
-
RDD : 弹性分布式数据集
-
累加器:分布式共享只写变量
-
广播变量:分布式共享只读变量
2.1、RDD
2.1.1、RDD基本概念
RDD叫做弹性分布式数据集,是Spark中最基本的数据抽象。代码中是一个抽象类,它代表一个弹性的、不可变的、可分区的、里面的元素可并行计算的集合。
-
弹性:
-
自动进行内存和磁盘数据存储的切换
-
Spark优先把数据放到内存中,如果内存放不下,就会放到磁盘里面,程序进行自动的存储切换
-
-
基于血统的高效容错机制
-
在RDD进行转换和动作的时候,会形成RDD的Lineage依赖链,当某一个RDD失效的时候,可以通过重新计算上游的RDD来重新生成丢失的RDD数据。
-
-
Task如果失败会自动进行特定次数的重试
-
RDD的计算任务如果运行失败,会自动进行任务的重新计算,默认次数是4次。
-
-
Stage如果失败会自动进行特定次数的重试
-
如果Job的某个Stage阶段计算失败,框架也会自动进行任务的重新计算,默认次数也是4次。
-
-
Checkpoint和Persist可主动或被动触发
-
RDD可以用Persist持久化将RDD缓存到内存或者磁盘,当再次用到该RDD时直接读取就行。也可以将RDD进行检查点,检查点会将数据存储在HDFS中,该RDD的所有父RDD依赖都会被移除。
-
-
数据调度弹性
-
Spark把这个Job执行模型抽象为通用的有向无环图DAG,可以将多Stage的任务串联或并行执行,调度引擎自动处理Stage的失败以及Task的失败。
-
-
数据分片的高度弹性
-
可以根据业务的特征,动态调整数据分片的个数,提升整体的应用执行效率。
-
不可变性:
-
RDD是不可变的,这意味着一旦创建,其内容就不能被改变。这种设计保证了RDD的只读属性,使得Spark能够在分布式环境中安全地高并发并行处理数据,而不用担心数据在处理过程中的修改。不可变性简化了并行计算的实现,因为它允许Spark优化数据的访问和存储,避免了并发修改带来的复杂性。
-
-
分区:
-
RDD是可分区的,这意味着可以将数据集分割成多个分区,每个分区可以被存储在集群中的不同节点上。这种分区机制允许Spark并行处理数据,每个分区可以在不同的节点上同时处理,极大地提高了处理速度和效率。通过合理的分区策略,可以优化数据的本地访问和减少跨节点通信的开销。
-
-
并行计算:
-
RDD支持并行计算,这是Spark的核心优势之一。通过对数据进行分区,Spark可以将计算任务分配到多个节点上并行执行。这种并行处理能力使得Spark能够处理大规模数据集,同时保持较高的处理速度和效率。通过使用如
map、filter、reduce等操作,可以在不同的分区上独立地执行数据处理逻辑,从而实现高效的并行计算。
-
2.1.2、RDD创建方式
2.1.2.1、从集合(内存)中创建RDD:parallelize
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("spark");JavaSparkContext jsc = new JavaSparkContext(conf);JavaRDD<String> stringRDD = jsc.parallelize(Arrays.asList("hello", "spark"), 2);//2:代表分区数2.1.2.2、从外部存储(文件)中创建RDD
由外部存储系统的数据集创建RDD包括:本地的文件系统,还有所有Hadoop支持的数据集,比如HDFS、HBase等。
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("spark");JavaSparkContext jsc = new JavaSparkContext(conf);JavaRDD<String> lineRDD = jsc.textFile("input.text");JavaPairRDD<LongWritable, Text> hadoopRDD =sc.hadoopFile("input", TextInputFormat.class, LongWritable.class, Text.class, 2);2.1.3.3、从其他RDD中创建
主要是通过一个RDD运算完后,再产生新的RDD。
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("spark");JavaSparkContext jsc = new JavaSparkContext(conf);JavaRDD<String> stringRDD = jsc.parallelize(Arrays.asList("hello", "spark"), 2);JavaRDD<String> mapRDD = stringRDD.map(s -> s + "123");2.1.3、分区(Partition)和分区器(Partitioner)
2.1.3.1、分区(Partition)
分区是 RDD(弹性分布式数据集)的基本组成单位,是一个逻辑上的概念,表示数据的分片。每个分区可被单独处理,分布在集群的不同节点上,实现并行计算。
分区数的设置优先级:
1. 优先使用方法参数
jsc.parallelize(Arrays.asList("hello", "spark"), 2);jsc.textFile("input.text", 2);2. 使用配置参数:spark.default.parallelism
sparkConf.set("spark.default.parallelism", "4");3. 采用环境默认总核值
sparkConf.setMaster("local[*]");分区数据的分配规则:
针对集合(内存)中创建的RDD:
val start = ((i * length) / numSlices).toInt
val end = (((i + 1) * length) / numSlices).toInt
i:索引编号,从0开始;length:数据的数组长度;numSlices:分区数
针对外部存储中创建的RDD:
Spark框架文件的操作没有自己的实现的。采用MR库(Hadoop)来实现,当前读取文件的切片数量不是由Spark决定的,而是由Hadoop决定。
注:底层使用函数minPartitions = Math.min(defaultParallelism, 2),以上设置的分区上不一定是最终分区数
2.1.3.2、分区器(Partitioner)
分区器是一种策略,用于决定 RDD 中的键值对(Key-Value)如何被分配到各个分区中。Spark目前支持Hash分区器、Range分区器和用户自定义分区器。Hash分区器为当前的默认分区器。分区器直接决定了RDD中分区的个数、RDD中每条数据经过Shuffle后进入哪个分区和Reduce的个数。
注意:
(1)只有Key-Value类型的pairRDD才有分区器,非Key-Value类型的RDD分区的值是None,数据分布由系统自动管理,通常采用轮询(round-robin)方式分配到不同分区
(2)每个RDD的分区ID范围:0~numPartitions-1,决定这个值是属于那个分区的。
Hash分区器:
对于给定的key,计算其hashCode,并除以分区的个数取余,如果余数小于0,则用余数+分区的个数(否则加0),最后返回的值就是这个key所属的分区ID。
Range分区器:
将一定范围内的数映射到某一个分区内,尽量保证每个分区中数据量均匀,而且分区与分区之间是有序的,一个分区中的元素肯定都比另一个分区内的元素小或者大,但是分区内的元素是不能保证顺序的。
用户自定义分区器:
-
定义分区器类:继承
org.apache.spark.Partitioner类,并实现其抽象方法。 -
实现
numPartitions方法:返回分区数量。 -
实现
getPartition方法:根据键返回其分区ID。 -
在操作中使用自定义分区器:在执行如
groupByKey或reduceByKey等操作时,通过设置参数来使用自定义分区器。
2.1.4、RDD算子
将数据转化为RDD之后,就需要进行RDD的计算,RDD提供了计算方法RDD的方法又称为RDD算子。RDD 支持两种类型的算子:转换算子(transformation) 和动作算子( action)。转换算子可以将已有RDD转换得到一个新的RDD,而动作算子则是基于RDD的计算,并将结果返回给驱动器(driver)。
2.1.4.1、转换算子-transformation
用于从现有 RDD 创建新的 RDD,原有的RDD保持不变,不会触发实际计算。转换算子是惰性的(Lazy),仅记录计算逻辑(DAG),不立即执行。
针对Value类型(部分方法):
| 方法 | 解释 | 示例 |
| map()映射 | 参数f是一个函数,可以写作匿名子类,它可以接收一个参数。当某个RDD执行map方法时,会遍历该RDD中的每一个数据项,并依次应用f函数,从而产生一个新的RDD。 | JavaRDD<String> lineRDD = sc.textFile("input/1.txt"); JavaRDD<String> mapRDD = lineRDD.map(s -> s + "||"); |
| flatMap()扁平化 | 与map操作类似,将RDD中的每一个元素通过应用f函数依次转换为新的元素,并封装到RDD中。 | List<List<Integer>> datas = Arrays.asList( Arrays.asList(1, 2), Arrays.asList(3, 4) ); JavaRDD<List<Integer>> rdd = jsc.parallelize(datas, 2); JavaRDD<Integer> flatMapRDD = rdd.flatMap(new FlatMapFunction<List<Integer>, Integer>() { @Override public Iterator<Integer> call(List<Integer> list) { return list.iterator(); } }); |
| mapPartitions()按分区批量处理 | 对每个分区的数据批量应用函数,函数输入为整个分区的迭代器。 | JavaRDD<Integer> integerJavaRDD = parallelize.mapPartitions(new FlatMapFunction<Iterator<Integer>, Integer>() { @Override public Iterator<Integer> call(Iterator<Integer> integerIterator) throws Exception { List<Integer> list = new ArrayList<>(); while (integerIterator.hasNext()) { Integer next = integerIterator.next(); list.add(next * 2); } return list.iterator(); } }); |
| groupBy()分组 | 按照传入函数的返回值进行分组。将相同的key对应的值放入一个迭代器。 groupBy会存在shuffle过程 shuffle:将不同的分区数据进行打乱重组的过程 | JavaRDD<Integer> integerJavaRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4),2); JavaPairRDD<Integer, Iterable<Integer>> groupByRDD = integerJavaRDD.groupBy((Function<Integer, Integer>) v1 -> v1 % 2); |
| filter()过滤 | 接收一个返回值为布尔类型的函数作为参数。当某个RDD调用filter方法时,会对该RDD中每一个元素应用f函数,如果返回值类型为true,则该元素会被添加到新的RDD中。 | JavaRDD<Integer> integerJavaRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4),2); JavaRDD<Integer> filterRDD = integerJavaRDD.filter((Function<Integer, Boolean>) v1 -> v1 % 2 == 0); |
| distinct()去重 | 对内部的元素去重,并将去重后的元素放到新的RDD中。 | JavaRDD<Integer> integerJavaRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5, 6), 2); JavaRDD<Integer> distinct = integerJavaRDD.distinct(); |
| sortBy()排序 | 该操作用于排序数据。在排序之前,可以将数据通过f函数进行处理,之后按照f函数处理的结果进行排序,默认为正序排列。排序后新产生的RDD的分区数与原RDD的分区数一致。Spark的排序结果是全局有序。 | JavaRDD<Integer> integerJavaRDD = sc.parallelize(Arrays.asList(5, 8, 1, 11, 20), 2); JavaRDD<Integer> sortByRDD = integerJavaRDD.sortBy((Function<Integer, Integer>) v1 -> v1, true, 2); |
针对Key-Value类型(部分方法):要想使用Key-Value类型的算子首先需要使用mapToPair方法转换为PairRDD
| 方法 | 解释 | 示例 |
| mapValues() | 针对于(K,V)形式的类型只对V进行操作 | JavaRDD<Integer> integerJavaRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4),2); JavaPairRDD<String, String> pairRDD = integerJavaRDD.mapToPair((PairFunction<Integer, String, String>) integer -> new Tuple2<>(integer.toString(), integer.toString())); JavaPairRDD<String, String> mapValuesRDD = pairRDD.mapValues((Function<String, String>) v1 -> v1 + "|||"); |
| groupByKey() | groupByKey对每个key进行操作,但只生成一个seq,并不进行聚合。该操作可以指定分区器或者分区数(默认使用HashPartitioner) | JavaRDD<String> integerJavaRDD = sc.parallelize(Arrays.asList("hi","hi","hello","spark" ),2); JavaPairRDD<String, Integer> pairRDD = integerJavaRDD.mapToPair((PairFunction<String, String, Integer>) s -> new Tuple2<>(s, 1)); JavaPairRDD<String, Iterable<Integer>> groupByKeyRDD = pairRDD.groupByKey(); |
| reduceByKey() | 该操作可以将RDD[K,V]中的元素按照相同的K对V进行聚合。其存在多种重载形式,还可以设置新RDD的分区数。与groupByKey()的区别在于在shuffle之前有combine(预聚合)操作,在不影响业务逻辑的前提下,优先选用reduceByKey() | JavaRDD<String> integerJavaRDD = sc.parallelize(Arrays.asList("hi","hi","hello","spark" ),2); JavaPairRDD<String, Integer> pairRDD = integerJavaRDD.mapToPair((PairFunction<String, String, Integer>) s -> new Tuple2<>(s, 1)); JavaPairRDD<String, Integer> result = pairRDD.reduceByKey((Function2<Integer, Integer, Integer>) Integer::sum); |
| sortByKey() | 在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD | JavaPairRDD<Integer, String> javaPairRDD = sc.parallelizePairs(Arrays.asList(new Tuple2<>(4, "a"), new Tuple2<>(3, "c"), new Tuple2<>(2, "d"))); JavaPairRDD<Integer, String> pairRDD = javaPairRDD.sortByKey(false); |
2.1.4.2、动作算子-action
行动算子是触发了整个作业的执行。
| 方法 | 解释 | 示例 |
| collect() | 以数组Array的形式返回数据集的所有元素 | JavaRDD<Integer> integerJavaRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4),2); List<Integer> collect = integerJavaRDD.collect(); |
| count() | 返回RDD中元素的个数 | JavaRDD<Integer> integerJavaRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4),2); long count = integerJavaRDD.count(); |
| first() | 返回RDD中的第一个元素 | JavaRDD<Integer> integerJavaRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4),2); Integer first = integerJavaRDD.first(); |
| take() | 返回一个由RDD的前n个元素组成的数组 | JavaRDD<Integer> integerJavaRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4),2); List<Integer> list = integerJavaRDD.take(3); |
| countByKey() | 统计每种key的个数 | JavaPairRDD<String, Integer> pairRDD = sc.parallelizePairs(Arrays.asList(new Tuple2<>("a", 8), new Tuple2<>("b", 8), new Tuple2<>("a", 8), new Tuple2<>("d", 8))); Map<String, Long> map = pairRDD.countByKey(); |
| saveAsTextFile() | 将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它转换为文件中的文本,每条记录占一行,适用于存储普通文本或 JSON 等可解析的字符串数据。 | JavaRDD<Integer> integerJavaRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4),2); integerJavaRDD.saveAsTextFile("output"); |
| saveAsObjectFile() | 将RDD中的元素序列化成对象,存储到文件中(二进制格式保存),适用于存储复杂对象(如自定义类或复杂结构数据),但需配合 Spark 提供的序列化框架(如 Kryo 序列化)使用。 | JavaRDD<Integer> integerJavaRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4),2); integerJavaRDD.saveAsObjectFile("output1"); |
| foreach() | 遍历RDD中每一个元素 | JavaRDD<Integer> integerJavaRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4),4); integerJavaRDD.foreach((VoidFunction<Integer>) System.out::println); |
| foreachPartition() | 遍历RDD中每一个分区 | JavaRDD<Integer> parallelize = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5, 6), 2); parallelize.foreachPartition((VoidFunction<Iterator<Integer>>) integerIterator -> { // 一次处理一个分区的数据 while (integerIterator.hasNext()) { Integer next = integerIterator.next(); System.out.println(next); } }); |
2.1.4.3、混洗算子-shuffle
混洗算子(shuffle operator)指的是那些导致Spark重新分配数据以达到重新组织数据的目的的操作。Shuffle操作通常发生在需要基于键(key)对数据进行重新分组或聚合时,比如在执行groupByKey、reduceByKey、aggregateByKey、join(特别是大key的join)等操作时。
示例:在执行groupByKey时,Spark需要将具有相同键的数据聚合到同一个节点上,这就需要将数据从一个节点移动到包含所有具有该键数据的节点上。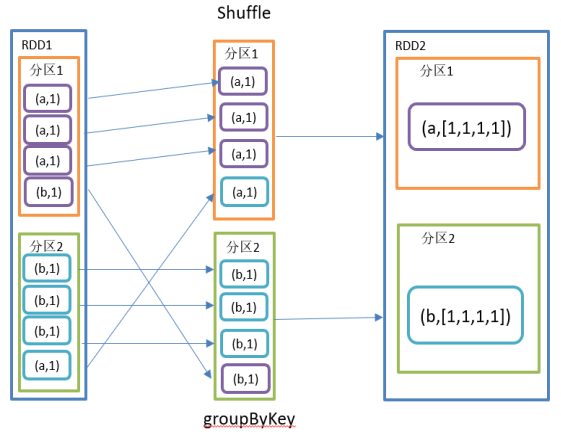
优化混洗操作的策略
-
减少混洗的数据量:尽量减少需要混洗的数据量。例如,通过在map阶段进行过滤,减少后续混洗操作的数据量。
-
使用合适的分区策略:合理设置分区数可以减少混洗的开销。例如,在执行
groupByKey之前使用repartition(重新分配数据,会触发shuffle)或coalesce(合并分区,不会触发shuffle)来调整数据的分区数。 -
避免宽依赖:尽量避免宽依赖(wide dependency),即尽量避免在混洗操作中使用大宽度的键。例如,使用
mapToPair和reduceByKey组合代替groupByKey,因为reduceByKey通常有更好的性能。 -
广播变量:对于小数据集的join操作,使用广播变量可以减少混洗的需求。
-
使用缓存:对频繁使用的数据进行缓存可以减少混洗操作的重复执行。
2.1.5、RDD依赖关系
2.1.5.1、RDD血缘关系
RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage(血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。通过.toDebugString()方法查看RDD血缘关系。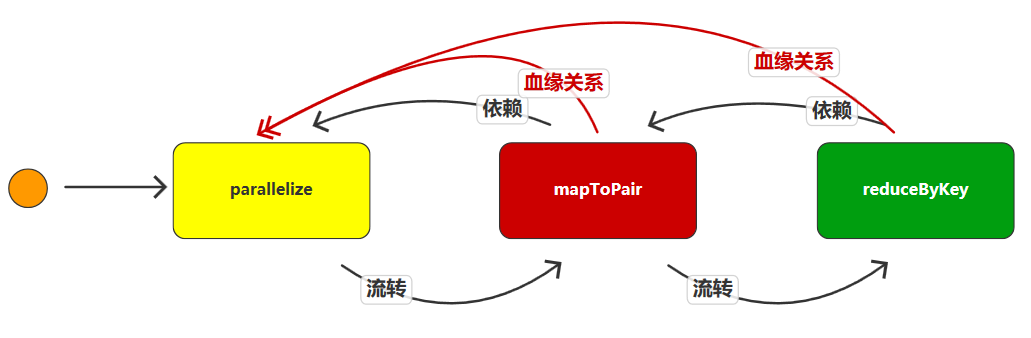
(8) ParallelCollectionRDD[0] at parallelize at SparkLineage.java:30 []**************mapToPair依赖parallelize****************(8) MapPartitionsRDD[1] at mapToPair at SparkLineage.java:33 []| ParallelCollectionRDD[0] at parallelize at SparkLineage.java:30 []**************reduceByKey依赖mapToPair****************(8) ShuffledRDD[2] at reduceByKey at SparkLineage.java:36 []+-(8) MapPartitionsRDD[1] at mapToPair at SparkLineage.java:33 []| ParallelCollectionRDD[0] at parallelize at SparkLineage.java:30 []2.1.5.2、宽依赖
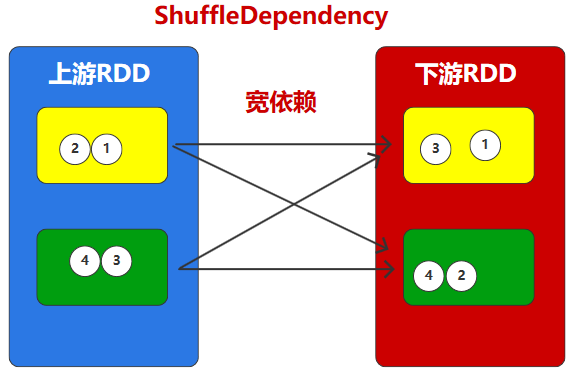
宽依赖表示同一个父RDD的Partition被多个子RDD的Partition依赖(只能是一对多),会引起Shuffle。宽依赖的算子包括sort、reduceByKey、groupByKey、join和调用rePartition函数的任何操作,在不影响业务的情况下,应避免使用。
2.1.5.3、窄依赖
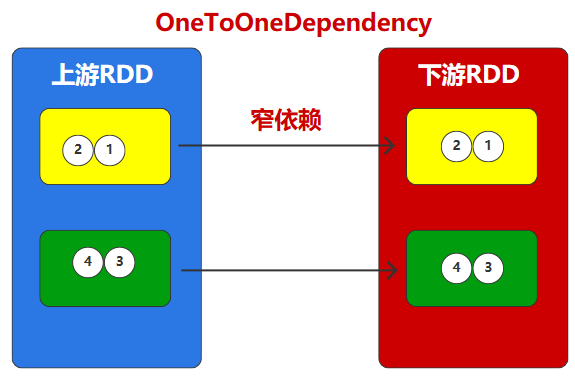
窄依赖表示每一个父RDD的Partition最多被子RDD的一个Partition使用(一对一or多对一)。
2.1.5.4、DAG有向无环图
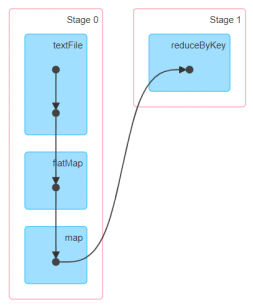
DAG(Directed Acyclic Graph)有向无环图是由点和线组成的拓扑图形,该图形具有方向,不会闭环。例如,DAG记录了RDD的转换过程和任务的阶段。
2.1.5.5、RDD任务划分
-
Application:初始化一个SparkContext即生成一个Application;
-
Job:一个Action算子就会生成一个Job;
-
Stage:Stage等于宽依赖的个数加1;
-
Task:一个Stage阶段中,最后一个RDD的分区个数就是Task的个数。
注意:Application->Job->Stage->Task每一层都是1对n的关系。
2.1.6、序列化
在实际开发中我们往往需要自己定义一些对于RDD的操作,那么此时需要注意的是,初始化工作是在Driver端进行的,而实际运行程序是在Executor端进行的,这就涉及到了跨进程通信,是需要序列化的。
示例:
在以下示例中,若User未实现implements Serializable接口,会报错SparkException: Task not serializable和java.io.NotSerializableException: com.example.spark.User
User zhangsan = new User("zhangsan", 13);User lisi = new User("lisi", 13);JavaRDD<User> userJavaRDD = sc.parallelize(Arrays.asList(zhangsan, lisi), 2);JavaRDD<User> mapRDD = userJavaRDD.map((Function<User, User>) v1 -> new User(v1.getName(), v1.getAge() + 1));mapRDD. collect().forEach(System.out::println);序列化方式:Java序列化(默认)、Kryo序列化(推荐)
Java的序列化能够序列化任何的类。但是比较重,序列化后对象的体积也比较大。Spark出于性能的考虑,Spark2.0开始支持另外一种Kryo序列化机制。Kryo速度是Serializable的10倍。当RDD在Shuffle数据的时候,简单数据类型、数组和字符串类型已经在Spark内部使用Kryo来序列化。
示例:
引入依赖(Spark已内置)
<dependency><groupId>com.esotericsoftware</groupId><artifactId>kryo</artifactId><version>5.6.1</version></dependency>代码中修改序列化机制和注册要序列化的类
SparkConf conf = new SparkConf();conf.setMaster("local[*]");conf.setAppName("sparkCore");// 替换默认的序列化机制conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");// 注册需要使用kryo序列化的自定义类conf.registerKryoClasses(new Class[]{Class.forName("com.atguigu.bean.User")});2.1.7、RDD持久化
2.1.7.1、RDD Cache缓存
RDD通过Cache或者Persist方法将前面的计算结果缓存,默认情况下会把数据以序列化的形式缓存在JVM的堆内存中。但是并不是这两个方法被调用时立即缓存,而是触发后面的action算子时,该RDD将会被缓存在计算节点的内存中,并供后面重用。注意:cache操作会增加血缘关系,不改变原有的血缘关系
默认存储级别是 StorageLevel.MEMORY_ONLY(以Java序列化方式存到内存里)。完整的存储级别列表如下:
| 存储级别 | 含义 |
| MEMORY_ONLY | 以未序列化的 Java 对象形式将 RDD 存储在 JVM 内存中。如果RDD不能全部装进内存,那么将一部分分区缓存,而另一部分分区将每次用到时重新计算。这个是Spark的RDD的默认存储级别。 |
| MEMORY_AND_DISK | 以未序列化的Java对象形式存储RDD在JVM中。如果RDD不能全部装进内存,则将不能装进内存的分区放到磁盘上,然后每次用到的时候从磁盘上读取。 |
| MEMORY_ONLY_SER | 以序列化形式存储 RDD(每个分区一个字节数组)。通常这种方式比未序列化存储方式要更省空间,尤其是如果你选用了一个比较好的序列化协议(fast serializer),但是这种方式也相应的会消耗更多的CPU来读取数据。 |
| MEMORY_AND_DISK_SER | 和 MEMORY_ONLY_SER 类似,只是当内存装不下的时候,会将分区的数据吐到磁盘上,而不是每次用到都重新计算。 |
| DISK_ONLY | RDD 数据只存储于磁盘上。 |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2等 | 和上面没有”_2″的级别相对应,只不过每个分区数据会在两个节点上保存两份副本。 |
缓存有可能丢失,或者存储于内存的数据由于内存不足而被删除,RDD的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于RDD的一系列转换,丢失的数据会被重算,由于RDD的各个Partition是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部Partition。
设置缓存示例:
mapRDD.cache();mapRDD.persist(StorageLevel.MEMORY_ONLY());2.1.7.2、RDD CheckPoint检查点
由于血缘依赖过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果检查点之后有节点出现问题,可以从检查点开始重做血缘,减少了开销。检查点的目的是将RDD中间结果写入磁盘。检查点存储路径通常是存储在HDFS等容错、高可用的文件系统。检查点数据存储格式为:二进制的文件。检查点触发时间和Cache缓存一样,不会马上被执行,必须执行Action操作才能触发。检查点会切断血缘关系。而且检查点为了数据安全,会从血缘关系的最开始执行一遍。推荐做法是先进行Cache缓存操作,再进行CheckPoint检查点操作。
sparkContext.setCheckpointDir("hdfs://hadoop102:9000/spark/checkpoint");//设置检查点路径mapRDD.cache();//执行cache方法,缓存数据mapRDD.checkpoint();//设置检查点2.1.7.3、缓存和检查点的的区别
-
Cache缓存只是将数据保存起来,不切断血缘依赖。Checkpoint检查点切断血缘依赖。
-
Cache缓存的数据通常存储在磁盘、内存等地方,可靠性低。Checkpoint的数据通常存储在HDFS等容错、高可用的文件系统,可靠性高。
-
建议对checkpoint()的RDD使用Cache缓存,这样checkpoint的job只需从Cache缓存中读取数据即可,否则需要再从头计算一次RDD。
-
如果使用完了缓存,可以通过unpersist()方法释放缓存。
2.2、累加器
累加器:分布式共享只写变量
累加器支持在所有节点间进行累加操作(如计数或求和),但仅允许驱动程序(Driver Program)读取最终结果。
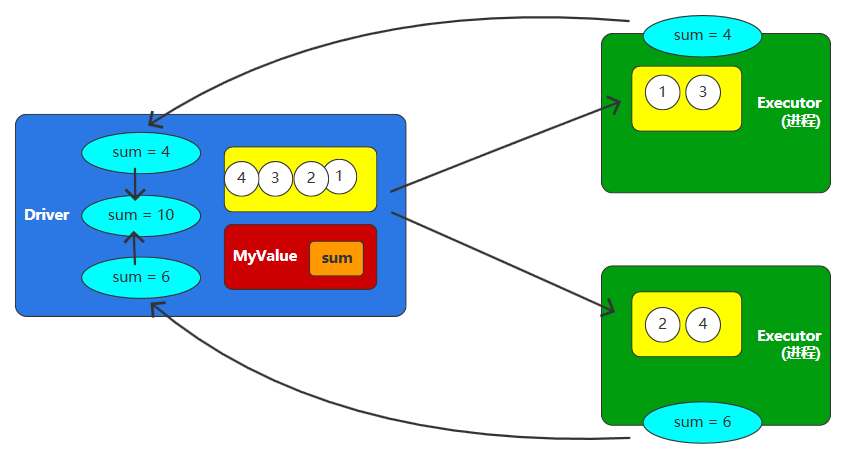
2.2.1、系统累加器
Spark内置了三种类型的Accumulator,分别是LongAccumulator用来累加整数型,DoubleAccumulator用来累加浮点型,CollectionAccumulator用来累加集合元素。
代码示例:
LongAccumulator longAccumulator = sc.sc().longAccumulator();// LongAccumulator: 数值型累加DoubleAccumulator doubleAccumulator = sc.sc().doubleAccumulator();// DoubleAccumulator: 小数型累加CollectionAccumulator<Integer> collectionAccumulator = sc.sc().collectionAccumulator();// CollectionAccumulator:集合累加List<Integer> integers = parallelize.map((Function<Integer, Integer>) v1 -> {longAccumulator.add(v1);doubleAccumulator.add(v1);collectionAccumulator.add(v1);return v1;}).collect();System.out.println(collectionAccumulator.value());//driver端获取累加值System.out.println(longAccumulator.value());//driver端获取累加值System.out.println(doubleAccumulator.value());//driver端获取累加值2.2.2、自定义累加器
当内置的Accumulator无法满足要求时,可以继承AccumulatorV2实现自定义的累加器。
代码示例:
1. 继承AccumulatorV2,实现相关方法
class BigIntegerAccumulator extends AccumulatorV2<BigInteger, BigInteger> {private BigInteger num = BigInteger.ZERO;public BigIntegerAccumulator() {}public BigIntegerAccumulator(BigInteger num) {this.num = new BigInteger(num.toString());}//检查当前值是否为零@Overridepublic boolean isZero() {return num.compareTo(BigInteger.ZERO) == 0;}//创建当前累加器的副本@Overridepublic AccumulatorV2<BigInteger, BigInteger> copy() {return new BigIntegerAccumulator(num);}//重置累加器的值(通常用于重新开始累加)@Overridepublic void reset() {num = BigInteger.ZERO;}//向累加器添加数值@Overridepublic void add(BigInteger num) {this.num = this.num.add(num);}//将当前值与本地值相加,并更新本地累加器的值@Overridepublic void merge(AccumulatorV2<BigInteger, BigInteger> other) {num = num.add(other.value());}//返回当前累加器的值,仅在Driver端可用@Overridepublic BigInteger value() {return num;}}2. 创建自定义Accumulator的实例,然后在SparkContext上注册它
// 直接new自定义的累加器BigIntegerAccumulator bigIntegerAccumulator = new BigIntegerAccumulator();// 然后在SparkContext上注册一下sparkContext.register(bigIntegerAccumulator, "bigIntegerAccumulator");2.3、广播变量
广播变量:分布式共享只读变量。
广播变量用来高效分发较大的对象。向所有工作节点发送一个较大的只读值,以供一个或多个Spark Task操作使用。
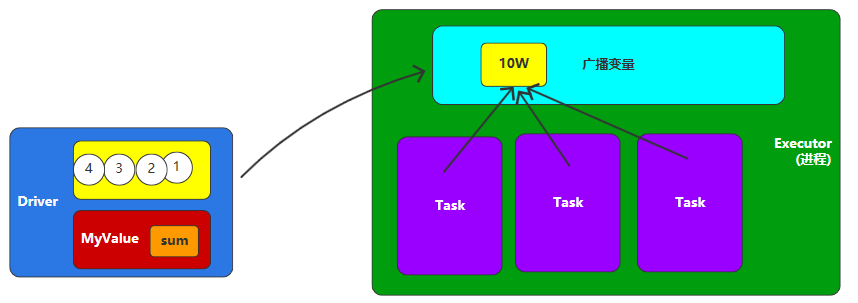
代码示例:
final JavaRDD<String> rdd = sparkContext.parallelize(Arrays.asList("Hello", "Spark", "Hadoop", "Flink", "Spark", "Hadoop"));List<String> okList = Arrays.asList("Spark", "Hadoop");//假设一个大对象final Broadcast<List<String>> broadcast = sparkContext.broadcast(okList);//构建一个广播变量final JavaRDD<String> filterRDD = rdd.filter(s -> broadcast.value().contains(s)//broadcast.value()拉取广播变量的值);3、Spark SQL模块
3.1、概述
Spark SQL是用于结构化数据处理的Spark模块。与基本的Spark RDD API不同,Spark SQL提供的接口为Spark提供了有关数据结构和正在执行的计算的更多信息。在内部,Spark SQL使用这些额外的信息来执行额外的优化。与Spark SQL交互的方式有多种,包括SQL和Dataset API。计算结果时,使用相同的执行引擎,与您用于表达计算的API/语言无关。
3.2、Spark SQL特点
- 易整合
无缝的整合了SQL查询和Spark编程。
Dataset<Row> ds = sparkSession.read().json("data/user.json");//将数据模型转换成表,方便SQL的使用ds.createOrReplaceTempView("user");//使用SQL文的方式操作数据String sql = "select avg(age) from user";Dataset<Row> sqlDS = sparkSession.sql(sql);//展示数据模型的效果sqlDS.show();- 统一的数据访问方式
使用相同的方式连接不同的数据源。
Dataset<Row> ds = sparkSession.read().json("data/user.json");//将数据模型转换成表,方便SQL的使用ds.createOrReplaceTempView("user");-
兼容Hive
在已有的仓库上直接运行SQL或者HQL。
SparkSession sparkSession = SparkSession.builder().enableHiveSupport() //启用Hive的支持.master("local[*]").appName("SparkSQL").getOrCreate();sparkSession.sql("show tables").show();sparkSession.sql("create table user_info(name String,age bigint)");-
标准的数据连接
通过JDBC或者ODBC来连接。
Dataset<Row> jdbc = sparkSession.read().jdbc("jdbc:mysql://localhost:3306/gmall", "activity_info", properties);//连接mysql数据库3.3、Spark SQL发展历程
RDD(Spark1.0)=》Dataframe(Spark1.3)=》Dataset(Spark1.6)
如果同样的数据都给到这三个数据结构,他们分别计算之后,都会给出相同的结果。不同的是他们的执行效率和执行方式。在现在的版本中,Dataset性能最好,已经成为了唯一使用的接口。其中Dataframe已经在底层被看做是特殊泛型的DataSet<Row>。
RDD、DataFrame、DataSet三者的共性:
-
三者都是Spark平台下的分布式弹性数据集,为处理超大型数据提供便利。
-
三者都有惰性机制,在进行创建、转换,如map方法时,不会立即执行,只有在遇到Action行动算子如foreach时,三者才会开始遍历运算。
-
三者有许多共同的函数,如filter,排序等。
-
三者都会根据Spark的内存情况自动缓存运算。
-
三者都有分区的概念。
3.4、Spark SQL编程
3.3.1、SparkSession
在老的版本中,SparkSQL提供两种SQL查询起始点:
-
一个叫SQLContext,用于Spark自己提供的SQL查询;
-
一个叫HiveContext,用于连接Hive的查询。
SparkSession是Spark最新的SQL查询起始点,实质上是SQLContext和HiveContext的组合,所以在SQLContext和HiveContext上可用的API在SparkSession上同样是可以使用的。
SparkSession内部封装了SparkContext,所以计算实际上是由SparkContext完成的。
//第一种方式SparkConf conf = new SparkConf().setAppName("sparksql").setMaster("local[*]");SparkContext sc = new SparkContext(conf);SparkSession sparkSession = new SparkSession(sc);//第二种方式SparkSession sparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL").enableHiveSupport() // 关键:开启Hive功能.getOrCreate();//第三种方式SparkConf conf = new SparkConf().setAppName("sparksql").setMaster("local[*]");SparkSession sparkSession = SparkSession.builder().config(conf).getOrCreate();3.3.3、Spark SQL入门
//构建环境对象SparkSession sparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL").getOrCreate();//对接文件数据源时,会将文件中的一行数据封装为Row对象Dataset<Row> ds = sparkSession.read().json("data/user.json");//可以转换成RDD对象JavaRDD<Row> javaRDD = ds.javaRDD();//将数据模型转换成临时视图,方便SQL的使用ds.createOrReplaceTempView("user");//使用SQL文的方式操作数据String sql = "select * from user";//执行sql查询Dataset<Row> sqlDS = sparkSession.sql(sql);//展示数据模型的效果sqlDS.show();//DSL语法ds.select("*").show();//DSL语法ds.select("name","age").where(ds.col("name").equalTo("张三")).show();//释放资源sparkSession.close();3.3.4、数据的加载与保存
3.3.4.1、CSV文件
Dataset<Row> csv = sparkSession.read().option("header", "true") //配置是否第一行为表头(列名).option("sep","_") //配置分隔符,默认是英文的逗号(,).csv("data/user.csv");csv.write().mode(SaveMode.Append)//追加模式,不影响原有文件。Overwrite:覆盖原有文件;Ignore:有文件则不操作;ErrorIfExists:存在文件就报错.option("header", "true") //配置第一行是否是表头.csv("output");3.3.4.2、JSON文件
Dataset<Row> json = sparkSession.read().json("data/user.json");json.write().json("output");3.3.4.3、Parquet文件(列式存储文件)
Dataset<Row> csv = sparkSession.read().json("data/user.json");csv.write().parquet("output");3.3.4.4、对接MySQL
Properties properties = new Properties();properties.setProperty("user","root");properties.setProperty("password","000000");Dataset<Row> jdbc = sparkSession.read().jdbc("jdbc:mysql://hadoop102:3306/gmall?useSSL=false&useUnicode=true&characterEncoding=UTF-8&allowPublicKeyRetrieval=true", "activity_info", properties);jdbc.show();3.3.6、用户自定义函数
3.3.6.1、UDF
用于处理单行数据并返回单个值。其输入和输出为1:1关系,即输入一行数据后输出单个结果。
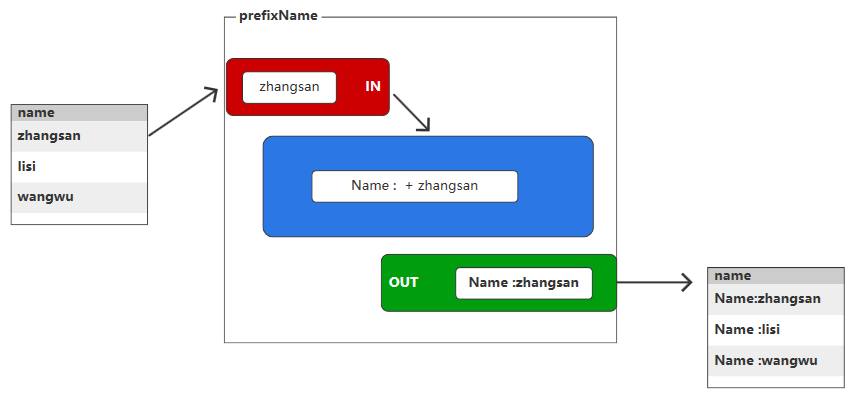
sparkSession.udf().register("prefixName", new UDF1<String, String>() {@Overridepublic String call(String name) throws Exception {return "Name:" + name;}}, DataTypes.StringType);String sql = "select prefixName(name) from user";Dataset<Row> sqlDS = sparkSession.sql(sql);3.3.6.2、UDAF
用于处理多行数据并返回单个聚合结果,通常用于统计、分组汇总等场景。
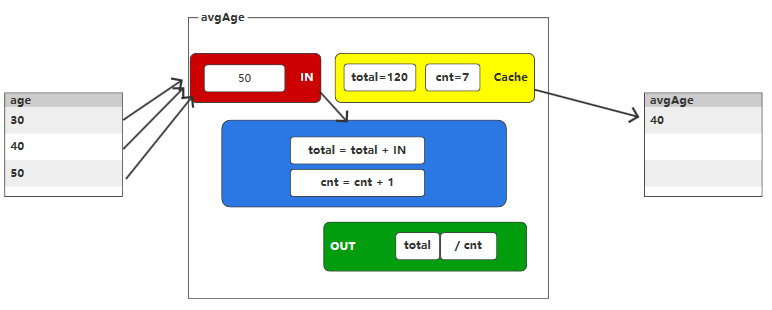
第一步:自定义UDAF函数
//自定义缓冲区的数据类型@Data@AllArgsConstructorpublic class AvgAgeBuffer implements Serializable {private Long total;private Long cnt;}//1. 创建自定义的【公共】类//2. 继承 org.apache.spark.sql.expressions.Aggregator//3. 设定泛型// IN : 输入数据类型// BUFF : 缓冲区的数据类型// OUT : 输出数据类型//4. 重写方法public class MyAvgAgeUDAF extends Aggregator<Long, AvgAgeBuffer, Long> {@Override// TODO 缓冲区的初始化操作public AvgAgeBuffer zero() {return new AvgAgeBuffer(0L, 0L);}@Override// TODO 将输入的年龄和缓冲区的数据进行聚合操作public AvgAgeBuffer reduce(AvgAgeBuffer buffer, Long in) {buffer.setTotal(buffer.getTotal() + in);buffer.setCnt(buffer.getCnt() + 1);return buffer;}@Override// TODO 合并缓冲区的数据public AvgAgeBuffer merge(AvgAgeBuffer b1, AvgAgeBuffer b2) {b1.setTotal(b1.getTotal() + b2.getTotal());b1.setCnt(b1.getCnt() + b2.getCnt());return b1;}@Override// TODO 计算最终结果public Long finish(AvgAgeBuffer buffer) {return buffer.getTotal() / buffer.getCnt();}@Overridepublic Encoder<AvgAgeBuffer> bufferEncoder() {return Encoders.bean(AvgAgeBuffer.class);}@Overridepublic Encoder<Long> outputEncoder() {return Encoders.LONG();}}第二步:使用
sparkSession.udf().register("avgAge", udaf(new MyAvgAgeUDAF(), Encoders.LONG()));String sql = "select avgAge(age) from user";Dataset<Row> sqlDS = sparkSession.sql(sql);