【Datawhale之Happy-LLM】Encoder-only模型篇 task05精华~
Task05:第三章 预训练语言模型PLM
3.1 Encoder Only之BERT
(这是笔者自己的学习记录,仅供参考,原始学习链接,愿 LLM 越来越好❤)
主流PLM的概况
PLM = pretrained language model,是在编解码的基础上引入了ELMo的预训练思路。
预训练+微调 处理 NLP任务
主流代表如下:
| 模型 | 推出公司 | 架构类型 | 主要任务方向 | 预训练方式/特点 |
|---|---|---|---|---|
| BERT | Google 2018 | Encoder-only | NLU(自然语言理解) | 提出MLM(掩码mask),堆叠Encoder层 |
| GPT 系列 | OpenAI | Decoder-only | NLG(自然语言生成) | 基于原有LM(语言模型),扩大参数量与训练语料 |
| T5 | Encoder-Decoder | 综合任务 | 保留完整Transformer架构,统一文本到文本 |
下面会介绍model的模型架构、选择的预训练任务、优势。
BERT
- 来自Transformer的双向编码表示法
= Bidirectional Encoder Representation from Transformer - 是PLM-预训练语言模型,seq2seq模型,LLM出来之前在多个NLP任务中up to SOTA(state of the art这个领域的no.1)
- 有很多变种,这里主要介绍 BERT(Google)、RoBERTa(Facebook)、ALBERT(Google),还有进一步改进了预训练任务的 ERNIE、对 BERT 进行蒸馏的小模型 DistilBERT、主打多语言任务的 XLM 等
- 主要做NLU任务,理解强,可做评论分类
BERT怎么问世的?
主要有2个原因:
- Transforme架构:2017年架构提出,牛逼。然后谷歌2018年就采用架构里的encoder优化,适配NLU任务
- 预训练+微调的范式:ELMo提出了很好的这种思路,有一个通用的pre模型,再结合具体任务微调,肯定更适配具体任务。
预训练+微调范式的优势?
- 传统是每个任务要重新用新的标注(全监督)数据训练出模型
- 而这种范式是
先花大钱训练【长时间、大规模数据和参数】一个通用的模型【强大的语言理解和生成能力】,再根据不同的下游任务再花小钱用少量数据进行微调。(成本低、应用价值广) - 因为训练大规模的,所以数据肯定肯定用的(无监督)数据,所以一般训练都是LM任务,语言建模任务,用的文本语料(数亿规模token)。
常见的LM-语言建模任务
LM = language modeling,这是任务 不是语言模型哈。
这类任务的target?:
让模型学 语言的结构、语义、上下文关系。能预测词语或理解句子【理解会说】
有哪些具体任务?:
下面这些都是比较新的LM任务
- MLM (masked遮蔽的):随机遮蔽句子中的某些词,让模型预测被遮蔽的词——BERT
- CLM (causal因果的):根据前面的词预测下一个词——GPT
- SOP(sentence order prediction):判断两句话的顺序是否合理——ALBERT
- NSP(next sentence prediction):判断两句话是否是连续的——BERT
传统LM pre-train的缺陷?
只拟合从左到右单向的语义关系,忽略了双向的语义关系。
虽然Transformer中有用位置编码,但是和直接拟合双向还是有区别,如BiLSTM优于LSTM。
BERT的pre-train任务
- BERT的架构和Transformer大差不差
- 创新点在于pre-train任务(语言建模任务):
- MLM = 完形填空
- NSP
MLM
完形填空任务,token级别
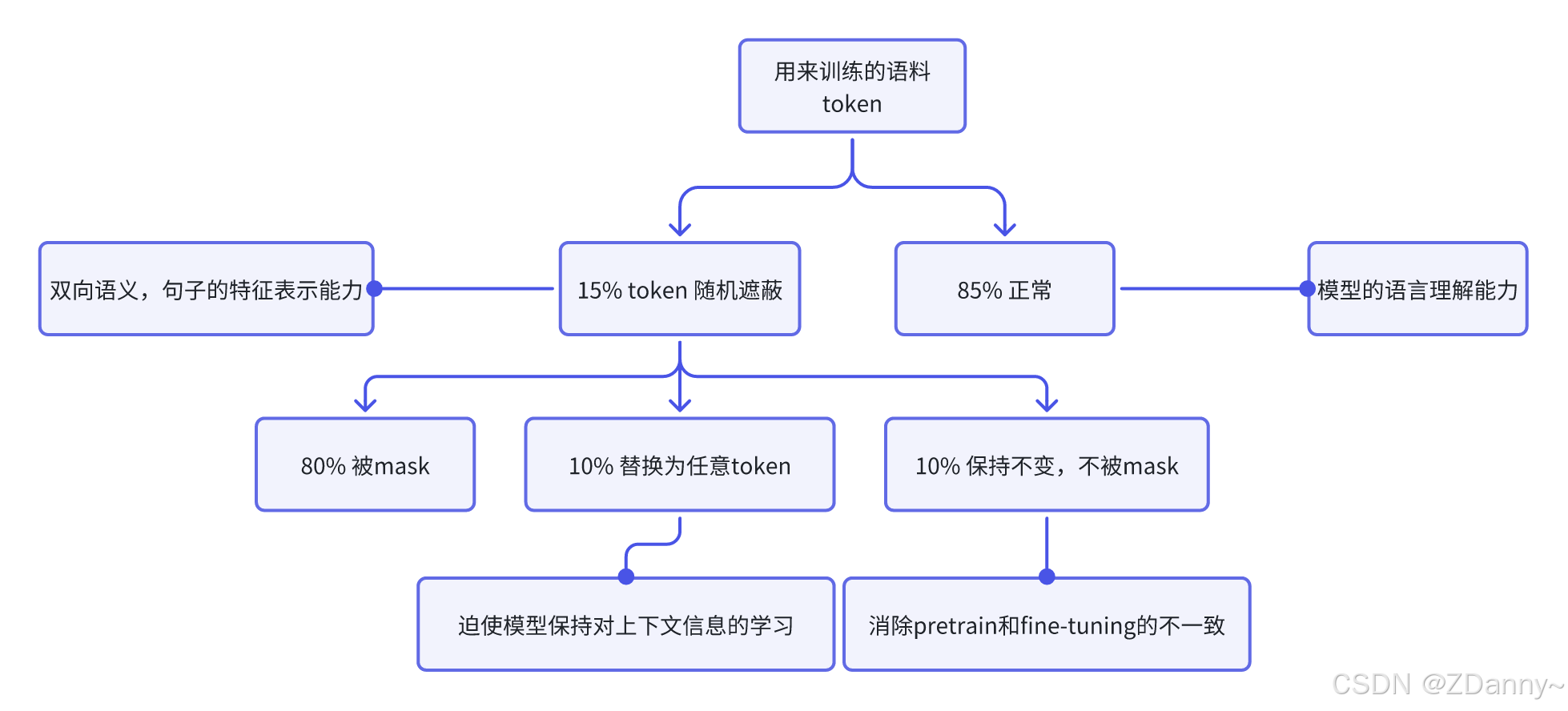
task:在一个文本序列中随机遮蔽部分 token,然后将所有未被遮蔽的 token 输入模型,要求模型根据输入预测被遮蔽的 token。
为什么MLM考虑到了双向语义和可用无监督数据?
- 掩码遮住token,模型就得从token的上文和下文一起预测masked token,从而拟合双向语义,实现更好的文本理解。
- 对文本语料随机遮蔽token就行
MLM pre-train的缺陷?
MLM虽然比LM关注了双向的语义,但是和下游任务不一致,会影响微调的性能。
下游任务(微调和推理):根据上文预测下文(LM的训练也是这样),不会有<mask>出现(MLM会出现),直接通过原文本得到对应的隐藏状态再根据下游任务进入分类器或其他组件。
改进MLM pre-train的策略
只遮蔽训练语料中15%的token,这些里面又只有80%概率被真的mask
NSP
句子级别
task:针对句级的 NLU 任务,句子级别拟合关系,判断两个句子之间的关系
为什么NSP可用无监督数据?
正样本直接随机抽句子文本,负样本随机打乱之后就可用了。
BERT的预训练语料与训练设置?
| 内容 | 详情 |
|---|---|
| 数据规模 | 3.3B Token(约 33 亿),约 13GB |
| 文本来源 | BooksCorpus:0.8B Token(约 8 亿,主要是小说) 英文 Wikipedia:2.5B Token(约 25 亿) |
| 上下文长度 | 90% 使用 128,10% 使用 512 |
| Batch Size | 256 个样本 |
| Step | 1M (1百万) |
| Epoch | 40个 |
NSP预训练时,(<CLS>特殊token 文本序列)代表句级的语义表征
MLM预训练时,用<CLS>特殊token对应的特征向量作为分类器的输入
BERT的版本?
| 版本 | Encoder 层数 | 隐藏层维度 | 参数量 | 训练资源 | 训练时长 |
|---|---|---|---|---|---|
| Base | 12 | 768 | 110M | 16 块 TPU | 约 4 天 |
| Large | 24 | 1024 | 340M | 64 块 TPU | 约 4 天 |
下游任务微调
怎么微调?
针对特定任务,用更少更精的数据,更小的batch size进行再训练,小幅调整更新参数。
一些下游任务
- 文本分类:直接改模型结构中的prediction_heads最后的分类头
- 序列标注:集成 BERT 多层的隐含层向量再输出最后的标注结果
- 文本生成:取 Encoder 的输出直接解码得到最终生成结果
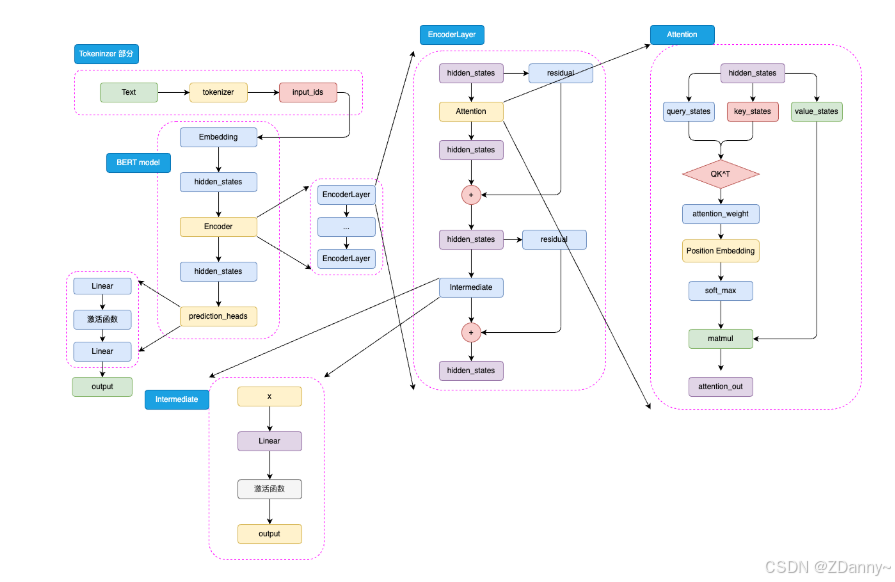
BERT架构
就是transformer的encoder堆叠。
tokenizer、Embedding、Encoder 、prediction_heads
tokenizer-WordPiece
| 特点 | 说明 |
|---|---|
| 分词方法 | 使用 WordPiece 作为分词器 |
| 核心思想 | 基于统计的子词切分算法,将单词拆分为子词 |
| 合并策略 | 按最大化语言模型的似然度来决定子词合并 |
| 英文处理 | 将单词切分为子词单位,例如 “playing” → [“play”, “##ing”] |
| 中文处理 | 由于没有空格分词,通常将单个汉字作为最小分词单位(token) 例如 “玩耍” → [“玩”, “耍”] |
Intermediate 层 = FNN
是 BERT 的特殊称呼,就是一个线性层加上激活函数
BERT的激活函数
GELU 函数,全名为高斯误差线性单元激活函数
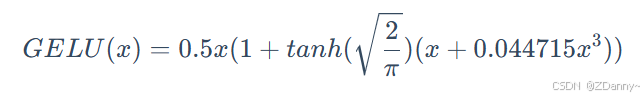
GELU 的核心思路为将随机正则的思想引入激活函数,通过输入
自身的概率分布,来决定抛弃还是保留自身的神经元。
BERT的位置编码和注意力计算
BERT 将相对位置编码融合在了注意力机制中,将相对位置编码同样视为可训练的权重参数。如图,BERT 的注意力计算过程和 Transformer 的唯一差异在于,在完成注意力分数的计算之后,先通过 Position Embedding 层来融入相对位置信息。这里的 Position Embedding 层,其实就是一层线性矩阵。通过可训练的参数来拟合相对位置,相对而言比 Transformer 使用的绝对位置编码 Sinusoidal 能够拟合更丰富的相对位置信息,但是,这样也增加了不少模型参数,同时完全无法处理超过模型训练长度的输入(例如,对 BERT 而言能处理的最大上下文长度是 512 个 token)。
可以看出,BERT 的模型架构既是建立在 Transformer 的 Encoder 之上的,这也是为什么说 BERT 沿承了 Transformer 的思想。
RoBERTa
模型架构不变,用的BERT-large
Facebook的,证明了更大的预训练数据、更大的预训练步长的重要意义
优化一:在预训练中去掉了 NSP,只使用 改进的 MLM 任务
- 动态遮蔽策略,让每一个 Epoch 的训练数据 Mask 的位置都不一致。(更高效、易于实现,后续 MLM 任务基本都使用了动态遮蔽)
- BERT用的静态,Mask 的操作在【数据处理阶段】完成,因此训练时同一个 sample 待预测的
<MASK>总是一致的。 - 由于 BERT 共训练了 40 个 Epoch,为使模型的训练数据更加广泛,BERT 将数据进行了四次随机 Mask,也就是每 10个 Epoch 模型训练的数据是完全一致的。
优化二 :更大规模的预训练数据和step
证明了大 batch size 的意义
| 项目 | 说明 |
|---|---|
| 数据规模 | 总计约 160GB,约为 BERT 的 10 倍 (13GB) |
| 数据来源 | - BookCorpus - 英文 Wikipedia - CC-NEWS(新闻) - OPENWEBTEXT(网页) - STORIES(故事风格) |
| 上下文长度 | 全部采用 512 长度训练 |
| 训练步数 | BERT:1M(40 Epoch) --> RoBERTa:0.5M=500K Step(约 66 个 Epoch) |
| 训练资源 | Meta 使用 1024 块 V100 GPU(32GB 显存),训练时长约 1 天 |
优化三:更大的BPE词表(tokenizer分词)
| 项目 | 说明 |
|---|---|
| 基本原理 | 字节对编码,以子词对作为分词单位 |
| 英文示例 | “Hello World” → [“Hel”, “lo”, “Wor”, “ld”] |
| 中文示例 | 按字节编码切分,如 “我”(UTF-8: E68891) → [“E68”, “891”] |
| 词表大小 | BERT:30K --> RoBERTa:50K |
| 词表大小影响 | 词表越大 → 编码能力更强 +但是 Embedding 参数量增加 |
| Embedding 作用 | Embedding 层就是把 token 从词典空间映射到隐藏空间 |
| Embedding 矩阵 | Embedding 矩阵形状 = (vocab_size, hidden_size),随词表变大会线性膨胀 |
ALBERT
减小模型参数,实现了超越 BERT 的能力。
优化模型结构,改进NSP预训练任务
优化一:将embedding参数进行分解
| 方面 | BERT | ALBERT (改进) |
|---|---|---|
| Embedding 参数公式 | V × H | V × E + E × H |
| 示例配置 | 词表大小 V=30K,隐藏层 H=1024 → 参数约 30M | V=30K,E=128,H=1024 → 参数显著下降 |
| 隐藏层扩展问题 | H 增加 → Embedding 参数线性膨胀(如 H=2048 → 61M) | E 固定较小,Embedding 参数不再随 H 扩张 |
| 设计思路 | Embedding 输出维度与隐藏层维度 绑定 | 通过引入线性变换矩阵 解绑 Embedding 与隐藏层维度 |
| 理论依据 | Word2Vec 经验:词向量维度无需过大(100维也有效) | Embedding 层可设较小维度,再升维至隐藏层大小 |
优化二:跨层进行参数共享
为什么要做 → 怎么做 → 效果 → 问题
| 方面 | 说明 |
|---|---|
| 原因 | 各个 Encoder 层的参数高度一致 + 24 层 Encoder 带来巨大的参数量 |
| 提出 | 通过让各个 Encoder 层 共享参数,减少模型总参数量 |
| 实现 | 仅初始化 1 个 Encoder 层,计算时重复使用 24 次 |
| 作用 | 极大程度地扩大隐藏层维度,使模型更“宽”但参数更少 |
| 实验结果 | BERT-Large:24 层,Hidden=1024,参数量约 334M ALBERT-xlarge:24 层,Hidden=2048,参数量仅 59M,效果优于 BERT |
| 问题 | 各层共享权重,参数量虽小,但训练效率提升微小 需重复 24 次计算,推理速度比 BERT 更慢 (这也是 ALBERT 最终没能取代 BERT 的一个重要原因。) |
优化三:提出SOP预训练任务
| 方面 | 说明 |
|---|---|
| 预训练的模型效果 | MLM + SOP > MLM > MLM + NSP |
| 改进动机 | NSP 难度太低,模型容易“投机取巧”,无法有效学习深层语义 |
| NSP 任务 | - 正例:两个连续句子组成的句对 - 负例:从任意两篇文档中抽取的句子对 ➡️ 较容易地判断正负例,并不能很好地学习深度语义 |
| SOP 任务 | - 正例:两个连续句子 - 负例:将这两个句子顺序对调 ➡️ 需要模型同时学习 句子关系 + 顺序关系 |