python黑盒包装
什么是黑盒封装:
黑盒:指外部用户不需要关心内部实现逻辑,只需要知道输入和输出。
封装:通过类、函数、接口等方式,把复杂实现隐藏在内部,对外提供统一的调用方式。
为什么要进行黑盒封装:
简化使用:降低外部调用的复杂度。
提高复用性:相同逻辑可以在多个项目中直接调用。
提高安全性:避免误操作内部实现逻辑。
方便维护:修改内部逻辑时不影响调用方。
扩展性好:可以在黑盒内部优化算法,而外部接口保持一致。
具体案例
1.创建新的文件夹下用于存放算法以及封装后的.pyd文件。
2.创建新的python文件命名为run_back.py。
3.将所需要的封装的算法复制到run_back.py文件下。
4.安装Nuitka
pip install nuitka
注意:确保Python环境下能够找到C编译器,分为两种系统windows系统下需要电脑有,如果没有的情况下需要自己安装;或者是直接运行命令系统自己安装。linux系统下是自带C编译器的无需安装。
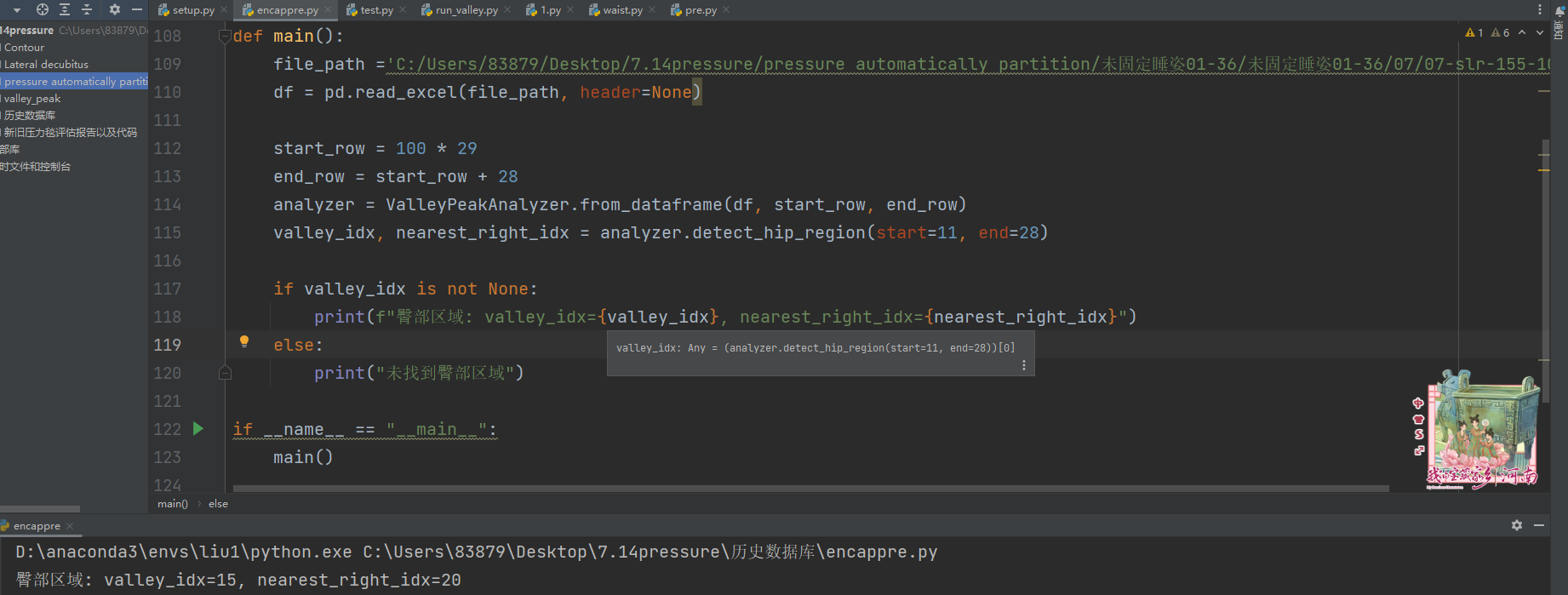
5.封装算法,形成黑盒
python -m nuitka --module run_valley.py --output-dir=.
--module会生成run_valley.cp39-win_amd64.pyd这个
.pyd文件就可以直接在任何 Python 项目中导入,无需源码:
6.显示效果:
为黑盒封装的效果:
黑盒封装的效果:
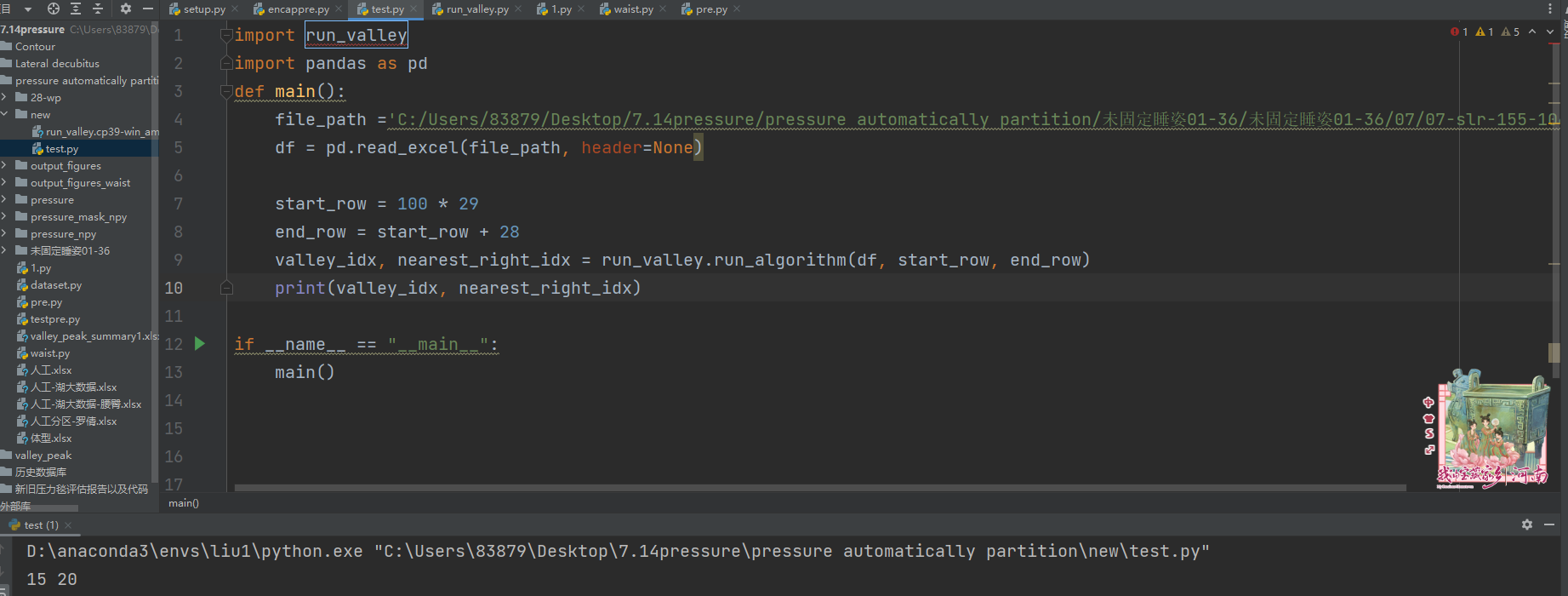
注意事项:
封装 Python 算法成独立黑盒(如用 Nuitka 或 Cython 编译成 .pyd/.so)后,需要注意以下几个方面,以确保稳定、可用并便于分发:
1️⃣ Python 版本和环境兼容性
编译
.pyd或.so文件与 Python 版本紧密绑定。例:
run_valley.cp39-win_amd64.pyd只能在 Python 3.9 Windows 64 位运行。
如果需要在不同版本 Python 使用,必须针对每个版本重新编译。
注意依赖库版本(如
pandas、numpy)与编译环境保持一致。
2️⃣ 依赖的第三方库
Nuitka / Cython 不会自动打包 Python 的动态依赖(如 pandas、numpy)。
外部环境必须 安装相应依赖。
可以在黑盒库文档里明确依赖版本,或者生成
requirements.txt。(安装pipreqs,且在项目根目录下运行pipreqs . --encoding=utf8 --force)
3️⃣ 数据输入输出
黑盒只暴露接口(如
run_algorithm(df, start_row, end_row))。确保 输入数据类型和格式严格:
DataFrame 行列大小、数据类型
缺失值处理
输出要标准化,最好统一返回元组、字典或 DataFrame,方便调用者使用。
4️⃣ 错误处理与异常
黑盒内部不要直接打印大量调试信息。
对非法输入、空数据、索引越界等情况 必须返回明确错误或 None。
可在接口里增加异常捕获,避免黑盒崩溃。
5️⃣ 性能和资源
编译成
.pyd后,Python 解释器调用时更快,但仍可能依赖 numpy/pandas,性能取决于这些库。大数据量时注意 内存占用和切片操作。
6️⃣ 安全与隐私
源码不可见,确保敏感算法逻辑不被泄露。
但仍需注意:
不在黑盒中硬编码敏感信息(如密码、文件路径)。
输入数据不要包含敏感信息,或做好加密处理。
7️⃣ 调试和维护
黑盒化后无法直接调试源代码,需要:
在编译前充分测试逻辑。
保留源码备份,便于迭代升级。
可以添加 日志接口 或 debug 模式,输出最小信息用于排查。
8️⃣ 分发方式
Windows
.pyd或 Linux.so文件可直接分发。可配合
pip install .或打包成 wheel,方便其他项目使用。如果跨平台,需要为每个平台编译不同版本。