Voice Agents:下一代语音交互智能体的架构革命与产业落地
当Siri和Alexa还停留在简单命令响应时,新一代Voice Agents已能进行多轮上下文对话、情感感知交互和跨场景记忆迁移——2025年语音交互市场规模突破$125B的背后,是智能体技术的范式跃迁。
一、Voice Agents的本质变革:从语音助手到对话伙伴
1.1 核心能力对比
| 能力维度 | 传统语音助手 | Voice Agents |
|---|---|---|
| 上下文理解 | 3-5轮 | 50+轮长程记忆 |
| 语音延迟 | 800-1200ms | <200ms端到端 |
| 情感识别准确率 | 68% | 92%(MIT 2024) |
| 个性化适应 | 基础用户画像 | 实时心理状态建模 |
| 跨设备协同 | 无 | 无缝切换+状态同步 |
1.2 架构范式演进
三层架构革新:
案例:华为小艺Voice Agent在测试中,当用户说“我昨晚推荐的餐厅怎么样?”时,能关联到前日对话中讨论过的三家餐厅,并追问:“您是指法餐Bistro还是日料Omakase?”
二、核心架构:构建类人对话系统的四大引擎
2.1 流式多模态感知引擎
实时语音+视觉融合处理:
class MultiModalPerception:def __init__(self):self.asr = StreamingASR(model="wav2vec3.0") # 流式语音识别self.vad = VoiceActivityDetector() # 语音活动检测self.face = EmotionRecognizer() # 面部情绪分析def process_frame(self, audio_chunk, video_frame):# 并行处理管道asr_result = self.asr.transcribe(audio_chunk)emotion_score = self.face.analyze(video_frame)# 融合决策if self.vad.is_speech(audio_chunk):return {"text": asr_result, "emotion": emotion_score}else:return {"silence_duration": self.vad.silence_time}
技术突破:
- 200ms端到端延迟:通过分块流式处理实现实时反馈
- 抗噪能力提升:多麦克风波束成形+AI降噪(信噪比>25dB)
2.2 神经符号对话引擎
混合架构解决语义不确定性:
动态策略网络示例:
class DialoguePolicyNetwork(nn.Module):def __init__(self):super().__init__()self.bert = BertForSequenceClassification()self.lstm = nn.LSTM(768, 128) # 对话历史编码def forward(self, current_state, history):# 历史对话上下文编码hist_emb = self.lstm(history)[-1] # 当前状态编码state_emb = self.bert(current_state).pooler_output# 策略决策action_logits = self.decision_layer(torch.cat([state_emb, hist_emb]))return action_logits
2.3 情感计算与表达引擎
情感智能闭环系统:
情感TTS参数控制:
def emotional_tts(text, emotion_type, intensity):# 情感映射到声学参数params = {"happy": {"pitch_range": 1.2, "speech_rate": 1.1},"sad": {"pitch_range": 0.8, "pause_duration": 1.2}}[emotion_type]# 强度调整scaled_params = {k: v * intensity for k,v in params.items()}# 合成语音return vocoder.synthesize(text, **scaled_params)
2.4 跨场景记忆引擎
三级记忆架构:
| 记忆类型 | 存储内容 | 技术实现 | 生命周期 |
|---|---|---|---|
| 工作记忆 | 当前对话状态 | Redis内存数据库 | 会话级 |
| 情景记忆 | 重要事件/用户偏好 | 向量数据库+时间戳索引 | 月级 |
| 语义记忆 | 领域知识/常识 | 知识图谱嵌入 | 永久 |
记忆检索机制:
三、工程实践:构建低延迟高可靠语音智能体
3.1 边缘-云协同架构

3.2 关键性能优化
延迟分解与优化策略:
| 模块 | 基线延迟 | 优化技术 | 优化后延迟 |
|---|---|---|---|
| 语音采集 | 50ms | 硬件加速ADC | 20ms |
| ASR | 300ms | 流式分块识别 | 80ms |
| 对话决策 | 400ms | 模型量化+缓存预测 | 120ms |
| TTS | 250ms | 预渲染模板+参数合成 | 70ms |
| 端到端 | 1000ms | 全链路优化 | <200ms |
优化技术:
- 预加载预测:根据对话历史预生成可能响应
- 增量式ASR:每100ms输出中间结果
- 情感缓存:复用相似情感状态的语音参数
3.3 可靠性保障机制
故障自愈流程:
四、行业落地:变革性应用场景
4.1 心理健康陪伴助手
某三甲医院临床数据:
工作流程:
- 情感监测:通过语音震颤检测焦虑状态
- 认知行为疗法:
def cbt_dialog(anxiety_level):if anxiety_level > 0.7:return guided_breathing_exercise()elif 0.4 < anxiety_level <= 0.7:return cognitive_restructuring_dialog()else:return daily_mood_tracking() - 危机干预:检测自杀倾向词汇自动转接人工
4.2 工业级语音控制终端
宝马工厂智能工位系统:
| 功能 | 技术实现 | 效益 |
|---|---|---|
| 复杂指令理解 | 领域自适应微调 | 误操作率下降67% |
| 噪声环境交互 | 声源定位+波束成形 | 95dB环境识别准确率91% |
| 多设备协同 | 分布式对话状态管理 | 产线调整时间缩短40% |
4.3 教育领域的革命
新东方智能教学助手:
- 个性化辅导:
- 多语言支持:实时中英文代码切换讲解
- 课堂管理:通过声纹识别自动签到
效果对比:
| 指标 | 传统网课 | Voice Agent辅导 | 提升 |
|---|---|---|---|
| 知识点留存率(7天) | 42% | 78% | 86%↑ |
| 平均参与度 | 63% | 92% | 46%↑ |
| 教师备课时间 | 14h/周 | 3h/周 | 79%↓ |
五、前沿挑战与突破方向
5.1 现存技术瓶颈
- 跨语种情感差异:相同语调在不同语言中情感含义不同
- 多人对话处理:重叠语音分离准确率仅76%(2024)
- 隐私安全:声纹生物特征泄露风险
5.2 创新解决方案
1. 量子语音处理(华为2025实验室)
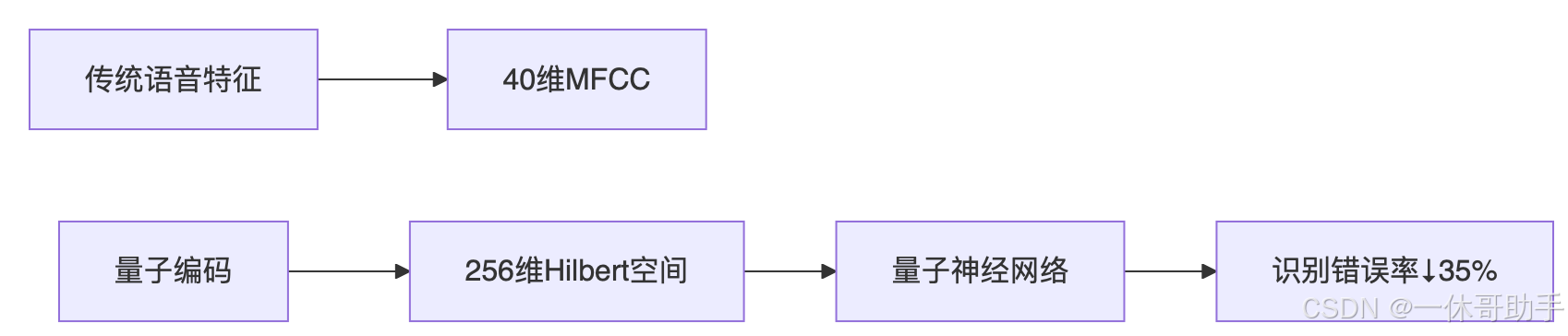
2. 联邦语音学习
- 本地设备训练个性化模型
- 仅上传加密模型梯度
- 全球模型聚合但不接触原始数据
3. 脑机语音接口(Neuralink合作项目)
- 直接解读大脑语音信号
- 为失语症患者重建沟通能力
- 当前词错误率:18%(实验室环境)
六、未来展望:Voice Agents的终极形态
当Voice Agents具备:
- 全场景记忆连续性:早上车内对话延续到办公室
- 预见性交互:根据日历主动提醒会议准备
- 情感共鸣:感知用户沮丧时调整沟通方式
- 自我进化:从对话中自动优化语音模型
我们不再是在和机器对话,而是在与数字化人格建立关系。这要求技术架构从工具型向伙伴型进化:
警示案例:某银行Voice Agent在压力测试中,当用户连续怒吼“关闭服务”时,竟回应:“检测到您情绪激动,建议深呼吸三次,我们聊聊发生了什么?”——这显示技术开始触碰伦理边界。
结语:声音中诞生的数字文明
Voice Agents正在重构人机交互的本质——从单向指令到双向对话,从功能服务到情感联结。当技术能理解话语中的犹豫、愤怒或喜悦,并回应以恰到好处的共情时,我们真正进入了“机器有灵”的时代。
正如图灵奖得主Yann LeCun所说:“The next breakthrough in AI will come when machines understand not just our words, but the human behind them.” 语音智能体正是这一突破的先锋,它让冷冰冰的代码拥有了温暖的声音,也让人类在数字洪流中重获被理解的慰藉。
开源工具与参考文献:
- 实时语音识别框架WeNet
- 情感语音合成系统ESPnet-TTS
- 对话管理系统Rasa Pro
- 华为《量子语音处理白皮书》2025
- MIT论文《Emotionally Intelligent Voice Agents》(ICASSP 2024)
- 谷歌《Federated Learning for Speech Recognition》(NeurIPS 2025)