Python网络爬虫(三) - 爬取动态网页数据
文章目录
- 一、动态网页及技术介绍
- 1. 动态网页介绍
- 2. Selenium 介绍
- 二、安装 Selenium
- 1. 安装 Selenium 库
- 2. 安装浏览器 WebDriver
- 2.1 Chrome 浏览器
- 2.2 Edge 浏览器
- 三、Selenium WebDriver
- 1. Selenium WebDriver 简介
- 2. Selenium WebDriver 基本操作
- 2.1 启动浏览器
- 2.2 关闭浏览器
- 2.3 打开网页
- 2.4 关闭当前网页
- 2.5 最大化窗口
- 2.6 最小化窗口
- 2.7 全屏模式
- 2.8 页面前进和后退
- 2.9 页面刷新
- 2.10 获取页面标题
- 2.11 获取当前页面URL
- 2.12 保存网页源码
- 2.13 截图
- 2.13.1 截取整个页面
- 2.13.2 截取特定元素
- 2.14 示例:Selenium WebDriver 基本操作
- 3. 元素查找
- 3.1 查找单个元素
- 3.2 查找多个元素
- 3.3 示例:查找元素
- 4. 元素操作
- 4.1 基础交互操作
- 4.2 输入框操作
- 4.3 键盘操作(结合 `Keys` 类)
- 4.4 下拉菜单操作(针对 `<select>` 标签)
- 4.5 表单操作(针对 `<form>` 标签)
- 4.6 示例:模仿百度搜索
- 4.7 滚动到元素位置
- 4.8 鼠标操作
- 4.9 等待机制
- 4.9.1 隐式等待 (Implicit Wait)
- 4.9.2 显式等待 (Explicit Wait)
- 4.9.3 手动等待 (Thread Sleep)
- 4.10 无头浏览器模式
- 4.10.1 配置Chrome为无头模式
- 4.10.2 配置Edge为无头模式
- 四、实战:爬取BOSS直聘java职位数据
一、动态网页及技术介绍
1. 动态网页介绍
动态网页是指页面内容可以根据用户交互、时间变化或数据更新而实时改变的网页。与静态网页(内容固定,由服务器一次性返回完整HTML)不同,动态网页的核心内容通常不是在初始HTML中完全呈现,而是通过客户端技术动态生成或加载。
2. Selenium 介绍
Selenium是一个自动化测试工具,最初用于Web应用程序的自动化测试,现在也被广泛应用于动态网页爬虫领域。它能够模拟真实用户在浏览器中的操作,如点击、输入、滚动等,并可以获取JavaScript渲染后的完整页面内容。
二、安装 Selenium
安装 Selenium 主要包括两个步骤:安装 Selenium 库和安装对应浏览器的 WebDriver 驱动程序。以下是详细的安装流程:
1. 安装 Selenium 库
Selenium 库可以通过 Python 的包管理工具 pip 快速安装,安装命令如下:
pip install selenium==4.15.2 -i https://mirrors.aliyun.com/pypi/simple/
安装完成后,可通过以下代码验证是否安装成功:
import selenium
print("Selenium 版本:", selenium.__version__) # 输出版本号即表示安装成功
2. 安装浏览器 WebDriver
Selenium 需要通过 WebDriver 驱动程序与浏览器进行通信,不同浏览器需要对应版本的 WebDriver。以下是主流浏览器的 WebDriver 安装方法:
2.1 Chrome 浏览器
-
查看 Chrome 版本:
- 打开 Chrome 浏览器 → 点击右上角三个点 → 帮助 → 关于 Google Chrome
- 记录版本号(如
130.0.6723.117)
-
下载对应版本的 ChromeDriver:
- 官方下载地址:Chrome for Testing
- 镜像地址(国内推荐):CNPM Binaries Mirror
- 选择与 Chrome 版本匹配的驱动(只需主版本号一致,如 Chrome 130.x 对应 ChromeDriver 130.x)
-
配置驱动:
- 将下载的
chromedriver-win64.zip解压到指定路径 - 代码中配置示例
from selenium import webdriver from selenium.webdriver.chrome.service import Servicedriver_path = r'D:\ProjectCode\untitled\chromedriver-win32\chromedriver-win32\chromedriver.exe'# 创建一个 Service 对象 service = Service(executable_path=driver_path)# 初始化 Chrome 浏览器 driver = webdriver.Chrome(service=service)
- 将下载的
2.2 Edge 浏览器
- 查看Edge浏览器版本:打开Edge浏览器,在地址栏输入“edge://version/”,按下回车键,即可查看当前Edge浏览器的版本号。
- 下载对应版本的Edge WebDriver:访问Microsoft官方的开发者网站https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/,在页面上找到并点击“Download WebDriver”按钮,在弹出的对话框中,选择适用于你的操作系统和Edge浏览器版本的WebDriver下载链接。
- 配置驱动:
将下载的 edgedriver_win64.zip 解压到指定路径,代码中配置示例:from selenium import webdriver from selenium.webdriver.edge.service import Serviceedge_driver_path = r"D:\ProjectCode\untitled\edgedriver_win64\msedgedriver.exe" service = Service(executable_path=edge_driver_path) driver = webdriver.Edge(service=service)
三、Selenium WebDriver
1. Selenium WebDriver 简介
Selenium WebDriver 是 Selenium 生态的核心组件,它提供了一套跨浏览器的编程接口,允许开发者通过代码控制浏览器的行为。与传统的 Selenium RC(Remote Control)相比,WebDriver 采用了更贴近浏览器原生支持的方式工作,直接与浏览器内核交互,执行效率更高,支持的浏览器功能更全面。
WebDriver 是动态网页爬虫的重要工具,通过模拟真实用户的浏览器行为,能够解决传统爬虫无法处理的 JavaScript 渲染、动态加载等问题。
2. Selenium WebDriver 基本操作
2.1 启动浏览器
启动浏览器是使用 WebDriver 的第一步,不同浏览器对应不同的 WebDriver 类,通过初始化这些类可以启动相应的浏览器实例。
基本语法:
from selenium import webdriver# 启动Chrome浏览器
driver = webdriver.Chrome(executable_path, options, service, keep_alive)# 启动Edge浏览器
driver = webdriver.Edge(executable_path, options, service, keep_alive)
参数说明:
| 参数名 | 类型 | 作用描述 | 示例值 |
|---|---|---|---|
executable_path | 字符串 | 指定 WebDriver 驱动程序的路径(若已添加到系统 PATH 可省略)。 | "C:/drivers/chromedriver.exe" |
options | 浏览器选项对象 | 配置浏览器启动参数(如无头模式、窗口大小、用户配置等)。 | options=webdriver.ChromeOptions() |
service | 服务对象 | 配置驱动服务的参数(如日志级别、端口号等)。 | service=webdriver.ChromeService(log_path="driver.log") |
keep_alive | 布尔值 | 是否保持驱动程序与浏览器的长连接(默认 True,关闭可解决部分连接问题)。 | keep_alive=False |
2.2 关闭浏览器
关闭浏览器是结束WebDriver会话的操作,会终止浏览器进程和驱动程序,释放资源。
方法:driver.quit()
2.3 打开网页
通过URL导航到目标网页,是WebDriver的基础操作。
方法:driver.get(url)
参数:
url(字符串):目标网页的URL(需包含协议,如https://)。
2.4 关闭当前网页
关闭当前聚焦的标签页,不影响其他标签页(若为最后一个标签页,浏览器可能自动关闭)。
方法:driver.close()
2.5 最大化窗口
将浏览器窗口最大化,模拟用户全屏操作,确保元素在可视区域内。
方法:driver.maximize_window()
2.6 最小化窗口
将浏览器窗口最小化到任务栏。
方法:driver.minimize_window()
2.7 全屏模式
使浏览器进入全屏模式(类似按F11,无地址栏和工具栏)。
方法:driver.fullscreen_window()
2.8 页面前进和后退
模拟浏览器的“前进”和“后退”按钮,在浏览历史中导航。
- 后退:
driver.back() - 前进:
driver.forward()
2.9 页面刷新
重新加载当前网页,用于刷新动态内容或恢复页面状态。
方法:driver.refresh()
2.10 获取页面标题
获取当前网页的标题(对应HTML中的<title>标签内容)。
属性:driver.title
2.11 获取当前页面URL
获取浏览器地址栏中显示的当前网页URL。
属性:driver.current_url
2.12 保存网页源码
获取当前页面渲染完成后的完整HTML源码并保存到本地文件,适用于动态网页的JavaScript渲染结果。
属性:driver.page_source
2.13 截图
2.13.1 截取整个页面
对当前浏览器窗口进行截图,用于保存页面状态、验证操作结果或捕获验证码等场景。
方法:driver.save_screenshot(file_path)
参数:
file_path(字符串):截图保存路径(需包含文件名和扩展名,如screenshot.png)。
2.13.2 截取特定元素
对指定元素进行截图。
方法:element.screenshot(file_path)
参数:
file_path(字符串):截图保存路径(需包含文件名和扩展名,如screenshot.png)。
2.14 示例:Selenium WebDriver 基本操作
import timefrom selenium import webdriver
from selenium.webdriver.edge.service import Service# 启动浏览器
edge_driver_path = r"D:\ProjectCode\untitled\edgedriver_win64\msedgedriver.exe"
service = Service(executable_path=edge_driver_path)
driver = webdriver.Edge(service=service)
# 打开百度
driver.get("https://www.baidu.com")
# 打开boss直聘
driver.get("https://www.zhipin.com")
time.sleep(2)
# 后退到百度
driver.back()
time.sleep(2)
# 前进到boss直聘
driver.forward()
time.sleep(2)
# 刷新网页
driver.refresh()
time.sleep(2)
# 获取当前页面的URL
current_url = driver.current_url
print("当前页面的URL:", current_url)
# 获取当前页面的标题
current_title = driver.title
print("当前页面的标题:", current_title)
# 获取当前页面的HTML
current_html = driver.page_source
print("当前页面的HTML:", current_html)
# 最大化窗口
driver.maximize_window()
time.sleep(2)
# 截取整个页面
driver.save_screenshot("screenshot.png")
# 关闭当前页面
driver.close()
time.sleep(2)
# 关闭浏览器
driver.quit()
3. 元素查找
在 Selenium 中,元素查找是与网页交互的基础,通过定位标签(元素)可以实现点击、输入、提取文本等操作。WebDriver 提供了 find_element()(查找单个元素)和 find_elements()(查找多个元素)两种核心方法,支持多种定位策略。
3.1 查找单个元素
find_element() 方法用于在页面中查找第一个符合条件的元素,返回一个元素对象(若未找到则抛出 NoSuchElementException 异常)。
基本语法:
element = driver.find_element(by=定位策略, value=定位值)
参数说明:
| 参数名 | 类型 | 作用描述 | 示例值 |
|---|---|---|---|
by | 字符串/枚举 | 指定元素定位策略,推荐使用 By 类的枚举常量(如 By.ID、By.CSS_SELECTOR)。 | By.ID、By.CLASS_NAME、By.XPATH |
value | 字符串 | 定位值,与定位策略对应(如ID值、类名、XPath表达式等)。 | "kw"(ID值)、"s_ipt"(类名)、"//input"(XPath) |
常用定位策略(by的取值):
| 定位策略 | 说明 | 示例代码(查找百度搜索框) |
|---|---|---|
By.ID | 通过元素的 id 属性定位(ID通常唯一,定位效率最高)。 | driver.find_element(By.ID, "kw") |
By.NAME | 通过元素的 name 属性定位。 | driver.find_element(By.NAME, "wd") |
By.CLASS_NAME | 通过元素的 class 属性定位(class可能重复,需注意唯一性)。 | driver.find_element(By.CLASS_NAME, "s_ipt") |
By.TAG_NAME | 通过HTML标签名定位(如 input、div,适合批量元素的首个)。 | driver.find_element(By.TAG_NAME, "input") |
By.LINK_TEXT | 通过链接的完整文本定位(精确匹配 <a> 标签的文本内容)。 | driver.find_element(By.LINK_TEXT, "新闻") |
By.PARTIAL_LINK_TEXT | 通过链接的部分文本定位(模糊匹配 <a> 标签的文本)。 | driver.find_element(By.PARTIAL_LINK_TEXT, "新") |
By.CSS_SELECTOR | 通过CSS选择器定位(支持类、ID、属性、层级等复杂规则)。 | driver.find_element(By.CSS_SELECTOR, "#kw") |
By.XPATH | 通过XPath表达式定位(支持复杂层级和条件筛选,兼容性强)。 | driver.find_element(By.XPATH, "//input[@id='kw']") |
3.2 查找多个元素
find_elements() 方法用于在页面中查找所有符合条件的元素,返回一个包含所有元素对象的列表(若未找到则返回空列表)。
基本语法:
elements = driver.find_elements(by=定位策略, value=定位值)
参数说明:
与 find_element() 完全一致,区别在于返回结果为列表:
| 参数名 | 类型 | 作用描述 | 示例值 |
|---|---|---|---|
by | 字符串/枚举 | 同 find_element(),指定定位策略。 | By.TAG_NAME、By.CLASS_NAME |
value | 字符串 | 同 find_element(),指定定位值。 | "a"(标签名)、"mnav"(类名) |
常用定位策略(by的取值):
与 find_element() 完全一致。
3.3 示例:查找元素
import timefrom selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.service import Service# 启动浏览器
edge_driver_path = r"D:\ProjectCode\untitled\edgedriver_win64\msedgedriver.exe"
service = Service(executable_path=edge_driver_path)
driver = webdriver.Edge(service=service)# 打开boss直聘
driver.get("https://www.baidu.com/")
time.sleep(2)# 定位“百度一下”按钮
element = driver.find_element(By.ID, 'chat-submit-button')# 定位输入框
element = driver.find_element(By.CLASS_NAME, 'chat-input-textarea')# 通过CSS选择器查找“百度一下”按钮
element = driver.find_element(By.CSS_SELECTOR, '#chat-submit-button')# 关闭浏览器
driver.quit()
4. 元素操作
4.1 基础交互操作
针对各类元素的基础交互,如点击、获取信息等,是最常用的操作类型。
| 操作目的 | 方法/属性 | 说明 | 适用元素 |
|---|---|---|---|
| 点击元素 | element.click() | 模拟用户单击元素(左键),触发元素默认行为(如提交、跳转)。 | 按钮、链接、复选框、单选框等 |
| 获取可见文本 | element.text | 返回元素标签内的可见文本(不含HTML标签)。 | 所有包含文本的元素(div、a、span等) |
| 获取属性值 | element.get_attribute(name) | 返回元素指定属性的值(如href、src、class等)。 | 所有带属性的元素 |
| 判断元素状态 | element.is_displayed() | 判断元素是否在页面中可见(布尔值)。 | 所有元素 |
element.is_enabled() | 判断元素是否启用(如输入框是否可编辑、按钮是否可点击)。 | 输入框、按钮、下拉框等 | |
element.is_selected() | 判断复选框/单选框是否被选中(布尔值)。 | 复选框(input[type=“checkbox”])、单选框(input[type=“radio”]) |
4.2 输入框操作
专门用于文本输入类元素的操作,模拟用户输入、修改内容。
| 操作目的 | 方法 | 说明 |
|---|---|---|
| 输入文本 | element.send_keys(*value) | 向输入框中输入文本,支持字符串或特殊按键(如回车、Tab)。 |
| 清空内容 | element.clear() | 清除输入框中已有的文本内容,常用于重新输入前重置。 |
| 提交输入内容 | element.submit() | 提交当前输入框所在的表单(等价于点击表单的提交按钮,仅适用于表单内元素)。 |
4.3 键盘操作(结合 Keys 类)
模拟键盘按键及组合键,扩展输入操作的灵活性。
| 操作目的 | 方法示例 | 说明 |
|---|---|---|
| 特殊按键输入 | send_keys(Keys.ENTER) | 输入回车键(常用于提交搜索、表单)。 |
send_keys(Keys.TAB) | 输入Tab键(切换焦点)。 | |
| 组合键操作 | send_keys(Keys.CONTROL, "a") | 按下Ctrl+A(全选内容)。 |
send_keys(Keys.SHIFT, "abc") | 按下Shift+字母(输入大写字母)。 |
| 特殊键描述 | Keys 类常量 |
|---|---|
| 回车键(Enter) | Keys.RETURN 或 Keys.ENTER |
| Tab 键 | Keys.TAB |
| Esc 键 | Keys.ESCAPE |
| 空格键 | Keys.SPACE |
| 向上方向键 | Keys.ARROW_UP 或 Keys.UP |
| 向下方向键 | Keys.ARROW_DOWN 或 Keys.DOWN |
| 向左方向键 | Keys.ARROW_LEFT 或 Keys.LEFT |
| 向右方向键 | Keys.ARROW_RIGHT 或 Keys.RIGHT |
| 删除键(Delete) | Keys.DELETE |
| 退格键(Backspace) | Keys.BACK_SPACE |
| 插入键(Insert) | Keys.INSERT |
| Home 键 | Keys.HOME |
| End 键 | Keys.END |
| Page Up 键 | Keys.PAGE_UP |
| Page Down 键 | Keys.PAGE_DOWN |
| F1 至 F12 功能键 | Keys.F1 至 Keys.F12 |
| Ctrl 键 | Keys.CONTROL |
| Shift 键 | Keys.SHIFT |
| Alt 键 | Keys.ALT |
4.4 下拉菜单操作(针对 <select> 标签)
通过 Select 类简化下拉菜单(单选/多选)的选择操作。
| 操作目的 | 方法 | 说明 |
|---|---|---|
| 按索引选择 | select_by_index(index) | 根据选项索引选择(索引从0开始,适用于固定顺序的下拉框)。 |
| 按属性值选择 | select_by_value(value) | 根据选项的 value 属性值选择(精准匹配属性值)。 |
| 按文本选择 | select_by_visible_text(text) | 根据选项的可见文本选择(匹配显示在页面上的文本)。 |
| 取消选择(多选) | deselect_all() | 取消所有已选中的选项(仅适用于 multiple="multiple" 的多选下拉框)。 |
| 取消单个选择 | deselect_by_index(index) | 取消指定索引的选项(多选下拉框专用)。 |
4.5 表单操作(针对 <form> 标签)
专门用于表单的整体提交或重置。
| 操作目的 | 方法 | 说明 |
|---|---|---|
| 提交表单 | form_element.submit() | 提交整个表单(等价于点击表单内的提交按钮,无需单独定位按钮)。 |
| 重置表单 | form_element.reset() | 重置表单内所有输入项为默认值(等价于点击重置按钮)。 |
4.6 示例:模仿百度搜索
import timefrom selenium import webdriver
from selenium.webdriver import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.service import Service# 启动浏览器
edge_driver_path = r"D:\ProjectCode\untitled\edgedriver_win64\msedgedriver.exe"
service = Service(executable_path=edge_driver_path)
driver = webdriver.Edge(service=service)# 打开boss直聘
driver.get("https://www.baidu.com/")
time.sleep(2)# 定位输入框
element1 = driver.find_element(By.CLASS_NAME, 'chat-input-textarea')# 通过CSS选择器查找“百度一下”按钮
element2 = driver.find_element(By.CSS_SELECTOR, '#chat-submit-button')# 打印 element1 元素的 'placeholder' 属性值
print(element1.get_attribute('placeholder'))# 打印 element2 元素的可见文本内容(text)
print(element2.text)# 向 element1 输入框中输入文本:“风景图片”
element1.send_keys('风景图片')# 模拟按下“回车键”(Enter),常用于提交搜索或表单
element1.send_keys(Keys.ENTER)# 点击 element2 元素
# element2.click()# 清空 element1 输入框中的所有已输入内容
element1.clear()# 关闭浏览器
driver.quit()
4.7 滚动到元素位置
有时需要滚动页面直到某个元素进入视图中,这可以通过JavaScript执行来完成。
driver.execute_script("arguments[0].scrollIntoView(true);", element)
4.8 鼠标操作
在Selenium中,鼠标操作是通过ActionChains类来实现的。这个类提供了一系列的方法来模拟各种鼠标操作,如点击、双击、右击、拖拽等。
以下是一些常见的鼠标操作及其使用方法:
-
导入ActionChains
在执行任何鼠标操作之前,首先需要从selenium.webdriver.common.action_chains模块中导入ActionChains类。from selenium.webdriver.common.action_chains import ActionChains -
初始化ActionChains对象
创建一个ActionChains对象,该对象需要传入一个浏览器驱动实例。actions = ActionChains(driver) -
常用鼠标操作
-
点击(Click): 点击一个元素。
element = driver.find_element(By.ID, "element_id") actions.click(element).perform() -
右键点击(Context Click): 在某个元素上执行右键点击。
element = driver.find_element(By.ID, "element_id") actions.context_click(element).perform() -
双击(Double Click): 双击一个元素。
element = driver.find_element(By.ID, "element_id") actions.double_click(element).perform() -
悬停(Move to Element): 将鼠标移动到某个元素上。
element = driver.find_element(By.ID, "element_id") actions.move_to_element(element).perform() -
拖放(Drag and Drop): 从一个位置拖动元素并释放到另一个位置。
source_element = driver.find_element(By.ID, "source_id") target_element = driver.find_element(By.ID, "target_id") actions.drag_and_drop(source_element, target_element).perform()
-
-
执行动作
所有的动作链都需要通过调用.perform()方法来执行。这意味着你可以先定义一系列的动作,然后一次性执行它们。 -
链式调用
ActionChains支持链式调用,即可以连续调用多个方法,最后通过.perform()来执行所有动作。actions.move_to_element(element).click().double_click().context_click().perform()
4.9 等待机制
在使用Selenium进行Web自动化测试时,等待机制是确保脚本稳定性和可靠性的关键因素之一。由于页面加载和元素渲染的时间可能不同,直接操作未完全加载的元素会导致错误。Selenium提供了两种主要的等待机制:隐式等待和显式等待。
4.9.1 隐式等待 (Implicit Wait)
隐式等待是对整个WebDriver会话设置的一个全局等待时间。如果在指定时间内网页没有加载完成或特定元素尚未出现,WebDriver将继续轮询DOM,直到元素变得可用或超时。
-
如何使用:
from selenium import webdriverdriver = webdriver.Chrome() # 或其他WebDriver实例 # 设置隐式等待时间为10秒 driver.implicitly_wait(10) # 参数为等待的秒数 -
优点: 简单易用,只需设置一次即可应用于所有查找元素的操作。
-
缺点: 如果页面上的某些元素比设定的时间更早出现,仍需等待至设定的最大时间,可能导致不必要的延迟。
4.9.2 显式等待 (Explicit Wait)
显式等待允许针对特定条件进行等待,只有当该条件满足时才会继续执行后续代码,或者在超过最大等待时间后抛出异常。这种方式更加灵活且高效。
-
常用方法:
WebDriverWait: 结合ExpectedConditions用于检查特定条件是否成立。
-
示例代码:
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as ECdriver = webdriver.Chrome() # 或其他WebDriver实例driver.get("http://example.com") try:# 使用WebDriverWait等待最多10秒,直到找到ID为'element_id'的元素element = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, "element_id"))) finally:driver.quit()
ExpectedConditions
在Selenium中,EC(expected_conditions,预期条件)模块封装了网页自动化测试中常用的方法,用于判断页面元素或页面状态是否满足特定条件,以下是一些常用方法介绍:
- 标题判断类:
title_is:用于判断当前页面的title是否完全等于预期字符串,返回布尔值。例如判断当前页面标题是否为“百度一下,你就知道”。title_contains:判断当前页面的title是否包含预期字符串,返回布尔值。
- 元素存在判断类:
presence_of_element_located:判断某个元素是否被加到了DOM树里,不代表该元素一定可见。使用时需传入元素定位元组,如(By.ID, ‘element_id’)。presence_of_all_elements_located:判断是否至少有1个元素存在于DOM树中。例如判断页面上class为’column-md-3’的元素是否至少有一个存在。
- 元素可见性判断类:
visibility_of_element_located:判断某个元素是否可见,可见代表元素非隐藏,并且元素的宽和高都不等于0 ,需传入元素定位元组。visibility_of:与visibility_of_element_located功能相同,只是直接传入定位到的element对象。invisibility_of_element_located:判断某个元素是否不存在于DOM树或不可见。
- 元素文本判断类:
text_to_be_present_in_element:判断某个元素中的text是否包含了预期的字符串。text_to_be_present_in_element_value:判断某个元素中的value属性是否包含了预期的字符串。
- frame操作类:
frame_to_be_available_and_switch_to_it:判断该frame是否可以切换进去,如果可以,返回True并且切换进去,否则返回False。
- 元素可操作判断类:
element_to_be_clickable:判断某个元素是否可见并且是enabled的,即可点击状态。staleness_of:等待某个元素从DOM树中移除,返回True或False。
- 元素选中状态判断类:
element_to_be_selected:判断某个元素是否被选中,一般用于下拉列表等。element_selection_state_to_be:判断某个元素的选中状态是否符合预期,需传入定位到的element对象。element_located_to_be_selected:判断特定元素是否存在于DOM树并被选中,传入元素定位元组。element_located_selection_state_to_be:与element_selection_state_to_be作用相同,只是传入元素定位元组。
- 弹窗判断类:
alert_is_present:判断页面上是否存在alert弹窗。
4.9.3 手动等待 (Thread Sleep)
虽然可以使用Python的time.sleep()方法来实现简单的线程休眠作为等待手段,但这通常不是最佳实践,因为它会造成固定的等待时间,无论实际需要与否,可能会增加不必要的测试运行时间。
-
不推荐的方式:
import timetime.sleep(5) # 强制等待5秒
4.10 无头浏览器模式
无头浏览器模式允许你在没有图形用户界面(GUI)的情况下运行浏览器。这对于在服务器环境中执行自动化测试、持续集成(CI)管道中使用Selenium非常有用,因为它不需要显示输出,可以节省资源并提高性能。以下是如何配置不同浏览器以无头模式运行的方法。
4.10.1 配置Chrome为无头模式
对于Chrome浏览器,通过设置--headless选项来启用无头模式。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options# 初始化Chrome选项
chrome_options = Options()# 添加无头模式参数
chrome_options.add_argument("--headless")# 如果需要,还可以添加其他常用参数
chrome_options.add_argument("--disable-gpu") # 适用于Windows系统的额外参数
chrome_options.add_argument("window-size=1920,1080") # 设置窗口大小# 使用配置好的选项启动Chrome WebDriver
driver = webdriver.Chrome(options=chrome_options)# 打开网页
driver.get('http://www.example.com')# 输出页面标题,验证是否正确加载
print(driver.title)# 关闭WebDriver
driver.quit()
4.10.2 配置Edge为无头模式
对于新版基于Chromium的Microsoft Edge浏览器,可以通过设置--headless选项来启用无头模式。需要注意的是,由于Edge也是基于Chromium内核,因此它的配置方式与Chrome非常相似。
from selenium import webdriver
from selenium.webdriver.edge.options import Options# 初始化Edge选项
edge_options = Options()# 添加无头模式参数
edge_options.add_argument("--headless")# 如果需要,还可以添加其他常用参数
edge_options.add_argument("--disable-gpu") # 适用于某些系统的额外参数
edge_options.add_argument("window-size=1920,1080") # 设置窗口大小# 使用配置好的选项启动Edge WebDriver
driver = webdriver.Edge(options=edge_options)# 打开网页
driver.get('http://www.example.com')# 输出页面标题,验证是否正确加载
print(driver.title)# 关闭WebDriver
driver.quit()
四、实战:爬取BOSS直聘java职位数据
代码如下所示:
import time
from pathlib import Pathimport pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.service import Service
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait# 配置 Edge 浏览器的启动选项
options = webdriver.EdgeOptions()# 禁用 Blink 渲染引擎的自动化控制特征
# 作用:隐藏“Chrome 正受到自动化测试工具控制”的提示,减少被网站检测的风险
options.add_argument("--disable-blink-features=AutomationControlled")# 禁用所有浏览器扩展(插件)
options.add_argument("--disable-extensions")# 禁用 GPU 硬件加速
# 原因:在无头模式或服务器环境中,GPU 可能不可用,禁用后可提高稳定性
# options.add_argument("--disable-gpu")# 禁用沙盒模式(sandbox)
# 说明:沙盒是浏览器的安全机制,但在某些 Linux 服务器或 Docker 中需要关闭才能运行
# options.add_argument("--no-sandbox")# 开启远程调试端口,端口号为 9222
# 用于调试浏览器行为(如通过 Chrome DevTools 远程查看页面)
# options.add_argument("--remote-debugging-port=9222")# 启用无头模式(headless)
# 浏览器在后台运行,不显示图形界面,适合服务器或自动化任务
# 注意:无头模式更容易被检测,建议配合其他反检测手段使用
# options.add_argument("--headless")# 禁用自动化扩展(如 WebDriver 标志)
# 防止浏览器暴露自动化特征
options.add_experimental_option("useAutomationExtension", False)# 移除“启用自动化”提示栏(即隐藏“Chrome 正在受到自动软件控制”的黄色警告条)
options.add_experimental_option("excludeSwitches", ["enable-automation"])# 指定 Edge 浏览器驱动程序(msedgedriver.exe)的本地路径
edge_driver_path = r"D:\ProjectCode\untitled\edgedriver_win64\msedgedriver.exe"# 创建 Service 对象,用于管理浏览器驱动进程
service = Service(executable_path=edge_driver_path)# 启动 Edge 浏览器实例,传入服务和配置选项
driver = webdriver.Edge(service=service, options=options)# 在每个新页面加载前注入 JavaScript 脚本
# 作用:覆盖 navigator.webdriver 属性,防止网站通过 JS 检测自动化
# 原理:正常用户浏览器中 navigator.webdriver 为 undefined 或 false,而 Selenium 默认为 true
# 这里将其强行定义为始终返回 false,伪装成正常用户
# driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
# "source": """
# Object.defineProperty(navigator, 'webdriver', {
# get: () => false
# });
# """
# })time.sleep(2)# 打开目标网页:BOSS直聘 杭州地区 Java 岗位列表,第1页
driver.get("https://www.zhipin.com/web/geek/jobs?query=&city=101290100&position=100101")# 暂停 2 秒,等待页面加载完成(简单等待,实际项目建议使用 WebDriverWait 显式等待)
time.sleep(2)# div_element_list = driver.find_elements(By.CSS_SELECTOR, ".job-list-container > .rec-job-list > .card-area")data = []try:div_element_list = WebDriverWait(driver, 60).until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, ".job-list-container > .rec-job-list > .card-area")))for div_element in div_element_list:a_element = div_element.find_element(By.CSS_SELECTOR, '.job-name')href = a_element.get_attribute("href")name = a_element.textexperience_education = div_element.find_elements(By.CSS_SELECTOR, '.tag-list > li')experience = experience_education[0].texteducation = experience_education[1].textcompany_name = div_element.find_element(By.CSS_SELECTOR, '.boss-name')company_name = company_name.textcompany_location = div_element.find_element(By.CSS_SELECTOR, '.company-location')company_location = company_location.textprint(href, name, experience, education, company_name, company_location)# time.sleep(random.uniform(1, 3))# 保存数据到csv文件data.append({'href': href,'name': name,'experience': experience,'education': education,'company_name': company_name,'company_location': company_location})# 转换为 DataFramedata_df = pd.DataFrame(data)# 创建保存目录(如果不存在)Path('./data').mkdir(parents=True, exist_ok=True)# 保存为 CSV 文件data_df.to_csv('./data/data.csv', index=False, encoding='utf-8-sig')print(f"图书数据已保存到:'./data/data.csv'")finally:print("等待元素出现超时")driver.quit()
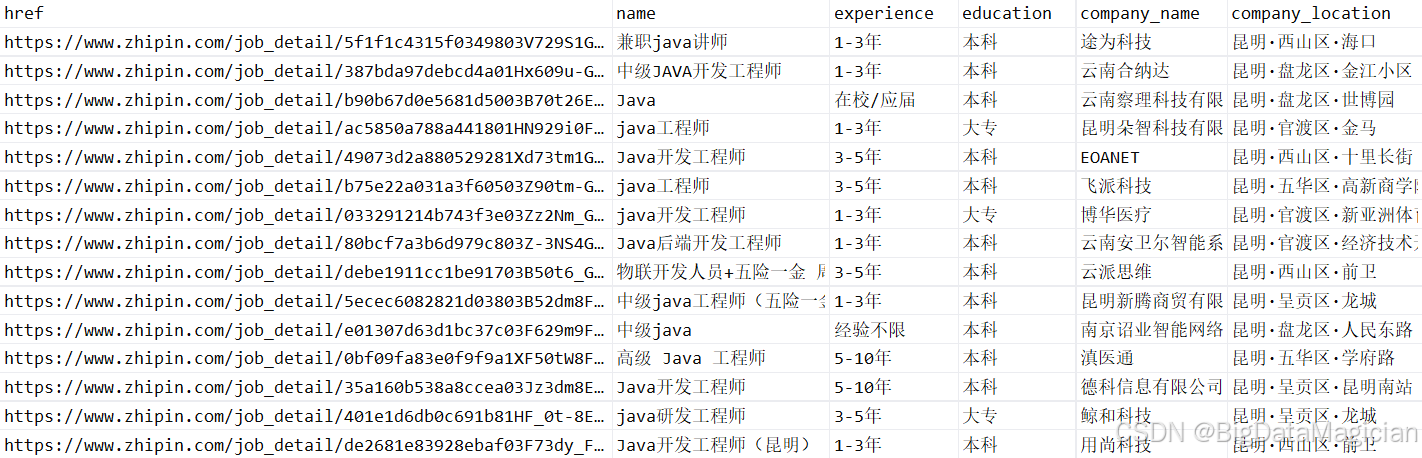
保存后的数据如下图所示: