数据转换细节揭秘:ETL如何精准映射复杂业务逻辑
为什么企业的数据集成项目总是掉链子?
一家大型零售集团在核心系统改造时,CRM、ERP 和电商平台都需要统一客户数据。可上线当天,订单状态却对不上号,导致促销规则混乱,用户投诉如潮。
这件事的问题到底出在哪里?难道是数据量太大导致统计错误了吗?错,问题并不在数据量,而是数据转换逻辑没对齐,ETL流程映射出了偏差。
什么是“精准映射”,为什么这么关键?
精准映射指的是在数据抽取和加载过程中,保持业务语义与字段含义完全一致。
如果精准映射没有实现,将会导致一个怎样的局面?举个常见的例子:
源系统:订单状态“C”表示已取消
目标系统:同一字段却用“99”表示已取消
这就是典型的因为转换逻辑没定义清楚,而导致的报表判断失误。报表会把“已取消”当“待发货”,业务决策立刻跑偏。
如何让ETL映射逻辑更可靠?
第一步:先统一业务数据标准
没有标准就谈不上转换。
-
建立一份 业务数据字典:包括字段定义、取值范围、单位和精度。
-
用 数据血缘(Data Lineage)工具跟踪字段流向,确保从源头到目标一清二楚。
-
实用做法:
1.把所有源系统字段拉出来,做个对照表。
2.用 JSON Schema 或 Avro 格式描述字段属性。
3.把映射关系的校验加进 CI/CD 流程,避免上线后才发现问题。
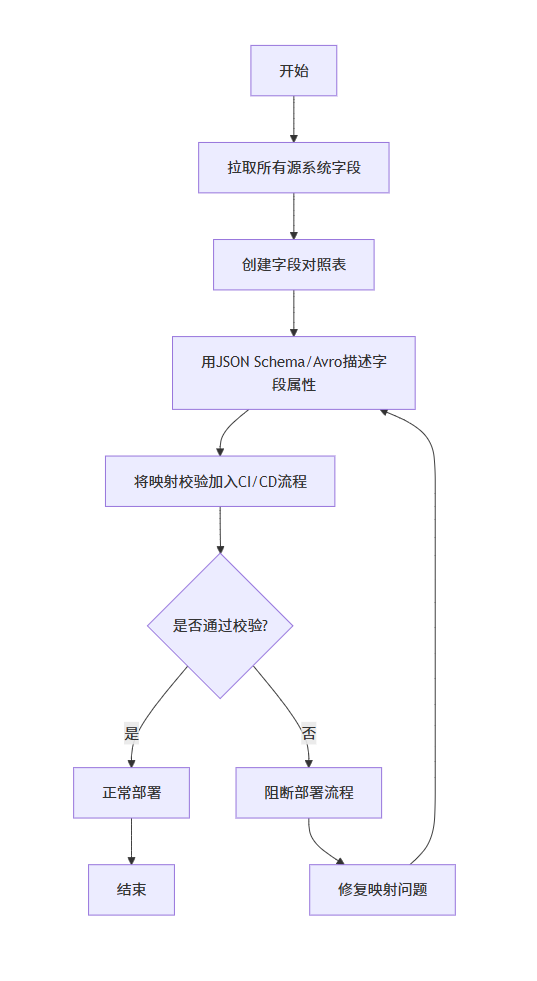
第二步:让ETL逻辑可回溯、可回滚
复杂转换一定要能追踪历史版本。
-
每次改动ETL逻辑,保留旧版本和变更记录。
-
对多字段聚合或跨系统计算,记好 逻辑注释 和 测试样本。
落地建议:
-
用Kafka 或 Pulsar 记录转换前后的数据片段,方便追溯。
-
用 Spark 或 Flink 重跑历史数据,验证修改是否破坏结果。
第三步:用规则引擎或API编排提高灵活性
硬编码映射跟不上业务变化的速度。
在 ETL 里接入 规则引擎(Drools、OpenL Tablets) 或 API 编排层 ,让转换逻辑通过配置快速调整。
真实经验:
-
场景:电商促销规则频繁改动,订单标记字段逻辑复杂。
-
做法:把转换逻辑抽到规则引擎,通过配置参数即时更新。
-
结果:上线周期从 5天缩短到1天,数据错误率降了 60%。
怎么验证ETL转换是不是精确?
问题1:有没有自动化验证?
-
给关键字段写 单元测试 + 集成测试。
-
建一个 金数据集(Golden Data Set) 做基准,验证每次改动都不破坏原逻辑。
问题2:有没有数据质量监控?
用 Great Expectations、Deequ 这些工具检测字段缺失、格式错误、跨系统不一致。
常见检测指标:
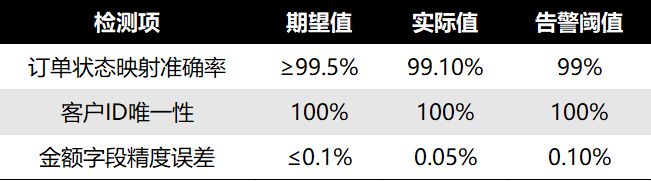
实际案例:精准映射带来的收益
某制造企业升级 ERP 时:
-
改进前:字段转换硬编码,数据错误率 2.3%,财务月结延迟两天。
-
改进后:用规则引擎 + 字段对照表 + 自动化监控,错误率降到 0.1% ,月结提前了48小时。
关键结论:ETL精准映射是数据治理的核心
精准映射不是单纯的技术问题,它是 数据治理、开发规范和业务协同的综合结果:
-
统一标准,保证字段语义一致。
-
版本控制和规则引擎,让逻辑灵活且可回溯。
-
自动化测试和质量监控,确保结果可量化、可验证。
总结:
对于涉及多系统集成或业务频繁变动的企业来说,构建动态、可回溯的ETL映射逻辑 是保证数据一致性与业务决策准确性的关键能力。这不只是技术投资,也是战略投资。
ETLCloud:为精准映射提供工程化支持
ETLCloud 是谷云科技自主研发的新一代全域数据集成平台,支持可视化字段映射、自动语义匹配和多源异构数据的高效转换。平台内置数据血缘分析、质量检测与异常告警能力,能够在不依赖大量手工 SQL 开发的前提下,实现复杂业务逻辑的快速建模和精准落地。
凭借 100% 自主研发的分布式架构 和 CDC+ETL一体化实时同步能力,ETLCloud 在高并发、大数据量场景中依然保持稳定,平均性能比传统开源工具提升 20% 以上。借助这些能力,企业可以更轻松地构建动态可回溯的数据转换流程,确保 ETL 映射逻辑始终准确无误。
