秋招笔记-8.17
鉴于明天我们会面试渲染开发相关的问题,我们今天来突击强化一下这个部分的内容。
我们先从复习GAMES101开始:
GAMES101
GAMES101作为计算机图形学的入门课程,大体上可以分为这几个部分:
基础的数学与变换
因为计算机图形学是绕不开图形的,而图形之间的变化牵扯到最基本的线性代数的内容,诸如向量的计算,矩阵的计算等等,所以我们大体上复习一下基本的数学知识。
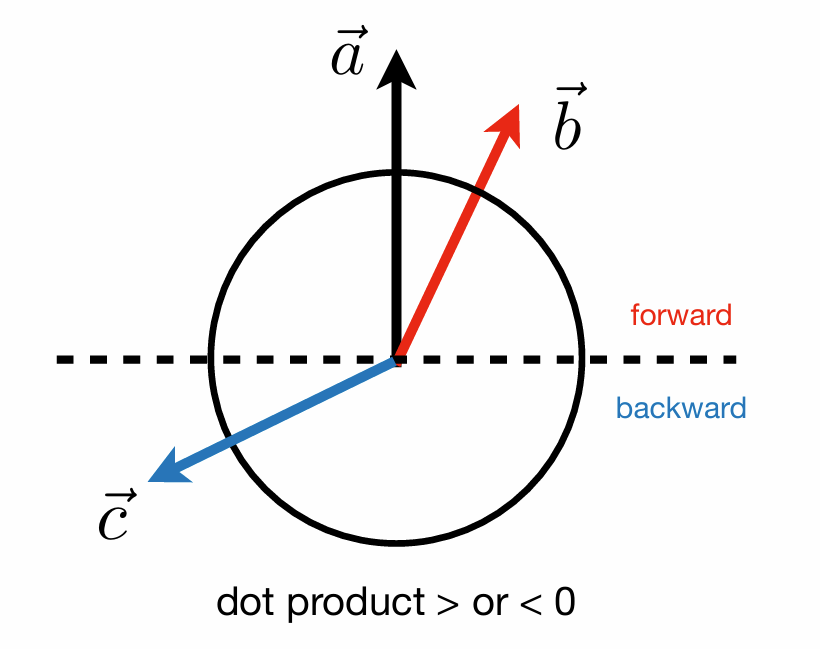
点乘与叉乘的概念和几何意义?
点乘是两个向量a·b = |a|×|b|×cosθ,其中θ是两向量夹角,点乘用于衡量两个向量的相似程度和夹角大小;叉乘则是两个向量a×b = |a|×|b|×sinθ×n,其中n是垂直于两向量的单位向量,意义是得到垂直于两向量的新向量,其长度等于两向量围成的平行四边形面积。
具体使用中,点乘可以用来判断两个向量的前后关系而叉乘判断左右关系以及里外关系。
为什么需要变换(Transform)?
因为真实的物体是3D的,但是我们的显示器只能以2D的形式呈现出来,所以需要想办法把3D的物体转移到2D的平面上来。
为什么在变化的过程中要引入齐次坐标系?
变换可以分为线性变化和非线性变换,针对这两种变换我们依然使用三维矩阵的话必须要用多个矩阵来表示且可能要包含矩阵的加法和乘法计算,引入齐次坐标系之后我们就可以统一使用矩阵的乘法进行计算。
如何理解MVP变化?
首先,MVP分别代表Model,View和Projection,也就是模型变换,视图变换和投影变换。MVP变化的意义就是将输入的顶点数据从最开始的模型空间转换到世界空间,再从世界空间转换到视图空间,再从视图空间转换到裁剪空间。
关于提到的模型空间、世界空间、视图空间以及裁剪空间:模型空间是每个物体自身的局部坐标系,物体的顶点数据通常定义在这个以物体为原点的空间中;通过模型变换将物体从模型空间转换到世界空间,世界空间是整个场景的全局参考坐标系,所有物体都统一在这个坐标系中确定其绝对位置和方向;接着通过视图变换将世界空间转换为视图空间,视图空间以相机为原点建立,相机看向-Z方向,在这个空间中根据视场角、近远平面自然形成一个视锥体;最后通过投影变换将这个视锥体转换为标准立方体(通常是[-1,1]³),这个立方体就是裁剪空间,在裁剪空间中便于进行视锥裁剪、透视除法和后续的光栅化处理,从而完成从3D世界到2D屏幕的完整变换流程。
具体代码上如何实现MVP变换?
我们来回顾一下作业的代码:
Eigen::Matrix4f get_model_matrix(float rotation_angle)
{Eigen::Matrix4f model = Eigen::Matrix4f::Identity();double rad = DEG2RAD(rotation_angle);model << cos(rad),-sin(rad),0,0,sin(rad),cos(rad),0,0,0,0,1,0,0,0,0,1;return model;
}这是模型矩阵的内容,负责将模型空间中的顶点坐标转换到世界空间中,通过旋转、缩放、平移等变换确定每个顶点在世界坐标系中的具体位置。
Eigen::Matrix4f get_view_matrix(Eigen::Vector3f eye_pos)
{Eigen::Matrix4f view = Eigen::Matrix4f::Identity();Eigen::Matrix4f translate;translate << 1, 0, 0, -eye_pos[0], 0, 1, 0, -eye_pos[1], 0, 0, 1, -eye_pos[2], 0, 0, 0, 1;view = translate * view;return view;
}这是视图矩阵,通过将世界坐标系的原点平移到摄像机位置,将所有顶点的坐标重新计算为相对于摄像机的坐标,从而建立以摄像机为中心的观察坐标系。
Eigen::Matrix4f get_projection_matrix(float eye_fov, float aspect_ratio, float zNear, float zFar)
{Eigen::Matrix4f projection = Eigen::Matrix4f::Identity();float top = -tan(DEG2RAD(eye_fov/2.0f) * abs(zNear));float right = top * aspect_ratio;projection << zNear/right,0,0,0,0,zNear/top,0,0,0,0,(zNear+zFar)/(zNear-zFar),(2*zNear*zFar)/(zFar-zNear),0,0,1,0;return projection;
}这是投影矩阵,通过相似三角形的数学原理将视锥体变换为标准立方体,将远近平面分别映射到z=1和z=-1,保持透视关系的同时为后续的视锥裁剪和光栅化处理做准备。
有哪两种投影方法?
透视投影模拟人眼的真实视觉,通过相似三角形的数学原理将锥形视锥体映射到标准立方体,具有近大远小的透视效果,投影矩阵构造相对复杂需要处理非线性变换和齐次坐标的w分量,常用于3D游戏和电影等需要真实感的场景;正交投影则采用平行投影的方式将长方体视锥体线性映射到立方体,没有近大远小的效果,投影矩阵构造简单只需线性缩放和平移变换。
光栅化渲染管线
如何理解光栅化?
光栅化简单来说就是将经由顶点着色器处理后输出的顶点组成的图元用屏幕上的像素去采样,判断具体哪些像素中包含图元,然后将这些图元用像素表达的过程,输出的东西名为片元,也就是没有着色的像素。这些片元中会包含一系列的数据,这些数据是基于顶点的数据通过重心插值来得到的。
为什么顶点着色器输出的顶点装配成图元时一般选择三角形?
因为三角形具有几何唯一性(三点确定唯一平面)、算法简单性(重心坐标插值、覆盖测试都相对简单)、硬件友好性(GPU针对三角形高度优化,便于并行处理和内存访问)以及实际应用优势(任何复杂几何都可以三角化,支持LOD和变形),同时三角形避免了四边形可能不是平面、多边形计算复杂等问题。
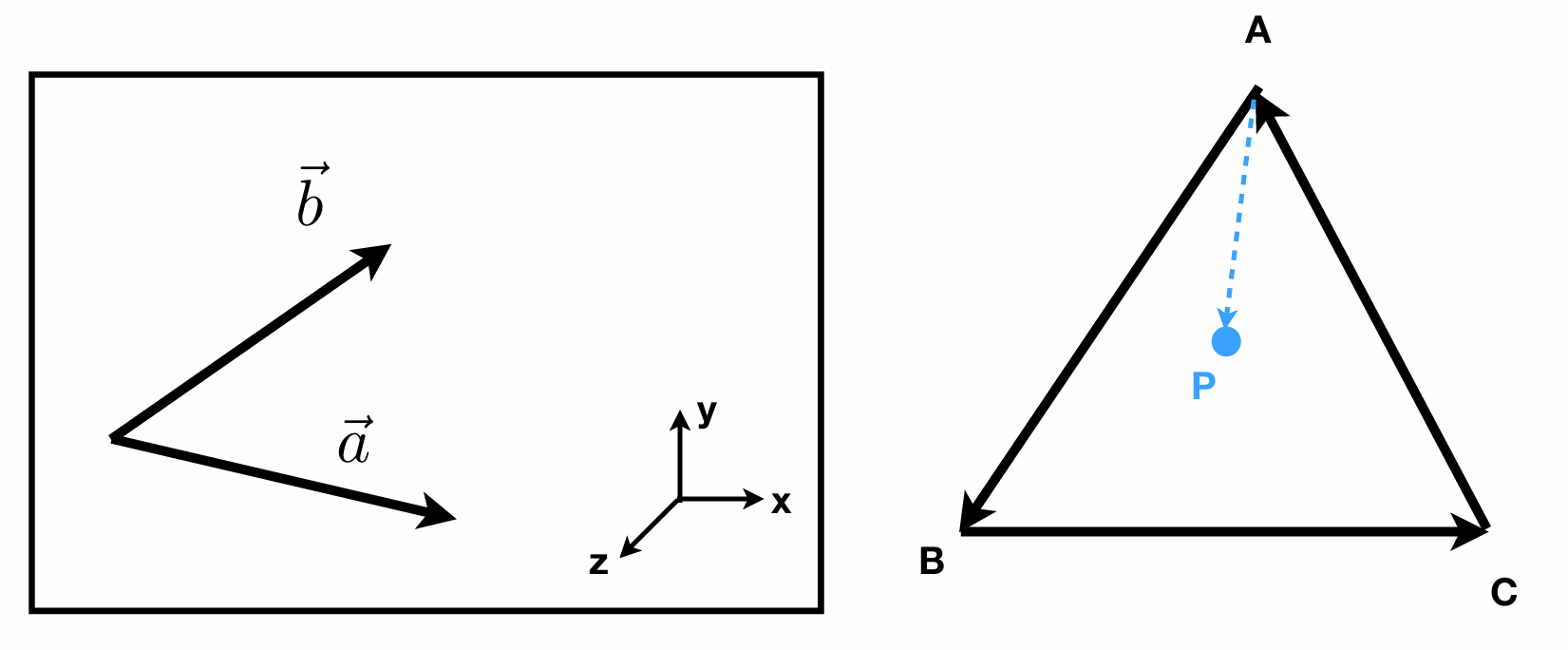
如何判断一个点是否在三角形内部?
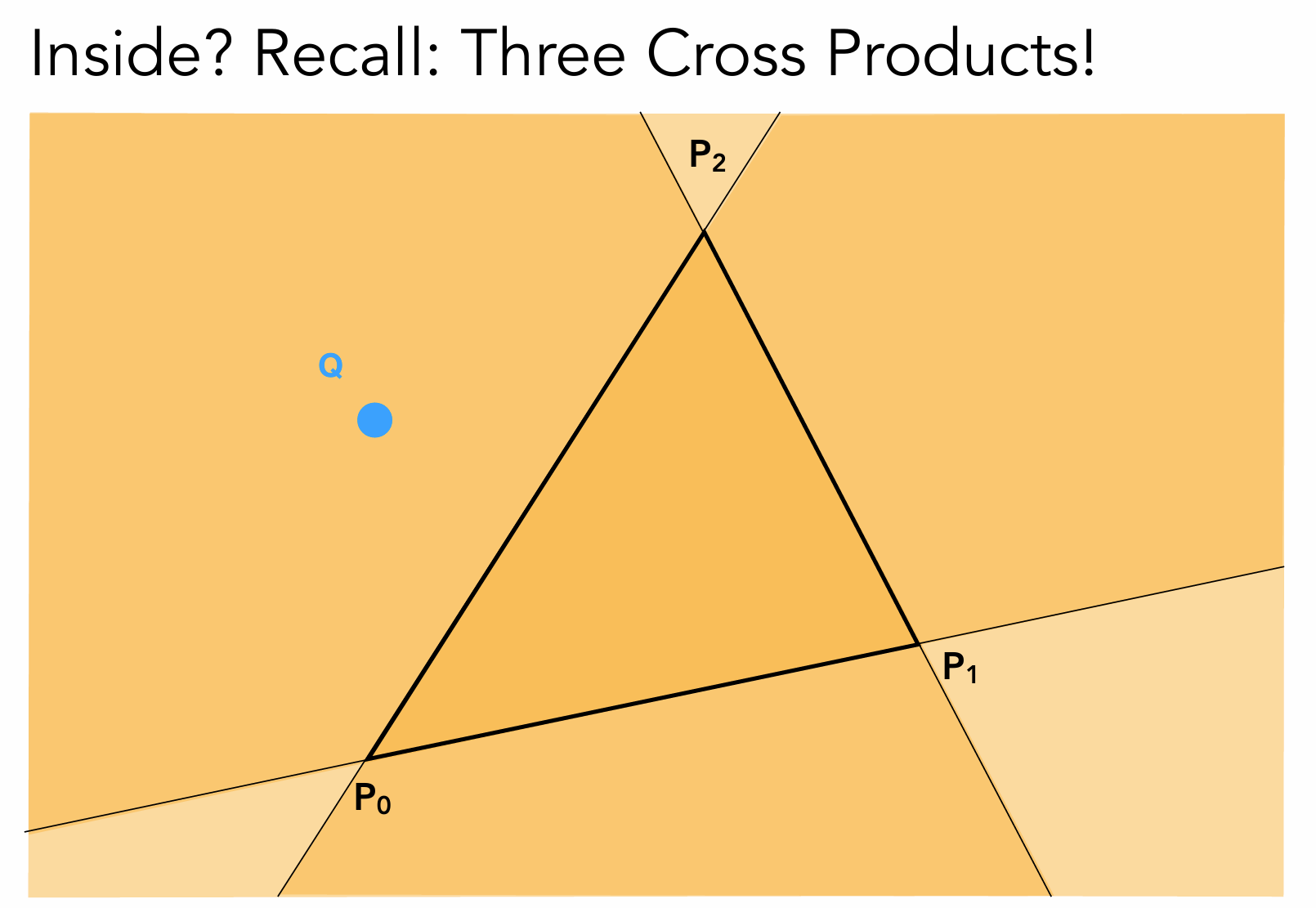
很简单,我们分别获取到三个点和待测试的顶点的向量,然后用三条边分别和这三个新的向量进行一个叉乘,如果正负都相同说明点在三角形内部,否则在外部。
常见的加快光栅化过程的手段有?
- 包围盒(Bounding Box):只处理三角形覆盖的像素区域,避免遍历整个屏幕
- 边函数优化:使用高效的边函数算法判断像素覆盖
- 扫描线算法:按行处理,减少重复计算
- 增量计算:利用相邻像素的连续性减少计算量
如何理解采样前低通滤波?有何作用?
采样前低通滤波是在对信号进行采样之前,通过滤波器去除信号中的高频成分,将信号带宽限制在采样频率的一半以下,从而确保满足奈奎斯特采样定理,避免混叠失真的产生;在图形学中,这种技术主要用于纹理采样、图像缩放和抗锯齿处理,通过预滤波可以显著减少摩尔纹、锯齿等采样伪影,提高最终图像质量,但需要注意的是过度滤波会丢失图像细节,因此需要在滤波强度、图像质量和计算开销之间找到合适的平衡点。
如何理解锯齿?为什么有锯齿?有哪些常见的抗锯齿手段?
锯齿(Aliasing)是由于采样频率不足导致的信号失真现象,在图形学中表现为边缘的阶梯状或锯齿状效果。常见的抗锯齿手段有:SSAA、MSAA、FXAA以及基于深度学习来抗锯齿(如DLSS)等。
SSAA(超采样抗锯齿):以比目标分辨率更高的分辨率渲染整个场景,每个像素对应多个采样点,然后通过下采样将高分辨率结果转换到目标分辨率,通过平均多个采样点的颜色值来减少锯齿,虽然能处理所有类型的锯齿且质量最高,但需要巨大的计算和内存开销。
MSAA(多重采样抗锯齿):只对检测到的几何边缘像素进行多重采样,内部像素只采样一次,通过比较相邻像素的深度或颜色差异来识别边缘,在边缘处使用多个采样点计算颜色,然后平均得到最终颜色,硬件友好且性能开销适中,但只能处理几何边缘锯齿。
FXAA(快速近似抗锯齿):采用后处理方式,通过分析像素邻域的亮度变化来检测边缘,对检测到的边缘应用智能平滑滤波,不需要额外的渲染过程,直接在最终图像上进行处理,性能开销小且不依赖硬件支持,但可能过度平滑细节。
基于深度学习的抗锯齿:使用预训练的神经网络来识别锯齿模式并预测正确的像素值,网络学习从低质量图像生成高质量图像,可以同时处理几何锯齿、纹理锯齿等多种失真类型,代表技术包括DLSS、FSR等,质量高但需要大量训练数据和计算资源。
着色与光照
什么是画家算法?深度测试又是什么?
画家算法是一种基于深度排序的渲染方法,按照从远到近的顺序渲染物体,后渲染的内容会覆盖先渲染的内容,从而实现正确的遮挡关系,但这种方法无法处理相互穿透的物体和循环遮挡问题,且需要全局排序导致性能较差;深度测试则是一种更高效的解决方案,通过为每个像素维护一个深度缓冲值,在渲染每个像素时比较其深度与缓冲中的深度值,只保留更近的像素,从而正确处理任意复杂的遮挡关系,无需全局排序且适合并行处理。
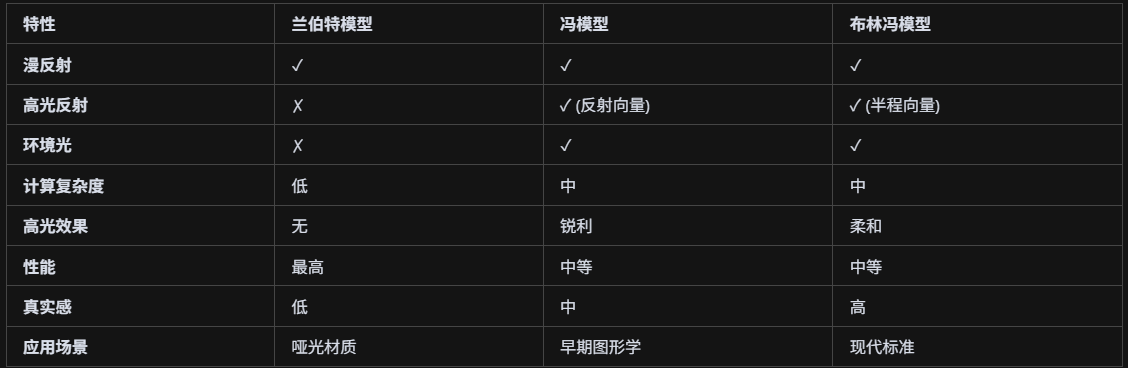
常见的光照模型有哪些?
兰伯特光照模型(Lambert Lighting Model):
兰伯特光照模型是最基础的光照模型,只考虑漫反射分量,基于兰伯特余弦定律,认为表面向各个方向均匀反射光线,光照强度与表面法线和光线方向的夹角余弦成正比,数学公式为I = kd × L × max(0, N·L),其中kd是漫反射系数,L是光线强度,N是表面法线,L是光线方向,这种模型计算简单但只能产生无光泽的哑光效果,无法表现高光反射。
冯光照模型(Phong Lighting Model):
冯光照模型在兰伯特模型基础上增加了高光反射分量,包含环境光、漫反射和高光三个组成部分,其中高光计算使用反射向量R,数学公式为Is = ks × L × max(0, R·V)^shininess,其中R是反射向量,V是视线方向,shininess控制高光的锐度,这种模型能够产生有光泽的表面效果,但反射向量的计算相对复杂。
布林冯光照模型(Blinn-Phong Lighting Model):
布林冯光照模型是对冯模型的改进,使用半程向量H代替反射向量R来计算高光,半程向量是视线方向和光线方向的归一化和,数学公式为Is = ks × L × max(0, N·H)^shininess,这种改进使得高光计算更高效,高光效果更自然柔和,避免了反射向量的复杂计算,成为现代图形学中最常用的光照模型。
如何理解图中的算式?
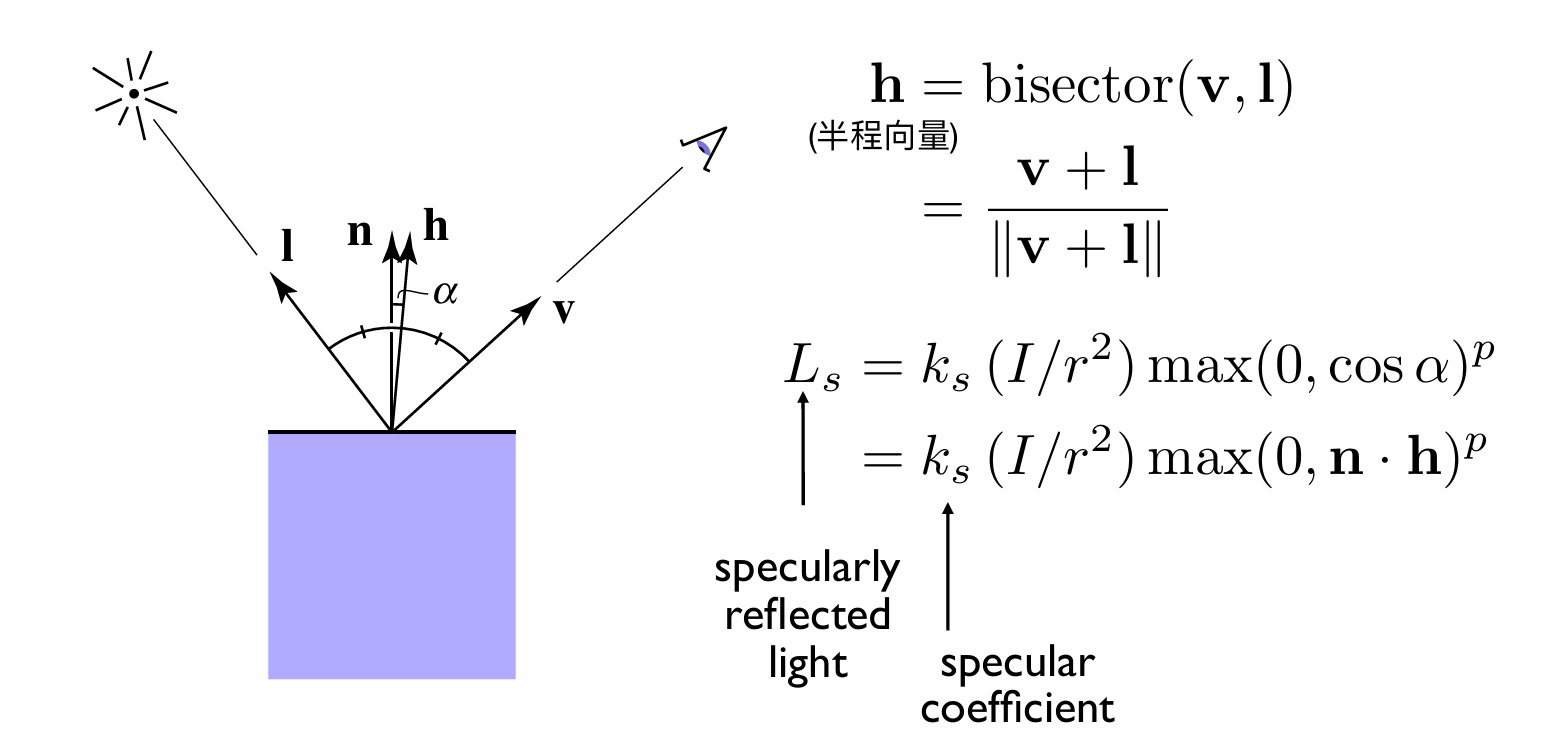
图中的算式是具体布林冯模型中如何计算高光光照的部分,其中Ls表示高光反射光强度,ks是高光反射系数,I是光源强度,r是距离,I/r²表示光线随距离的衰减,α是反射方向与视线方向的夹角,p是光泽度指数控制高光的锐度,第一个公式使用反射方向与视线方向的夹角余弦值cos α来计算高光强度,其中α是反射方向与视线方向的夹角,第二个公式使用法线向量与半程向量的点积n·h来计算。

顺带一提,这个就是布林冯光照模型的完整内容,也就是由环境光加漫反射计算加上高光反射计算组成。
如何理解着色频率?
着色频率就是指在渲染过程中多久计算一次着色,比较常见的着色频率包括:逐顶点,逐像素,逐面。

着色频率是指光照计算的频率,分为三种类型:逐顶点着色在顶点着色器中计算光照,每个顶点计算一次光照值,然后通过插值传递给片元,性能较高但可能出现马赫带效应;逐面着色在几何着色器中计算光照,对整个三角形计算一次光照,三角形内所有片元使用相同的颜色值,性能最高但质量最差,有明显的面片感;逐像素着色在片元着色器中计算光照,每个像素独立计算光照,质量最高但性能开销最大,能产生最真实的光照效果和最锐利的高光,是现代图形学的标准做法。
渲染管线回顾:
渲染管线的输入是CPU传递给GPU的顶点数据,首先进入顶点着色器进行MVP变换,将顶点从模型空间依次转换到世界空间、视图空间、裁剪空间,然后进行透视除法将裁剪空间转换为NDC空间,再通过视口变换映射到屏幕坐标系,同时顶点属性(颜色、法线、纹理坐标等)在变换过程中不断更新;顶点着色器输出的顶点进入图元装配阶段,将顶点组装成三角形等图元,这些图元作为光栅化的输入,光栅化过程用屏幕像素采样图元,判断哪些像素包含图元,并将图元转换为片元,片元的属性通过重心坐标插值从顶点属性得到;片元进入片元着色器进行着色计算,包括光照计算、纹理采样等,通常采用逐像素着色频率;最后进入测试和混合阶段,包括深度测试、模板测试、混合等,只有通过测试的片元才会写入帧缓冲区,最终通过双缓冲机制将像素映射到屏幕形成可见图像,这就是完整的现代图形渲染管线流程。
如何理解纹理映射?
纹理映射是将2D图像映射到3D物体表面的技术,通过UV坐标系统建立2D纹理和3D几何体的对应关系,每个顶点分配UV坐标,片元通过重心坐标插值得到精确的UV坐标,然后根据UV坐标从纹理图像中采样颜色值并应用到片元着色中,从而为物体表面增加颜色、图案、细节等视觉信息。
纹理在显示器中被放大会怎样?如何解决?
纹理在显示器中被放大后会产生像素化、锯齿和细节丢失等视觉问题,因为一个屏幕像素可能对应纹理中的非整数纹素位置,导致采样精度不足,也就是所谓的纹理走样。
解决方法是选择合适的插值算法,包括最近邻插值(简单但像素化明显)、双线性插值(平滑但模糊)和双三次插值(质量最好但计算复杂),同时可以使用更高分辨率的原始纹理、Mipmap技术或各向异性过滤来进一步提升质量,在性能和图像质量之间找到合适的平衡点。
最近邻插值直接选择距离目标UV坐标最近的纹素颜色值,计算最简单但会产生明显的像素化;双线性插值取目标坐标周围2×2网格的4个纹素,在水平和垂直方向分别进行线性插值,先对水平方向的两个纹素按距离权重插值得到两个中间值,再对这两个中间值进行垂直方向的线性插值得到最终颜色,结果平滑但可能模糊;双三次插值取目标坐标周围4×4网格的16个纹素,使用三次多项式权重函数进行更复杂的插值计算,考虑更多周围纹素的影响,计算复杂度最高但能保留更多细节和锐度,三种方法从简单到复杂,质量从低到高,需要在性能和质量之间权衡选择。
几何处理
什么是贝塞尔曲线?如何实现?
贝塞尔曲线是由一组控制点定义的参数曲线,通过伯恩斯坦多项式或De Casteljau算法实现,其中起点和终点控制点决定曲线的起止位置,中间控制点用于"牵引"曲线形状而不一定在曲线上,曲线始终位于控制点凸包内且具有仿射不变性;实现方法包括直接使用伯恩斯坦多项式公式计算或采用De Casteljau的递归线性插值算法,后者通过不断对相邻控制点进行线性插值直到得到最终曲线点,数值稳定且易于实现。
如何理解网格?网格有哪些相关的操作?
网格是3D模型的基本几何表示,由顶点(vertices)、边(edges)和面片(faces)组成,定义了模型的几何形状和拓扑结构。网格常见的操作如下:

网格细分:分为Catmull-Clark细分:在面片中心添加新顶点,连接形成新面片和Loop细分:在三角形边的中点添加新顶点。其中Loop细分主要针对三角形而CC细分可以针对各种多边形实现网格细分。
Loop细分来说:
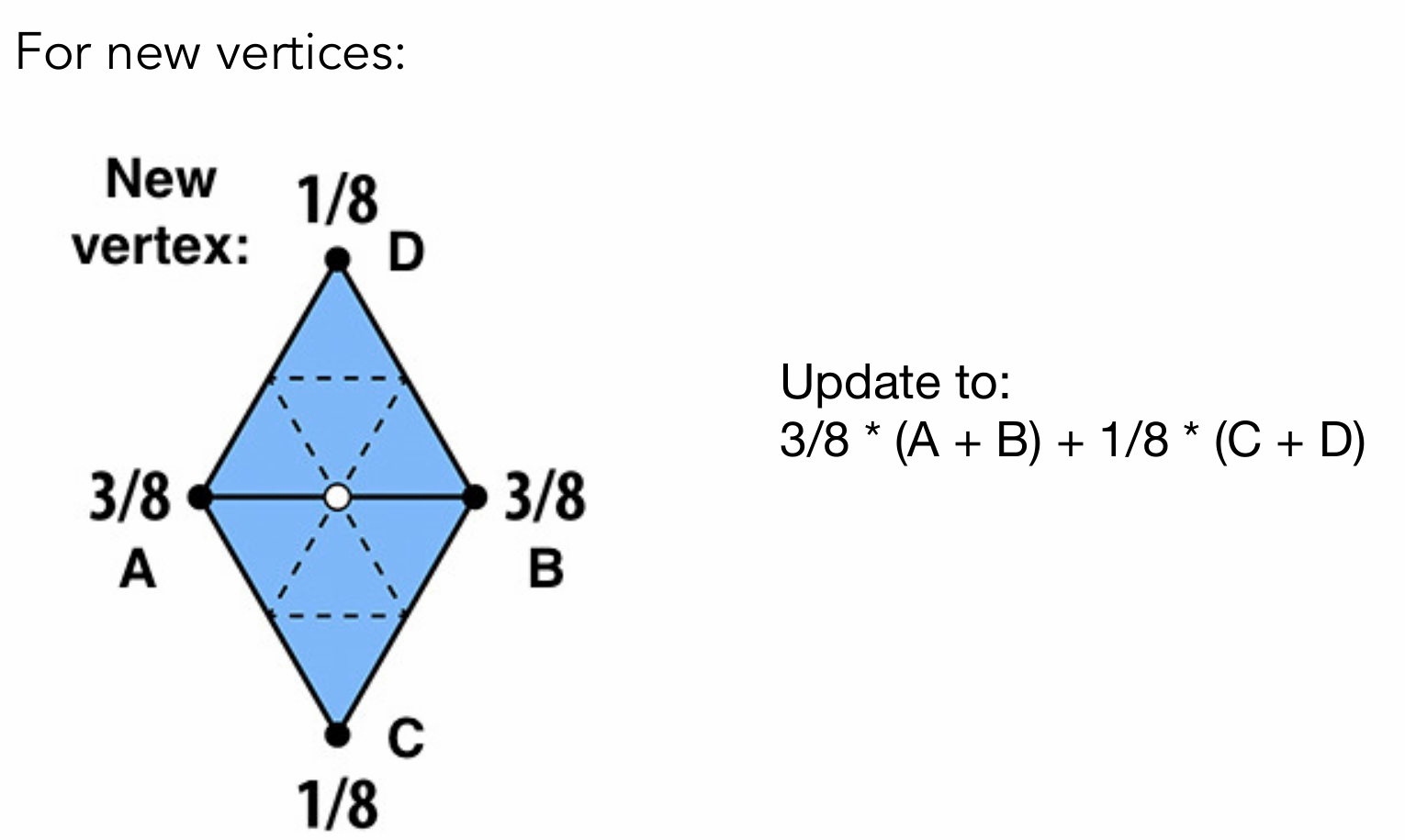
在每个三角形的边中点加入新的顶点,然后基于新的顶点来重新划分三角形。
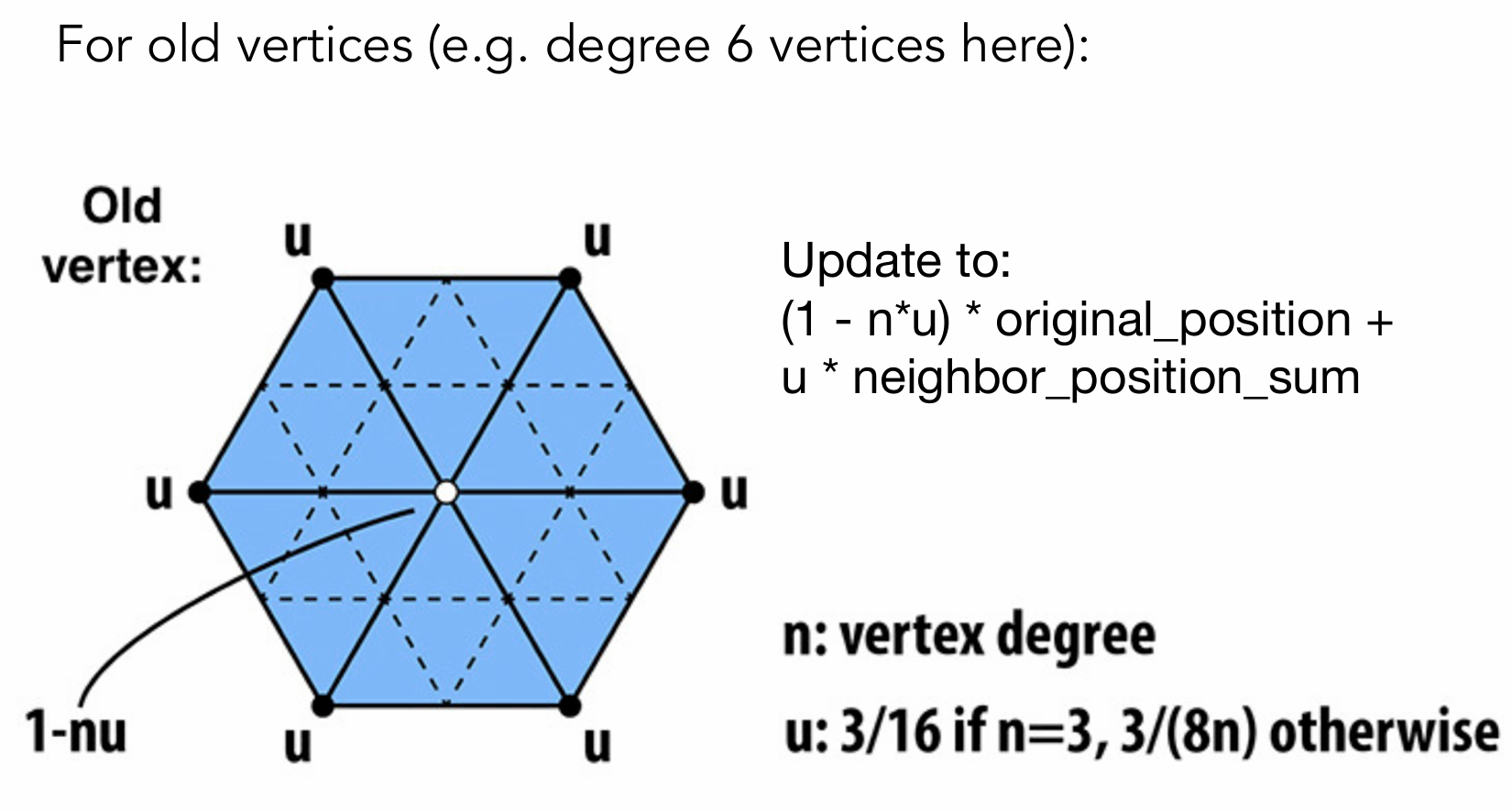
Catmull-Clark细分则是通过在面片和边的中心处加入顶点来重新划分网格。
网格的简化则主要通过边折叠实现:
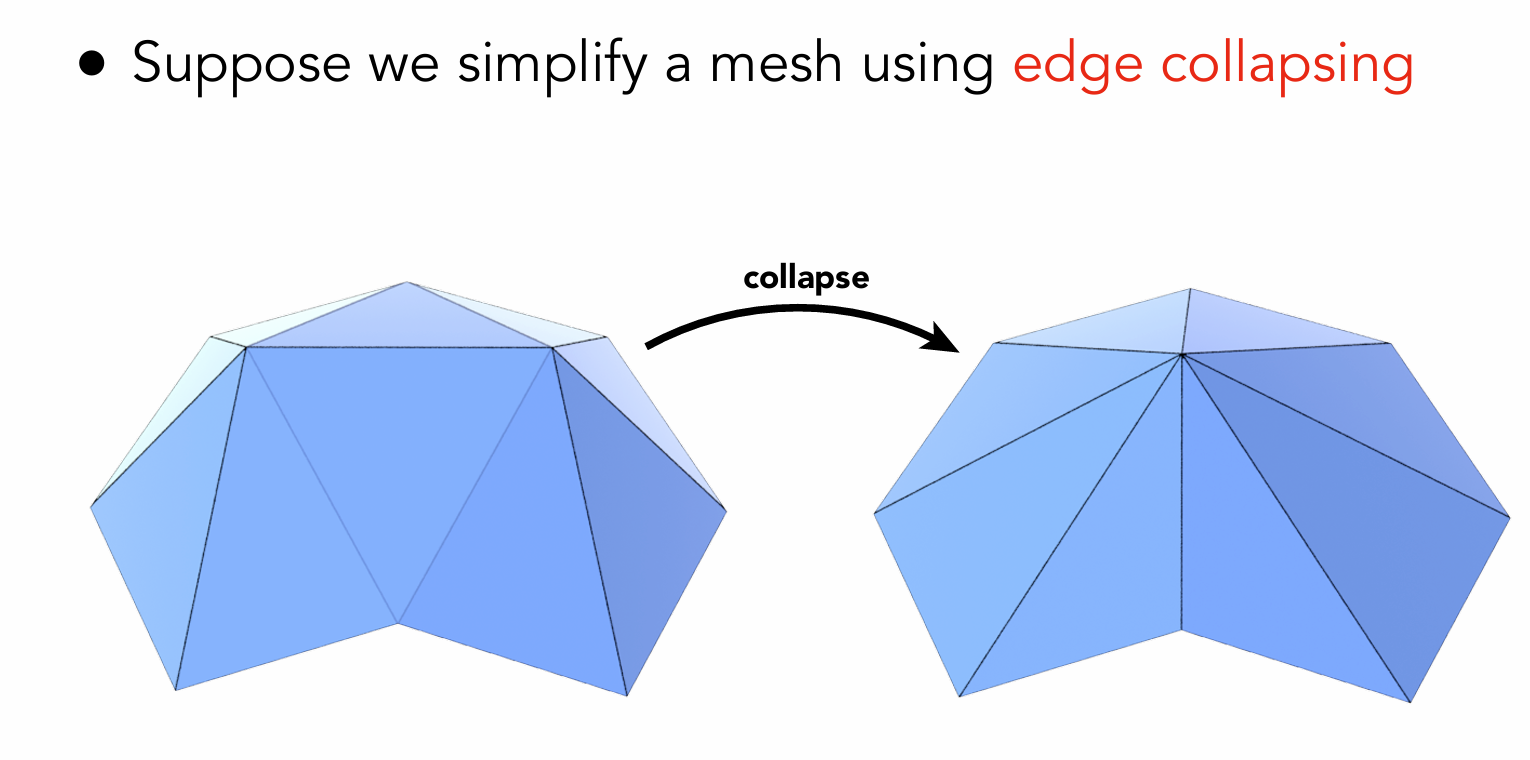
网格的正则化则是通过所谓的拉普拉斯算子计算更换网格顶点位置来实现。
如何理解阴影映射?有哪些常见的阴影映射方法?
阴影映射是一种实时阴影渲染技术,通过从光源视角渲染场景的深度信息到阴影贴图中,然后在主渲染过程中将当前像素的深度与阴影贴图中的深度进行比较,如果当前深度大于阴影贴图中的深度则说明该像素被其他物体遮挡,从而判断像素是否处于阴影中,最终实现实时阴影效果。
常见的阴影映射方法包括:标准阴影映射,PCF阴影,CSM等。
标准阴影映射:从光源位置设置虚拟相机,将场景从光源视角渲染一遍并将每个像素的深度值存储到阴影贴图中,然后在主渲染过程中将当前像素从世界坐标转换到光源的裁剪空间,采样阴影贴图中对应位置的深度值进行比较,如果当前深度大于阴影贴图中的深度则说明被遮挡,从而判断像素是否在阴影中,这是最基础的阴影映射方法。
PCF阴影映射(百分比渐进过滤):在标准阴影映射的基础上,对阴影贴图进行多次采样而不是单次采样,通过计算周围多个采样点的深度比较结果,将这些结果进行加权平均得到阴影的软硬程度,从而产生软阴影效果,采样次数越多阴影越软,但计算开销也越大。
CSM阴影映射(级联阴影映射):为了解决大场景中远近阴影质量差异的问题,将视锥体按距离分成多个层级,每个层级使用不同分辨率的阴影贴图,近处使用高分辨率阴影贴图保证细节,远处使用低分辨率阴影贴图节省内存,通过这种方式在保证近处阴影质量的同时避免远处阴影贴图浪费,适合大场景的阴影渲染。
光线追踪
为什么需要光线追踪?
传统的光栅化方法只考虑了直接光照而遗漏了间接光照这一重要的全局光照组成部分,无法模拟物体间的相互反射、软阴影、颜色溢出等真实的光照效果,同时其本身使用的经验模型(如Blinn-Phong)物理真实性不足,不是基于真实的光线传播原理,因此需要光线追踪这种基于物理的光线传播方法来自然产生间接光、统一处理所有光照效果,从而获得更真实、更完整的渲染结果。
如何实现光线与球体/三角形求交?
将光线方程 P(t) = orig + t * dir 代入球体方程 |P - center|² = radius²,得到二次方程 a*t² + b*t + c = 0,通过求解判别式得到交点参数t;光线与三角形求交使用重心坐标法:设交点满足 orig + t*dir = v0 + u*(v1-v0) + v*(v2-v0),通过克莱默法则求解线性方程组得到参数t和重心坐标u、v,然后检查约束条件 t≥0, u≥0, v≥0, u+v≤1 判断交点是否在三角形内部。
简单地来说,本质上光线与球体和三角形求交都是解方程,把两个几何体的数学表达式联立求解,看解是否满足几何约束条件。
GAMES101中主要提出了两种光线追踪:Whitted-Style光线追踪算法和路径追踪算法。
Whitted光线追踪是一种递归的光线追踪算法,其底层原理是从相机为每个像素发射主射线,在场景中寻找最近交点,若命中则先计算直接光照(向光源发射阴影射线判断遮挡),然后根据材质类型生成后继射线:对于镜面材质沿反射方向递归追踪,对于透明材质沿折射方向递归追踪,每次递归都累积光照贡献,通过设置最大递归深度或俄罗斯轮盘来避免无限递归,最终将所有递归路径的光照贡献合成得到像素颜色,这种方法能自然产生反射、折射和硬阴影效果,但无法处理漫反射间接光,属于确定性的光线追踪方法,计算相对简单但物理真实性有限。
路径追踪是一种基于蒙特卡洛积分的光线追踪算法,其核心思想是通过随机采样来求解渲染方程。算法从相机发射光线,当光线与场景中的物体相交时,根据材质的BRDF(双向反射分布函数)随机选择新的光线方向继续追踪,直到光线击中光源或达到最大深度。每个像素的颜色通过多次采样(SPP - Samples Per Pixel)的平均值来计算,这样就能自然地处理全局光照、间接光照、软阴影、焦散等复杂的光照效果。路径追踪的关键在于使用重要性采样和俄罗斯轮盘赌等技术来提高采样效率,确保算法能够收敛到正确的物理光照解。
Whitted光线追踪是一种确定性的算法,它通过递归地追踪反射和折射光线来计算像素颜色,主要处理镜面反射、透明材质和直接光照,但不考虑间接光照。相比之下,路径追踪是一种随机算法,通过蒙特卡洛方法随机采样光线路径,能够完整地模拟光的传播过程,包括所有形式的间接光照和全局光照效果。Whitted算法计算速度快但光照效果有限,而路径追踪虽然计算复杂且会产生噪声,但能够产生照片级真实感的渲染结果,是现代光线追踪的主流技术。
AABB盒是什么?有什么用?
AABB盒(Axis-Aligned Bounding Box,轴对齐包围盒)是一种最简单的包围盒类型,它是一个与坐标轴平行的长方体。AABB盒由两个点定义:最小点(min)和最大点(max),分别表示包围盒在x、y、z三个轴向上的最小和最大坐标值。由于AABB盒的边与坐标轴平行,这使得与它的相交测试变得非常简单和高效。
我们用AABB盒替代物体来进行相交检测就可以快速排除不会发生相交的像素点,加速传统的光线与物体求交点的过程。
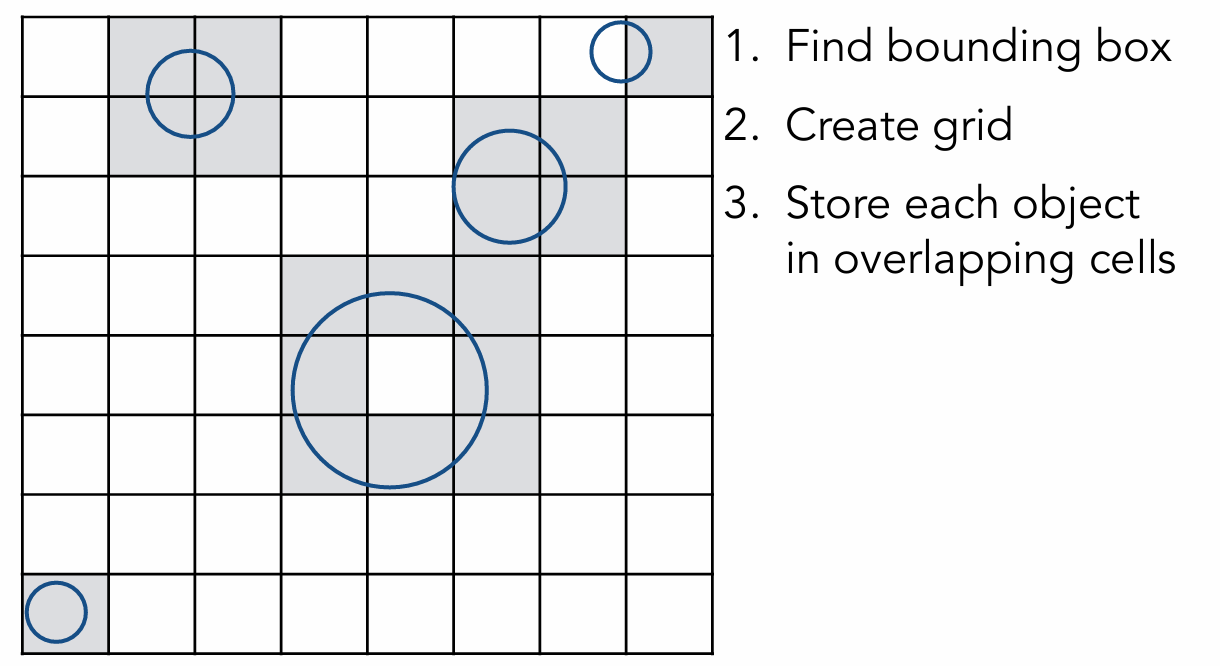
Uniform Spatial Partitions (Grids) 是什么?
Uniform Spatial Partitions (Grids) 是一种简单而有效的光线追踪加速结构,通过将3D空间均匀分割成网格单元来加速光线与物体的相交测试。它特别适合物体分布均匀的场景,但在处理复杂或不均匀的场景时,BVH等自适应结构通常表现更好。
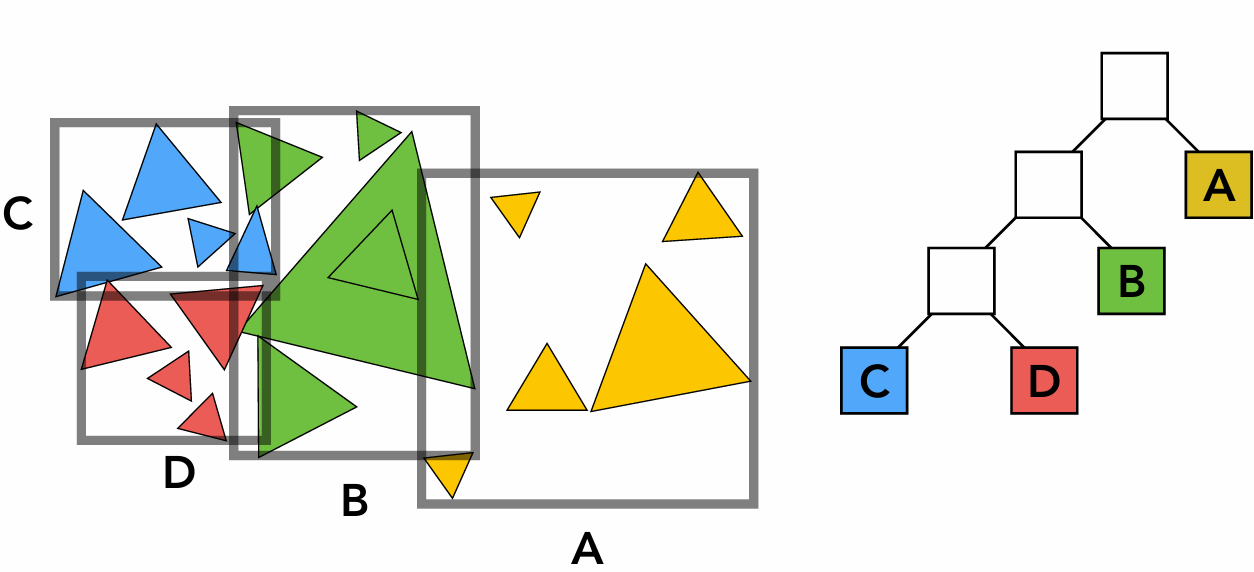
BVH又是什么?
BVH是层次包围盒,是一种基于包围盒的层次化空间加速结构。它将场景中的物体组织成树状结构,每个节点都有一个包围盒,包含其子节点中的所有物体。
KD树又是什么?
KD树是一种空间分割数据结构,用于组织k维空间中的点。在3D图形学中,KD树将3D空间递归地分割成更小的子空间,每个子空间包含场景中的一部分物体。
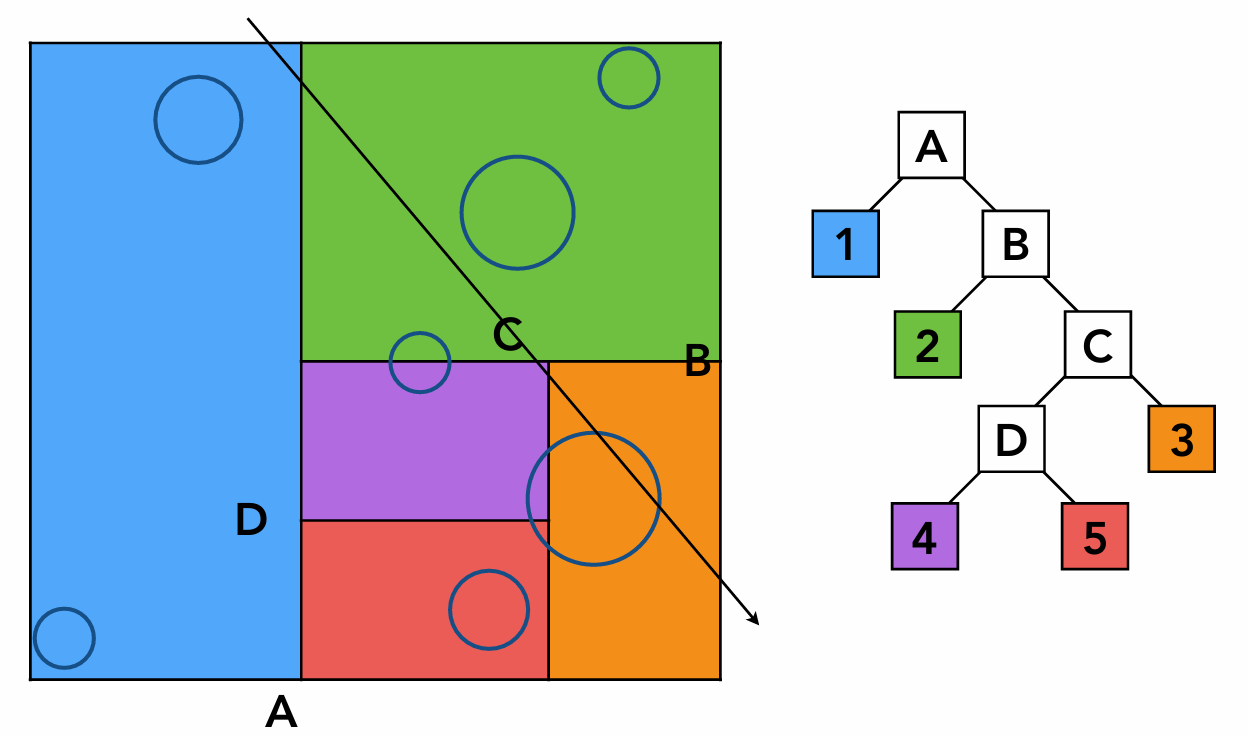
总的来说,无论AABB包围盒,均匀网格分割,KD树还是BVH,都是帮助我们进行光线追踪加速的一个效果:
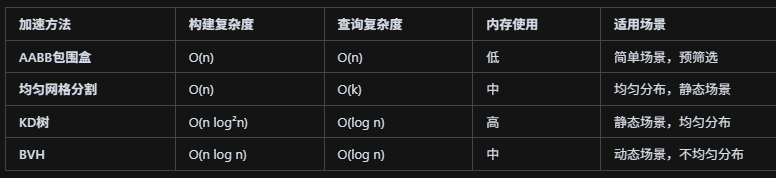
什么是辐射度量学?在GAMES101中具体起到什么作用?
首先介绍了几个基本的概念:
- 辐射通量(Radiant Flux):单位时间内通过某个表面的能量
- 辐射强度(Radiant Intensity):单位立体角内的辐射通量
- 辐射亮度(Radiance):单位面积、单位立体角的辐射通量
- 辐照度(Irradiance):单位面积接收到的辐射通量
GAMES101课程中关于辐射度量学的内容主要集中在光线追踪部分,特别是为路径追踪算法奠定理论基础。
关于反射方程:
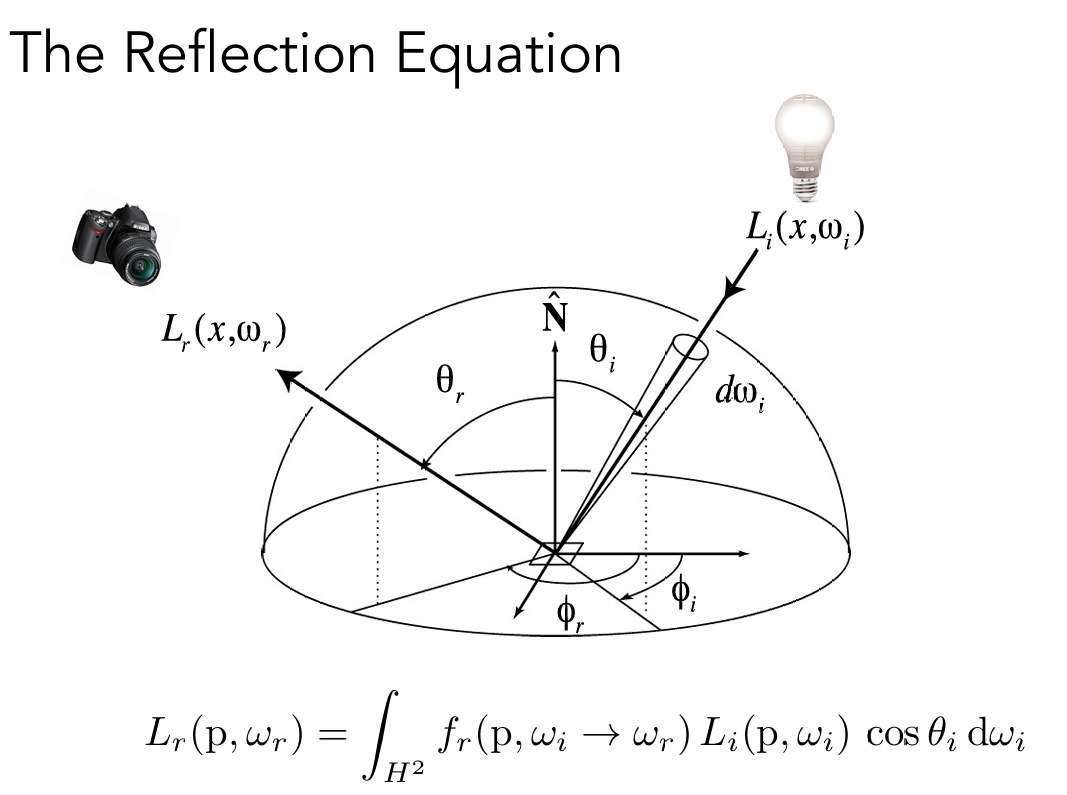
反射方程描述了光线在物体表面的反射过程。其中,出射辐射亮度表示从表面点沿特定方向反射出去的辐射亮度(即我们最终看到的颜色和亮度),半球积分表示对上半球所有可能的入射方向进行积分,BRDF是双向反射分布函数,定义了材质如何将入射光线从入射方向反射到出射方向,入射辐射亮度表示从入射方向射入的辐射亮度(包括直接和间接光照),入射角余弦是入射光线与表面法线夹角的余弦值(遵循朗伯余弦定律),微分立体角用于积分。
这个反射方程是渲染方程的重要组成部分,现在让我们来看看渲染方程:
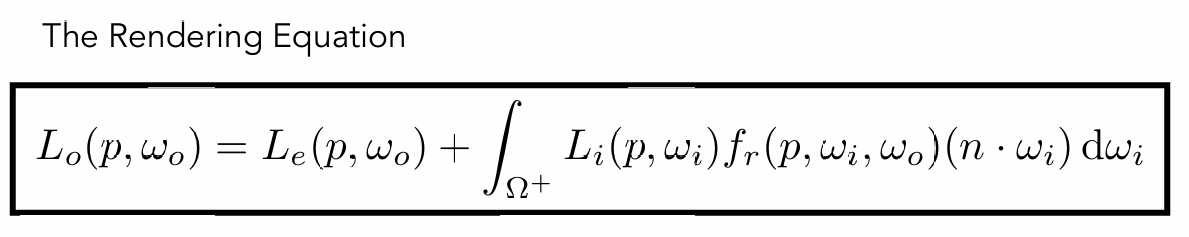
渲染方程的本质就是一个自发光项和反射方程,这个自发光项主要针对光源,非光源这一项为0,反射方程则是由BRDF函数以及一个半球立体角积分组成。我们的路径追踪的目的就是去解这个渲染方程,获取具体的出射辐射亮度,更具体来说就是图像的颜色和亮度。
OK,那具体怎么解呢?这就需要我们的蒙特卡洛积分:
蒙特卡洛积分是一种用随机采样来近似计算积分的方法,其核心思想是将复杂的积分 ∫f(x)dx 转化为随机采样点的平均值 (1/N) * Σ(f(xi)/p(xi)),其中 xi 是随机采样的点,p(xi) 是采样概率密度函数,N 是采样数量。在渲染方程中,我们需要计算半球上所有入射方向的积分,但无法直接求解,因此使用蒙特卡洛方法随机采样一些入射方向,计算每个采样点的贡献并求平均,从而近似求解整个积分。这种方法虽然会产生噪声,但能够处理任意复杂的积分,是路径追踪等现代光线追踪算法的数学基础。
最后我们还有一个避免无限递归的俄罗斯轮盘赌:
俄罗斯轮盘赌是路径追踪中用于控制光线路径长度的一种技术,其核心思想是通过概率性终止来避免光线无限递归追踪。当光线与物体相交时,算法会以一定概率(通常为0.8)决定是否继续追踪该光线,如果继续追踪则递归计算间接光照,如果终止则直接返回零贡献。为了保持能量守恒,当决定继续追踪时,会将最终结果除以继续追踪的概率来补偿被终止的路径,这样既避免了无限递归,又保证了渲染结果的物理正确性,是一种在计算效率和渲染质量之间取得平衡的重要优化技术。
至此整个路径追踪需求的内容已经全部介绍了:
路径追踪是一种基于物理的光线追踪算法,其理论基础是辐射度量学和渲染方程。渲染方程描述了表面点在特定方向的出射辐射亮度等于自发光加上所有入射方向的反射贡献,其中BRDF函数定义了材质的反射特性。由于渲染方程中的积分无法直接求解,路径追踪使用蒙特卡洛积分方法,通过随机采样入射方向,计算每个采样点的贡献并求平均来近似求解积分。算法从相机发射光线,当光线与物体相交时,根据材质类型随机采样新的光线方向继续追踪,并使用俄罗斯轮盘赌技术来控制路径长度,以一定概率终止路径避免无限递归,最终通过多次采样的平均值计算每个像素的颜色,从而实现全局光照、软阴影、焦散等照片级真实感的渲染效果。
LearnOpenGL
为什么要学LearnOpenGL?
GAMES101专注于图形学理论基础和数学推导,而LearnOpenGL则提供现代OpenGL的实际编程实践。LearnOpenGL通过完整的可运行代码示例,从基础窗口创建到高级PBR渲染,教授现代图形API的使用、工程实践技能(如CMake构建、依赖管理)、性能优化技术(实例化渲染、GPU编程)以及实时渲染的核心技术栈。
说实话,GAMES101作为入门课来说确实工程这部分比较少。
我们先来大体介绍一下OpenGL这个图形学API:
OpenGL是一个跨平台的图形编程接口,由Khronos Group维护,提供标准化的函数来渲染2D和3D图形。它采用状态机设计,通过CPU发送命令给GPU执行渲染,支持可编程的着色器管线(顶点着色器、片段着色器等)。OpenGL从早期的固定管线演进到现代的可编程管线(3.3+版本),广泛应用于游戏开发、科学可视化等领域,让开发者能够直接与GPU交互实现高效的图形渲染。
我们按照OpenGL的章节来分部分复习:
入门
如何理解OpenGL是一个巨大的状态机?
OpenGL自身是一个巨大的状态机(State Machine):一系列的变量描述OpenGL此刻应当如何运行。OpenGL的状态通常被称为OpenGL上下文(Context)。我们通常使用如下途径去更改OpenGL状态:设置选项,操作缓冲。最后,我们使用当前OpenGL上下文来渲染。
假设当我们想告诉OpenGL去画线段而不是三角形的时候,我们通过改变一些上下文变量来改变OpenGL状态,从而告诉OpenGL如何去绘图。一旦我们改变了OpenGL的状态为绘制线段,下一个绘制命令就会画出线段而不是三角形。
当使用OpenGL的时候,我们会遇到一些状态设置函数(State-changing Function),这类函数将会改变上下文。以及状态使用函数(State-using Function),这类函数会根据当前OpenGL的状态执行一些操作。只要你记住OpenGL本质上是个大状态机,就能更容易理解它的大部分特性
如何理解VAO、VBO以及IBO/EBO?
VAO是一个状态容器,存储了顶点属性的配置信息(如数据格式、步长、偏移量),通过glVertexAttribPointer()设置如何解释VBO中的数据,现代OpenGL中必须使用VAO来管理顶点属性状态。
VBO是存储在GPU内存中的缓冲区,用来存储顶点数据(如位置、颜色、法向量、纹理坐标等),通过glBufferData()将CPU数据上传到GPU,减少数据传输开销,提高渲染性能。
EBO(Element Buffer Object)是 OpenGL 中用来存储顶点索引的缓冲区对象,它存储的是指向 VBO 中顶点数据的索引数组,而不是顶点数据本身。当你有很多重复的顶点时(比如一个立方体的 8 个顶点可以组成 12 个三角形),EBO 存储的是"用第 0、1、2 号顶点组成第一个三角形,用第 1、2、3 号顶点组成第二个三角形"这样的索引信息,通过 glDrawElements() 函数,GPU 会根据这些索引从 VBO 中取出对应的顶点数据进行渲染。
什么是GLFW?
GLFW(Graphics Library Framework)是一个轻量级的、跨平台的C语言库,专门用于创建窗口、上下文和接收输入事件。
如何理解NDC?
NDC是标准化设备坐标系统,坐标范围在[-1,1]的立方体空间内,通过投影变换将3D场景转换为标准化的2×2×2立方体,实现设备无关的几何体处理,简化裁剪测试,是3D图形渲染管线中从3D世界坐标到2D屏幕坐标转换的关键中间步骤。
什么是GLSL?为什么着色器用这种语言来写?
GLSL(OpenGL Shading Language)是专门为 GPU 并行计算设计的着色器编程语言,它看起来像 C 语言但针对图形渲染进行了优化。GPU 有数千个并行处理单元,需要同时处理大量顶点或像素,GLSL 就是为这种并行架构设计的,它内置了向量和矩阵运算(如 vec3、mat4),支持 SIMD(单指令多数据)操作,可以直接对多个分量同时计算,还集成了图形学常用的函数(如 texture()、normalize()、dot() 等)。
什么是uniform?
uniform 是 GLSL 中的一种变量类型,用来从 CPU 向 GPU 传递"全局常量"数据。uniform 变量在着色器程序执行期间保持不变,所有顶点或像素都能访问相同的值,比如变换矩阵、光照参数、时间等,CPU 可以通过 glUniform* 函数(如 glUniformMatrix4fv、glUniform3f)来设置这些值。
如何理解纹理采样中出现的各种问题?
纹理采样是 OpenGL 中从纹理贴图获取颜色值的过程,纹理坐标在顶点着色器中作为顶点属性传入,通过光栅化插值到每个片元,在片元着色器中执行实际采样;当物体距离摄像机较近时,一个纹素对应多个片元,需要双线性或三线性插值来避免像素化效果,当物体距离摄像机较远时,多个纹素对应一个片元,会出现摩尔纹和性能问题,这时需要 mipmap 多级渐远纹理技术,预先计算不同分辨率的纹理层级,根据片元大小自动选择合适的 mipmap 级别,通过空间换时间的方式既提高渲染性能又改善图像质量,OpenGL 提供了 GL_NEAREST(最近邻)、GL_LINEAR(线性插值)、GL_LINEAR_MIPMAP_LINEAR(三线性过滤)等多种采样模式来平衡质量和性能。
LearnOpenGL中具体代码上如何去生成纹理并应用纹理?
LearnOpenGL 中生成和应用纹理的流程是:首先用 glGenTextures() 创建纹理对象,用 glBindTexture(GL_TEXTURE_2D, textureID) 绑定纹理,然后通过 glTexImage2D() 将图像数据上传到 GPU,设置纹理参数如 glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR) 定义过滤和环绕模式,最后在着色器中用 uniform sampler2D textureName 声明纹理,通过 glActiveTexture(GL_TEXTURE0) 和 glBindTexture(GL_TEXTURE_2D, textureID) 绑定到纹理单元,在片元着色器中用 texture(textureName, TexCoords) 进行采样。
创建纹理对象 → 绑定纹理 → 上传图像数据 → 设置参数 → 在着色器中声明 uniform → 绑定到纹理单元 → 在片元着色器中采样,整个过程通过 stb_image 库加载图像文件,通过 VAO/VBO 传递纹理坐标作为顶点属性,最终在片元着色器中结合纹理坐标和纹理数据输出最终颜色。
渲染管线中涉及到哪些坐标系的转换?
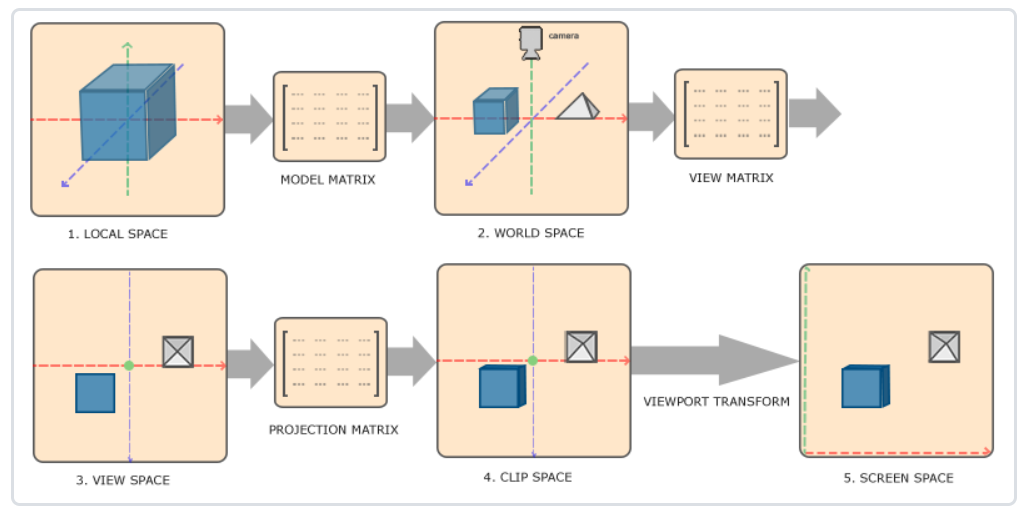
OpenGL 中的坐标系转换分为两个阶段:顶点着色器阶段通过 MVP 矩阵变换将顶点从模型空间转换到裁剪空间,具体是模型矩阵(Model)将顶点从模型空间转换到世界空间,视图矩阵(View)将世界空间转换到视图空间,投影矩阵(Projection)将视图空间转换到裁剪空间,这个过程在顶点着色器中用 gl_Position = projection * view * model * vec4(position, 1.0) 完成;光栅化阶段由 OpenGL 硬件自动进行透视除法(gl_Position.xyz / gl_Position.w)将裁剪空间转换为标准化设备坐标(NDC),然后根据 glViewport() 设置将 NDC 坐标映射到屏幕坐标系,这两个步骤不需要在着色器中编写代码,由 GPU 自动处理,最终完成从 3D 世界坐标到 2D 屏幕坐标的完整变换过程。
光照
在OpenGL中如何从零开始具体实现一个Phong光照模型?
在 OpenGL 中实现 Phong 光照模型需要以下步骤:首先在顶点着色器中处理 MVP 变换,将顶点位置和法线转换到世界空间,通过 out 变量将世界空间位置和法线传递给片段着色器,然后在片段着色器中声明材质和光源的 uniform 变量(如 uniform vec3 lightPos、uniform vec3 lightColor、uniform vec3 albedo),计算光照方向向量 L = normalize(lightPos - FragPos),计算环境光分量 ambient = ambientStrength * lightColor,计算漫反射分量 diffuse = max(dot(normal, L), 0.0) * lightColor,计算镜面反射分量(需要视角方向 V 和反射方向 R),最后在 main 函数中将三个分量相加得到最终颜色 result = (ambient + diffuse + specular) * albedo,通过 uniform 变量从 CPU 传递光源位置、颜色、强度等参数。
模型加载
如何理解网格?在OpenGL中如何具体实现一个网格?
网格是 3D 物体的几何表示,由顶点、边和面组成,在 OpenGL 中实现网格需要定义顶点数据结构(包含位置、法线、纹理坐标等),创建 VAO 和 VBO 存储顶点数据,创建 EBO 存储面索引信息,通过 glVertexAttribPointer() 设置顶点属性格式,用 glDrawElements() 根据索引绘制三角形,对于复杂网格通常使用 Assimp 库加载 3D 模型文件(如 .obj、.fbx),解析顶点和面数据后转换为 OpenGL 可用的格式,最终将 3D 模型的几何信息转换为 GPU 可渲染的数据结构。
一个模型由哪些部分组成?
一个完整的 3D 模型由网格(Mesh)和材质(Material)两部分组成:网格定义了模型的几何形状,包含顶点、边和面等几何元素,决定了物体的基本外形;材质定义了物体表面的光学属性,如金属度、粗糙度、反射率等参数,决定了光线如何与表面相互作用,材质参数可以通过 uniform 变量直接设置,也可以通过纹理贴图提供更丰富的表面细节,纹理是材质参数的实现方式之一,属于材质的一部分,两者结合形成完整的 3D 模型。
高级OpenGL
如何理解深度测试?有何作用?
深度测试发生在片元着色器之后,是光栅化管线的后期阶段,具体顺序为顶点着色器 → 光栅化 → 片元着色器 → 深度测试 → 模板测试 → 混合 → 帧缓冲,深度测试需要片元的最终深度值,这个深度值在光栅化阶段通过顶点深度插值得到,片元着色器可能会修改深度值(通过 gl_FragDepth),所以深度测试必须在片元着色器执行完毕后进行,确保使用最终的深度值进行测试,虽然深度测试在片元着色器之后,但现代 GPU 通常会在片元着色器执行前进行"早期深度测试"(Early Depth Test),如果片元被遮挡就直接跳过片元着色器的计算,提高渲染性能。
如何理解深度冲突?怎么解决?
深度冲突(Z-fighting)是指当两个或多个物体距离相机非常接近时,由于浮点数精度限制,它们的深度值变得几乎相同,导致深度测试结果不稳定,物体表面出现闪烁或交替显示的现象。
具体的解决方法有调整近平面距离(near 值)增大深度精度,使用更大的深度范围;调整物体间距,避免物体过于接近;使用 glPolygonOffset() 添加深度偏移,人为增加物体间的深度差异。
为什么调整近平面距离可以增大深度的精度?
因为深度缓冲区的精度分布不均匀,在近平面附近精度最高,在远平面附近精度最低,OpenGL 使用透视除法将深度值映射到 [0,1] 范围,这个映射是非线性的,在近平面附近深度值变化很敏感(精度高),在远平面附近深度值变化不敏感(精度低)。
如何理解模板测试?模板测试在深度测试之前执行吗?
模板测试是 OpenGL 中用于控制像素绘制的机制,通过比较模板缓冲区中的值与参考值来决定是否绘制片元,类似于深度测试但基于模板值而不是深度值,模板缓冲区为每个像素存储一个模板值,当渲染片元时,GPU 会比较当前片元的模板值与模板缓冲区中对应位置的值,根据设置的测试函数(如 GL_EQUAL、GL_NOTEQUAL 等)决定是否绘制该片元,同时可以更新模板缓冲区的值,模板测试在深度测试之前执行,完整的测试顺序是模板测试 → 深度测试 → 混合,这是因为模板测试通常用于标记特定区域,然后深度测试在这些区域内进行正常的深度比较,模板测试常用于实现镜面反射、阴影、轮廓描边等效果,通过设置不同的模板值和测试函数来控制哪些区域被绘制,哪些区域被丢弃,是高级渲染技术的重要工具。
如何理解混合?具体如何实现?
混合是 OpenGL 中用于处理透明物体的技术,通过将当前片元的颜色与帧缓冲区中已存在的颜色进行数学运算来产生最终的显示颜色。首先启用混合 glEnable(GL_BLEND),然后设置混合函数如 glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA)(最常用的透明混合),在片段着色器中输出带 alpha 值的颜色 FragColor = vec4(color, alpha),OpenGL 会自动根据混合函数计算最终颜色。
面剔除是什么?有何作用?
面剔除是 OpenGL 中用于优化渲染性能的技术,通过丢弃不可见的三角形面来减少不必要的渲染计算。面剔除基于三角形的顶点顺序(顺时针或逆时针)来判断三角形的朝向,当启用面剔除时(glEnable(GL_CULL_FACE)),OpenGL 会丢弃背向相机的三角形(背面剔除)或面向相机的三角形(正面剔除),只渲染朝向相机的面。
如何理解帧缓冲FBO?为什么需要帧缓冲?
帧缓冲(FBO)是 OpenGL 中用于离屏渲染的机制,它允许我们将渲染结果输出到纹理或渲染缓冲区,而不是直接输出到屏幕,FBO 是一个虚拟的渲染目标,可以附加颜色纹理、深度纹理、模板纹理等,当绑定 FBO 时,所有的渲染操作都会输出到 FBO 中,而不是默认的帧缓冲区(屏幕),通过 glFramebufferTexture2D() 将纹理附加到 FBO,通过 glBindFramebuffer(GL_FRAMEBUFFER, fboID) 切换渲染目标,FBO 主要用于后处理效果、阴影映射、延迟渲染等技术,比如要实现模糊效果,需要先将场景渲染到 FBO 的纹理中,然后对这个纹理进行模糊处理,最后再渲染到屏幕,FBO 还用于多遍渲染,将中间结果存储起来供后续 Pass 使用,实现复杂的渲染效果,是现代图形渲染中实现复杂效果的基础技术。
(颜色缓冲、深度缓冲、模板缓冲等都是帧缓冲的组成部分,帧缓冲是管理这些缓冲区的容器)
如何理解立方体贴图?为什么需要立方体贴图?
立方体贴图是 OpenGL 中的一种特殊纹理类型,由六个 2D 纹理组成,形成一个立方体的六个面,用于存储 3D 环境信息。
立方体贴图主要用于环境映射,包括天空盒(Skybox)显示远处的环境,环境反射让物体表面反射周围环境,环境折射实现透明物体的折射效果,阴影映射中的点光源阴影等,它能够完整地表示 3D 空间中的环境信息。
如何理解几何着色器?有何作用?
几何着色器是 OpenGL 渲染管线中的一个可选阶段,位于顶点着色器和光栅化之间,可以对图元进行动态生成、修改或删除。
顶点着色器处理原始顶点数据 → 曲面细分控制着色器和曲面细分计算着色器动态细分几何体(可选阶段)→ 图元装配将顶点组合成图元(点、线、三角形)→ 几何着色器对图元进行修改、删除或生成新图元(可选阶段)→ 光栅化将图元转换为片元 → 片段着色器计算每个片元的颜色 → 模板测试 → 深度测试 → 混合 → 帧缓冲输出,其中曲面细分着色器用于动态调整几何复杂度,几何着色器用于图元的动态处理,两者都是可选的着色器阶段,可以根据需要启用或禁用。
实例化是什么?为什么可以支持大量的数据计算?底层原理是什么?
实例化是 OpenGL 中用于高效渲染大量相似物体的技术,通过单次绘制调用渲染同一网格的多个副本,每个副本可以有不同的变换、颜色等属性,实例化支持大量数据计算的原因是将"多次绘制调用"简化为"单次绘制调用",传统方式渲染 1000 个物体需要 1000 次 glDrawArrays() 调用,每次都有 CPU-GPU 通信开销,而实例化只需要 1 次调用就能渲染所有物体,大幅减少了 CPU 开销和 draw call 数量,底层原理是通过 glVertexAttribDivisor(attr, 1) 设置某些顶点属性为"每实例推进",而不是每顶点推进,GPU 会自动复制网格几何数据 N 次,但每个副本使用不同的实例属性(如变换矩阵、颜色),在顶点着色器中可以通过 gl_InstanceID 或直接接收实例属性来区分每个实例,实现批量渲染,性能优势是将 CPU 的重复工作转移到 GPU 的并行处理能力上,GPU 可以同时处理多个实例的渲染,充分利用 GPU 的并行计算能力,特别适合渲染大量相似物体(如草地、石头、粒子等),是现代图形渲染中提高性能的重要技术。
高级光照
如何理解gamma校正?
Gamma 校正是用于处理显示器非线性响应特性的技术,确保图像在不同设备上显示一致。Gamma 校正的底层原理是显示器对输入信号的响应是非线性的,通常遵循 Gamma 2.2 曲线,这意味着显示器会将暗部压缩(让暗的东西更暗)、亮部拉伸(让亮的东西更亮),导致图像显示失真,而我们在渲染管线中进行光照计算时使用的是线性空间,光照强度是线性的,这样计算出来的结果在物理上是正确的,但由于显示器会将线性输入进行非线性处理,如果我们直接输出线性光照结果,显示器会让暗部更暗、亮部更亮,导致最终显示效果失真,为了补偿显示器的非线性响应,我们在输出前进行逆 Gamma 变换(pow(color, 1.0/2.2)),这样显示器处理后的结果就是正确的线性光照效果,Gamma 校正主要针对 RGB 颜色通道的亮度值,确保光照、颜色、阴影等所有亮度相关的计算在显示器上正确显示,是保证图像质量的关键技术。
如何理解点阴影?
点阴影是用于点光源的阴影技术,因为点光源向所有方向发射光线,所以需要从光源位置向六个方向(上下左右前后)渲染场景,生成立方体深度贴图。
点阴影使用立方体贴图存储六个方向的深度信息,从光源位置渲染整个场景到立方体贴图的六个面,每个面记录该方向上最近物体的深度值,在正常渲染时,将片元位置转换到光源空间,计算片元到光源的距离,与立方体贴图中对应方向的深度值比较,判断是否被遮挡。
什么是HDR?
HDR(高动态范围)是一种图像处理技术,能够表示更大范围的亮度值,超越传统显示器能显示的范围。现实世界的光照强度范围远超显示器能显示的范围(0-1),HDR 使用浮点纹理存储更大的亮度值,比如太阳的亮度可能是 10.0 或更高,而显示器只能显示 1.0,HDR 允许我们存储这些超亮值。
法线贴图的概念是什么?底层原理呢?
法线贴图是一种纹理技术,用于在不增加几何复杂度的情况下增加表面细节,通过改变表面法线方向来模拟凹凸不平的效果。法线贴图存储的是表面法线的方向信息,而不是颜色信息,每个纹素存储一个法线向量(通常是 RGB 三个分量),在片段着色器中用这个法线替换原始的顶点法线进行光照计算,从而产生凹凸不平的视觉效果。
泛光的概念是什么?
泛光(Bloom)是一种后处理效果,模拟明亮物体在眼睛中产生的光晕效果,让超亮的区域"泛"出柔和的光晕。泛光基于 HDR(高动态范围)渲染,现实世界的光照强度范围远超显示器能显示的范围(0-1),泛光提取超过阈值(如 1.0)的"超亮"部分,对这些亮部进行模糊处理,然后叠加回原场景,模拟人眼对强光的视觉反应。
如何理解SSAO?
SSAO(屏幕空间环境光遮蔽)是一种后处理技术,用于模拟小尺度的阴影效果,增加场景的深度感和真实感。SSAO 在每个像素的法线方向生成一个半球采样核,检查采样点的深度值,如果采样点被其他几何体遮挡,就累计遮蔽值,最终计算环境光遮蔽因子,被遮挡的区域会变暗,增加明暗对比。
PBR
PBR具体来说有哪些组成部分?
PBR(基于物理的渲染)主要由材质参数(包括 albedo 基础反射率、metallic 金属度、roughness 粗糙度、normal 法线、ao 环境光遮蔽等参数,这些参数定义了表面的物理特性)、BRDF 模型(基于物理的双向反射分布函数,通常使用 Cook-Torrance 模型,包含法线分布函数 D、几何遮蔽函数 G、菲涅尔函数 F 三个核心函数)、能量守恒(确保反射能量不超过入射能量,漫反射和镜面反射分量严格遵循物理规律,金属材质几乎无漫反射)、环境光照 IBL(基于图像的照明,包括辐照度贴图、预滤波环境贴图、BRDF 查找表等)和线性空间渲染(所有计算在线性空间进行,最后进行 Gamma 校正,确保物理计算的准确性)组成,共同实现基于物理的真实渲染效果。
具体来说有什么用?
BR 光照模型基于 PBR 材质、BRDF 反射函数和 IBL 环境贴图三个部分组成:PBR 材质的输入包括 albedo(基础反射率)、metallic(金属度)、roughness(粗糙度)、normal(法线)、ao(环境光遮蔽),输出表面物理属性,作用是定义物体表面的物理特性,决定光线如何与表面相互作用;BRDF 反射函数的输入是入射光线方向、出射光线方向、表面法线、材质参数,输出反射强度(标量值),作用是计算给定方向下的反射强度,模拟不同材质的反射特性;IBL 环境贴图的输入是环境 HDR 贴图,输出辐照度贴图(漫反射环境光)、预滤波环境贴图(镜面反射环境光)、BRDF 查找表,作用是提供环境光照信息,实现基于图像的照明,包括漫反射和镜面反射的环境光贡献,三者结合实现完整的 PBR 光照模型。
Unity Shader
什么是ShaderLab?
ShaderLab是Unity的着色器配置语言,用于组织和描述Shader的结构和属性;它定义了Properties(材质面板中可调节的参数如贴图、颜色、数值),SubShader(渲染管线的备选方案,按硬件能力排序),Pass(具体的渲染通道,包含顶点/片元着色器代码和渲染状态),Tags(给渲染引擎的元数据如RenderType、Queue等);ShaderLab本身不在GPU上执行,而是作为"外壳"承载真正的HLSL着色代码,Unity会根据ShaderLab的描述生成对应的渲染指令;它提供了跨平台的Shader管理能力,让开发者可以用统一的语法描述不同图形API(DirectX、OpenGL、Metal等)的Shader,是Unity Shader开发的基础框架。
HLSL是什么?
HLSL(High-Level Shading Language)是微软开发的高级着色器语言,用于编写在GPU上执行的着色器程序;在Unity中,HLSL是真正跑在GPU上的着色代码,写在CGPROGRAM或HLSLPROGRAM代码块中,包含顶点着色器、片元着色器、计算着色器等;Unity对HLSL进行了扩展,提供了大量内置函数和宏(如UnityObjectToClipPos、SAMPLE_DEPTH_TEXTURE等),以及跨平台编译支持,将HLSL代码编译到不同的图形API(DirectX、OpenGL、Metal、Vulkan)。
Surface Shader和Shader Graph分别是什么?
Surface Shader是Unity内置渲染管线下的高层Shader开发工具,让你只需定义一个surface function来描述表面属性(如Albedo、Normal、Emission、Metallic、Smoothness),Unity会自动生成包含完整光照、阴影、前向/延迟渲染等Pass的HLSL代码,开发效率高但自定义程度较低,且只支持Built-in渲染管线。
Shader Graph是Unity URP/HDRP的可视化Shader编辑器,通过连接各种节点(纹理采样、数学运算、光照模型等)来定义着色逻辑,Unity实时生成对应的HLSL代码,深度集成现代渲染管线,支持自定义函数节点和自定义Pass,迭代快、协作友好但复杂自定义时仍有限制。
Unity Shader中具体有哪些可以实现性能优化的手段?
使用GPU Instancing批量渲染大量相同对象,减少DrawCall数量;启用SRP Batcher将使用相同Shader变体的对象合并批次,减少CPU开销;合理使用精度类型(fixed/half/float),移动端优先使用fixed和half;避免在片元着色器中使用分支语句,用数学函数替代条件判断;优化纹理采样,使用合适的MIP级别和压缩格式,减少带宽占用;使用变体剔除移除未使用的Shader变体,减少内存占用;合理设置渲染状态,避免不必要的深度测试和混合操作;使用LOD系统根据距离选择不同精度的Shader。
什么是计算着色器?具体如何使用?
Compute Shader是GPU的通用计算着色器,不参与图形渲染管线,而是直接在GPU上执行并行计算任务,使用HLSL编写,通过numthreads定义线程组大小,用StructuredBuffer进行数据读写,支持Barrier同步线程;典型应用包括粒子系统计算、GPU Transform、物理模拟、图像处理、几何处理等,核心优势是充分利用GPU并行计算能力,将计算密集型任务从CPU转移到GPU,显著提升性能。
首先在C#脚本中创建ComputeBuffer存储数据,找到Compute Shader的kernel(计算核心),设置输入参数和缓冲区;然后在Update中调用Dispatch执行计算,指定线程组数量;最后将计算结果传递给渲染Shader或读取回CPU;具体流程是:创建StructuredBuffer存储输入输出数据,用FindKernel找到要执行的kernel,用SetBuffer、SetFloat等设置参数,用Dispatch启动GPU计算,计算完成后数据自动更新到缓冲区,可以在渲染Shader中采样或通过GetData读取回CPU。
Compute Shader是用HLSL编写的GPU计算程序,通过C#创建ComputeBuffer管理数据结构并调用计算流程,其特殊性在于运行在GPU上利用并行计算能力,且计算完成后数据可以直接传递给渲染管线的Shader使用,实现GPU计算和GPU渲染的无缝连接,避免了CPU和GPU之间的数据传输开销,特别适合粒子系统、物理模拟、图像处理等需要大量并行计算的任务,既能充分利用GPU的计算能力,又能将计算结果直接用于渲染。
FrameDebugger是什么?有何作用?
FrameDebugger是Unity内置的渲染调试工具,用于逐帧分析渲染过程,帮助开发者定位渲染问题和优化性能;它的主要作用包括:查看每个DrawCall的详细信息,包括渲染状态、Shader变体、渲染目标、深度/模板缓冲等;分析渲染管线中的每个Pass,了解渲染顺序和状态变化;检测过绘(Overdraw)问题,查看哪些像素被重复渲染;调试渲染状态错误,如深度测试、混合模式、面剔除等设置问题;分析Shader变体使用情况,查看哪些变体被实际使用;检查渲染目标(RenderTexture)的内容和状态;优化渲染性能,通过分析DrawCall数量和渲染状态来找出性能瓶颈;FrameDebugger是Shader开发和渲染优化的重要工具,能帮助开发者深入理解渲染过程并解决复杂的渲染问题。
这里我们也大致介绍一下ECS:
ECS(Entity-Component-System)是一种软件架构模式,将游戏对象分解为三个核心概念:Entity(实体)是纯ID标识符,不包含任何数据或逻辑;Component(组件)是纯数据结构,存储实体的属性信息,如位置、速度、健康值等;System(系统)是纯逻辑,处理具有特定组件组合的实体,如移动系统处理所有具有位置和速度组件的实体;ECS的优势包括:数据局部性好,相同类型的数据存储在连续内存中,提高缓存命中率;并行处理能力强,系统可以独立并行执行;内存效率高,只存储必要的数据;易于扩展,通过添加组件和系统来增加功能;Unity的ECS实现包括Job System用于并行处理,Burst编译器将C#代码编译为高性能原生代码,适合大规模实体模拟和高性能计算场景。
一般说到ECS也绕不开Burst编译器和Job System:
Job System是Unity的并行处理框架,允许将计算任务分解为多个独立的Job,这些Job可以在多个CPU核心上并行执行,显著提升性能;它通过IJob、IJobForEach、IJobParallelFor等接口定义并行任务,自动处理线程调度和同步,避免手动管理线程的复杂性;Burst编译器是Unity的高性能编译器,将C#代码编译为优化的原生代码,接近C++的性能水平,特别适合数学计算、向量运算、循环等计算密集型任务;它通过静态分析确保代码安全,自动向量化优化,减少GC压力。
Unreal
最后我们来大致聊一聊虚幻引擎的渲染系统:
如何理解Nanite技术?
Nanite解决了传统实时渲染中高精度几何体处理的根本瓶颈问题:传统GPU渲染管线受限于固定的三角形处理能力和内存带宽,当模型包含数百万甚至数亿三角形时,会导致性能崩溃或无法渲染,开发者必须手工创建多个LOD(细节层次)版本来降低几何体复杂度,这不仅耗费大量美术资源,还会在LOD切换时产生明显的视觉突变。
Nanite通过虚拟化几何体存储架构和软件光栅化技术彻底解决了这个问题:它将传统基于三角形数量的渲染限制转换为基于像素密度的渲染,通过将几何体数据分解成小聚类并构建层次结构,实现按需加载和流式传输;同时使用计算着色器实现软件光栅化,绕过硬件光栅化器的三角形数量限制;最终通过可见性驱动的渲染管线,只处理屏幕空间内可见的几何体,实现了从数十亿三角形到几个三角形的自动LOD控制,让开发者可以直接使用ZBrush、Maya等软件的原始高精度模型,无需任何手工优化,在保证实时性能的同时达到电影级的几何体细节质量。
Lumen全局光照比起其他渲染系统的光照来说优势在哪里?
Lumen通过多层次实时光线追踪架构,将传统需要离线预计算的全局光照转换为实时计算,彻底解决了传统光照系统的根本瓶颈:传统方法依赖静态光照烘焙,一旦场景改变就需要重新计算数小时,且无法支持动态光源和移动物体的间接光照效果,导致游戏中的光照缺乏真实感;而Lumen通过屏幕空间追踪、距离场追踪和硬件光线追踪的混合方案,实现了完全动态的间接光照和反射效果,支持光源移动、物体移动、昼夜循环等复杂场景变化,同时无需任何预计算时间,修改场景后立即看到最终效果,在保证实时性能的同时达到了接近离线渲染的光照质量。
首先使用屏幕空间追踪处理近距离的间接光照,利用已渲染的深度和法线信息进行快速光线追踪;然后通过距离场追踪覆盖屏幕外的几何体,使用球体步进算法在预计算的距离场中追踪光线;最后在支持的硬件上使用硬件光线追踪处理远距离的高精度光照。同时,Lumen采用表面缓存系统智能存储和更新间接光照数据,通过辐射度传播算法模拟真实的光线反弹效果,结合时域重投影技术复用前一帧的计算结果,并使用多分辨率渲染策略在不同距离使用不同精度,最终实现了将传统需要离线计算的全局光照转换为实时渲染,在保证性能的同时达到接近离线渲染的光照质量。
VSM又是什么?
VSM(Virtual Shadow Maps)虚拟阴影映射是一种革命性的阴影渲染技术,通过虚拟化存储和按需分配的方式管理阴影数据:传统阴影映射需要为每个光源创建完整的阴影贴图,无论这些阴影数据是否被使用都会占用大量内存,导致大型场景中内存爆炸、远处阴影质量差、性能不稳定等问题;而VSM采用类似虚拟内存的管理方式,只存储实际需要的阴影数据,通过阴影页表和流式加载系统,根据阴影的重要性和可见性动态分配内存资源,重要区域使用高分辨率阴影,次要区域使用适当精度,实现了内存使用减少90%以上、性能与场景复杂度解耦、整体阴影质量均衡的突破性效果。
VSM的底层原理基于分层存储和智能管理:系统将阴影数据分解成不同分辨率的阴影页,构建类似虚拟内存的页表结构,通过重要性计算算法评估每个阴影页的价值(基于距离、屏幕空间大小、光源重要性等因素),使用LRU缓存和流式加载技术按需加载和卸载阴影数据,同时结合预测性加载算法根据玩家移动方向提前准备阴影资源,最终通过压缩算法和GPU内存管理实现高效的阴影数据存储和访问,让阴影渲染从传统的固定分配模式转变为智能的动态管理模式。
这东西其实从17号开始写的,但是一直写到了现在,已经18号了...