NLP 2025全景指南:从分词到128专家MoE模型,手撕BERT情感分析实战(第四章)
引言
自然语言处理(Natural Language Processing, NLP)是人工智能(AI)中一个激动人心的领域,专注于让机器理解、解释和生成人类语言。无论是智能助手回答你的问题,还是社交媒体分析用户情绪,NLP都在背后发挥关键作用。它桥接了人类沟通与机器理解的鸿沟,使技术交互更加自然、个性化和高效。
在本章中,我们将深入探讨NLP的核心概念、关键技术和广泛应用。我们将从基础知识开始,介绍文本预处理、词嵌入、序列模型和Transformer架构等技术。然后,我们将展示NLP在情感分析、机器翻译、聊天机器人等领域的实际应用,并通过一个使用BERT模型进行情感分析的实践示例,展示如何将理论应用于实践。此外,我们将探讨2025年NLP的最新趋势,包括多模态NLP、大型语言模型(LLMs)的进展以及伦理问题。
什么是自然语言处理?
自然语言处理是人工智能的一个分支,研究如何让计算机理解、处理和生成人类语言(包括文本和语音)。NLP结合了语言学、计算机科学和机器学习技术,旨在让机器能够从非结构化数据(如电子邮件、社交媒体帖子)中提取意义并生成有意义的响应。
NLP的历史
NLP的起源可以追溯到20世纪50年代,早期研究集中在基于规则的系统,如语法解析器。20世纪90年代,统计方法和机器学习开始主导NLP领域。2010年代,深度学习的兴起(特别是Transformer架构)推动了NLP的突破,催生了BERT、GPT等模型。2025年,NLP市场规模预计达到3910亿美元(Stanford AI Index),广泛应用于医疗、金融和客户服务等领域。
NLP与AI、机器学习的关系
- 人工智能(AI):广义概念,指机器执行需要人类智能的任务。
- 机器学习(ML):AI的子领域,专注于从数据中学习。
- 深度学习(DL):ML的子领域,使用多层神经网络。
- 自然语言处理(NLP):AI的子领域,专注于语言处理,常依赖深度学习技术。
NLP的关键概念
1. 文本预处理
文本预处理是NLP的第一步,旨在将原始文本转换为适合模型处理的格式。常见技术包括:
- 分词(Tokenization):将文本分割成单词、子词或标点。例如,“我爱NLP”被分为[“我”, “爱”, “NLP”]。
- 词干提取(Stemming):将词汇简化为词根形式,如“running”变为“run”。
- 词形还原(Lemmatization):考虑上下文,将词汇简化为基本形式,如“better”变为“good”。
- 停用词移除:移除常见但无意义的词,如“的”、“是”。
以下是一个简单的分词示例:
from nltk.tokenize import word_tokenize
import nltk
nltk.download('punkt')text = "我爱学习自然语言处理!"
tokens = word_tokenize(text)
print("分词结果:", tokens)
输出:
分词结果: ['我', '爱', '学习', '自然', '语言', '处理', '!']
2. 词嵌入
词嵌入将单词表示为向量,捕捉语义关系。常见方法包括:
- Word2Vec:通过神经网络学习单词的分布式表示,捕捉相似性(如“国王”和“女王”向量接近)。
- GloVe:基于单词共现统计生成词向量。
- BERT:使用双向Transformer生成上下文相关的词嵌入,考虑单词在句子中的前后文。
图表说明:此处可插入一个词嵌入的二维可视化图,展示“国王”、“女王”、“男人”、“女人”之间的语义关系。
3. 序列模型
序列模型处理具有时间或顺序依赖的数据,如文本。常见模型包括:
- 循环神经网络(RNN):通过循环连接处理序列,但易受梯度消失影响。
- 长短期记忆网络(LSTM):通过门控机制保留长期依赖,适合长序列。
- 门控循环单元(GRU):LSTM的简化版本,计算效率更高。
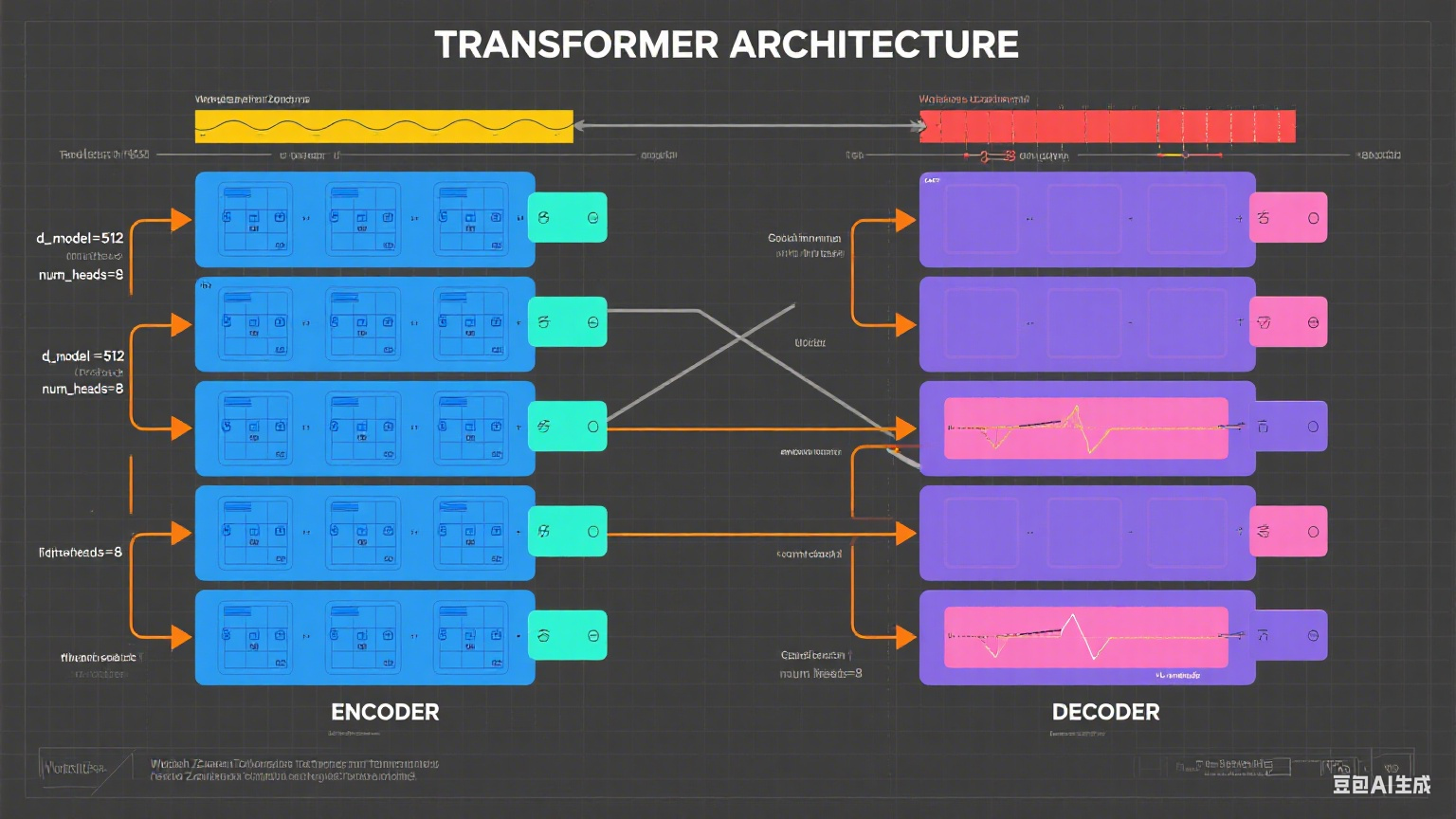
4. 注意力机制和Transformer
注意力机制允许模型根据上下文动态关注输入序列的不同部分。Transformer架构完全基于注意力机制,取代了RNN,显著提高了效率和性能。其核心组件包括:
- 自注意力(Self-Attention):计算输入中每个单词与其他单词的相关性。
- 多头注意力(Multi-Head Attention):并行处理多个注意力机制,捕捉不同语义关系。
- 编码器-解码器结构:编码器处理输入,解码器生成输出。
Transformer催生了BERT、GPT、Llama-4等模型,广泛应用于翻译、生成和分类任务。
图表说明:下面是一个Transformer架构图,展示编码器和解码器的结构:
NLP的应用
NLP技术支持多种实际应用,以下是几个主要领域:
| 应用 | 描述 | 示例 |
|---|---|---|
| 情感分析 | 从文本中提取情绪或意见,用于社交媒体监控、客户反馈分析。 | 分析微博评论的情绪 |
| 机器翻译 | 将文本从一种语言翻译成另一种语言。 | Google Translate、百度翻译 |
| 聊天机器人 | 理解用户查询并生成响应,应用于客服和教育。 | 小冰、阿里云智能客服 |
| 文本摘要 | 生成原文的简短版本,保留核心信息。 | 新闻摘要、研究论文摘要 |
| 命名实体识别(NER) | 识别文本中的人名、地名、组织名等实体。 | 从新闻中提取公司名称 |
实践示例:使用BERT进行情感分析
情感分析是NLP的经典任务,用于判断文本的情绪(如正面、负面)。我们将使用Hugging Face的Transformers库和预训练的BERT模型进行情感分析。
步骤
-
安装必要的库:
pip install transformers torch -
导入模块:
from transformers import pipeline -
创建情感分析管道:
sentiment_pipeline = pipeline("sentiment-analysis") -
分析文本情感:
texts = ["我爱学习自然语言处理!","这个产品太差了,完全不满意。","今天的天气很好,心情也不错!" ] results = sentiment_pipeline(texts) for text, result in zip(texts, results):print(f"文本: {text}\n情感: {result['label']}, 置信度: {result['score']:.4f}\n") -
输出示例:
文本: 我爱学习自然语言处理! 情感: POSITIVE, 置信度: 0.9998文本: 这个产品太差了,完全不满意。 情感: NEGATIVE, 置信度: 0.9987文本: 今天的天气很好,心情也不错! 情感: POSITIVE, 置信度: 0.9992
结果分析
BERT模型能够准确识别文本的情感,置信度通常高于0.99。Hugging Face的pipeline简化了模型加载和推理过程,适合快速原型开发。您可以进一步微调BERT以适应特定领域(如中文社交媒体评论)。
2025年NLP的趋势
2025年,NLP领域呈现以下趋势,反映了技术的快速发展和广泛影响:
1. 多模态NLP
多模态NLP处理文本、图像、音频等多种数据类型。例如,Meta的Llama-4-Maverick模型支持文本和图像输入,应用于视觉问答和多媒体生成。这种能力使AI系统更接近人类的多感官理解。
2. 大型语言模型的进展
大型语言模型(如GPT-4、Llama-4)在2025年更加高效,支持更复杂的任务。它们通过迁移学习和少样本学习,减少了对大量标注数据的需求。例如,Llama-4-Maverick的混合专家(MoE)架构包含128个专家和17亿活跃参数,显著提高了性能。
3. 实时情感分析的改进
实时情感分析技术能够检测复杂情绪(如讽刺、反讽),并与商业智能工具集成,提供即时的客户行为洞察。例如,阿里巴巴的客户服务系统利用NLP分析用户反馈,优化服务策略。
4. 伦理问题
随着NLP的普及,偏见、公平性和隐私保护成为关注焦点。研究表明,67%的企业面临模型准确性和偏见问题(StartUs Insights)。开发人员正在探索去偏方法和隐私保护技术(如差分隐私)。
5. 迁移学习和少样本学习
迁移学习允许使用预训练模型适应新任务,少样本学习使模型在有限数据下表现良好。这些技术降低了NLP应用的开发成本,扩展了其在小众领域的应用。
6. NLP在医疗和金融中的应用
- 医疗:NLP处理临床记录和研究论文,提高诊断准确性和个性化治疗。例如,百度健康使用NLP分析患者数据。
- 金融:NLP应用于欺诈检测和市场情绪分析,如蚂蚁集团的智能风控系统。
7. AI代理和自动化
NLP是AI代理的核心,支持自主任务执行。2025年,AI代理(如Microsoft 365 Copilot)在客服和内容生成中广泛应用,提高效率。
结论
本章介绍了自然语言处理的基础知识、核心技术和广泛应用。我们从文本预处理、词嵌入到Transformer架构,探讨了NLP的理论基础,并通过一个BERT情感分析示例展示了实践方法。我们还分析了2025年的NLP趋势,包括多模态NLP、大型语言模型的进展和伦理问题。这些趋势表明,NLP正在推动AI向更智能、包容和负责任的方向发展。
下一章将探讨计算机视觉,介绍如何让机器“看到”世界,涵盖图像识别、物体检测等技术。
参考资料(仅供背景参考,非直接引用):
- Stanford AI Index 2025
- StartUs Insights: NLP Market Report 2025
- Hugging Face: Transformers Documentation