深度学习-卷积神经网络CNN-AlexNet
在深度学习的发展历程中,卷积神经网络(CNN)扮演着举足轻重的角色,而 AlexNet 作为 CNN 发展史上的一个里程碑式模型,具有重大的意义和影响力。
2012年,AlexNet横空出世。它首次证明了学习到的特征可以超越手工设计的特征。
AlexNet 由 Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 提出,并在当年的 ImageNet 大规模视觉识别挑战赛(ILSVRC)中以显著的优势取得了冠军,推动了深度学习在计算机视觉领域的快速发展,引发了深度学习在各个领域的广泛关注和应用。
它一举打破了计算机视觉研究的现状!
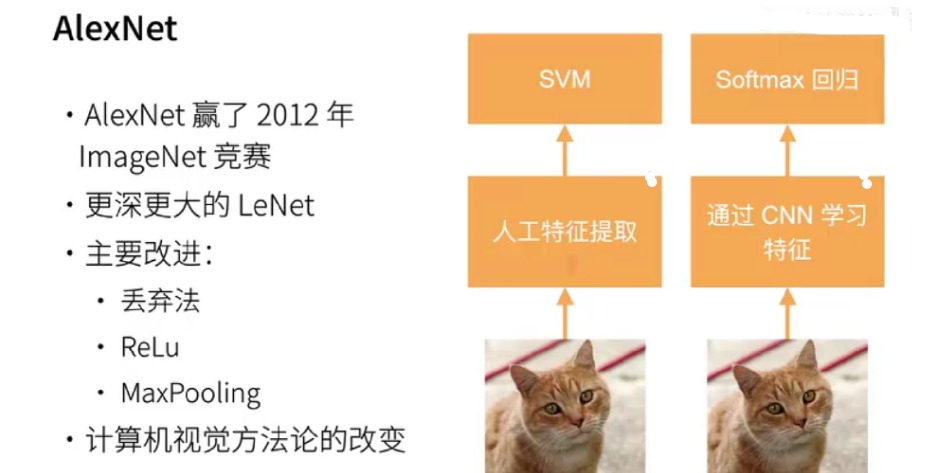
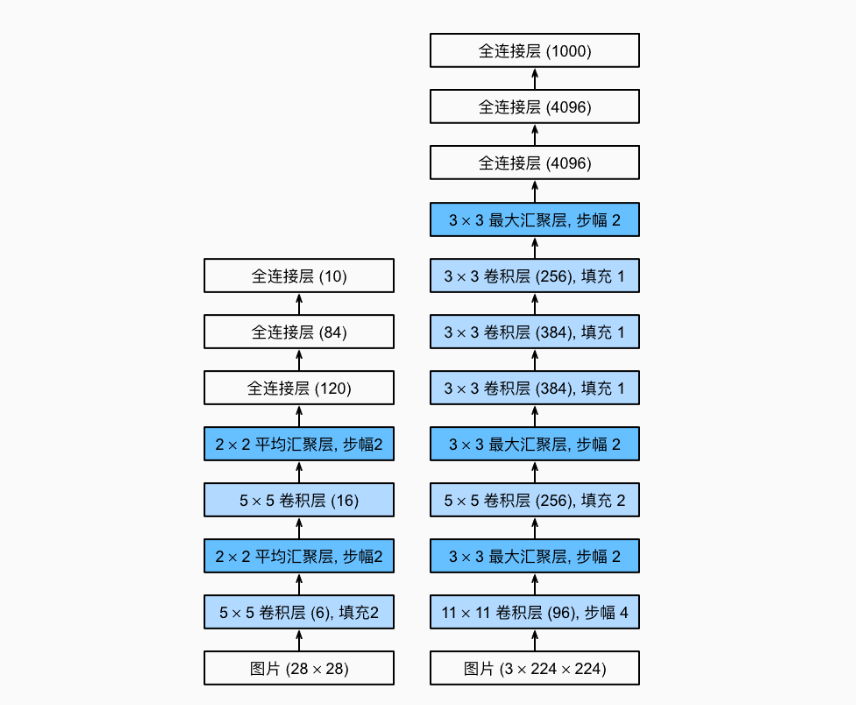
AlexNet和LeNet的设计理念非常相似,但也存在显著差异:
AlexNet比相对较小的LeNet5要深得多。
AlexNet由八层组成:五个卷积层、两个全连接隐藏层和一个全连接输出层。
AlexNet使用ReLU而不是sigmoid作为其激活函数。
1. 网络结构组成
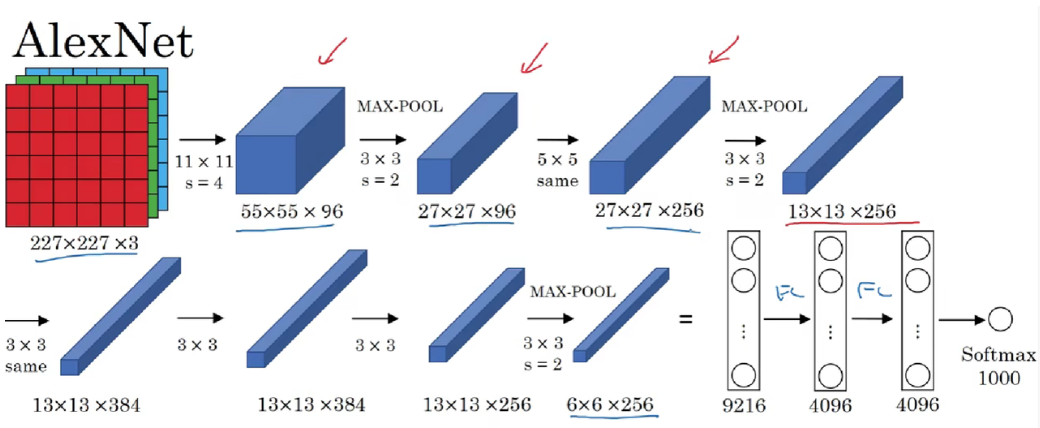
输入层 :接收 227×227×3 的彩色图像数据,与当时 ImageNet 数据集中图像的尺寸和颜色通道相匹配。
卷积层 1(C1):包含 96 个 11×11 的卷积核,步长为 4。这些卷积核用于提取图像的边缘、纹理等低级特征。每个卷积核在输入图像上滑动,进行卷积操作,产生 96 个特征图,每个特征图的大小为 55×55。较大的卷积核尺寸使得模型能够覆盖较大的感受野,捕捉到图像中的较大结构特征。
池化层 1(P1):采用最大池化,池化窗口大小为 3×3,步长为 2。对 C1 层输出的 96 个特征图分别进行池化操作,将每个特征图的大小缩小为 27×27。最大池化通过取池化窗口内的最大值,保留了特征图中的显著特征,同时降低了特征图的空间分辨率,减少了计算量和参数数量,增强了模型对图像的平移、缩放等变化的鲁棒性。
卷积层 2(C2):包含 256 个 5×5 的卷积核。每个卷积核与 P1 层的部分特征图相连,进行卷积操作,产生 256 个特征图,每个特征图的大小为 27×27。这一层进一步提取更高级的特征,如局部纹理的组合、形状等特征。
池化层 2(P2):同样采用最大池化,池化窗口大小为 3×3,步长为 2。对 C2 层输出的 256 个特征图进行池化操作,得到 256 个 13×13 的特征图。再次缩小特征图尺寸,提取更具有语义信息的特征。
卷积层 3(C3):包含 384 个 3×3 的卷积核。每个卷积核与 P2 层的全部 256 个特征图相连,进行卷积操作,产生 384 个特征图,每个特征图的大小为 13×13。使用较小的卷积核尺寸可以更精细地提取特征,增加模型的深度和复杂度。
卷积层 4(C4):包含 384 个 3×3 的卷积核。每个卷积核与 C3 层的全部 384 个特征图相连,进行卷积操作,产生 384 个特征图,每个特征图的大小为 13×13。这一层继续深入提取更高级、更抽象的特征。
卷积层 5(C5):包含 256 个 3×3 的卷积核。每个卷积核与 C4 层的全部 384 个特征图相连,进行卷积操作,产生 256 个特征图,每个特征图的大小为 13×13。这一层将特征进一步整合和抽象,为后续的全连接层做准备。
全连接层 1(FC1):包含 4096 个神经元,与 C5 层输出的 256×13×13 特征图进行全连接。全连接层的作用是将卷积层提取到的高级特征进行全局的组合和抽象,提取更具语义意义的特征表示。
全连接层 2(FC2):包含 4096 个神经元,与 FC1 层的 4096 个神经元全连接。进一步对特征进行整合和抽象,增强模型的非线性拟合能力。
输出层(FC3):包含 1000 个神经元,对应 ImageNet 数据集中的 1000 个类别。使用 softmax 激活函数计算每个类别的概率分布,输出图像属于各个类别的预测概率。
2. 激活函数与训练
AlexNet 中采用了 ReLU 激活函数,它解决了传统激活函数(如 sigmoid、tanh)在深层网络训练中出现的梯度消失问题,加速了网络的训练过程。ReLU 激活函数在正区间具有恒等映射的特性,使得梯度能够更有效地反向传播,提高了模型的收敛速度。
在训练过程中,使用了随机梯度下降(SGD)优化算法,并引入了 dropout 技术来防止过拟合。Dropout 在训练时随机丢弃一部分神经元的输出,使得模型在每次迭代时只能依赖部分神经元进行学习,从而增强了模型的泛化能力。
3. 代码实现
代码来自《动手学深度学习》
import torch
from torch import nn
from d2l import torch as d2lnet = nn.Sequential(# 这里使用一个11*11的更大窗口来捕捉对象。# 同时,步幅为4,以减少输出的高度和宽度。# 另外,输出通道的数目远大于LeNetnn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),# 使用三个连续的卷积层和较小的卷积窗口。# 除了最后的卷积层,输出通道的数量进一步增加。# 在前两个卷积层之后,汇聚层不用于减少输入的高度和宽度nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Flatten(),# 这里,全连接层的输出数量是LeNet中的好几倍。使用dropout层来减轻过拟合nn.Linear(6400, 4096), nn.ReLU(),nn.Dropout(p=0.5),nn.Linear(4096, 4096), nn.ReLU(),nn.Dropout(p=0.5),# 最后是输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000nn.Linear(4096, 10))我们构造一个高度和宽度都为224的单通道数据,来观察每一层输出的形状。
可以看出,它与AlexNet架构相匹配。
X = torch.randn(1, 1, 224, 224)
for layer in net:X=layer(X)print(layer.__class__.__name__,'output shape:\t',X.shape)输出:
Conv2d output shape: torch.Size([1, 96, 54, 54])
ReLU output shape: torch.Size([1, 96, 54, 54])
MaxPool2d output shape: torch.Size([1, 96, 26, 26])Conv2d output shape: torch.Size([1, 256, 26, 26])
ReLU output shape: torch.Size([1, 256, 26, 26])
MaxPool2d output shape: torch.Size([1, 256, 12, 12])Conv2d output shape: torch.Size([1, 384, 12, 12])
ReLU output shape: torch.Size([1, 384, 12, 12])Conv2d output shape: torch.Size([1, 384, 12, 12])
ReLU output shape: torch.Size([1, 384, 12, 12])Conv2d output shape: torch.Size([1, 256, 12, 12])
ReLU output shape: torch.Size([1, 256, 12, 12])
MaxPool2d output shape: torch.Size([1, 256, 5, 5])Flatten output shape: torch.Size([1, 6400])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])Linear output shape: torch.Size([1, 10])读取数据集:
batch_size = 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)对 AlexNet 进行训练:
lr, num_epochs = 0.01, 10
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())输出:
loss 0.331, train acc 0.878, test acc 0.883
3941.8 examples/sec on cuda:0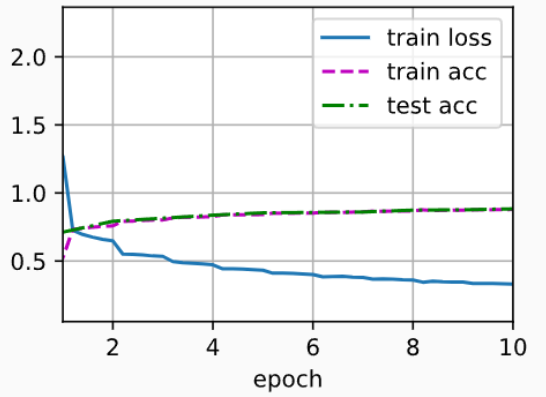
4. AlexNet的影响
AlexNet的架构与LeNet相似,但使用了更多的卷积层和更多的参数来拟合大规模的ImageNet数据集。
今天,AlexNet已经被更有效的架构所超越,但它是从浅层网络到深层网络的关键一步。
尽管AlexNet的代码只比LeNet多出几行,但学术界花了很多年才接受深度学习这一概念,并应用其出色的实验结果。这也是由于缺乏有效的计算工具。
Dropout、ReLU和预处理是提升计算机视觉任务性能的其他关键步骤。
推动了深度学习在计算机视觉领域的飞速发展 :AlexNet 在 ImageNet 挑战赛中的成功,证明了深度卷积神经网络在图像分类任务中的巨大优势,激发了学术界和工业界对深度学习研究的热情,促使大量研究人员投入到深度学习模型的开发和优化中,推动了计算机视觉领域的发展,使得深度学习技术在图像识别、目标检测、图像分割等众多计算机视觉任务中得到了广泛应用。
引领了深度学习模型结构设计的新潮流 :AlexNet 的深度网络结构和各种创新技术为后续深度学习模型的设计提供了范例和灵感。后续的众多卷积神经网络架构(如 VGGNet、GoogLeNet、ResNet 等)在 AlexNet 的基础上进行了进一步的改进和优化,不断加深网络深度、拓宽网络宽度、引入更复杂的结构设计,以提高模型性能,推动了深度学习模型的不断发展和创新。
促进了 GPU 在深度学习中的广泛应用 :AlexNet 的训练过程展示了 GPU 在加速深度学习模型训练方面的巨大优势,促使深度学习社区更加广泛地采用 GPU 进行模型训练。这不仅提高了模型的训练效率,还为深度学习模型的进一步发展提供了硬件支持,使得研究人员能够训练更复杂、更大规模的模型,进一步推动了深度学习技术的发展。
推动了深度学习框架和库的发展 :为了方便研究人员和开发者更高效地构建和训练深度学习模型,众多深度学习框架和库(如 TensorFlow、PyTorch、Keras 等)应运而生并不断发展壮大。这些框架和库提供了丰富的工具和接口,使得构建和训练类似 AlexNet 的深度卷积神经网络变得更加简单和高效,降低了深度学习的入门门槛,促进了深度学习技术的普及和应用。